规模上,最长可以扩展到10万token,一口气就能读完长篇小说的多个章节或中短篇小说。
贾佳亚韩松联合团队提出的这个基于LoRA的全新大模型微调方法,登上了GitHub热榜。

这种方式叫做LongLoRA,由来自香港中文大学和MIT的全华人团队联合出品。
在一台8个A100组成的单机上,增大窗口长度的速度比全量微调快数倍。
网友看了之后不禁表示,这个效率实在是令人印象深刻:

那么,用LongLoRA微调之后,模型会有什么样的变化呢?
一口气读完一部小说
研究团队的实验当中使用的模型是Llama 2。
经过LongLoRA方法微调之后,Llama 2-7B的窗口长度最高可提升到10万token。
实测发现,微调后的模型可以一口气读完一部小说,然后回答各种问题。
比如总结一下大刘在《三体》第三部中体现的中心思想,比总结内容还高出了一个层次。
模型给出的答案是与外星文明首次接触的危险性、星际旅行之困难与人类文明之脆弱,以及团结协作的重要性等内容。
的确每条在原著中都有所体现,而且也比较全面了。

除了对整部作品进行概括提炼,局部内容当然也可以询问。
小说中的角色也能对答如流,比如《西游记》中孙悟空是怎么开花成长的。
模型告诉我们,孙悟空很有智慧,但又有一颗顽皮的心,在伴随唐僧取经的过程中走向了成熟。
这次的总结依旧是很到位。

而且不仅是单个角色,不同人物之间复杂的关系也能了如指掌。
提问的方式可以简单粗暴些,直接要求描述这本书(《哈利波特》)中的人物关系。
模型以哈利·波特为中心,介绍了他的朋友韦斯莱、赫敏,敌人马尔福,以及邓布利多教授等人物。

除了看小说,LongLoRA微调后的Llama还可以读论文,生产力一下子就提高了(喜)。
无论是整体概括还是局部询问,微调后的模型都能准确地给出答案:

△中文部分为谷歌机翻

为了从宏观上把握模型的表现,研究团队用了如下数据集进行了测试:
PG19:来自书籍的长篇文档数据集,用来测试语言建模效果。
Proof-pile:来自arXiv的数学论文数据集,用来测试语言建模效果。
LongQA:作者自行构建的长序列问答数据集,用于有监督的微调。
LongChat:第三方构建的长对话理解数据集,用来测试长序列叙述理解效果。
结果显示,LongLoRA在PG19和Proof-pile上的困惑度与全量微调接近。
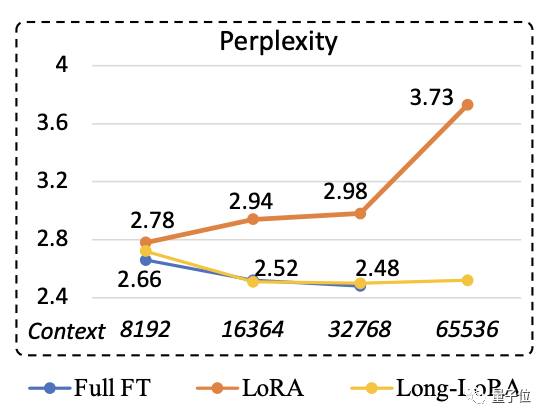
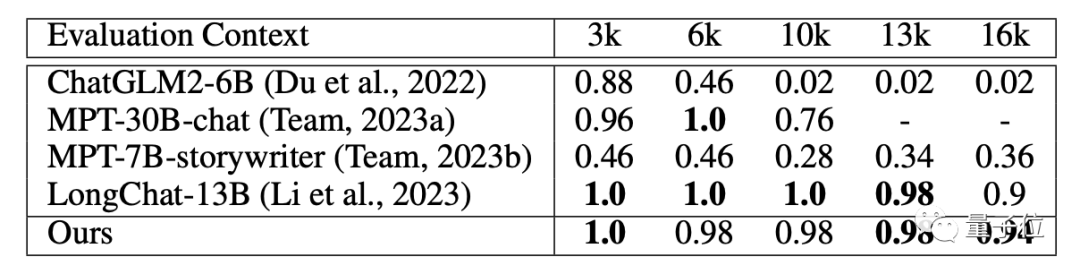
在问答数据集上,LongLoRA微调出的模型表现也很优异,长文本理解方面更是达到了SOTA水平。
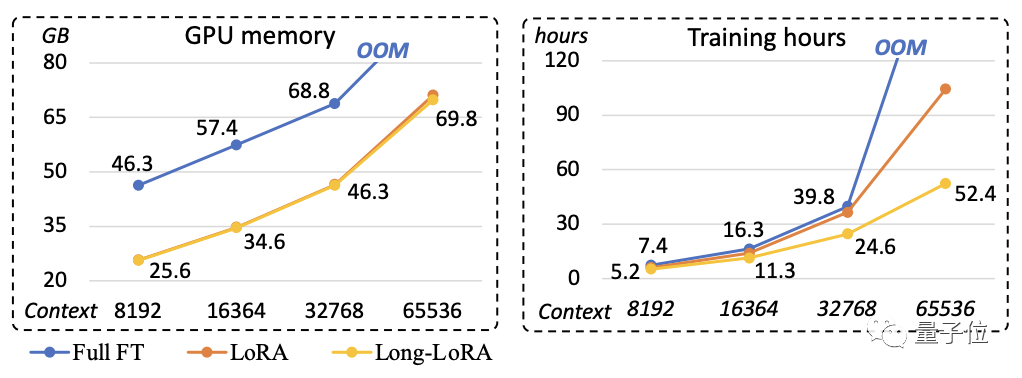
当然,LongLoRA的意义不仅在于提高了窗口长度,关键在于用更少的消耗提高了窗口长度。
以7B参数量的Llama-2为例,如果使用全量微调,从4k提升到32k,在一台8个A100的单机上需要五天。
而改用LongLoRA方式,则只用11.3小时就能完成,连半天都不到,效率提升近十倍。
如果提升到65k,全量微调所需时间将超过1000小时,LongLoRA却只用52.4小时。
那么LongLoRA又是怎么做到的呢?
“大而化小”降低计算量
LongLoRA建立在LoRA的基础之上,引入了一种称为“移位短注意力”(shift short attention)的机制。
这种机制只需要两行代码就能实现:

Transformer架构的核心是自注意力(Self-attention)计算。
短注意力就是将训练文本划分为多个组,使自注意力计算在每个组内分别进行,从而达到降低运算量的目的。
而在这一过程中注意力头也被进行了分组,通过注意力头的位移,就实现了组间的信息交互。
划分出的每个组之间有重叠部分,确保了数据可以在全文中流通。
这样一来,每次计算都只需要对组内的token进行操作,运算量大大降低。
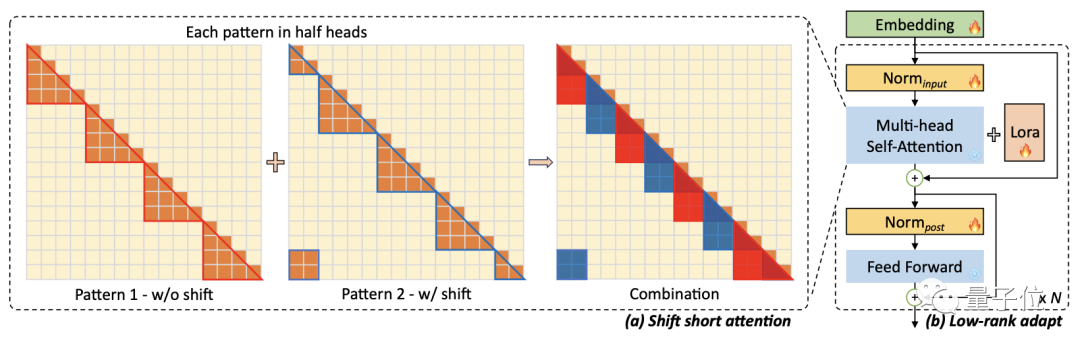
除了对输入进行分割之外,LongLoRA相比于Lora还可以微调embedding层和normalization层。
这两项内容占的参数量很小,以Llama 2-7B为例,embedding层只占1.94%,normalization层更是不到十万分之四。
消融实验结果表明,除了核心的Attention层,这两个占比很小的部分也起到了重要作用。

除了核心的短注意力机制,研究团队引入了DeepSpeed和FlashAttention方式,进一步降低了训练消耗。
目前,LongLoRA微调过后不同参数量和窗口长度的Llama 2已经开源,感兴趣的话可以到GitHub页面中查看。
论文地址:
https://arxiv.org/abs/2309.12307
GitHub项目页:
https://github.com/dvlab-research/LongLoRA
若觉得还不错的话,请点个 “赞” 或 “在看” 吧
论文指导班
论文指导班面向那些没有导师指导、需要升学申博的朋友,指导学员从零开始调研相关方向研究、尝试idea、做实验、写论文,指导老师会提供一些idea、代码实现部分的指导、论文写作指导和修改,但整体仍然是由学员自主完成。需要说明的是,论文指导班并非帮你写论文,或者直接给一篇论文让你挂名,我们不会做任何灰色产业,因此,想直接买论文或挂名的朋友请勿联系。
指导老师:
海外QS Top-60某高校人工智能科学博士在读, 师从IEEE Fellow,曾在多家AI企业担任研究实习生和全职算法研究员,具备极强的学术届和工业界综合背景。研究领域主要包括通用计算机视觉模型的高效设计,训练,部署压缩以及在目标检测,语义分割等下游任务应用,具体包括模型压缩 (知识蒸馏,模型搜索量化剪枝), 通用视觉模型与应用(VIT, 目标检测,语义分割), AI基础理论(AutoML, 数据增广,无监督/半监督/长尾/噪声/联邦学习)等;共发表和审稿中的15余篇SCI国际期刊和顶级会议论文,包括NeurIPS,CVPR, ECCV,ICLR,AAAI, ICASSP等CCF-A/B类会议。发明专利授权2项。
长期担任计算机视觉、人工智能、多媒体领域顶级会议CVPR, ECCV, NeurIPS, AAAI, ACM MM等审稿人。指导研究生本科生发表SCI, EI,CCF-C类会议和毕业论文累计30余篇,有丰富的保研,申博等方面经验,成功辅导学员赴南洋理工,北大,浙大等深造。
涉及范围:CCF会议A类/SCI一区、CCF会议B类/SCI二区、CCF会议C类/SCI三区、SCI四区、EI期刊、EI会议、核心期刊、研究生毕业设计
报名请扫描下方二维码了解详细情况,备注:“论文班报名”。

如果有其他想要当论文指导老师的朋友,请发简历给我,同样扫描上方二维码,备注:“论文指导老师”。基本条件:已发表两篇以上一作顶会,或3-5篇其他级别的一作论文,学历在985博士及以上。









