深度学习经典模型之BERT(上)
在"深度学习经典模型之BERT(上)"我们描述了BERT基本信息、意义、与GPT和Transformer的区别、预训练、自监督等相关信息后,本章节将介绍BERT的输入、Encoder、微调及两个主流变种。
BERT inputs
切词方法
BERT的切词方法用的是WordPiece embeddings,其思想是如果一个词在整个里面出现的概率不大的话,就应该把它切开,看他的一个子序列,如果它的一个子序列(比如它的词根)出现的概率很大,那么只保留这个子序列就好了,这样可以把一个相对长的词切成一段又一段的片段,这些片段还是经常出现的,就可以用相对较小的30k的词典就能表示一个比较的文本。这样可以避免按照空格切词时一个词作一个token会让数量大进而导致词典变大,让可学习的参数都集中在了嵌套层里的问题。
序列的第一个词永远是一个特殊词元[CLS]代表序列开始(全称:classification), 在每个句子后面放一个特殊词[SEP]表示separate或end,全称separator。如上图所示。
 image.png
image.png输入嵌入
Bert输入嵌入包含三部分的内容:token embeddings,position embeddings,和Segment Embeddings(token所属段落编码的embeddings),示意如上图所示。即对于每一个token(词元)在BERT的向量表示这个token本身的embedding加上它在哪个句子的embedding再加上位置的embedding.
在Transfomer里面位置信息是手动构造出的矩阵,但是在BERT里面不管你是属于哪个句子还是位置在哪,它对应的向量的表示都是通过学习而来的。
- Token Embeddings:采用look up的方式,将每个token转换成768维的向量。
- Segment Embeddings:BERT支持双句输入,Segment(0,1)用于区分a、b句。
- Position Embeddings:采用训练式位置编码,通过look up获取位置编码。
transformer的输入是由 word embedding + position embedding组合而成的向量x.
BERT Encoder
基础架构
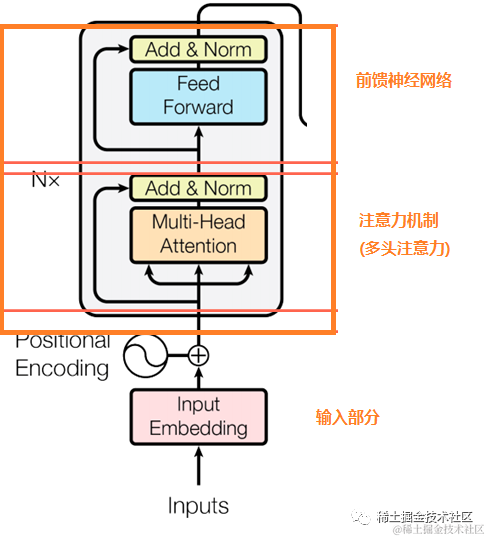
BERT的Encoder包含三个部分的内容:输入、多头注意力与前馈神经网络。对应的是Transformer的Encooder部分,
其中输入部件的组成比Transormer多了一层,具体见Bert input章节。
Bert与Transformer不同的是,BERT仅采用Transfomer的Encoder,分为BERT bae与BERT large,其层数等参数都有所不同。
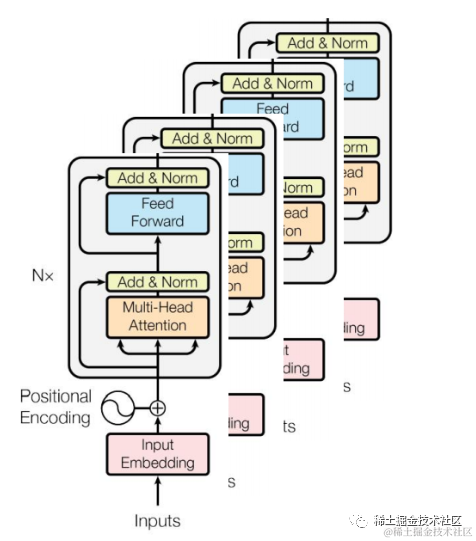
BERT Base信息
BERT-base采用12层的Transformer Encoder堆叠,上一层的输出作为下一层的输入,基本信息与架构图如下:
| 基本信息 | 架构示意图 |
|---|
encoder层数(layers) :12层
模型最大输长度(max_len):512
维度(dim):768
头数(Head,简称h):12
参数:110M
GPU:7G+
|  |
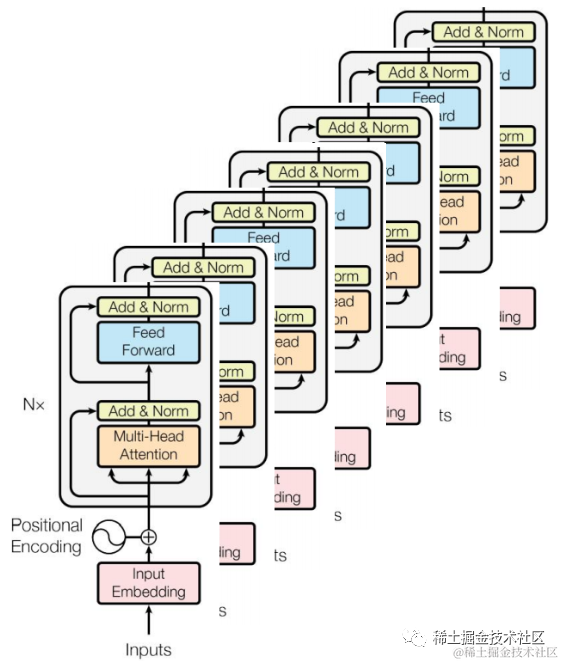
BERT large信息
BERT-large采用24层的Transformer Encoder堆叠,上一层的输出作为下一层的输入,基本信息与架构图如下:
| 基本信息 | 架构示意图 |
|---|
encoder层数(layers):24层
模型最大输长度(max_len):1024
维度(dim):768
头数(Head,简称h):16
参数:340M
GPU:32G+
|  |
BERT Fintune - 微调
预微调模块
BERT本质是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示。通过大量的数据预训练得到的通用模型,后续基于通用模型再进行微调。
对于不同的任务,微调都集中在预微调模块,几种重要的NLP微调任务架构图展示如下:
 image.png
image.png微调任务
句对分类任务
判断两句子之间的关系,如句子语义相似度、句子连贯性判定等,其本质是文本分类。
- 输入: 两句子,[CLS]sentence1[SEP]sentence2[SEP]
单句分类任务
单句分类任务是判断句子属于哪个类别,如新闻分类、问题领域分类等。
- 输入: 一个句子,形如 [CLS]sentence[SEP];
- 做法: 选择bert模型输出的第一个位置的token,也就是[CLS]的向量作为下游任务的输入。
QA任务
给定问答和一段文本,从文本中抽取出问题的答案,如机器阅读理解等。其本质是序列标注。
- 输入: 一个问题,一段文本,形如[CLS]question[SEP]content[SEP]
NER任务
NER(Named Entity Recognition 命名实体识别)的过程,就是根据输入的句子,预测出其序列标注的过程。
- 输入: 念熹在清华大学的体育场看了中国男篮的一场比赛
- 输出: B-PER,E-PER,O, B-ORG,I-ORG,I-ORG,E-ORG,O,B-LOC,E-LOC,O,O,B-ORG,I-ORG,I-ORG,E-ORG,O,O,O,O
其中,“念熹”以PER,“清华大学”以ORG,“体育场”以LOC,“中国男篮”以ORG为实体类别分别挑了出来。
BIOES标注方式中含义
B,即Begin,表示开始
I,即Intermediate,表示中间
E,即End,表示结尾
S,即Single,表示单个字符
O,即Other,表示其他,用于标记无关字符
BERT变种
RoBERTa - 主流
特点
-
使用更多的预训练数据 (由16GB 升-> 160GB)
- 更大的batch size (batch size 256 -> batch size 8K)
括号中的数据代表传统bert到ROBERTa时配置变化
动态掩码
原本的BERT采用的是static mask的方式,就是在create pretraining data中,先对数据进行提前的mask。
为了避免在每个epoch中使用相同的mask数据,充分利用数据,定义了dupe factor,这样可以将训练数据复制dupe factor份,然后同一条数据可以有不同的mask,注意这些数据不是全部都喂给同一个epoch,是不同的epoch,例如dupe factor=10,epoch=40则每种mask的方式在训练中会被使用4次。
动态掩码的方式在模型训练阶段实时计算掩码的位置和方法,能够最大限度的保证同一段文本在不同epoch下使用不同的掩码模式,提高了数据的复用效率。
ALBERT
- 词向量因式分解。BERT中 embedding 维度E与Transformer 隐层维度 H一致ALBERT 引入词向量因式分解方法解耦E和H,先将词向量编码到低维空间E,然后通过个全连接层将E映射到H,计算复杂度从 (VH) 降低到 (VE + EH)
- Transformer 跨层参数共享。ALBERT中每一层Transformer的参数都是一样的,类似于一个循环结构,每次都经过相同的Transformer层
- 引入sop (Sentence Order Prediction) 任务代替NSP任务
附:Bert中的特殊词元表示
在BERT中,和是特殊的词元(token),用于在输入序列中标记特定的位置和边界。
[CLS]
[CLS]它是表示序列开头的特殊词元,全称为"classification"。在BERT中,输入序列的第一个位置被标记为[CLS],用于表示整个序列的概括信息。在训练过程中,BERT模型学习使用位置的表示来进行各种分类任务,例如文本分类、情感分析等。在编码后的表示中,[CLS]位置的向量通常用作整个序列的汇总表示。
[SEP]
[sep]它是表示序列分割的特殊词元,全称为"separator"。在BERT中,输入的文本序列可以由多个片段(segments)组成,例如两个句子或一个问题和一个回答。为了将这些片段分隔开,[sep]词元用于标记不同片段的边界。它出现在片段之间和序列的末尾,用于告知BERT模型输入序列的结构。
[PAD]
[PAD]它表示填充(padding)的词元,在输入序列中用于填充长度不足的片段或序列。填充是为了使所有输入序列具有相同的长度,以便进行批量处理。
[MASK]
[MASK]它表示掩蔽(mask)的词元,在预训练阶段用于生成掩蔽语言模型(Masked Language Model,MLM)任务。在训练过程中,输入序列中的一部分词元会被随机选择并替换为[MASK]词元,模型需要预测被掩蔽的词元。
[UNK]
[UNK]它表示未知(unknown)的词元,用于表示在预训练期间未见过的词汇。当输入序列中出现未登录词(out-of-vocabulary)时,这些词元将被替换为[UNK]词元。
这些特殊的词元表示方式使BERT模型能够处理不同类型的输入和执行不同的任务,例如分类、回归、命名实体识别等。它们提供了对输入序列的结构和语义的信息,并且在预训练和微调阶段起到关键的作用。
除了[CLS],[SEP],[MASK],[UNK]之外,BERT还可以使用其他自定义的特殊词元表示方式,具体取决于具体的应用场景和任务需求。比如 领域特定词元、标签词元、实体词元等。
来自(https://blog.csdn.net/weixin_44624036/article/details/131146059)
记录于2023-11-15 山海
[参考]
https://blog.csdn.net/weixin_42038527/article/details/130871339
https://blog.csdn.net/weixin_44624036/article/details/131146059
https://blog.csdn.net/qq_42801194/article/details/122294769









