实现功能:对点云进行DBSCAN聚类,并得到每一次聚类的点云簇的个数
加载所需的库
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import DBSCAN from sklearn.preprocessing import StandardScaler
从数据中不断按帧数来读取数据,从frame_start读,最多不能超过frame_end,直到读取点的数量达到num_threshold后停止。可以理解为,自适应地读取一定数量的点云,从而使得点云总数拓充到一个可以聚类的程度。
def adaption_frame(data, frame_start, frame_end, num_threshold=1000): data_x = [] data_y = [] data_z = [] for i in range(frame_start, frame_end): target_frame = i # 替换为你想要读取的Frame值 # 筛选出指定Frame值的点云数据 table_data = data[data['Frame #'] == target_frame] x_arr = table_data['X'].values data_x = np.concatenate((data_x, x_arr), axis=0) y_arr = table_data['Y'].values data_y = np.concatenate((data_y, y_arr), axis=0) z_arr = table_data['Z'].values data_z = np.concatenate((data_z, z_arr), axis=0) if data_x.shape[0] > num_threshold: break return data_x, data_y, data_z
利用坐标值,简单的对点云进行去噪
def valid_data(data_x, data_y, data_z): # 创建一个布尔数组,检查每个元素是否在 -2 到 2 之间 # 使用 & 操作符来确保 A、B、C 的对应元素都满足条件 condition = (data_x >= -5) & (data_x <= 5) & (data_y>= -5) & (data_y <= 5) & (data_z >= -5) & (data_z <= 5) # 使用布尔数组来索引 A、B、C,过滤出满足条件的元素 data_x_valid = data_x[condition] data_y_valid = data_y[condition] data_z_valid = data_z[condition] # 输出新的数组大小 # print
("x valid shape:", data_x_valid.shape) # print("y valid shape:", data_y_valid.shape) # print("z valid shape:", data_z_valid.shape) return data_x_valid, data_y_valid, data_z_valid
用于点云的绘图
def draw_data_origin(data_x, data_y, data_z): # 创建3D绘图 fig = plt.figure() ax = fig.add_subplot(111, projection='3d') # 绘制点云 ax.scatter(data_x, data_y, data_z, s=0.1) # s控制点的大小 # 设置轴标签 ax.set_xlabel('X') ax.set_ylabel('Y') ax.set_zlabel('Z') ax.set_title(f'Point Cloud at Frame {1}') # 显示图形 plt.show()
DBSCAN代码
def dbscan(data_x, data_y, data_z): # 将 X, Y, Z 合并成一个二维数组 data_input = np.column_stack((data_x, data_y, data_z)) # 标准化数据(对于许多聚类算法来说,标准化是一个好习惯) scaler = StandardScaler() data_scaled = scaler.fit_transform(data_input) # 初始化 DBSCAN,这里 eps 和 min_samples 是两个重要的参数,需要根据数据特性进行调整 # eps 是邻域的半径大小,min_samples 是成为核心对象所需的最小邻居数 dbscan = DBSCAN(eps=0.3, min_samples=5) # 进行聚类 labels = dbscan.fit_predict(data_scaled) # 计算不同标签的数量,即点簇的个数 num_clusters = len(set(labels)) - (1 if -1 in labels else 0) return num_clusters, labels,
对每一次的聚类结果,按照点数大小降序排列。例如:某次聚类结果分为了3类,label为2的点云簇点云数为100,label为2的点云簇点云数为30,label为3的点云簇点云数为50。结果就是对他们进行降序排列。
def order_cluster(clusters_num, labels): unique_labels, inverse_indices = np.unique(labels, return_inverse=True) print(unique_labels.shape) print(inverse_indices.shape) # 使用 numpy.bincount 统计每个标签出现的次数 counts = np.bincount(inverse_indices) # 按照出现次数降序排列 sorted_indices = np.argsort(counts)[::-1] # 获取降序排列的索引 sorted_labels = unique_labels[sorted_indices] # 根据索引重新排列标签 sorted_counts = counts[sorted_indices] # 根据索引重新排列计数 # 打印结果 for label, count in zip(sorted_labels, sorted_counts): print(f"类别 {label}: {count} 次") A = [] for i in range(unique_labels.shape[0]): # 首先找到个数最多的标签 most_common_label = sorted_labels[i] # 然后找到这个标签在原始 labels 数组中的位置 positions_most_common = np.where(labels == most_common_label)[0] A.append(positions_most_common) return A
第一次的聚类结果,需要进行特殊的处理。认为点云数量超过human_size,才可以成为一个有效簇。用这种方式得到第一次聚类结果,存在多少个有效簇,并返回最小簇的点云数
def getFirstJudge(clusters_num, labels_order, human_size): num = 0 for i in range(clusters_num): size = labels_order[i].shape[0] if size > human_size: num = num + 1 points_num_min = size return num, points_num_min
每一次的聚类结果进行处理。如果这一次的聚类结果,有某一次的点云簇点云数大于上一次的最小点数,认为簇的个数可以增加;否则更新最新的最小簇代表的点云个数。
def adaption_cluster(clusters_num, labels_order, num_last, points_num_min, human_size): print("上一帧个数:" + str(num_last)+ " 最小的点簇:"+str(points_num_min)) for i in range(clusters_num): shape = labels_order[i].shape if i <= num_last-1: if labels_order[i].shape[0] < human_size: num_last = i + 1 break else: points_num_min = labels_order[i].shape else: if labels_order[i].shape[0] > human_size: num_last = num_last + 1 points_num_min = labels_order[i].shape else: break; return num_last, points_num_min
主函数的实现流程:
1.读取数据
2.积累一定帧数的点云,随后聚类
3.对每一次的聚类结果,进行处理
if __name__ == "__main__": # 参数 human_size = 100 csv_file = 'data/1.csv' # 替换为你的CSV文件名 data = pd.read_csv(csv_file) frame_start = data['Frame #'][0] frame_end = data['Frame #'][data['Frame #'].shape[0]-1] for i in range(100000): frame_start = data['Frame #'][i] if frame_start < frame_end: break print(frame_start) print(frame_end)# frame_start = 0# frame_end = 120 num_last = 0
# 上一帧的人数 points_num_min = 0 # 满足此个数才是一个人 flag = 0 for i in range(frame_start, frame_end): data_x, data_y, data_z = adaption_frame(data, frame_start, frame_end, num_threshold=1000) data_x, data_y, data_z = valid_data(data_x, data_y, data_z) clusters_num, labels = dbscan(data_x, data_y, data_z) # draw_data_origin(data_x, data_y, data_z) # 使用 numpy.unique 获取唯一标签和它们在原始数组中的索引 labels_order = order_cluster(clusters_num, labels) print(labels_order[0].shape) print(labels_order[1].shape) if flag == 0: num_last, points_num_min = getFirstJudge(clusters_num, labels_order, human_size) flag = 1 else: num_last, points_num_min = adaption_cluster(clusters_num, labels_order, num_last, points_num_min, human_size) print("第 "+str(frame_start) + " 帧有 :" + str(num_last)+" 个人") if frame_start + 10 > frame_end: break else: frame_start = frame_start + 1
实现功能:设定K值,对点云进行Kmeans聚类,
加载所需的包
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import DBSCAN from sklearn.preprocessing import StandardScalerfrom sklearn.cluster import KMeans from scipy.optimize import linear_sum_assignment from scipy.spatial.distance import cdist
以下代码同之前的DBSCAN一样,在这里不赘述
def adaption_frame(data, frame_start, frame_end, num_threshold=1000): def valid_data(data_x, data_y, data_z):def draw_data_origin(data_x, data_y, data_z):def dbscan(data_x, data_y, data_z):def order_cluster(clusters_num, labels):def getFirstJudge(clusters_num, labels_order, human_size):def adaption_cluster(clusters_num, labels_order, num_last, points_num_min, human_size):
Kmeans进行聚类
def cluster_kmeans(value, data_x, data_y, data_z): data_x = data_x.reshape(-1, 1) data_y = data_y.reshape(-1, 1) data_z = data_z.reshape(-1, 1)
从聚类结果中,提取一些特征,用做之后的匈牙利匹配。
这里,提取了三个特征:点云簇的均值、点云数、以及点云排序id
def extract_feature(K, labels_order, data_x, data_y, data_z): features = [] for i in range(K): one_feature = [] data_x_k = data_x[labels_order[i]] data_y_k = data_y[labels_order[i]] data_z_k = data_z[labels_order[i]] # print(data_x_k.shape)# print(data_y_k.shape)# print(data_z_k.shape) x_mean = np.mean(data_x_k, axis=0) y_mean = np.mean(data_y_k, axis=0) z_mean = np.mean(data_z_k, axis=0) cluster_mean = np.hstack((x_mean, y_mean, z_mean)) cluster_points_size = labels_order[i].shape one_feature.append(cluster_mean) one_feature.append(cluster_points_size) one_feature.append(i) features.append(one_feature) return features
用提取的特征进行匈牙利匹配
def hungarian_match(features_last, features_now): # 提取点云中心和点云数 centers_last = np.array([a[0] for a in features_last]) counts_
last = np.array([a[1][0] for a in features_last]) centers_now = np.array([b[0] for b in features_now]) counts_now = np.array([b[1][0] for b in features_now]) # 计算点云中心之间的欧氏距离 distance_matrix = cdist(centers_last, centers_now) # 定义基于点云数和距离的成本函数 # 这里我们简单地使用距离的倒数和点云数差异的绝对值作为成本 # 你可能需要根据你的具体需求来调整这个成本函数 # cost_matrix = 1.0 / distance_matrix + np.abs(counts_last[:, np.newaxis] - counts_now) cost_matrix = np.abs(counts_last[:, np.newaxis] - counts_now) + distance_matrix * 10 # 应用匈牙利算法找到最小成本匹配 row_ind, col_ind = linear_sum_assignment(cost_matrix) # 打印匹配结果 matches = [(features_last[row_ind[i]], features_now[col_ind[i]]) for i in range(len(row_ind))] for match in matches: print(f"Match: last={match[0][0]} (count={match[0][1][0]}), (label={match[0][2]}), now={match[1][0]} (count={match[1][1][0]}), (label={match[1][2]})") return matches
主函数
if __name__ == "__main__": csv_file = 'data/2.csv' # 替换为你的CSV文件名 K = 2 # 参数 human_size = 100 data = pd.read_csv(csv_file) frame_start = data['Frame #'][0] frame_end = data['Frame #'][data['Frame #'].shape[0]-1] for i in range(100000): frame_start = data['Frame #'][i] if frame_start < frame_end: break frame_start = 0 frame_end = 120 num_last = 0 # 上一帧的人数 points_num_min = 0 # 满足此个数才是一个人 flag = 0 features_last = [] data_x_all= [[] for _ in range(K)] data_y_all = [[] for _ in range(K)] data_z_all = [[] for _ in range(K)] for i in range(frame_start, frame_end): data_x, data_y, data_z = adaption_frame(data, frame_start, frame_end, num_threshold=1000) data_x, data_y, data_z = valid_data(data_x, data_y, data_z) result_kmeans = cluster_kmeans(K, data_x, data_y, data_z) # 输出每个点的label labels = result_kmeans.labels_ labels_order = order_cluster(K, labels) features = extract_feature(K, labels_order, data_x, data_y, data_z) print(features) frame_start = frame_start + 1 if flag == 0: features_last = features flag = 1 continue else: matches = hungarian_match(features_last, features) for k in range(K): # 第一维代表匹配对数,第二维0代表features_last,1代表features # 第三维代表特征维度,第四维每个特征的参数 data_x_all[k].extend(data_x[labels_order[matches[k][0][2]]]) data_y_all[k].extend(data_y[labels_order[matches[k][0][2]]]) data_z_all[k].extend(data_z[labels_order[matches[k][0][2]]])# print(len(data_x_all[k])) features_last = features # 创建颜色列表,这里使用RGB颜色 colors = ['r', 'g', 'b'] # 红色、绿色、蓝色 # 创建一个3D图形 fig = plt.figure() ax = fig.add_subplot(111, projection='3d') # 遍历每组数据并绘制 for k in range(K): x = data_x_all[k] y = data_y_all[k] z = data_z_all[k] color = colors[k % len(colors)] # 使用循环颜色,以防K大于颜色数量 ax.scatter(x, y, z, c=color, label=f'Group {k+1}') # 添加图例 ax.legend() # 设置坐标轴标签 ax.set_xlabel('X') ax.set_ylabel('Y') ax.set_zlabel('Z') # 显示图形 plt.show()
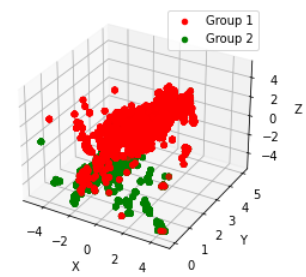
以下就是匈牙利匹配后的结果。红色和绿色分别代表,经过匈牙利匹配后的点云簇,统一了时间维度画在一张图上的结果。如果需要,可以按照时间序列一步步来画,这样可以看到红色和绿色沿着各自的动线前进



 点击“阅读原文”了解详情
点击“阅读原文”了解详情










