在如今数据为王的AI时代,用户隐私保护变得尤为重要。
OpenAI作为全球领先的人工智能公司,深知这一点,并始终致力于保护用户的隐私。

在本文中,我们将详细介绍OpenAI如何通过多种措施保障用户隐私,并提供相应的控制数据使用的方法。
保护用户隐私的承诺
OpenAI承诺保护每一位用户的隐私,并理解用户可能不希望自己的数据被用于模型改进。

为此,OpenAI提供多种管理数据的方式,确保用户在享受AI技术便利的同时,能够自主掌控自己的数据。
透明的数据管理方式
人工智能模型的一大优势在于它们能够通过不断学习和改进,变得越来越智能。
为了提高模型的准确性和解决问题的能力,OpenAI通过研究突破和实际数据的不断曝光来改进模型。

当用户与OpenAI分享内容时,这些数据帮助OpenAI的模型变得更加精确和高效。
然而,他们充分理解并尊重用户对数据隐私的需求,因此OpenAI提供多种管理数据的方式:
1. 用户自主选择
对于ChatGPT免费和Plus用户,可以在设置中轻松选择是否参与未来模型的改进。
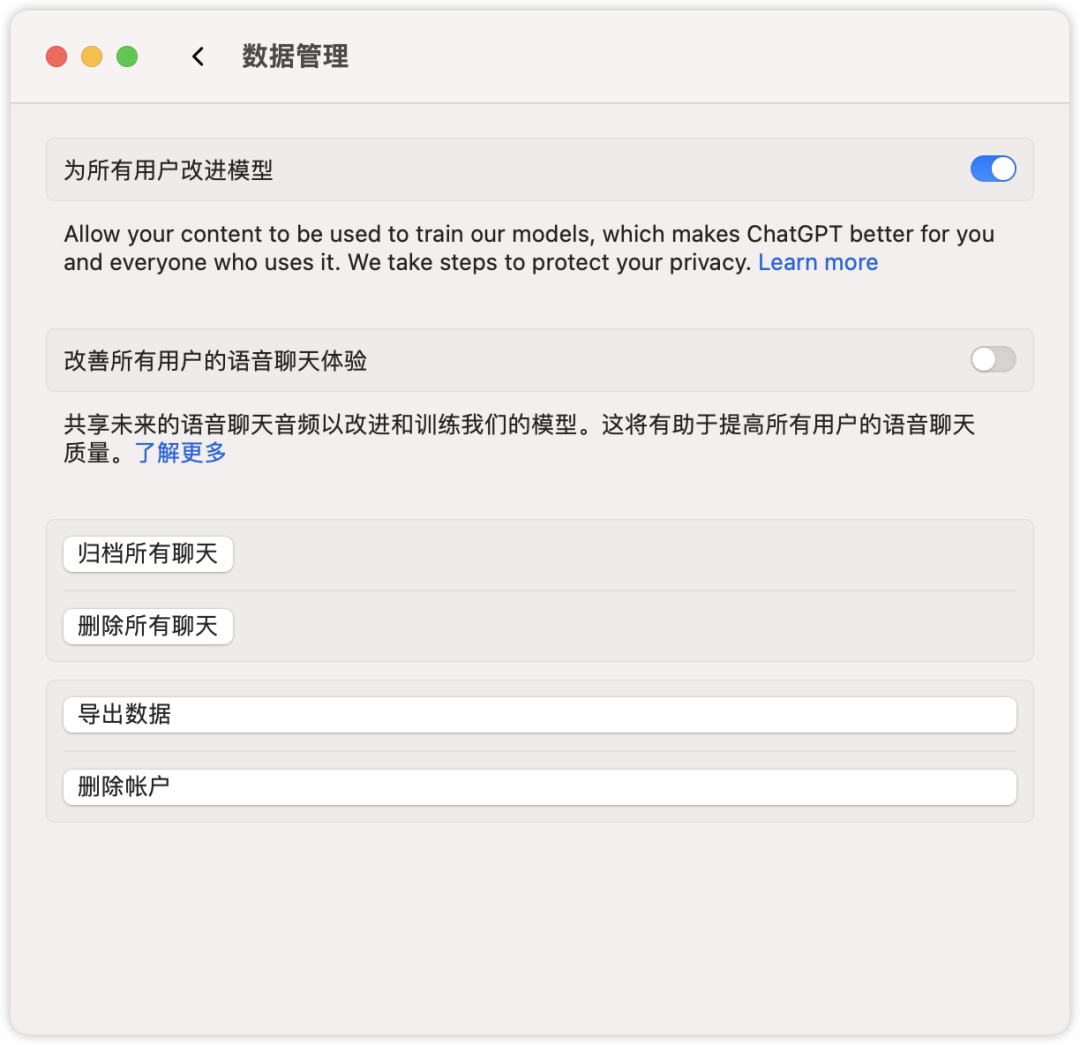
用户可以通过设置决定是否将他们的数据用于模型训练,这为用户提供更大的隐私控制权。
2. “临时聊天”模式
在ChatGPT中,用户可以选择使用“临时聊天”功能,这些对话内容不会被用于训练模型。
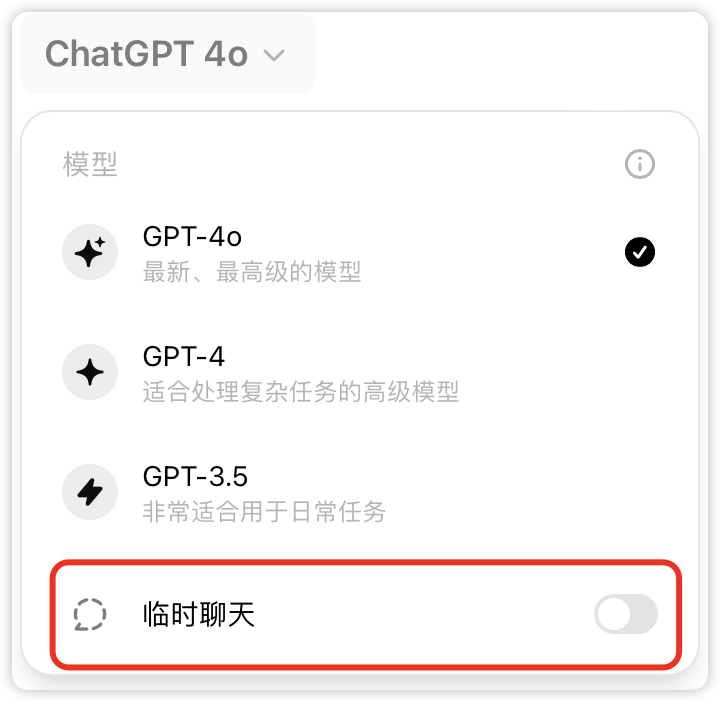
用户可以放心使用这一功能,而无需担心对话内容被用于模型改进。
3. 默认不训练API及企业客户数据
OpenAI默认不使用通过API提交的数据,以及ChatGPT企业版和团队版客户的数据来训练模型。

此政策确保企业和团队用户的数据安全性,避免其商业机密或敏感信息被用于模型改进。
目标:开发有用且安全的AI模型
OpenAI的核心目标是开发能够理解和响应用户需求的有用AI模型,而非收集私人信息。
训练数据旨在帮助AI模型(如ChatGPT)了解语言并学会如何有效地回应各种问题。

OpenAI不会主动搜集个人信息用于训练模型,也不会利用互联网公开信息来建立个人档案、进行广告投放或销售用户数据。
模型在每次回答问题时都会生成新的文字,而不是从数据库中调用信息或“复制粘贴”训练数据。
这意味着每个回答都是实时生成的,避免存储和重复使用个人信息,从根本上保障用户隐私,用户可以安心使用。
数据隐私保护措施

1. 减少用于训练模型的个人信息量
OpenAI致力于尽量减少在训练模型过程中使用的个人信息量,以确保用户隐私得到最大程度的保护。
2. 训练模型拒绝私人或敏感信息请求
模型经过专门训练,可以拒绝处理涉及私人或敏感信息的请求,从而进一步增强用户数据的安全性。
3. 最小化包含私人或敏感信息的生成可能性
通过不断优化模型,尽可能减少模型在生成回复时包含私人或敏感信息的可能性,确保用户的隐私得到最大程度的保护。
常见问题解答

1. OpenAI会使用我的内容来改进模型和服务吗?
通过OpenAI API提交的数据不会用于训练OpenAI模型或改进我们的服务。
通过非API消费者服务(如ChatGPT或DALL·E)提交的数据可能会被用于改进模型。
2. 我可以选择不将我的数据用于改进非API服务吗?
可以。
用户可以通过访问隐私请求门户,选择“提出隐私请求”,以便选择不让你的数据用于改进非API服务。

3. 我可以选择将我的数据用于API服务吗?
可以。
虽然OpenAI不会使用通过API提交的数据来训练或改进模型,但用户可以通过填写“OpenAI 数据共享选择加入”申请表,选择分享数据。
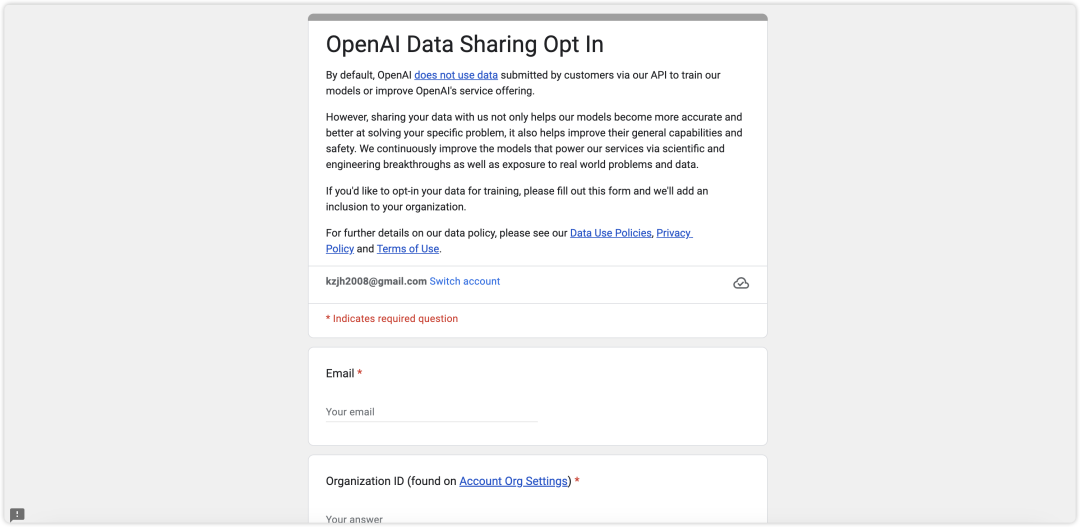
4. 我可以请求删除我的内容吗?
可以。
当用户提交数据删除请求时,我们会删除其内容(如提示、生成的图像、上传和API响应)。
处理数据删除请求可能需要多达30天的时间。
5. 我的内容会与第三方共享吗?
不会将用户内容用于营销目的分享给第三方。
用户可以通过“OpenAI Subprocessor List”页面找到OpenAI为提供处理活动而与之合作的子处理器列表。

总结:信任与透明的承诺
在数据隐私保护方面,OpenAI始终秉持着信任与透明的原则。
通过多种数据管理选项和严格的隐私保护措施,致力于为用户提供安全、可靠的AI使用环境。
希望用户在享受AI带来的便利和创新的同时,也能放心地掌握自己的数据权利。

OpenAI将继续努力,确保AI技术不仅在性能上领先,也在数据隐私保护方面树立行业标杆。
OpenAI承诺将始终把用户的隐私保护放在首位,无论是个人用户还是企业客户,都将一如既往地提供最优质的服务,保护您的数据隐私。
一键三连「分享」、「点赞」和「在看」
加入AI小岛,用魔法消除烦恼!










