
SWE-bench榜单:
https://www.swebench.com
arXiv链接:
https://arxiv.org/pdf/2406.01304
GitHub链接:
https://github.com/NL2Code/CodeR作者单位:
华为,中科院,新加坡管理大学,北京大学
摘要
最近,GitHub issue 自动消解引起了学术界和工业界的极大关注。普林斯顿大学的 NLP 小组提出了 SWE-bench [1] 用于自动衡量大模型解决这个任务的能力。在本文中,我们提出了一个新的框架 CodeR,它采用了多智能体(Multi-Agent)和预先定义的任务图(Task Graph)来自动解决 GitHub 的 issues:1. 修复和解决 issue 中报告的错误(fix bug)2. 根据issue描述在代码仓库中添加新功能特性(add new feature)
在 SWE-bench-lite 上(SWE-bench 的子集),我们提出的 CodeR 能够通过单次提交解决 28.33% 的 GitHub issues,刷新 SOTA(2024/06/04)!
背景介绍
大语言模型(Large Language Models, LLMs)的快速发展,正在重塑众多行业。最近发布的 GPT-4o 在多模态能力和交互方面有了显著提升,同时也保持了与 GPT-4-Turbo 相同的文本、推理和代码智能水平。LLMs 已展示出能与人类无缝协作或完全自主工作的潜力。
在软件开发中,GitHub issues 是一种用于跟踪项目中任务、缺陷、功能请求和讨论的工具。通过 issues,可以记录需要完成的任务,如 bug 修复、功能开发等,并将这些任务分配给团队成员。用户和开发人员还可以通过 Issues 报告发现的 bug 并进行跟踪和解决。
那么,大模型能否自动解决 GitHub Issues 呢?普林斯顿的研究人员创建了一个叫 SWE-bench 的数据集,以衡量大模型在自动解决 issue 上的表现。
SWE-bench 数据集从 12 个流行的 Python 库中收集了 2,294 个 issues。给定 issue 描述和对应的代码仓库,LLMs 需要深入挖掘 issue 信息,理解代码仓库的庞大结构和内容,确定修复位置,最终生成修复补丁。这个任务极具挑战性,因为需要对大量代码进行深度推理,而任务描述信息通常并不完整。SWE-bench-lite 从 SWE-bench 中筛选了 300 个描述清晰、只修改一个文件的 issue 作为子集。在 lite 版本上迭代不仅可以缩短时间,还可以节省成本。代码仓级的任务通常需要处理大量信息,并可能需要多个相互依赖的处理步骤。从已有的工作来看,将仓库级任务划分为一组相互连接的子任务,并逐个解决它们是一个行之有效的方法。比如 Parsel [2] 和 CodeS [3],它们主要关注生成复杂的算法和简单的代码仓库,利用程序结构进行任务分解,如函数调用图或文件结构。Issue 解决更接近于修改任务,而不是生成任务。除了生成代码,仓库级修改任务还需要在生成正确代码之前识别正确位置,因为整个代码仓库的输入上下文远大于大模型的窗口大小。这将引入额外的步骤和复杂性。
自 SWE-bench 发布以来,已经涌现了多种解决方案,主要分为两类:
1. 模型直接生成补丁:将 issue 描述和代码相关上下文放入 prompt 中,直接让模型生成补丁。SWE-Llama 采用检索增强生成(RAG)方法,使用 BM25 文本相似度检索直接关联 issue 到相关代码文件。AutoCodeRover [4] 将问题描述中的关键字进行代码上下文检索,并加入到流程中,通过问题中的关键字迭代收集代码上下文,直到 LLMs 收集到足够信息生成正确补丁。
2. 迭代编辑:基于 Agent 框架,通过实时与 shell 环境交互,在代码仓库中进行迭代式代码编辑,并在完成后使用 git diff 命令生成补丁,如 SWE-agent、Devin 以及我们的方法 CodeR。
根据 SWE-bench-lite 的官方榜单,目前 300 个 issue 的自动解决率已接近 30%。
痛点和机遇
● 部分软件开发任务可以用自然语言完成
issue 的自动消解率接近 30%,意味着自然语言到项目级的复杂任务解决方案已经涌现出可以自动化的可能性。未来如《西部世界》中调试机器人(host)的方式可能成为现实,自然语言即编程语言。
● 测试和验证在自动化中的将发挥重要作用
自然语言描述复杂任务带来的不精确性,加上大模型生成的代码并不能保证其有严格的等价语义,测试和验证的加入将避免人工校验生成的解决方案。
● 模型与模型协作,模型与人协作,可能是解决长尾问题的关键
解决方案
针对上述痛点和机遇,我们探索基于 ReAct 的多 agent 框架 CodeR,该设计采用可解析的任务图来约束任务执行。我们的设计基于以下直觉:
更少的候选动作,更简单的决策:CodeR 为 agent 引入一些列针对 issue 修复的动作,与 SWE-agent 相比,动作的数量和复杂度大大增加(2x)。沿用 SWE-agent 的单 agent 框架可能会导致决策不够准确,多 agent 框架通过将动作与子任务之间的关联关系划分动作集合的方式来限定候选动作,从而降低了做出下一个行动决策的复杂性。
三思而后行:我们相信,在流程开始时进行规划比在任务进行中临时决定下一个步骤更好。而且,一个好的计划会将任务拆解成大模型能完成的子任务。
- 绕过指令遵从和长期记忆:以往大模型生成的规划通常以纯文本的形式存在。它通常会被放在提示中,以指导大模型开展后续的步骤。这要求大模型具有强大的指令遵从能力,并且需要有一个“好”的记忆,来已迭代的方式精确的执行计划。对于需要使用复杂工具并且需要很多步迭代的复杂任务,纯文本提示中的任务计划将难以遵循。
受到现实世界中人类程序员解决问题过程的启发,我们设计了 agent 的角色和其配套的动作。如图 1 所示,我们的设计包含五个角色,它们可以协作解决 GitHub issue。
每个角色都拥有自己的动作空间:
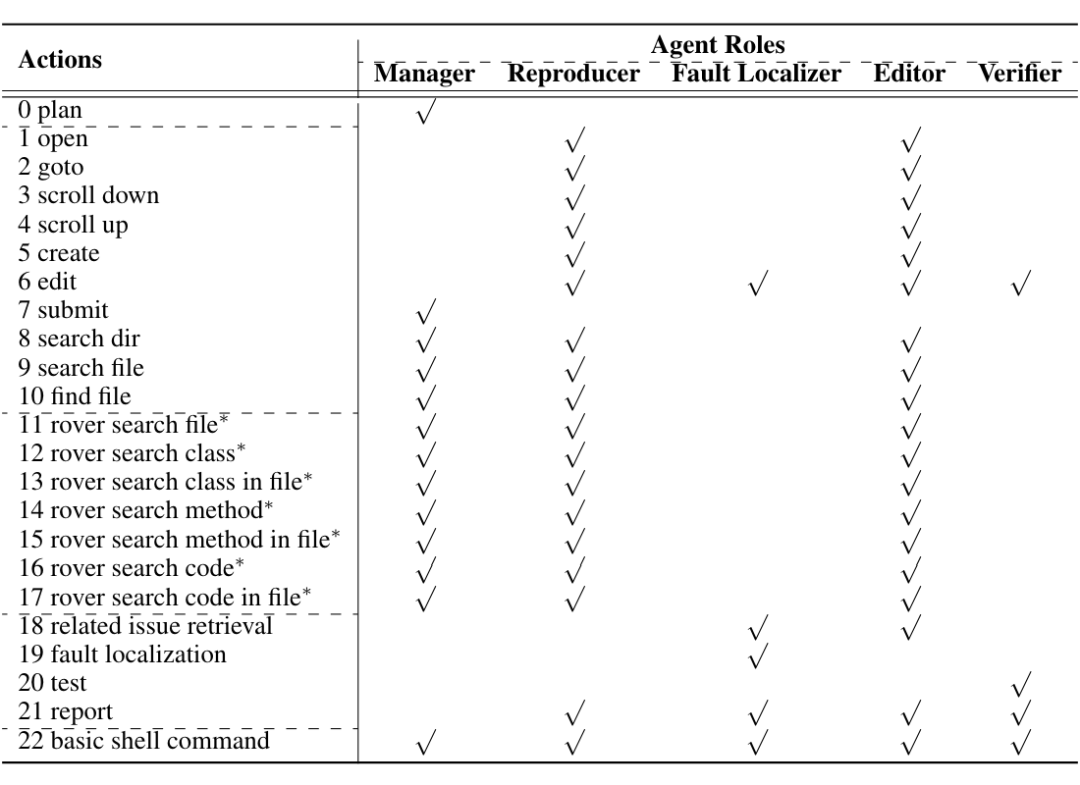
对于每个角色的动作,我们复用了 SWE-agent 和 AutoCodeRover 定义的动作。除此之外,我们还引入了新的动作:
生成规划:通过分析当前 issue 来选择或生成可行的计划。
相似 issue 检索:通过 issue 描述检索出最相似的问题及其相应的补丁。注意,对于检索结果,我们提示大模型去首先检查结果是否与当前问题相关,并分析其补丁如何解决检索到的问题。
错误定位:通过执行错误定位来找到最有可能去修改的代码段。我们采用了 BM25+ 测试覆盖的定位方法。
校验:运行由 Reporducer 生成的测试和集成测试。与 Aider [7] 一样,集成测试不包括验证生成的补丁的正确性的测试。
任务图
GitHub 问题的描述非常多样化。一些问题只有一句自然语言(例如,astropy__astropy-70084)。有些可能提供测试代码、测试代码的运行结果以及可能的解决方案(sympy__sympy-147745)。除了描述,问题的解决方案也各不相同。有些可能只需要改动一两行代码就能解决,使得任务更像代码补全任务(scikit-learn__scikit-learn-137796),而有些可能需要更改多个文件,并需要深入理解仓库内代码的语义。
对于描述清晰的简单问题单,它们的解决方案是显而易见的。但对于描述模糊或不准确的复杂问题,执行测试并通过代码库或网络进行搜索可能有助于解决它们。为了应对解决问题的不同方法,我们设计了一种可解析并可以严格执行的任务图(采用 JSON 格式)。它可以确保 agent 按照规划的准确执行,并同时为人工注入规划提供了便捷的接口。
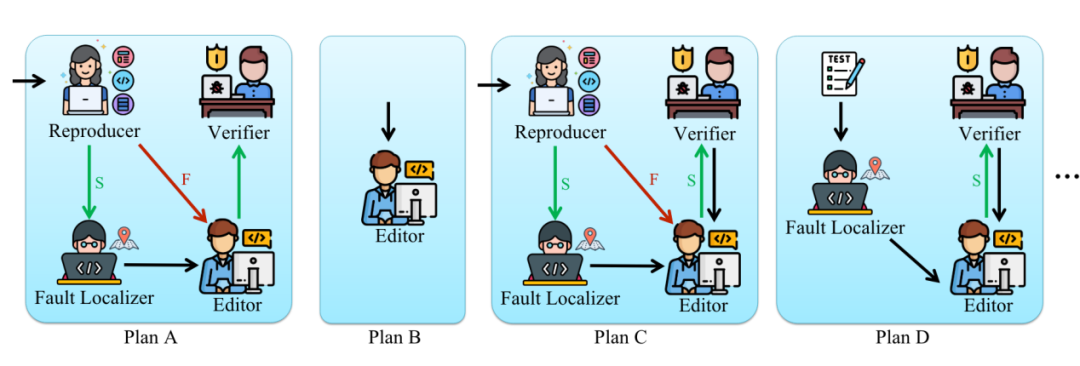
图 2 展示了一个以 JSON 格式的任务图。它在顶层指定了一系列名为 “Plan ID” 的计划。 对于每个计划,“entry” 指定了从哪个 agent开始执行计划。“roles” 指定了参与此计划的 agent 列表。
每个被选中的 agent 将在 “task” 中被给予一个子任务。一旦完成,agent 将总结执行的所有动作,并根据当前子任务的结果并传递给其 “downstream” 指定的 agent。图 2 中的计划 A 涉及到四个 agent:Reproducer,Fault localizer,Editor 和 verifier。如下图所示,该计划从 Reproducer 开始。

我们通过对 SWE-bench 数据集进行分析,结合 issue-resolve 的任务特点,总共设计了四个任务图,如下图所示:
错误定位
基于测试驱动的错误定位将有利于 CodeR 更好的找到错误发生的位置,然后才能进一步提升解决 issue 的能力。我们使用 SBFL(spectrum-based fault localization)和 BM25 相结合的方法去错误定位。
值得一提的是,我们使用 Reproducer 提供的测试用例和仓库内集成的测试用例(叫做 Integration tests,不是 issue 的测试用例)得到了更好的定位结果。
这一部分的详细的实验设置请参考论文:
https://arxiv.org/pdf/2406.01304实验结果
上表显示了 CodeR 在 SWE-bench lite 上的结果以及其与比较方法的对比结果。结果显示,与所有其他商业产品和方法相比,CodeR 在 SWE-bench lite 上创立了新的记录,达到了迄今为止(2024.06.13)的最佳性能。在 SWE-bench lite 中,CodeR 解决了 28.33% 的问题,一共 300 个中的 85 个 issues。相比之下,SWE-agent + GPT 4 和 Aider 仅为 16.67% 和 24.67%。这证明了 CodeR 精心设计的角色和任务图的显著效果。

总结
CodeR 是一个多代理框架,通过预定义的任务图来使用大语言模型(LLMs)自动解决 GitHub issues。它旨在改进单代理方法,如 SWE-agent 和 AutoCodeRover。
CodeR 具有五个代理角色:经理(Manager)、复现者(Reproducer)、故障定位器(Fault Localizer)、编辑器(Editor)和验证者(Verifier)。每个代理都有一组特定的可执行动作。与单一代理需要从大型联合动作空间中选择不同,多个代理的角色分担了决策复杂性。
关键创新之一是使用结构化任务图(task graph)来表示解决 issue 的计划。任务图指定了参与的代理、他们的子任务以及基于成功/失败的流程。这允许注入专家设计的计划,并确保其被精确执行,从而避免了 LLMs 中指令遵循和长上下文的问题。
CodeR 利用 LLM 生成的测试用例和现有代码库中的测试来获取代码覆盖率数据。这些覆盖率信息以及 BM25 分数用于改进故障定位和基于关键字的代码检索。
每个代理角色的提示工程都进行了仔细设计,定义了他们的身份、职责和可用动作。使用 ReAct 风格的提示,其中包含讨论/行动字段。

讨论和思考
任务图是否会复杂化以模型为中心的系统?任务图在提升效果的同时,也额外引入了系统的复杂度。
▲ 来自https://www.linkedin.com/posts/raphaelmansuy_github-issue-resolution-with-coder-a-multi-agent-activity-7203611421337645057-eUei推荐阅读
[1]>>专注大模型/AIGC、学术前沿的知识分享!
[2]港大&腾讯 |让LLM自学获取新知识,表现出色!
[3]
前沿:分享几个大模型(LLMs)的热门研究方向
[4]RU|提出手语生成大模型SignLLM,达到SOTA!
[5]ICLR2024顶会,历年paper整理分享(含源码)!!
投稿或寻求报道联系:ainlperbot
点击下方链接🔗关注我们










