大家好,欢迎来看今天的文献解读!你是否曾想过,为什么有些人会面临维生素D缺乏的风险?在全球维生素D缺乏成为一种“流行病”的背景下,如何及早识别高风险人群显得尤为重要。幸运的是,今天我们要分享的这篇文章Machine learning-based prediction of vitamin D deficiency: NHANES 2001-2018,正是利用机器学习的方法,帮助我们预测维生素D缺乏的风险。更令人兴奋的是,研究中不仅有丰富的数据支持,还有一个在线计算器可以直接用于社区筛查!这是不是让你心动不已呢?让我们一起来看看这篇文章的亮点吧!
这篇文章的最大亮点在于其创新性和实用性。研究者们首次运用机器学习中的XGBoost算法,构建了一个几乎完美的维生素D缺乏风险预测模型。该模型基于来自NHANES 2001-2018的数据,能有效识别社区人群中维生素D缺乏的风险。此外,研究中提出的在线网页计算器,使得任何人都可以通过简单的访谈获取风险评估,极大地降低了传统检测的高昂费用和繁琐程度。这无疑为公共卫生领域带来了新的契机,尤其是在高风险人群的筛查上。
数据来源
本研究的数据来自于Centers for Disease Control and Prevention (CDC)的National Health and Nutrition Examination Survey (NHANES),涵盖了2001至2018年的相关数据。所有数据均可公开获取,详细信息可访问:NHANES官方网站。
题目:Machine learning-based prediction of vitamin D deficiency: NHANES 2001-2018
杂志:Frontiers in Endocrinology
数据筛选与分析过程
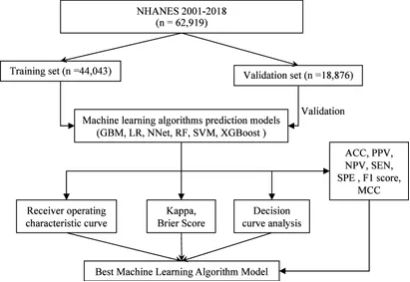
图1展示了研究中数据筛选和分析的完整流程。研究从National Health and Nutritional Examination Surveys (NHANES)数据库中纳入了62,919名参与者,并随机将数据划分为训练集和验证集,比例为70:30。经过筛选,最终确定了参与者的特征,并构建了不同的机器学习模型来预测维生素D缺乏风险。该流程图清晰地描述了每个步骤,从数据获取到模型构建,再到模型评估和验证,提供了研究设计的全貌。
这一流程图为研究的逻辑框架提供了直观的呈现,使读者能够快速理解研究的流程和结构。尤其是,图中标示了参与者的筛选标准和数据划分方式,强调了研究的科学性和严谨性。这种清晰的可视化方式有助于强化研究的可信度,使读者对后续模型构建和评估过程的信息更加有信心。
模型性能评估
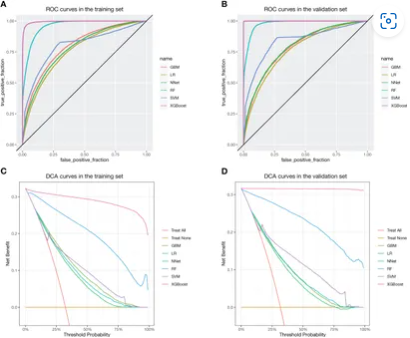
图2分为四部分,分别展示了训练集和验证集中的ROC曲线(图A和图B)以及DCA曲线(图C和图D)。ROC曲线用于评估不同机器学习方法的预测性能,AUC值的大小直接反映了模型的优劣。训练集中的AUC值显示,XGBoost方法的表现最佳,达到0.995,而在验证集中的AUC值同样表现出色,达到1。DCA曲线则展示了不同模型在不同阈值下的净收益,XGBoost模型在所有阈值下均高于“全部干预”或“无干预”策略,表明其临床实用性。
ROC和DCA曲线的结合展示了模型的预测能力和临床效用。通过高AUC值,XGBoost模型的优秀预测性能得到了验证,而DCA曲线进一步表明该模型在实际应用中的有效性和可行性。这样的分析不仅有助于理解模型的准确性,还为未来在临床实践中的应用提供了数据支持,强调了使用该模型进行维生素D缺乏筛查的潜在价值。
风险评估与在线工具
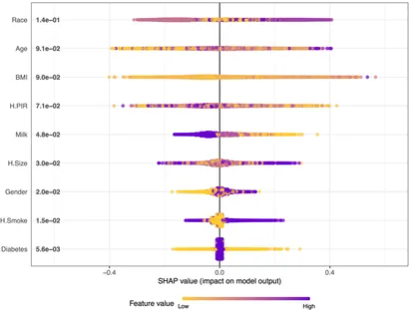
图3展示了XGBoost模型结果的SHAP值摘要图。每个点代表一名患者,X轴上的位置(SHAP值)指示该特征对模型输出的影响,Y轴则显示特征的重要性排序。结果显示,种族、年龄和BMI是影响维生素D缺乏预测的三大重要特征,从而为模型解释提供了依据。
SHAP值提供了对模型内在机制的深入理解,帮助识别出哪些因素对维生素D缺乏的预测最为关键。种族的影响尤为显著,表明不同种族在维生素D合成方面存在差异,提示在进行风险评估时需考虑种族背景。此外,年龄和BMI的影响也强调了健康管理中应关注的目标人群。这种分析不仅丰富了对模型的理解,还为公共卫生政策的制定提供了重要参考。
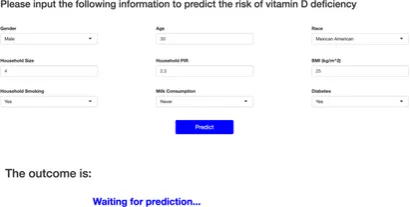
图4展示了基于XGBoost模型构建的在线计算器的界面。该工具通过简单的访谈收集数据,如种族、性别、年龄、家庭规模、收入比、BMI、家庭吸烟情况和牛奶消费等信息,帮助用户快速评估维生素D缺乏的风险。
在线计算器的构建使得模型应用更加便捷,普通用户能够通过简单的询问,获得关于维生素D缺乏风险的及时反馈。这种工具在社区健康管理中具有广泛的应用潜力,能够有效提高维生素D缺乏的筛查率,降低公共卫生开支,同时为高风险人群提供早期干预的机会,促进公众健康。
总结
这篇研究探讨了利用机器学习技术预测维生素D缺乏风险,特别是通过XGBoost算法构建出了一种高效的预测模型。基于2001至2018年间的NHANES数据,研究者成功识别出社区人群中维生素D缺乏的高风险个体。此外,研究中提供的在线计算器极大简化了风险评估过程,允许用户通过简单的访谈获取结果,降低了传统检测的成本和复杂度。这一创新不仅为公共卫生领域提供了新的筛查工具,也为高风险人群的早期干预创造了条件,具有重要的社会意义和应用潜力。





