 量子位 | 公众号 QbitAI
量子位 | 公众号 QbitAI
什么?Kimi底层推理架构刚刚宣布:开!源!了!
你没听错,就是那个承载了Kimi线上80%以上流量的架构。
昨天,月之暗面Kimi联合清华大学等机构,开源了大模型推理架构Mooncake。根据官方介绍,本次开源将采用分阶段的方式:
逐步开源高性能KVCache多级缓存Mooncake Store的实现,同时针对各类推理引擎和底层存储/传输资源进行兼容。其中传输引擎Transfer Engine现在已经在GitHub全球开源。
Mooncake一经开源,已在GitHub狂揽1.7k star。
论文:https://arxiv.org/pdf/2407.00079
开源地址:https://github.com/kvcache-ai/Mooncake
其最终开源目标是,为大模型时代打造一种新型高性能内存语义存储的标准接口,并提供参考实现方案。
月之暗面Kimi工程副总裁许欣然表示:
通过与清华大学MADSys实验室紧密合作,我们共同打造了分离式大模型推理架构Mooncake,实现推理资源的极致优化。
Mooncake不仅提升了Kimi的用户体验,降低了成本,还为处理长文本和高并发需求提供了有效的解决方案。
我们相信,通过与产学研机构开源合作,可以推动整个行业向更高效的推理平台方向发展。
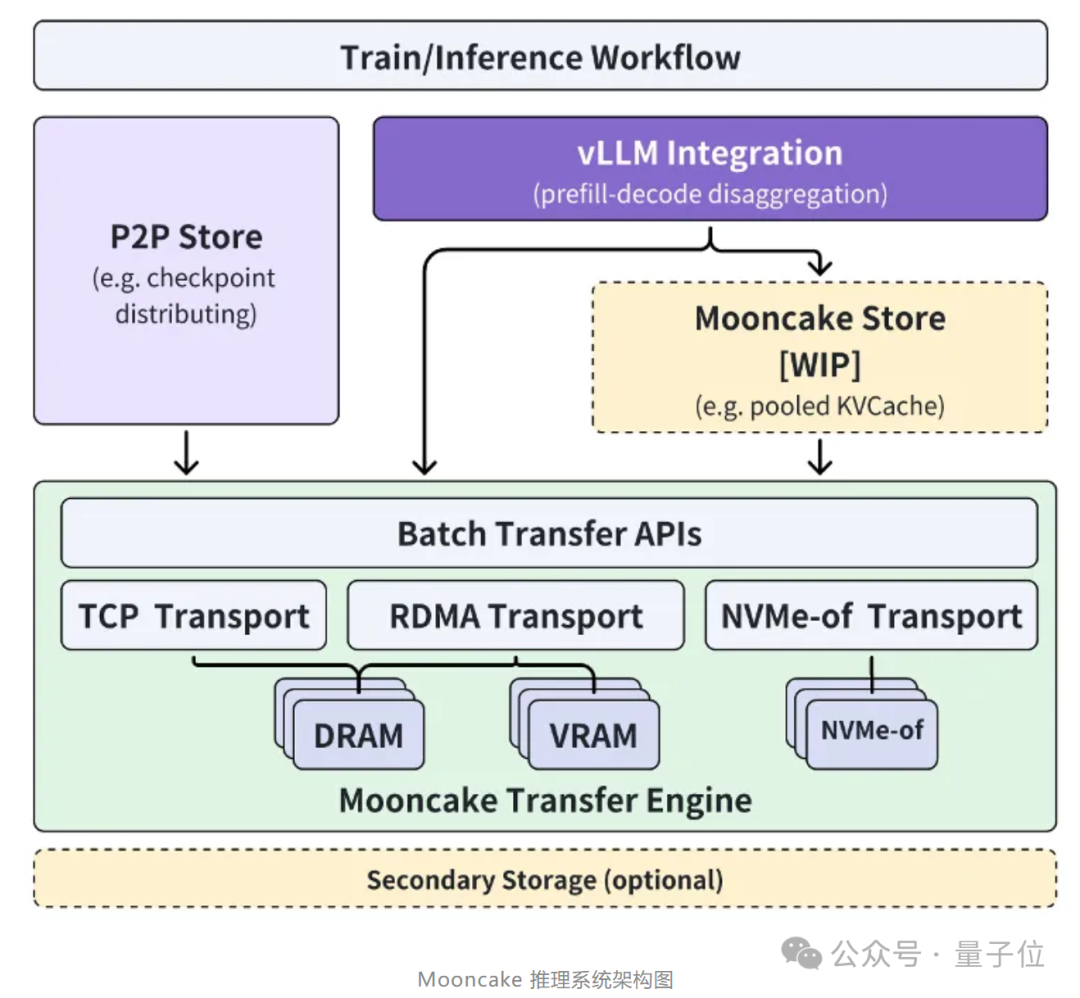
大模型推理架构Mooncake
今年6月,月之暗面和清华大学MADSys实验室联合发布了Kimi底层的Mooncake推理系统设计方案。在这篇名为《Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving》的论文中,作者详细介绍了Mooncake这种系统架构。
该系统基于以KVCache为中心的PD分离和以存换算架构,大幅度提升了推理吞吐。

具体而言,Mooncake采用以KVCache为中心的解耦架构,将预填充集群与解码集群分离,并充分利用GPU集群中未充分利用的CPU、DRAM和SSD资源,实现KVCache的解耦缓存。
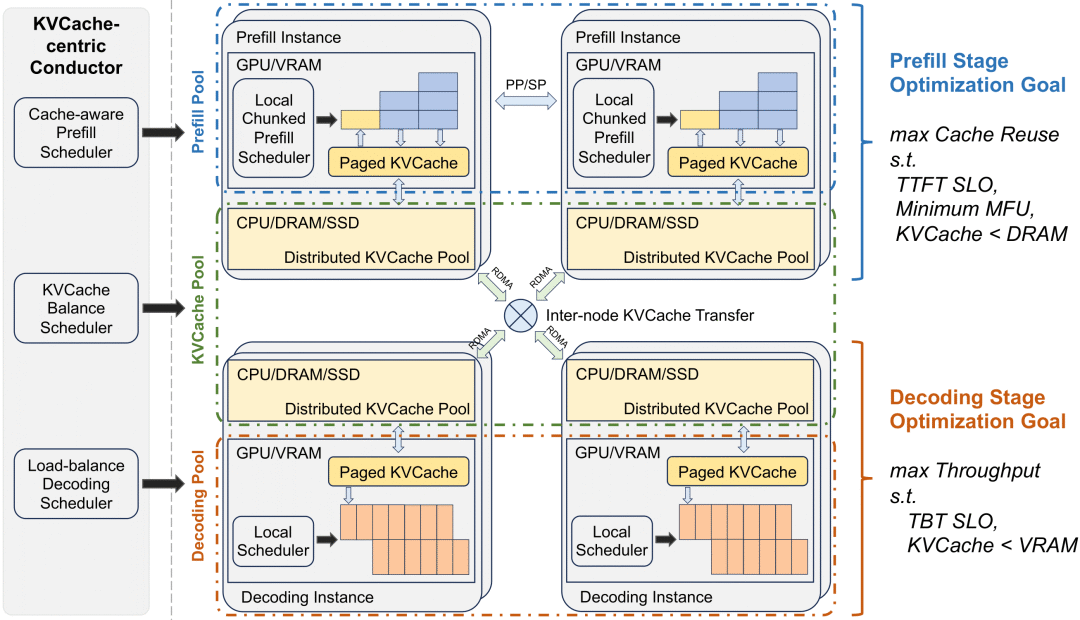
其核心在于以KVCache为中心的调度程序:
在最大化整体有效吞吐量和满足与延迟相关的服务级别目标 (SLO) 要求之间取得平衡
当面对流量高峰期时,Mooncake通过早期拒绝策略和预测未来负载的方法,来处理超载问题。
早期拒绝策略(Early Rejection Policy)
简单说,其核心思想是在请求实际开始处理之前,根据当前系统的负载情况预测是否有足够的资源来处理新的请求。
如果预测结果表明系统资源不足以保证请求的及时处理,系统就会在请求到达之前予以拒绝,从而避免了无效的资源占用和不必要的延迟。
预测未来负载(Predicting Future Load)
在Mooncake中,系统需要能够预测在未来一段时间内的负载情况,以便做出更准确的接受或拒绝请求的决策。
通常来说,这种预测会基于当前的请求模式、系统的资源使用情况以及历史数据等信息。
再通过对信息的进一步分析建模,Mooncake就能够估计接下来的请求处理需求,并据此调整其调度策略。
论文实验结果显示,与基线方法相比,Mooncake在某些模拟场景中可以实现高达525%的吞吐量提升,同时遵守SLO(与延迟相关的服务级别目标)。
在实际工作负载下,Mooncake使Kimi能够处理75%以上的请求。
而且据许欣然在其他场合透露:
而现在,为了进一步加速该技术框架的应用与推广,Kimi联合清华大学等机构共同发布开源项目Mooncake。
参与开源的首批阵容包括:AISoft、阿里云、华为存储、面壁智能、趋境科技等。
可以说,云计算、存储、AI模型玩家等产学研力量都聚齐了。
据悉,Mooncake开源项目从论文延伸,以超大规模KVCache缓存池为中心,通过以存换算的创新理念大幅度减少算力开销,显著提升了推理吞吐量。
目前Mooncake技术框架已正式开源上线,官方还表示:
欢迎更多企业和研究机构加入Mooncake项目共建,共同探索更加高效和先进的模型推理系统架构创新,让基于大模型技术的AI助手等产品,持续惠及更广泛人群。
Whose,一个 Python 的轻量级搜索工具!
浙大 TableGPT2 开源,横扫任务榜,最强表格 AI问世!
李沐重返母校上海交大,这里是演讲全文!附现场视频!
吴恩达在Github开源了翻译智能体,标星4.4K!
Github标星10.2K!抛弃MATLAB,开启可视化巅峰之旅!
GitHub 标星 18.3w,Python必备宝典!
商务合作 | 交流学习 | 送书活动
添加vx:yuliang-bj(备注姓名-单位)
 觉得不错,请点个在看
觉得不错,请点个在看








