轻量级神经网络的进步已经彻底改变了计算机视觉在各种物联网(IoT)应用中的使用,涵盖了远程监控和过程自动化。
然而,对于许多这些应用来说,检测小型物体,这是至关重要的,目前在计算机视觉研究中仍然是一个未探索的领域,尤其是在资源受限的嵌入式设备上,这些设备拥有处理器。
为了解决这一问题,本文提出了一种适应性的分块方法,用于轻量级和节能的目标检测网络,包括YOLO基础模型和流行的更快地找到更多物体(FOMO)网络。
所提出的分块方法可以在低功耗微控制器单元(MCUs)上实现目标检测,同时与大型检测模型相比不妥协准确性。通过将该方法应用于内置机器学习(ML)加速器的基于 RISC-V 的新型MCU上的 FOMO 和 TinyShimyOLO 网络,证明了所提出方法的优势。
大量的实验结果表明,所提出的分块方法在FOMO和TinyShimyOLO网络上的F1分数提高了225%,同时将平均目标计数错误减少了76%(FOMO)和89%(TinyShimyOLO)。
此外,本工作的发现表明,在FOMO网络中使用软F1损失可以作为隐式非最大抑制。
为了评估实际性能,将这些网络部署在 RISC-V 基础的GAP9微控制器上,从 GreenWaves Technologies 公司,展示了所提出的在MCU上使用高分辨率图像进行多个预测,实现检测性能(F1分数58%-95%)、低延迟(0.6ms/推理 - 16.2ms/推理)和节能(31µJ/推理 - 1.27mJ/推理)之间的平衡。
1 Introduction
低功耗物联网(IoT)设备与先进传感器以及尖端机器学习(ML)算法的整合正在推动各行业发生变革,包括健康监测[1],家居自动化[2]和工业过程优化[3]。这些边缘计算设备通过利用设备上的ML算法,提高了数据隐私保护,增强了带宽效率,并实现了成本降低。这些算法在本地处理隐私关键的感知信息,并提取元数据,然后将元数据传输到云进行进一步分析或操作。对于许多场景,精确目标检测[4, 5]是关键应用。目前,最先进的目标检测器通常使用卷积神经网络(CNN)架构来预测图像中的物体位置和类别。值得注意的是,基于 Transformer 的网络架构[7, 10]已经出现,并展示出在提高目标检测系统能力方面具有巨大的潜力。
然而,这些网络虽然具有深度上下文理解,但计算要求非常高,因此需要消耗数百瓦特功率的强效和昂贵硬件,使其不适合大多数IoT处理器。这促使学者们提出使用模型量化方法来实现移动和低功耗嵌入式设备上的微机器学习(TinyML)。虽然轻量级神经网络的进步使得在图像分类等任务上取得了很大的进展[11],最近开始在简化目标检测任务上获得良好的检测精度,但检测小物体仍然是一个挑战,尤其是在内存受限的设备上,如微控制器单元(MCUs)。这些嵌入式处理器的计算预算有限,导致一个图像的执行延迟在几秒钟[21]。
检测图像中小目标的挑战主要归因于这些目标具有有限的像素覆盖,这极大地抑制了目标检测器生成独特特征的能力,这是准确识别的至关重要的一步[21]。高分辨率图像提高了信噪比,然而,具有8位颜色深度和像素分辨率的RGB图像已经超过了低功耗MCU通常可用的的闪存存储。有限的剩余内存限制了可以部署的模型的大小[11]。另一个因素是CNN基础算法中的步进操作导致小目标在特征图中被完全消失。
这篇论文是对作者之前的工作《"增强物联网应用中小型目标检测的轻量级神经网络方法"》中的方法和发现进行全面阐述和扩展。作者之前研究的核心是开发一种自适应分块技术,如图1所示为所提出方法的总览,专门用于增强轻量级神经网络的能力,例如更快地检测更多目标(FOMO)[16],以准确识别小型目标。该技术的有效性通过在低功耗的Sony Spresense MCU平台上的实现进行实证。尽管实现了令人称赞的检测准确性,但该方法受到显着的延迟惩罚。此外,作者之前的调查还揭示了FOMO物体预测能力的一种固有局限性,即分块粒度和输入分辨率的提升在检测性能方面不再产生成比例的改善。
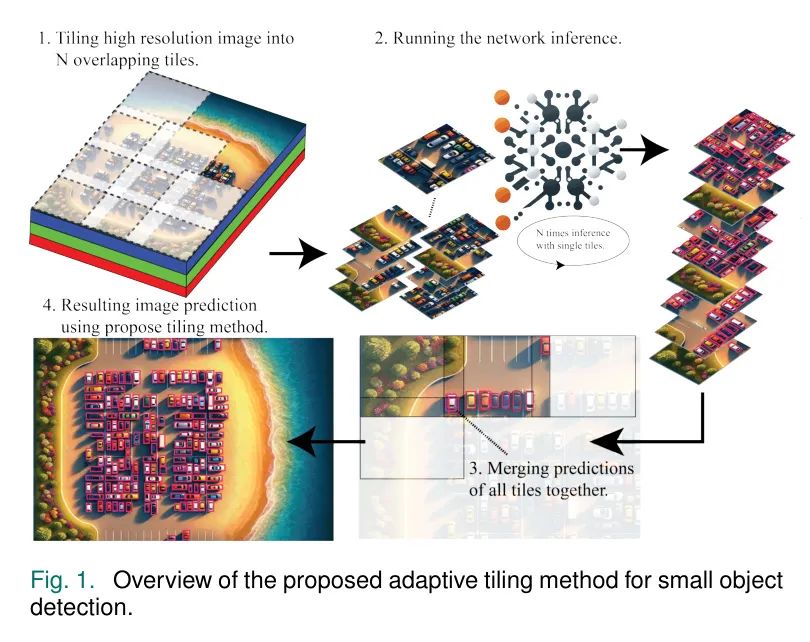
在这些基础见解的基础上,本研究的扩展部分引入了重大进步和新的贡献,具体体现在以下几个方面:
增强方法论深度:本文扩展为引入了自适应镶嵌方法[21]提供深入解释,展示了其在显著提高信噪比的同时,无需相应增加网络输入分辨率的能力。
网络修改和集成:本文详细描述了针对原始FOMO架构所进行的修改,以及与作者的自适应拼图方法相结合时所产生的协同效应。进行了一项消融研究,以证明它们在提高作者之前研究中所设立的 Baseline 之外的目标检测能力方面的作用。
扩展至作者最初发布的范围之外,这项扩展通过以下实验改进,拓宽了作者方法的实际验证:
应用于TinyissimoYOLO:通过将自适应镶嵌技术应用到TinyissimoYOLO网络,相较于CARPK [22]数据集上的最新基准,实现了最先进的检测准确率。这一成就证明了作者的方法在不同网络架构下的通用性和有效性。
在GAP9上部署:FOMO和TinyissimoYOLO网络都在GAP9微控制器(MCU)上部署,这是一种基于 RISC-V 的并行处理器,具有硬件加速器。这个平台实现了最先进的推理延迟,这是在物联网应用中追求高效实时目标检测的一个重要里程碑。
开源代码1:与TinyissimoYOLO一起发布了提出的瓷砖方法的开放式版本。(https://github.com/ETH-PBL/TinyissimoYOLO)
通过这些贡献,本文不仅扩展了在物联网范式下小目标检测的理论与实践理解,还为新发布的低功耗MCU上神经网络的部署设立了新的基准,从而为该领域的未来创新铺平了道路。
2 Related Work
检测小型物体仍然是一个研究挑战,因为从小型物体所覆盖的相对有限的像素中生成特征具有固有的困难。大多数广泛使用的目标检测模型并未针对这一挑战进行优化。表1 显示了像YOLOv4 [23]和Faster R-CNN [25]这样的流行目标检测模型在小型物体上的表现显著较差。这一限制部分可以归因于网络架构。例如,YOLO [27]使用网格方法进行预测,其中位于同一网格单元的小型物体可能不会被正确检测。另一个问题是与用于开发这些模型的训练数据相关。大多数目标检测模型需要大量的训练数据,对于只有有限数据的专用场景构成了挑战。
因此,实践者可能需要依赖可以针对其使用场景进行微调的预训练模型。然而,用于预训练模型的通用训练数据集通常倾向于包含占据图像较大比例的目标[28]。因此,在主要包含小型物体的目标使用场景下,它们的可用性受到限制。
为解决这些问题,所采取的努力可以广泛地分为两类:
一类是试图为给定目标提供更多的信息;
另一类是试图在小型目标上生成更丰富的特征。刘等人[8]的工作是利用CNN的层叠结构在多个尺度上进行预测的最早尝试。他们在其网络的末端添加了多个特征层,这些特征层的分辨率逐渐减小。每个特征层都进行自己的预测,最后,非极大值抑制步骤选择最可能的预测。
然而,在初始特征提取器中发生的下采样限制了该网络检测小型物体的能力。这一局限性在林等人[9]的工作中得到解决,他们提出将早期层的高分辨率特征与后期层的更成熟特征相结合。为此,他们将多个分辨率下的特征图拼接在一起,并采用一个可以接受这种多尺度特征向量作为输入的单一预测器。这些发现决定了本工作的选择,即采用TinyissimoYOLOv1.3[30],这是一个轻量级网络,使用了YOLOv3[31]中引入的检测Head,该检测Head将不同尺度的特征组合在一起。
虽然这些方法试图通过改变网络架构来最大化小目标特征的表达能力,但其他研究行人试图通过增加可用的信息量来达到这个目标。一个明显的途径是增加网络的输入分辨率,这在刘等人[8]的工作中有提及。不幸的是,增加图像分辨率并非总是可行的。许多网络具有固定的输入大小,而增加图像尺寸会极大地增加内存和计算负载。
Cagatay等人[32]提出了一种名为Slicing Aided Hyper Inference的框架,将图像分割成子图像。他们展示了如何使用这个框架来提高现成目标检测器的推理性能,同时在使用框架微调预训练模型时获得更好的结果。他们的方法将输入图像分割成固定数量的小块,并在后处理阶段将每个块的预测与全图像的预测相结合。为了抵消图像分块引入的增加处理时间,Plastiras等人[33]提出了一种选择性分块方法。他们的方法为每个块分配一个重要性分数,对于给定的迭代,只处理具有最高分数的块。受到选择性分块方法启发,之前的工作引入了一种适应性分块方法[21],以最小化推理次数,同时优化目标大小以确保最大的检测准确性。
CNNs的部署在MCU类设备上主要是内存约束问题,需要采用应对_量化技术_的方法[34],以降低随机访问内存(RAM)和闪存(FLASH)的使用,同时保持精度不变[35],_(ii)_减小网络大小,例如FOMO方法[16]或TinyissimoYOLO[12],_(iii)_或者在执行网络前向传播时减少所需的RAM,例如不同版本的MCUNet[14],[15]。
例如PP-PicoDet[36]或NanoDet[37]等目标检测模型具有前景,但它们的最小版本在1MB的FLASH上 barely fit,并且超过了MCU中通常可用的RAM。因此,这些网络在Snapdragon类系统芯片(SoCs)上进行基准测试,这些芯片的功耗处于等待状态。
文献报告了一些用于MCU上的目标检测网络,如XiNet [13]和PhiNet [17],这些网络优化了RAM消耗。然而,这些网络使用了诸如注意力机制或压缩和激励块等层操作,这些操作在商用的MCU内置加速器中并不常见[20]。大多数ML加速器,如实现到Marsellus SoC [38]中的可配置二进制引擎(RBE)加速器,只加速少数简单的层操作,例如3D卷积层。利用这些加速操作,TinyissimoYOLO可以实现与最佳类模型相当的检测精度,同时支持实时推理。
虽然边缘设备上的目标检测领域已经得到了一定程度的探索,尤其是在MCU的有限功耗范围内,但是将小型目标检测器部署在这些设备上仍然是一个相对较少研究的领域。以前的研究主要集中在为边缘部署优化现有神经网络架构,或者减少目标检测算法的计算复杂性。然而,在MCU上检测小型物体的两倍挑战,即需要高检测准确率和低计算开销,至今尚未得到全面解决。
本文做出了几个新颖的贡献,不仅填补了本节中描述的差距,而且在微控制器的推理速度和检测精度方面,也突破了目前的可行性界限:
高速推理:本文扩展展示了使用FOMO网络在低功耗MCU上实现每秒>30帧的推理速度。这一显著成就进一步证实了作者的方法在效率方面的优势,使其在实时应用中具有可行性,在这些应用中,快速目标检测至关重要。
当前最先进的检测准确率:将TinyissimoYOLO网络部署在GAP9 MCU上,本工作实现了小目标检测的当前最先进平均物体误差计数。这一成就是在保持接近3 FPS的运行速度的同时实现的,这在一个资源受限的目标部署平台中是值得注意的成就。
创新解决方案:在MCU上实现小目标检测:本文提出的该方法扩展解决了在MCU上检测小型目标未得到解决的问题。通过优化网络架构和推理流水线,本文扩展提出了一种可行的解决方案,该解决方案满足了边缘应用对高精度和低延迟的严格要求。
3 Method
Detection Networks
3.1.1 Fomo
恐失(Fomo)[16] 是一种轻量级的目标检测网络,它预测目标中心而不是边界框。Fomo 使用 MobileNetV2 [24] 网络的早期层作为特征提取器,从而形成一个 的特征网格,其中 的尺寸取决于特征提取器的深度。在本工作中使用的 Fomo 实现具有三个下采样阶段,导致从输入到输出的整体下采样因子为 8。特征网格随后被输入到一个小的检测Head中,该检测Head通过将属于同一目标的 特征分类并进行聚类来预测目标中心。原始 Fomo 网络,由 Edge Impulse 实现,使用了粗糙的聚类技术,即邻域网格单元上的所有预测都被合并在一起。
该架构有两个主要局限性。首先,它对每个 特征只做出一次预测,与其他单次检测器(如 You Only Look Once,YOLO)不同。这意味着在同一网格单元中定位的小物体将算作一次预测。其次,它无法区分相邻网格单元中预测的附近物体,因为聚类步骤会将它们错误地融合在一起。
根据在FOMO应用中采用对比监测,对标准FOMO实现进行了两项修改。由于图像中的物体与背景的比例可能剧烈变化,因此替换了加权二进制交叉熵损失,采用了由Maiza等人引入的软F1损失[39],无需手动调整每个目标类损失成分的权重。此外,在对比监测中,通常许多车辆都位于非常接近的位置。这使得相邻车辆的预测很可能位于FOMO输出的相邻网格单元中,然后由FOMO融合机制错误地合并。在3.3节中,作者提出了一种最小化不同目标预测意外合并的方法。
3.1.2 TinyissimoYOLO
[21] 中的工作表明,FOMO的检测性能在输入分辨率达到192×192时会停滞。因此,可以合理地假设FOMO的小参数数量是这一限制的原因。本工作通过研究更复杂的网络,扩展了[21]的结果。
微小的YOLOv1.3 [30]是一种目标检测网络,它基于TinyissimoYOLO [12],但使用了YOLOv3的检测Head,使其能够基于提取的多尺度特征预测边界框。由于该网络结构简单且大量使用了3D卷积层,因此可以使用具有ML加速器的SoC进行高度加速,这一点由TinyissimoYOLO的后续出版物所证明 [20]。这种网络预测边界框的能力允许使用更复杂的算法来融合相邻块的预测,这一点将在第3.3节中详细说明。
Adaptive Tiling
为了解决小型物体像素信息不足以及来自FOMO架构的目标大小限制问题,作者提出了一种自适应分块的方法,将图像分割成较小的子图像。这种方法具有多个优点。首先,它增加了物体的相对大小,从而在假设输入分辨率保持不变的情况下提高了信噪比。其次,增加物体的尺寸会降低多个物体位于同一网格单元的概率,这对基于 Anchor 点目标检测器(如FOMO和TinyissimoYOLO)非常重要。作者遵循Akyon等人[32]的工作,将图像分割成重叠块,确保在某一块中仅部分可见的目标在相邻块中完全可见。图2显示了所提出的方法如何将图像分割成较小的块进行单独处理。
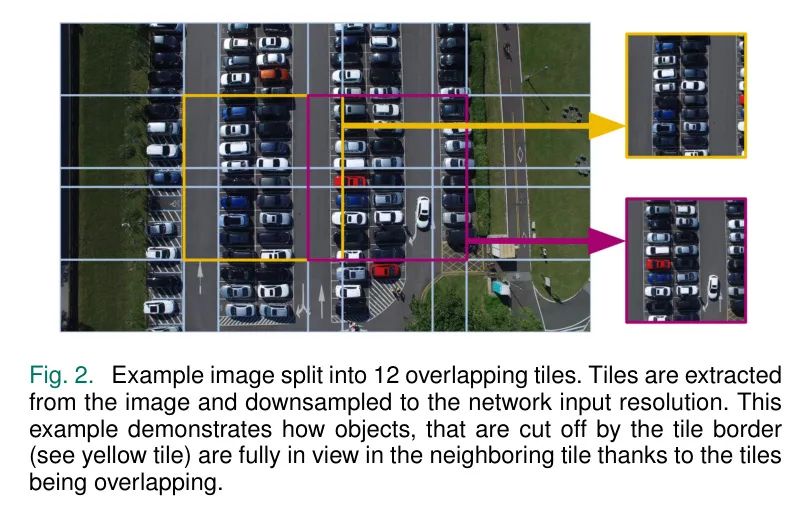
将图像分割成瓷砖进行逐个处理的一个缺点是处理时间的增加,且物体越小,需要使用的瓷砖越多才能获得良好的检测结果。在这项工作中,定义了一个目标物体大小,该大小通过归一化边界框面积(NBA)进行量化,以调整瓷砖的数量。NBA是边界框的像素面积,通过将像素总面积除以像素总面积进行归一化。对于拍摄在物体附近的照片,只需要使用几块瓷砖就能达到目标物体大小,而对于拍摄在物体较远位置的照片,需要使用更多的瓷砖。这样可以在最小化需要处理瓷砖数量的同时,确保最佳可能的检测性能。
为了确保拼贴图像中的目标大小与目标目标大小匹配,作者为每张图像定义了一个正方形拼贴块。
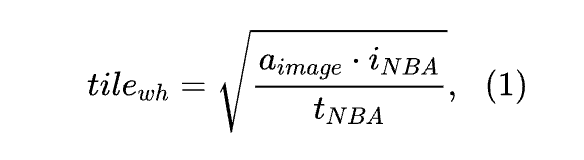
其中 表示瓷砖的宽/高, 是平均物体大小, 是图像中的区域(以像素为单位), 表示目标物体大小。最后,在 x 和 y 方向上的瓷砖数量选择,使得瓷砖重叠至少为平均物体宽/高的 1.5 倍。
在训练过程中,被标注物体的边界框大小被用来计算最优的瓷砖尺寸。在实际应用中,例如使用GPS的高度测量,可以估算物体的尺寸。
Fusing Tiled Predictions
采用重叠的方格会导致网络多次看到相同的图像区域,因此网络可能会对同一物体做出多次预测。为了确保准确的物体数量,来自多个方格的同一物体的预测必须正确融合。这通过比较所有方格预测的交集来实现,但是,实现方式会因网络架构的差异而有所不同。
对于FOMO网络做出的每个预测,都会创建一个“伪”边界框,其大小等于相应的网格单元。当相邻的瓷砖的交并比(IoU)大于特定阈值时,这些网格单元大小的边界框预测会被融合在一起。
微小的YOLO(TinyissimoYOLO)也以网格形式进行预测,但并非预测质心位置,而是预测每个 Anchor 点对应的边界框。人们仍然可以使用IoU指标来确定重叠预测之间的对应关系,然而,当物体在一个瓷砖中只部分可见,而在另一个瓷砖中完全可见时,同一物体的边界框将具有非常不同的尺寸。如图3所示的一个例子可以说明这一点。这个例子表明,即使一个瓷砖的边界框完全重叠于另一个瓷砖中的第二个边界框,IoU也可以很小。这使得在确保同一物体预测融合正确的同时,难以找到一个阈值,以防止附近物体意外融合。
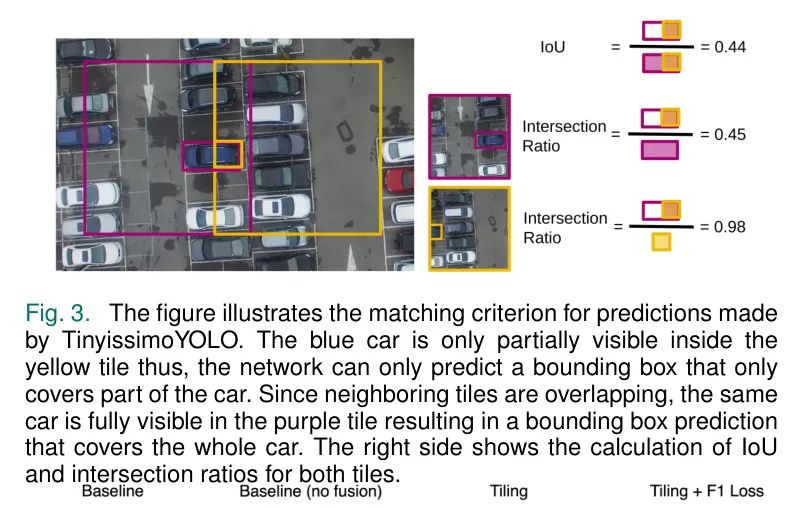
为了解决这个问题,作者采用了一种稍微不同的匹配方法。作者不再基于IoU进行双向匹配,而是使用作者称之为“交点比率”的一向匹配。这个比率对于每个边界框是通过将其交点区域除以另一个边界框的面积来确定的。这种指标的优点是,几乎完全被另一个边界框包围的边界框,其交点比率将接近1。
如果至少有一个边界框的交点比率大于阈值,那么这对边界框就被认为是匹配的。如图3所示,黄色方块只能部分看到物体,因此预测的边界框比紫色方块小,导致IoU小于50%。另一方面,黄色方块的预测交点比率为98%,因此在使用作者的单向匹配时,这两个预测可以被认为是高置信度的匹配。
IV Results
作者评估了标准FOMO实现[16]、作者的FOMO实现[12]以及TinyissimoYOLO [12]在CARPK [22]数据集上的检测性能。
该数据集由无人机在约40米高度飞行,覆盖了四个不同停车场的近1,500张图像,其中包含超过90,000辆汽车。
Experimental Settings
除了将提出的方法与其他在CARPK[22]数据集上的工作进行比较外,作者还评估了由作者提出的瓦片方法的不同配置所带来的小型目标检测性能提升。具体而言,作者用三种不同的输入分辨率以及四个不同的目标NBA值训练FOMO模型,同时用一个输入分辨率训练TinyissimoYOLOv1.3,并用四个更大的目标NBA值训练。在本论文中,作者使用配备了9个 RISC-V 核心的GAP9 MCU进行部署和评估。调查的模型通过使用NNTool2将其量化到Int8精度。NNTool用于优化计算图,进行量化并验证拓扑结构。
使用Autotiler3根据拓扑优化和量化图自动生成C代码。生成的代码用于在设备上执行量化网络。延迟和能量测量通过在GAP9评估套件上部署网络并利用 Nordic Semiconductor 的 Power Profiler Kit 2 进行。将模型部署到GAP9使作者能够观察到提出的瓦片方法以及不同的输入分辨率如何影响到网络的目标物体大小,从而影响检测性能和内存消耗以及延迟。
部署的网络通过参数数量、延迟和推理效率(这描述了设备上计算工作负载的并行化程度)以及根据Giordano等人[40]的建议的每推理能量进行评估和比较。
Fomo
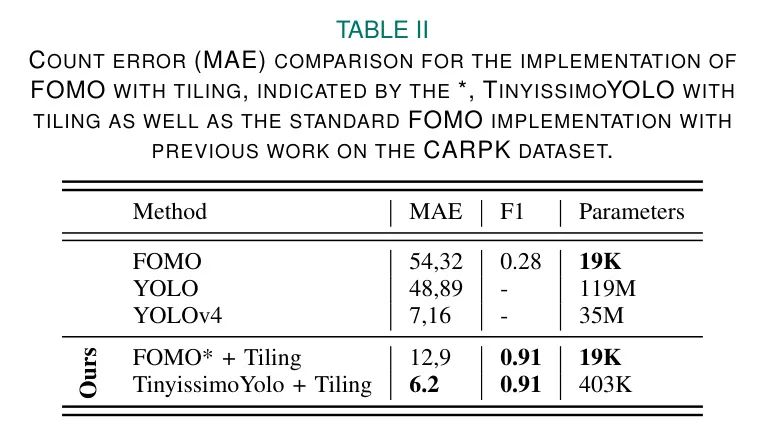
在表2中,作者将使用作者开发的拼图方法在CARPK数据集上与标准FOMO实现以及其他已发布的结果进行了比较。与原始FOMO架构相比,作者的方法在物体计数误差方面减少了76%,F1得分提高了225%。
YOLO的平均平均误差(MAE)来自[22],YOLOv4的值来自[41]。对于YOLO和YOLOv4,作者分别根据[27]和[23]中的实现估计了参数数量。与YOLO[27]相比,作者的FOMO实现(带有拼图)减少了MAE的74%,而YOLOv4[23]实现了85%的减少。然而,YOLO和YOLOv4都不是为MCU设计的,并且不符合大多数低功耗嵌入式设备的内存要求。这清楚地体现在表2中,当比较模型参数数量时。
4.2.1 On Device Performance
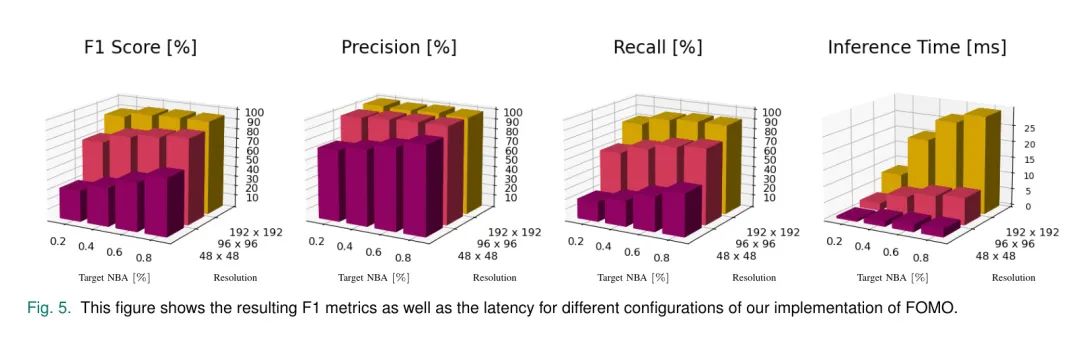
在图5中,作者展示了不同配置下作者方法的目标F1指标和设备端延迟。从图5中的数据可以看出,无论是增加目标NBA(即使用更多瓷砖),还是使用更高的输入分辨率,都可以显著提高F1指标。检测性能的明显改善表明,小型目标检测中的主要障碍确实是小型物体可用的信息相对较少。
这些结果表明,当增加输入分辨率不是选项(因为受内存限制)时,所提出的瓷砖方法是一种有效的替代方法,可以提高小型物体的信噪比,从而提高检测性能。作者还可以在这些结果中看到瓷砖方法带来的额外延迟。例如,达到目标NBA的0.8%需要比目标NBA的0.2%多3.66倍的瓷砖,这导致在网络输入分辨率为192x192的全图像处理过程中,延迟从8.0ms增加到30.0ms。
TinyissimoYOLO
如图5所示,本扩展的前期工作以及可以看到,FOMO的检测性能在目标NBA为0.8%,输入分辨率为192×192时停滞不前。这种停滞可以归因于FOMO网络中参数数量极低,限制了其预测能力。因此,作者进行了使用TinyissimoYOLOv1.3 [30]网络与作者的瓷砖方法相结合的实验。这个网络比之前的大得多,因此可以进行边界框预测,而不仅仅是预测质心。
在表4中,作者报告了将Tiling方法与TinyissimoYOLOv1.3结合使用时,针对不同目标物体大小的结果。使用目标NBA为0.8%,即在精确率和召回率为93%和46%时,性能达到停滞,此时目标计数误差为53.6,明显优于FOMO的性能。然而,与FOMO不同,将目标物体大小增加至0.8%以上,将带来显著的改进。
当目标NBA为4%时,最佳FOMO模型的F1得分与匹配,同时实现了目标计数误差为6.2,相较于作者最佳FOMO网络实现了52%的降低。这甚至超过了大规模模型如YOLOv4 [23]的表现,如表2所示。
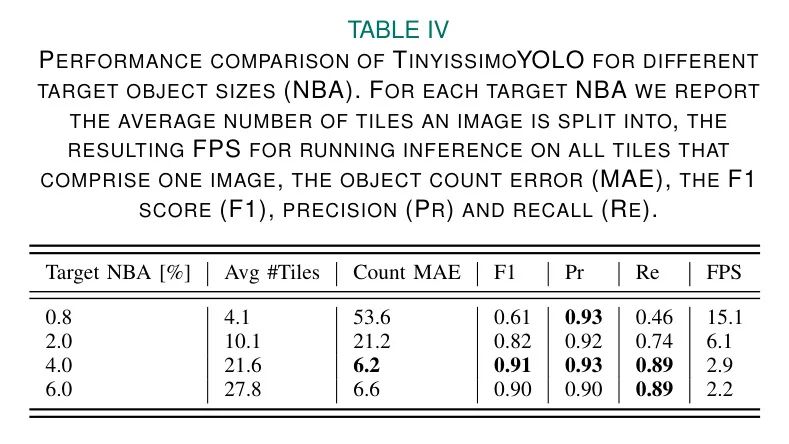
表4的最后一行说明了使用目标NBA为6%时获得的检测结果,除召回外,所有指标均略有下降。当目标NBA为6%时,图像平均分为近30个块,导致许多汽车被多个块边界吸引,从而降低了检测性能。因此,作者认为这代表了在将物体尺寸增加的好处与被块边界交叉的许多物体相抵消时的实际极限。
Iii-C1 On Device Performance
通过在GAP9的NE16加速器上部署Int8量化FOMO网络和TinyissimoYOLO,实现了实时推理。图6比较了部署网络在III节描述的指标方面的差异。在图6a)中可以看出,与实现的FOMO网络相比,TinyissimoYOLO大约大21倍。然而,GAP9将TinyissimoYOLOv1.3的工作负载并行化5倍优于FOMO的工作负载,参见图6c),导致比FOMO大21倍的网络执行时间增加了2.2倍。这种差异可以解释为NE16加速器特别加速了3D卷积,这是TinyissimoYOLOv1.3网络的核心层。由于加速器的能效,在GAP9上运行的TinyissimoYOLOv1.3的能量消耗仅比FOMO增加2.7倍,如图6d)所示。
Ablation
除了增加自适应分块步骤外,作者对标准FOMO实现进行了两个修改,如第三部分A1节所述。
这些修改包括:(1)移除融合步骤,(2)在训练过程中集成软F1损失。在表3中,作者展示了这些修改对物体计数误差以及F1指标的影响。此比较的基准是标准FOMO实现,作者使用所有网络的输入分辨率均为192×192。
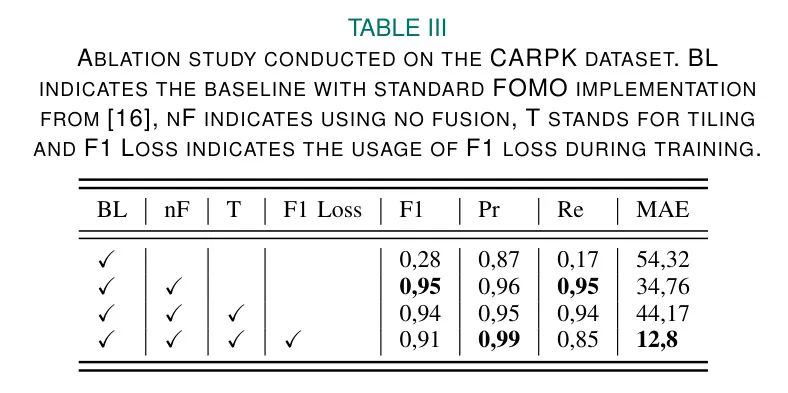
图4比较了所有网络对于同一输入图像的输出。图4a) 突出了FOMO融合方法带来的负面影响。在这个场景中,车辆被紧密地停在一起,以至于相邻车辆的边界框甚至接触在一起。这意味着大多数车辆位于FOMO特征网格的相邻网格单元中,这导致FOMO错误地将许多预测融合成跨多个车辆的大边界框。如表3所示,去掉这个融合步骤可以显著提高召回率以及目标计数误差。这些结果在图4b)中得到了视觉确认,可以明显看到去掉这个融合步骤大大减少了假阴性数量。

图4c)说明了提出的镶嵌方法如何既增加了FOMO预测网格单元的数量,又减少了网格单元的大小。这个过程减少了同一网格单元被多个车辆覆盖的可能性,同时增加了同一辆车被多个网格单元覆盖的可能性。在III-A1节中描述的融合方法能够融合重叠的预测,但在不重叠时,它不能将属于同一辆车的预测进行融合,导致目标计数过多。这就是为什么表3中的目标计数变得更糟,而F1指标保持相似水平的原因。
最后,图4d)显示了使用软F1损失进行训练的效果。使用这种损失,网络被鼓励在单个目标上只进行一次预测,即使它被多个网格单元覆盖。这种看似“隐式”的非极大值抑制大大减少了每个目标的重复预测,从而导致了目标计数误差的重大降低。与标准FOMO实现相比,作者实现了F1分数增加225%,目标计数误差减少76%。
V Conclusion
本文通过将作者之前提出的自适应镶嵌方法应用于最新的TinyissimoYOLOv1.3网络,扩展了该方法。TinyissimoYOLOv1.3生成的边界框预测可以被自适应镶嵌方法智能地融合相邻瓷砖的预测。
新颖的瓷砖融合算法将之前实现的平均物体数量误差从12.9 MAE降低到6.2 MAE,在作者的FOMO实现中,实现了在CARPK数据集[22]上的最先进检测精度。
本工作在基于_RISC-V_的GAP9 MCU上进行了边缘部署,该MCU内置了来自 GreenWaves Technologies_的ML加速器。
FOMO的最佳实现可以在单个瓷砖上运行推理,耗时7.31 ms,从而在33.4 FPS的全图像上预测物体位置,而TinyissimoYOLOv1.3每个瓷砖的推理时间为16.2 ms,在全图像上的预测速度为2.8 FPS。
作者展示了如何使用提出的镶嵌方法实现高检测性能,与CARPK数据集[22]上的最先进的大型网络相媲美,同时满足MCU严格的低内存和低功耗要求。这些结果是向MCU实时小目标检测迈出的重大一步。
参考文献
[0]. DSORT-MCU: Detecting Small Objects in Real-Time on Microcontroller Units.










