核心概念
Cluster:集群,由一个或多个 Elasticsearch 节点组成。
Node:节点,组成 Elasticsearch 集群的服务单元,同一个集群内节点的名字不能重复。通常在一个节点上分配一个或者多个分片。
Shards:分片,当索引上的数据量太大的时候,我们通常会将一个索引上的数据进行水平拆分,拆分出来的每个数据库叫作一个分片。
在一个多分片的索引中写入数据时,通过路由来确定具体写入那一个分片中,所以在创建索引时需要指定分片的数量,并且分片的数量一旦确定就不能更改。
分片后的索引带来了规模上(数据水平切分)和性能上(并行执行)的提升。每个分片都是 Luence 中的一个索引文件,每个分片必须有一个主分片和零到多个副本分片。
Replicas:备份也叫作副本,是指对主分片的备份。主分片和备份分片都可以对外提供查询服务,写操作时先在主分片上完成,然后分发到备份上。
当主分片不可用时,会在备份的分片中选举出一个作为主分片,所以备份不仅可以提升系统的高可用性能,还可以提升搜索时的并发性能。但是若副本太多的话,在写操作时会增加数据同步的负担。
Index:索引,由一个和多个分片组成,通过索引的名字在集群内进行唯一标识。
Type:类别,指索引内部的逻辑分区,通过 Type 的名字在索引内进行唯一标识。在查询时如果没有该值,则表示在整个索引中查询。
Document:文档,索引中的每一条数据叫作一个文档,类似于关系型数据库中的一条数据通过 _id 在 Type 内进行唯一标识。
Settings:对集群中索引的定义,比如一个索引默认的分片数、副本数等信息。
Mapping:类似于关系型数据库中的表结构信息,用于定义索引中字段(Field)的存储类型、分词方式、是否存储等信息。Elasticsearch 中的 Mapping 是可以动态识别的。
如果没有特殊需求,则不需要手动创建 Mapping,因为 Elasticsearch 会自动根据数据格式识别它的类型,但是当需要对某些字段添加特殊属性(比如:定义使用其他分词器、是否分词、是否存储等)时,就需要手动设置 Mapping 了。一个索引的 Mapping 一旦创建,若已经存储了数据,就不可修改了。
Analyzer:字段的分词方式的定义。一个 Analyzer 通常由一个 Tokenizer、零到多个 Filter 组成。
比如默认的标准 Analyzer 包含一个标准的 Tokenizer 和三个 Filter:Standard Token Filter、Lower Case Token Filter、Stop Token Filter。
集群节点
下面简单介绍下部署高可用的ES集群时,各个节点的职责:
master节点
也叫主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch 中的主节点的工作量相对较轻。
data节点
数据节点,负责数据的存储和相关具体操作,比如索引数据的创建、修改、删除、搜索、聚合。所以数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统 CPU、Memory 和 I/O 的性能消耗都很大。
通常随着集群的扩大,需要增加更多的数据节点来提高可用性。通过在配置文件中设置 node.data=true 来设置该节点成为数据节点。
协调节点
协调节点,是一种角色,而不是真实的 Elasticsearch 的节点,我们没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点都可以充当协调节点的角色。
当一个节点 A 收到用户的查询请求后,会把查询语句分发到其他的节点,然后合并各个节点返回的查询结果,最好返回一个完整的数据集给用户。
在这个过程中,节点 A 扮演的就是协调节点的角色。由此可见,协调节点会对 CPU、Memory 和 I/O 要求比较高
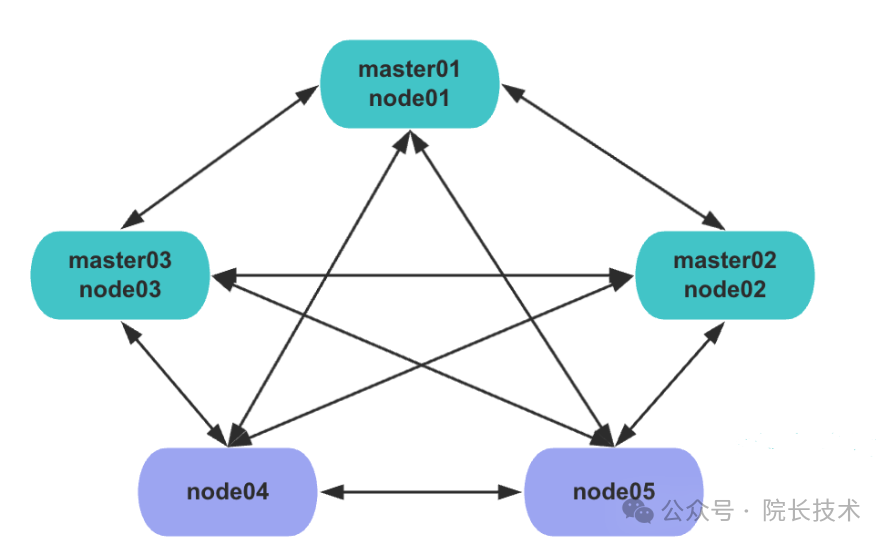
部署架构
这里,我们部署5节点集群时,规划部署架构图可以如下所示,协调节点可以配置为2个即可: