深度学习模型就像是处理数据的筛子,包含一系列越来越精细的数据过滤器(也就是层)。每一层都致力于从数据中捕捉有用的信息,并将这些信息传递给下一层,以便进一步的处理和表示。它通过一系列层层相连的数据过滤器(即层layer),逐步对输入数据进行处理和精炼,从而实现渐进式的数据蒸馏(Data Distillation)。数据蒸馏通常关注于数据的处理和优化,旨在从原始数据集中提取出更具代表性和有用性的数据子集;知识蒸馏则是一种模型压缩和知识迁移的方法,旨在将大型教师模型中的知识转移到小型学生模型中。数据蒸馏(Data Distillation)是什么?
数据蒸馏通常关注于数据的处理和优化,旨在从原始数据集中提取出更具代表性和有用性的数据子集。原始数据集:包含大量的、可能包含冗余和噪声的数据。
数据预处理:对原始数据进行清洗、去噪等处理,以提高数据质量。
特征提取:从数据中提取出关键特征,这些特征能够反映数据的本质属性。
数据降维:通过减少数据的维度,去除冗余信息,得到更为简洁的数据集。
精炼数据集:经过上述步骤处理后的数据集,具有更高的质量和代表。
在深度学习中,数据蒸馏通常是通过逐层过滤和提取特征来实现的。每一层都会对数据进行一定的变换和处理,使其更加接近最终的目标表示。
“数据蒸馏是一个数据处理与优化技术,它旨在从包含大量可能冗余和噪声的原始数据集中,通过一系列步骤如数据预处理、特征提取、数据降维等,提炼出一个高质量、低冗余且高度代表性的精炼数据集。”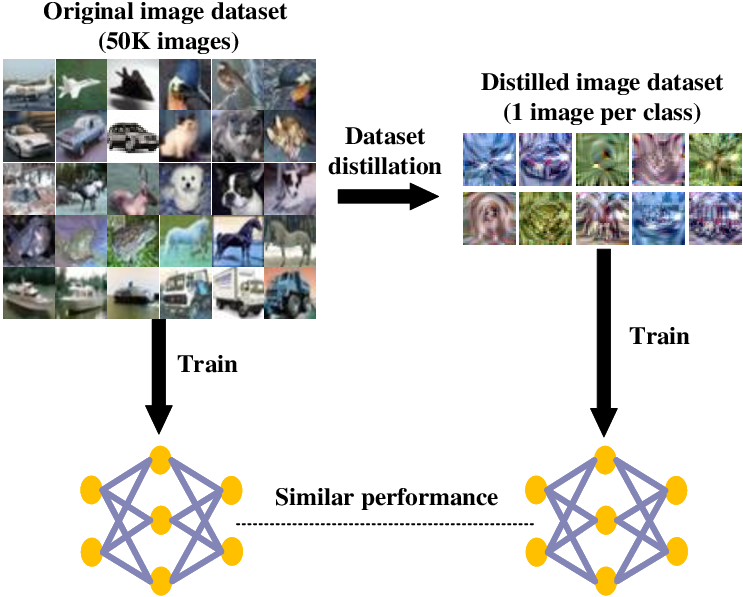
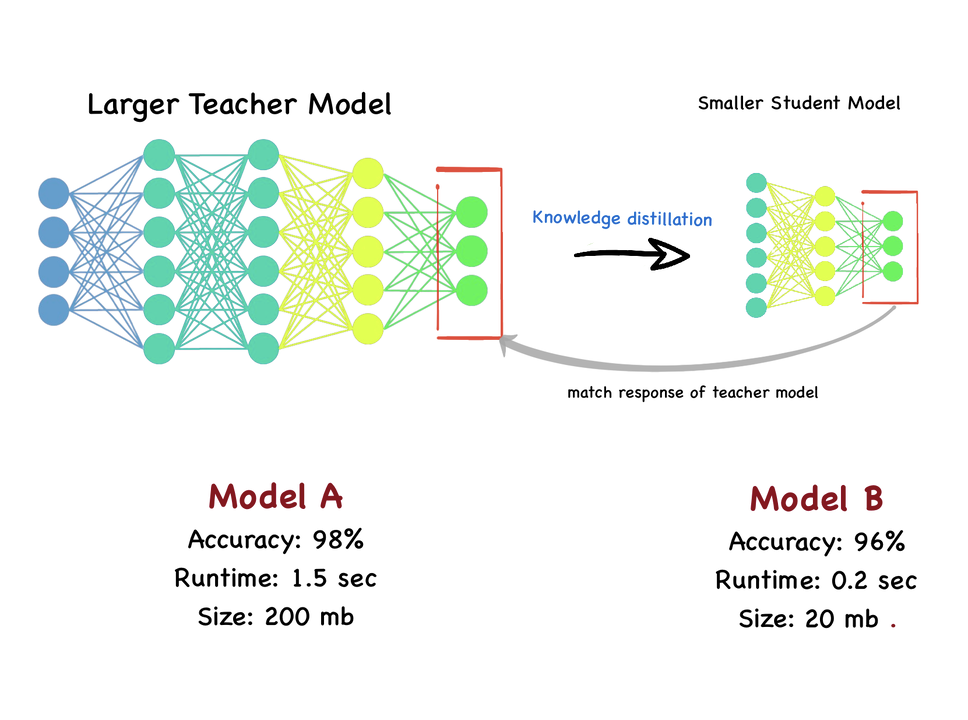
知识蒸馏(Knowledge Distillation)是什么?知识蒸馏则是一种模型压缩和知识迁移的方法,旨在将大型教师模型中的知识转移到小型学生模型中。教师模型(已训练):一个高精度、但可能较为复杂的大型模型。
提取知识:从教师模型的输出(如概率分布、中间特征等)中提取出有用的知识。
学生模型(待训练):一个轻量化、但性能可能较低的小型模型。
蒸馏训练:利用教师模型提取出的知识,作为学生模型的训练目标进行训练。
精炼学生模型:经过蒸馏训练后的学生模型,能够学习到教师模型的泛化能力,从而达到或接近教师模型的性能。
知识蒸馏从多个已经训练好的大型模型中,将知识转移给一个轻量级的模型。它主要关注于模型之间的知识传递,通过利用教师模型的输出(如概率分布或中间特征)作为软目标,来指导学生模型的训练。
“知识蒸馏是一种模型压缩技术,旨在将大型、高精度教师模型中的关键知识提炼并传递给轻量化学生模型。通过这一过程,学生模型能在保持低计算成本的同时,学习到教师模型的泛化能力,实现性能的大幅提升,接近教师模型的性能水平。
”