
随着互联网业务的快速发展,日志数据量日益庞大,传统的日志处理方式面临着成本高、扩展性差等问题。为了应对这一挑战,越来越多的企业开始转向更先进的解决方案——阿里云 Elasticsearch Serverless 。
本文将探讨在日志场景下,使用阿里云 Elasticsearch Serverless 相较于基于 ECS 自建 Elasticsearch 集群的成本与性能优势,展示如何通过 Serverless 架构实现高达 70% 以上的成本节约。

特性对比
传统方案:基于 ECS 自建 Elasticsearch 集群
资源利用率低:在非高峰时段,可能会出现资源浪费;而在高峰期,则可能出现资源不足的问题。
维护成本高:除了硬件成本,还需投入大量的人力资源进行集群的日常运维,包括集群监控、数据备份、安全防护、版本升级等。
扩展性差:面对突发流量或数据量激增时,通常需要手动调整集群规模,这不仅耗时且存在一定的风险。
阿里云 Elasticsearch Serverless 方案
按需付费:仅需为实际使用的资源支付费用,无需预购大量固定资源,有效降低了初期投入成本。
自动扩缩容:根据业务需求自动调整计算与存储资源,确保服务稳定的同时避免了资源浪费。
免运维:阿里云负责底层基础设施的管理和维护,用户可以专注于业务逻辑的开发,无需担心复杂的运维工作。

场景模拟
本文将通过真实的日志业务数据,进行一天的日志写入场景模拟:
1、集团内某应用对应的业务曲线,压力曲线如下:(每日 12~13、22~23点高峰以每日为周期规律),写入用量:1.2k~5.4K 数据级 qps 的单 bulk 3MB 写入,不进行查询;

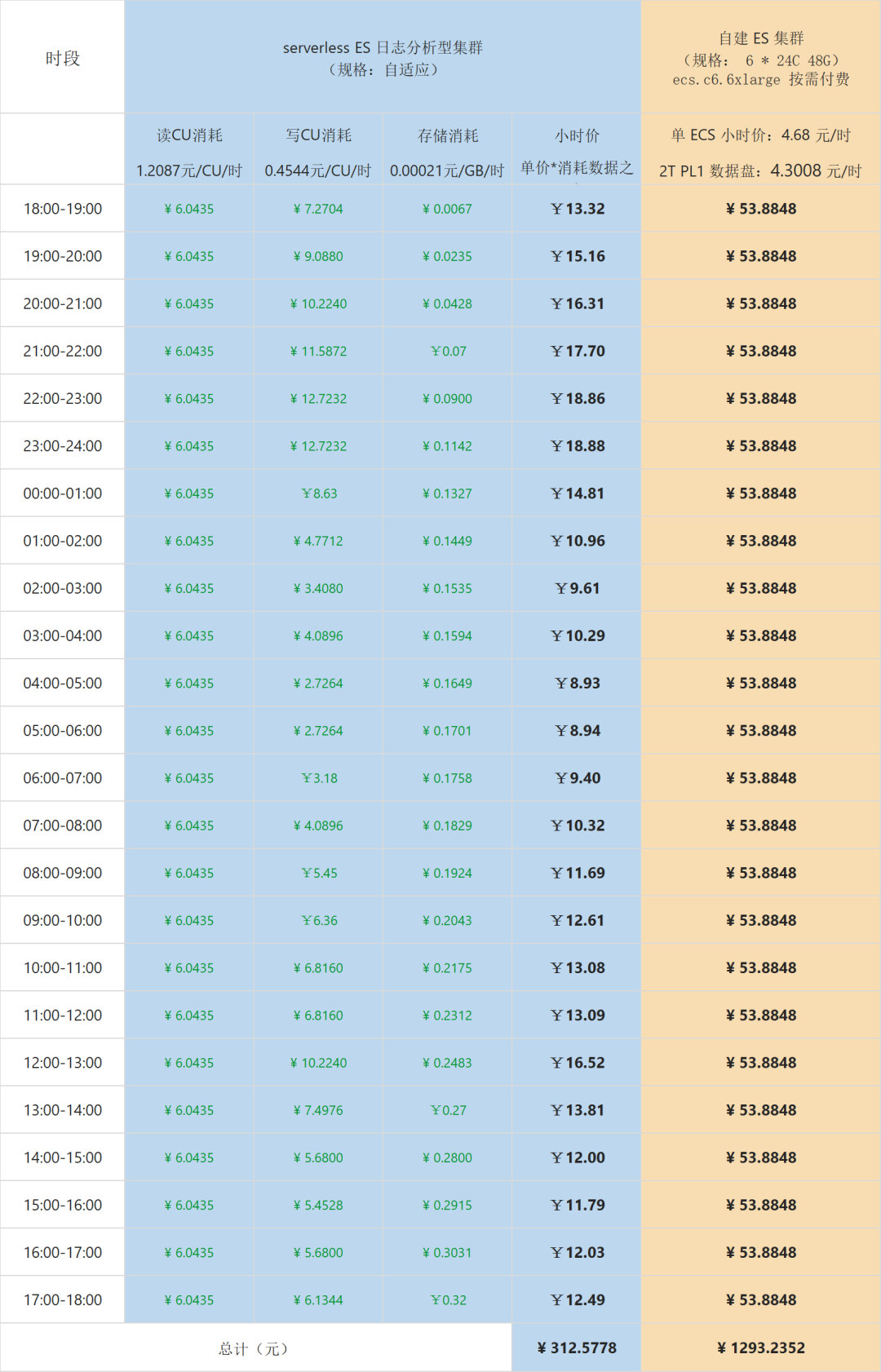
根据上述业务体量,如果通过基于 ECS 自建,按照 CPU 水位上限取 70%以上条件下,选型规格 ECS:24C48G/数据盘:2048 GiB ESSD PL1(50000 IOPS) 云盘,单小时价格 ECS:¥ 4.68/数据盘:¥4.3008(系统盘、LB 等在此不做计入), 6 节点 ES 自建集群单日价格:24*6*(4.68+4.3008)=1293.2352。
若需对应其他规格,请自行计算费用比较;
ESSD PL0 承接以上写入吞吐有瓶颈,会导致自建集群在高压下写入队列堆积请求拒绝。
以下为 PL1 云盘的吞吐监控:

2、当日自建 ES 所在某 ECS 负载如下:

3、现将同样的业务数据接入到 Elasticsearch Serverless 应用中,请求监控数据如下:

性能相比自建更稳定
下图为客户端写入请求指标图
相同 qps、吞吐下,自建 ES 的请求响应即使在低压时也存在上下波动、不稳定的情况;
22:30 写入压力到高峰时,自建 ES RT 上涨明显;Serverless ES 几乎不受影响;
高压下自建集群出现请求失败情况,原因为写入线程池队列满集群拒绝新请求;

根据实际的业务请求,Serverless 应用能做到资源规划,贴合使用曲线
日志分析型集群主要体现在索引主分片数变化:

上图可见:
1、【point 1】在水位下降后会保持一段时间的高主分片数,原因是主分片数不影响资源消耗,预防突发流量,等一段时间后会降至这一段时间判断可降的最低值;
2、【point 2】在水位高于当前已有主分片数时,若在可控范围内,则会等一定时间后升高至这一段时间判断的所需值;
3、【point 3】若水位超出可控范围,则会加快分片数升高的速度;
预期主分片数:系统对当前写入水位做出的主分片建议数
当前主分片数:当前正在写入的索引主分片数
存储数据压缩率相比自建有显著提升,进一步节省了存储成本 80% 以上

以上每日数据量总额达百亿级。可见,该数据集在 Serverless 日志分析型集群总存储空间占比约为自建 ES 集群的六分之一。
成本相比自建得到显著降低 70% 以上
按照 Serverless 日志分析型应用的收费标准,每小时收费 CU 统计如下:
该场景测试未发起查询压力,Serverless 应用会默认按 5CU 查询进行最低查询资源计费
等比大流量估算
以上为单日写入统计,日常场景会考虑长期数据存储如 3 天热数据 14 天冷数据存储等。结合此特点,Serverless成本仍有较大的压缩空间。而根据冷热存储大数据计费估算,ES Serverless 相对于 ES 自建节省约为 88.6%。

如何开通 Elasticsearch Serverless 服务
Step 1:开通服务
第一次使用 ES Serverless服务时需要开通服务。
1、登录 Elasticsearch Serverless 服务控制;
2、在 ES Serverless 服务页面,单击立即开通;

3、在服务开通页面,选中服务协议,单击立即开通,根据页面提示开通 ES Serverless服务。
Step 2:创建应用
1、进入创建 Serverless 应用的页面;

2、配置应用的基本信息;
3、配置应用的访问设置;
说明:配置应用公网访问或私网访问,请参见配置 Serverless 应用公网或私网访问。
4、输入用户密码,登录 Kibana 时需要。
5、单击立即创建。
您可以在应用管理页面查看已创建的应用列表。等待应用状态变为运行中,即创建应用成功,然后可根据个人需求,尝试体验更多功能。
立即使用 Elasticsearch Serverless,成本节省高达 70% 以上!
轻松快速搭建 AI 搜索,助您高效搜索 Web 应用数据,提升您的业务效率!最低 59 元,欢迎点击【阅读原文】前往体验!







