论文介绍
题目:Remote Sensing Spatio-Temporal Vision-Language Models: A Comprehensive Survey
论文:https://arxiv.org/abs/2412.02573
Github仓库:https://github.com/Chen-Yang-Liu/Awesome-RS-SpatioTemporal-VLMs
年份:2025
单位:北京航空航天大学,内蒙古大学
注: 本篇由论文原作者审阅
介绍
文章首先介绍遥感多时相图像解译的重要性,指出传统的二值或语义变化检测难以提供人类可读的语义信息。文章指出遥感时空视觉语言模型(RS-STVLMs)通过融合图像与语言,实现对变化的语义解释与互动问答,为遥感时空理解开辟了新路径。
文章章节
1. Introduction
引言
2. Evolution of Spatio-Temporal Vision-Language Models
时空视觉语言模型的发展
3. Key Technologies in Spatio-Temporal Vision-Language Models
时空视觉语言模型的关键技术
4. Large Language Models Meet Temporal Images
大语言模型与时序图像的融合
5. Evaluation Metrics and Datasets
评估指标与数据集
6. Future Prospects and Discussion
未来展望与讨论
7. Conclusion
结论
时空视觉语言模型的发展
1 从视觉变化检测到时空视觉语言理解(From Visual Change Detection to Spatio-Temporal Vision-Language Understanding)
(1) 遥感变化检测(Remote Sensing Change Detection)
(2) 遥感时空视觉语言任务(Remote Sensing Spatio-Temporal Vision-Language Tasks)
2 遥感时空视觉语言模型方法(Remote Sensing Spatio-Temporal Vision-Language Models)
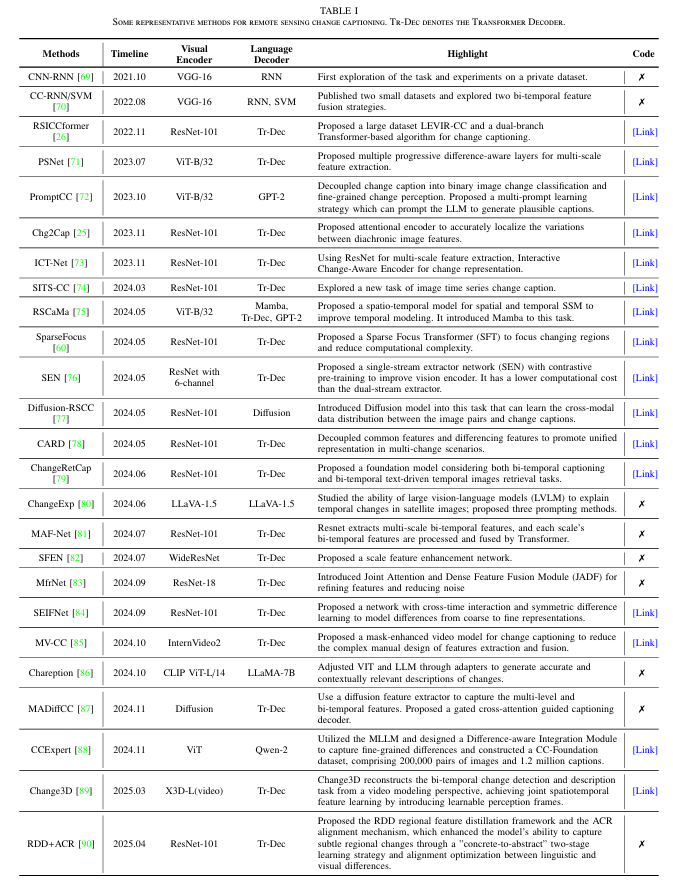
(1)变化描述(Change Captioning)
(2) 变化检测与描述的多任务学习(Multi-task Learning of Change Detection and Change Captioning)
将变化掩膜预测与语言描述统一在同一模型中,提高效率并相互促进。
代表性方法如Change-Agent,采用共享编码器+双分支结构。
关键挑战在于:如何平衡两个任务的训练,常用策略包括动态损失加权、梯度自适应等。
也有部分研究提出“反向优化”,即利用检测结果辅助描述精度,提升对小目标或暗光条件下的表现。
(3) 变化问答(Change Question Answering)
(4)文本驱动的时序图像检索(Text-driven Temporal Image Retrieval)
输入为一段描述某类变化的文字,输出为最相关的图像对(如“房屋被淹没”对应洪水前后图像)。
实现方式通常为:图文特征投影到同一多模态空间,使用对比学习进行相似度优化。
面临挑战如“假负样本干扰”,一些研究提出False Negative Elimination等机制加以解决。
(5) 变化定位(Change Grounding)
给定语言指令,模型输出空间位置(如掩膜或框)定位出所指变化区域。
方法通常结合LLM与视觉特征,对时序图像进行联合编码,并生成空间输出。
掩膜输出更精细,框输出更直观,典型模型包括VisTA、RSUniVLM等。
(6) 其他任务:文本驱动图像生成与时序表达定位(Others: Generation & Temporal Referring)
文本驱动图像生成:用户输入“森林逐渐变为城市”,模型生成一系列遥感图像;
时序表达定位:判断描述中“某个变化”发生在哪一时相的图像中;
这些新任务尚处于探索阶段,但展示出RS-STVLM的巨大潜力。
![]()
![]()
![]()
![]()
时空视觉语言模型的关键技术
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 本章系统总结了构建遥感时空视觉语言模型(RS-STVLMs)中涉及的关键技术模块,横跨图像编码、时空融合、语言建模、模态交互与语言生成,是支撑多任务实现的核心技术框架。
本章系统总结了构建遥感时空视觉语言模型(RS-STVLMs)中涉及的关键技术模块,横跨图像编码、时空融合、语言建模、模态交互与语言生成,是支撑多任务实现的核心技术框架。
1 模型基础构建块(Fundamental Building Blocks)
构建STVLMs常用的三种模型架构
LSTM(长短期记忆网络)
Transformer
Mamba
2 关键模块拆解(Key Modules of RS-STVLMs)
(1) 图像时序编码(Temporal Image Encoding)
目标是提取图像对或图像序列的表征。
方法包括:
CNN提取器:如ResNet、UNet、Siamese结构;
Transformer结构:如Vision Transformer、Swin Transformer;
时序编码器:引入3D CNN、时空Transformer、ConvLSTM等建模序列动态;
预训练视觉编码器:如CLIP、DINO、SAM可迁移至遥感场景。
一些方法还通过多尺度设计、残差连接增强特征感知能力。
(2) 时空特征融合(Spatio-Temporal Feature Fusion)
关键在于如何将不同时间点的图像特征有效对齐与组合,建模变化。
主要策略包括:
(3) 语言编码(Language Encoding)
目标是将文本输入编码为可用于交互的语言特征。
常用语言模型包括:
当前趋势是借助开源LLM(如LLaMA、ChatGLM)直接处理多样化文本指令。
(4) 图文交互机制(Vision-Language Interaction)
该模块是模型“融合语言与视觉”的关键。
技术路径大致分为:
早期融合(Early Fusion):视觉和语言在输入前或初期融合,简单直接;
晚期融合(Late Fusion):各自提取后独立处理,再进行浅层融合;
中间融合(Deep Fusion):常用多模态注意力机制,如Cross-Attention、多层Transformer等;
更复杂的方法如VL-Transformer、多头互注意力等,已成为主流架构;
新兴趋势也引入了 Prompt融合(如PromptCC)和 Adapter注入机制,提升参数效率与任务迁移能力。
(5) 语言生成模块(Language Generation)
用于生成描述、回答等自然语言输出,是最终呈现模型“理解能力”的关键。
主要方法包括:
语言模型与时序遥感图像的结合
本章探讨了如何将大语言模型(LLMs)与遥感图像,尤其是多时相图像结合,推动遥感视觉语言模型能力升级。内容主要围绕模型发展、调优技术、任务适配、基础模型构建与智能体应用等展开。
1 大语言模型的演化(The Evolution of Large Language Models)
2 高效的参数调优技术(Efficient Parameter Tuning Methods)
为应对LLM参数庞大、训练成本高的问题,介绍了一些轻量化的微调技术:
Prompt Tuning / Prompt Learning:只调整输入提示词,主模型参数保持不变;
Adapter / Prefix Tuning:插入小模块,冻结主模型,仅微调部分参数;
LoRA(Low-Rank Adaptation):通过低秩矩阵重构权重变化,兼顾精度与效率;
这些技术为RS-STVLMs迁移到特定任务提供了可行途径。
3 大语言模型驱动的任务特定模型(LLM-driven Task-Specific Models)
本节介绍如何使用LLM构建特定任务的遥感模型,典型例子包括:
PromptCC:利用prompt将图像特征转化为语言提示,指导LLM生成变化描述;
Semantic-CC:通过语义标签增强生成内容的细粒度;
KCFI:引入知识增强的变化解释模块;
ChangeChat / CDChat:结合对话式LLM与变化检测模块,实现交互问答;
这些方法通过“视觉+语言+指令”融合,实现了从描述到问答的语义推理升级。
4 统一的遥感时空视觉语言基础模型(Unified Foundation Models for RS-STVLMs)
统一的时空视觉语言基础模型(Unified Spatio-Temporal Vision-Language Foundation Models)旨在用一个模型同时处理遥感中的多种任务,如变化检测、描述、问答和定位,文章介绍了数据的统一表征和代表性方法。
其特点包括:
图像编码器 + 大语言模型联合构建;
自然语言指令驱动,输出格式统一为文本;
无需多个任务模型,提升泛化能力和实际适应性。
代表模型有:TEOChat、RSUniVLM、EarthDial、RingMoGPT等。
5 LLM驱动的遥感智能体(LLM-powered Spatio-temporal Agents for Remote Sensing)
探索遥感领域的“多模态智能体”构建,模型可以“听懂人话、看懂图像、给出解释或行动”;
代表性项目:
这些智能体实现从“图像理解”向“智能遥感助手”演进,为未来遥感自动化分析和决策提供了新范式。
评估指标与数据集
1 多任务评估指标(Evaluation Metrics for Multi-tasks)
为支持RS-STVLMs涵盖的多种任务,本节根据不同任务类型,列出了相应的常用评估指标:
1)语言生成指标(Language Generation Metrics)
适用于模型生成文本(如图像描述或问答)时的质量评估,衡量生成文本与人工参考的相似性,注重精确性、召回率及语义一致性。
BLEU:衡量生成文本与参考文本之间的n-gram重合程度,常用BLEU-4,强调精确度并惩罚过短的输出。
ROUGE:注重召回率,衡量参考文本被覆盖的程度,ROUGE-N关注n-gram,ROUGE-L注重句子结构相似性。
METEOR:结合词根、同义词对齐及词序惩罚,适合评估语义准确但语法多变的生成结果。
CIDEr:根据n-gram的权重评估生成文本与参考之间的语义一致性,更加重视少见但重要的表达。
复合指标,综合BLEU-4、ROUGE-L、METEOR 和 CIDEr 的得分,从多个角度评估文本生成的整体质量。
2)检索指标(Retrieve Metrics)
用于评估模型根据文本检索图像或根据图像检索文本的能力,重点考察排序结果的相关性与覆盖度。
Recall@K:衡量前K个结果中被正确检索到的相关项比例,是对检索全面性的评估。
Precision@K:衡量前K个检索结果中真正相关项所占比例,侧重检索结果的准确性。
Mean Recall:在多个K值下的平均召回率,用于提供更全面的检索性能评估。
3)空间定位指标(Localization Metrics)
用于模型输出空间区域(如边框或掩膜)时的评估,主要关注预测区域与真实区域的空间重合程度。
2 遥感时空图文任务数据集(RS-STVLM Datasets)
本节概述了用于 RS-STVLMs 研究的代表性多时相图像数据集,包括其来源、内容和任务支持情况:
1)图像与文本配对(Temporal Images + Text)
这类数据集配对时间序列图像和变化描述,支持描述生成和检索。
DUBAI CCD:500对Landsat图像,2,500条简短描述,关注迪拜城市扩张。
LEVIR CCD:500对高分图像,每对5条描述,句子更长更细致。
LEVIR-CC:大规模数据集,10,077对图像,5条描述/对,强调显著变化。
2) 图像、文本与掩膜配对(Temporal Images + Text + Mask)
提供描述和像素级掩膜,支持多任务建模。
LEVIR-MCI:在LEVIR-CC上加入建筑和道路掩膜,适合联合学习。
LEVIR-CDC:仅含建筑掩膜,掩膜来源与LEVIR-CD相似。
WHU-CDC:记录地震后城市变化,覆盖多类地物变化。
SECOND-CC:提供变化前后的语义掩膜,强化语义对齐。
3)图像、指令与响应配对(Temporal Images + Instruction + Response)
支持指令理解和多模态响应,适用于问答和定位任务。
CDVQA:基于SECOND生成12万问答对,涵盖变化类型和范围。
ChangeChat-87k:基于LEVIR-MCI,ChatGPT辅助生成多类型指令响应对。
QAG-360K:6,800多组图像,平均每组53条问答+掩膜。
GeoLLaVA:GPT生成10万组变化描述,来源于fMoW图像。
TEOChatlas:超50万组样本,支持多时相、多任务推理。
EarthDial / UniRS / Falcon-SFT:百万级样本,用于大模型训练。
3 基准性能比较(Benchmark Comparison)
未来展望与讨论
构建高质量数据集
多模态融合
时空泛化与变长推理
通用推理模型
超大图像的细粒度理解
文本驱动的影像生成
更多图表分析可见原文









