专家混合(MoE)是一种流行的架构,比如最近火爆天的 DeepSeek V3 和 R1 就是这类模型。它利用不同的“专家”来改进 Transformer 模型。
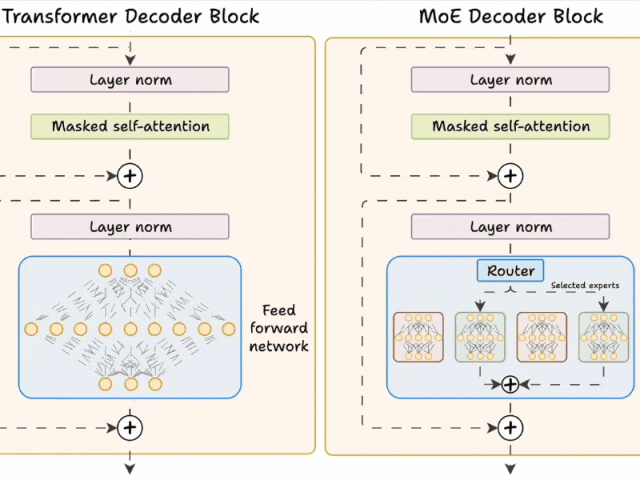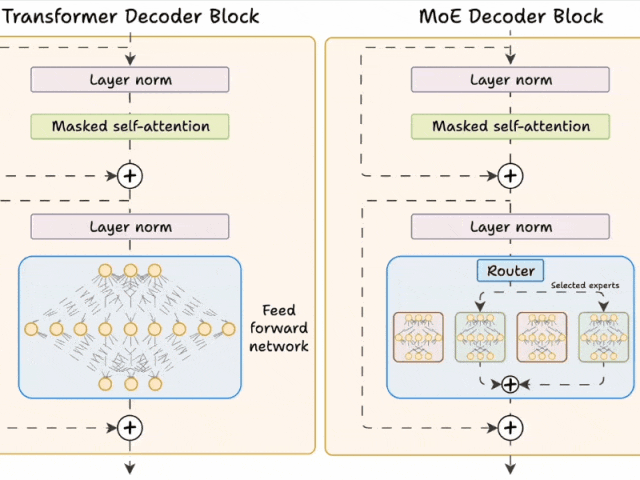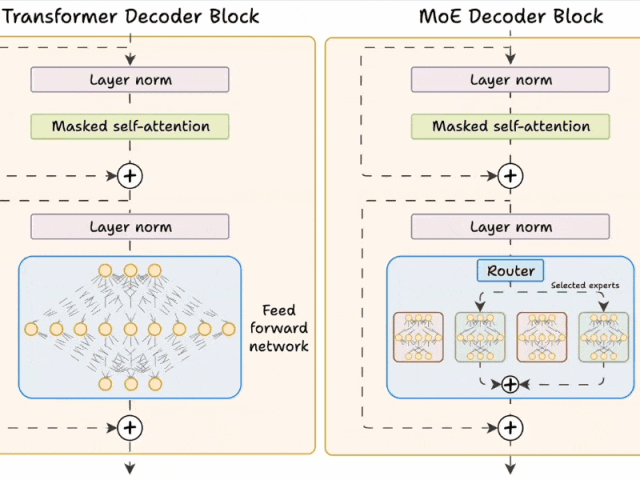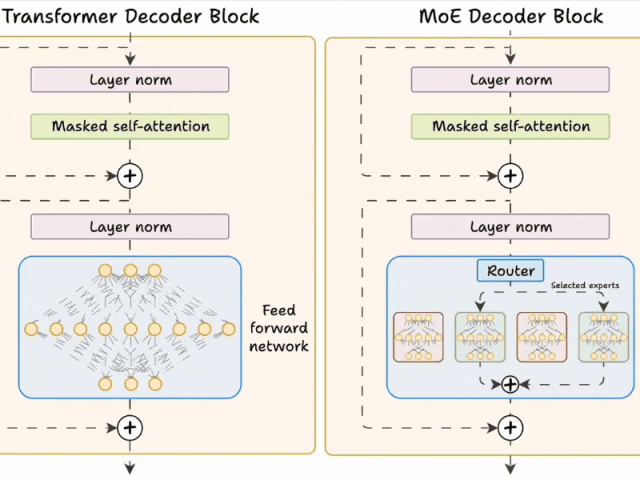
下面的示意图展示了它们与 Transformer 的不同之处。
 图片
图片Transformer 和 MoE 在 decoder 块中有所不同:
MoE 使用 experts,它们是前馈网络,但与 Transformer 中的网络相比更小。
在推理过程中,将选择专家的子集。这使得 MoE 中的推理速度更快。
 图片
图片由于网络包含多个解码器层:
但是,模型如何决定哪些专家是理想的呢?
这由路由器(Router)来完成。接下来我们来讨论它。
 图片
图片路由器就像一个多分类分类器,它对专家生成 softmax 分数。根据这些分数,我们选择前 K 个专家。
路由器与网络一起训练,并学习如何选择最合适的专家。
但这并不简单。让我们来看看其中的挑战!
 图片
图片
挑战 1)注意训练初期的这一模式:
许多专家因此训练不足!
 图片
图片我们通过两个步骤来解决这个问题:
在路由器的前馈输出中添加噪声,使其他专家的 logits 更高。
将除前 K 个之外的所有 logits 设为负无穷大,这样在 softmax 之后,这些分数就变为零。
这样,其他专家也有机会参与训练。
 图片
图片挑战 2)某些专家可能会比其他专家处理更多的 token,导致部分专家训练不足。
我们通过限制每个专家可处理的 token 数量来避免这种情况。
如果某个专家达到上限,输入的 token 就会被传递给下一个最合适的专家。
MoE 具有更多的参数需要加载,但由于每次仅选择部分专家,因此只有一部分参数被激活。
这使得推理速度更快。@MistralAI 的 Mixtral 8x7B 就是一个基于 MoE 的知名大型语言模型(LLM)。
下面是对比 Transformer 和 MoE 的示意图!
 图片
图片(完)










