现代金融文件通常超过100页,包含复杂的文本、表格和图形,准确的问答(QA)对分析师和自动化金融代理至关重要。然而,现有问答方法面临文档长度超出LLM的令牌限制、API成本高、混合格式使得表格和图形的关系在转为文本时丧失等挑战。
传统的检索增强生成(RAG)方法存在以下问题:
MultiFinRAG框架提出以下创新:
批量多模态提取:小组表格和图像输入轻量级多模态LLM,返回结构化JSON和简洁摘要,保留数值关系。
语义块合并与阈值检索:基于嵌入相似性重新组合过度分段的文本块,并使用特定阈值过滤边际上下文。
分级回退策略:优先检索高相似度文本,若结果不足则自动扩展到表格和图像上下文,确保全面覆盖。
LLMs在决策流程中的应用推动了检索增强生成(RAG)系统的发展,以解决知识局限,尤其是在特定领域和不断变化的环境中。财务文件(如10-K和8-K)对RAG提出了挑战,因其内容冗长且多模态,信息分散。现有RAG系统在处理需要跨多种格式的信息综合时表现不足。
开源多模态模型(如Meta的Llama-3.2-11BVision-Instruct、Google的Gemma等)使构建强大的多模态RAG管道成为可能。现代RAG框架引入了动态检索策略、智能分块机制和层次化内容组织。SELF-RAG、T-RAG、MoG和DRAGIN等方法提升了检索和生成的效率。Dense Passage Retrieval(DPR)是开放域QA中的基石,优于稀疏检索基线。PDFTriage提出了布局感知检索,以改善对图表和多页内容的QA。
尽管有进展,现有金融RAG系统在处理复杂多模态问题时仍有限。MultiFinRAG旨在跨文本、表格和图形进行综合推理,结合近似最近邻检索和模态感知相似性过滤,专为金融文件设计。
模型和工具使用
使用专门和通用模型处理金融文档的多模态特性。
表格检测:使用Detectron2Layout识别和提取表格结构。
图像检测:Pdfminer的布局分析定位PDF中的图表和图示。
多模态摘要:尝试使用Gemma3和LLaMA-3.2进行表格和图像的批量摘要,输出结构化JSON和纯文本。
嵌入生成:BAAI/bge-base-en-v1.5模型生成语义文本块、表格和图像摘要的嵌入。
近似检索:FAISS提供高效的近似最近邻搜索。
集成的LLM:通过Ollama框架整合Gemma3和LLaMA-3.2,优化内存和速度,支持单GPU部署。
基线框架
使用传统的RAG管道评估方法性能。
基本RAG设置:标准的检索增强生成管道,使用固定大小文本块,无语义合并。
嵌入与检索:与MultiFinRAG相同的BAAI/bge-base-en-v1.5嵌入,通过FAISS IVF-PQ从固定块中检索,无分层逻辑。
无多模态解析:图表和表格未被总结,视觉和表格元素被简化为原始文本或忽略。
MultiFinRAG
概览
系统将每个PDF 𝐹 𝑖 分为三类可检索的块:文本块 𝐶 𝑖 ^ text、表格块 𝐶 𝑖 ^ table和图像块 𝐶 𝑖 ^ image。
文本块包含语义连贯的文本段落,表格和图像块通过多模态LLM转换。所有块被嵌入并存储在FAISS索引中。查询 𝑄 触发分层检索,先检索文本,再检索文本+表格和图像,自动升级以应对上下文不足,最终生成LLM答案。
语义分块和索引
句子分割:将叙述分割为句子。
滑动窗口:使用滑动窗口形成重叠块,以捕捉语义单元。
嵌入与断点:对每个句子进行嵌入,计算相似度,标记高于95百分位的相似度作为分割点。
块形成:在断点处将块分割为语义块。
块合并:计算块间余弦相似度,合并相似度高的块以减少冗余。
近似索引:嵌入最终块集,构建FAISS索引,实现快速k-NN查找,减少上下文大小,降低计算成本。
批量多模态提取
通过检测区域、语义文本分块,批量处理表格和图像,确保100%覆盖。
分层检索与决策功能
设定文本、表格和图像的最小检索数量,通过分层检索策略进行有效调用。结合文本、表格和图像的检索,使用FAISS索引和系统提示以避免幻觉。
通过决策函数进行阈值校准
通过决策函数进行阈值校准,优化相似性切割点。文本阈值从0.55到0.85逐步调整,记录检索质量和QA准确性。表格和图像阈值在固定文本阈值下独立调整,记录准确性。选择最大化上下文相关性和QA准确性的阈值组合,保持查询上下文大小在预算内。
最终选择的阈值为:文本0.70,表格0.65,图像0.55,确保文本优先,必要时使用表格/图像。
本研究关注端到端问答(QA)准确性。信息检索统计(如精确度、召回率等)在开发过程中收集,但因篇幅限制未在此报告。计划在后续论文中提供详细的检索组件统计数据。
数据集
收集了多家公司财务文件,包括Form 10-Q、Form 10-K、Form 8-K和DEF 14A,通过SEC的EDGAR数据库和API下载并转换为PDF。制作了300个评估问题,分为四类:146个文本问题、42个图像问题、72个表格问题、40个需结合文本和图像/表格的问题。
文本问题直接从财务文件中提取信息,确保答案简洁明了。图像问题要求分析财务图表,测试框架对图形的理解能力。
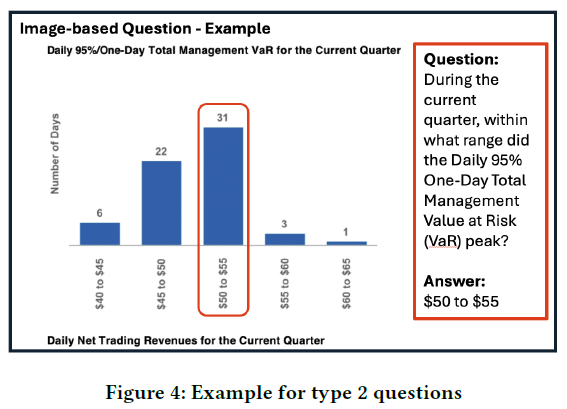
表格问题涉及表格数据的解读,需准确定位行列获取答案。
结合文本和图像/表格的问题最具挑战性,需要综合信息才能回答。
评估策略
评估LLM框架输出仍是重要的研究领域,传统的精确匹配方法不再适用,尤其在数值答案中可能出现单位差异。BERTScore计算生成答案与参考答案的相似度,但对数值问题不合理,因无法有效比较数字的语义相似性。最近对使用LLM评估GenAI结果的兴趣增加,但存在LLM偏见的问题。由于数据集规模和资源限制,选择手动评估以确保更准确的评估,减少误判风险。
结果
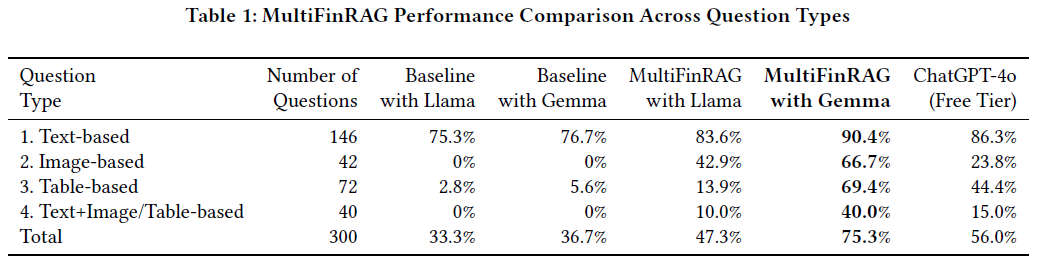
文本问题准确性:MultiFinRAG框架下,Gemma 3的准确率为90.4%,比基线框架提高15.1%。Gemma 3在识别关键答案方面优于Llama-3.2-11B-Vision-Instruct(高6.8%)。
图像问题准确性:MultiFinRAG与Gemma 3的准确率为66.7%,显著高于Llama-3.2-11B-Vision-Instruct的42.9%,表明Gemma 3在图像描述上更有效。
表格问题准确性:MultiFinRAG与Gemma 3的准确率为69.4%,比Llama-3.2-11B-Vision-Instruct的13.9%高55.5%,显示Gemma 3在表格描述上表现更佳。
综合问题准确性:MultiFinRAG与Gemma 3的准确率为40%,而Llama-3.2-11B-Vision-Instruct仅为10%。基线框架下Gemma 3的准确率为0%,转向MultiFinRAG后显著提升。
与ChatGPT-4o比较
MultiFinRAG与Gemma 3在文本问题上比ChatGPT-4o高出4.1%的准确率,且在某些情况下提供了ChatGPT-4o未能正确回答的答案。
在图像问题上,MultiFinRAG的准确率比ChatGPT-4o高出40%以上,ChatGPT-4o因文本中多个值的干扰而回答错误。
对于表格问题,MultiFinRAG的准确率比ChatGPT-4o高出25%以上,ChatGPT-4o的错误回答显示其可能受限于训练数据。
在需要同时分析文本和图像/表格的问题上,MultiFinRAG的准确率为75.3%,比ChatGPT-4o的56.0%高出19.3%。ChatGPT-4o在已有知识的情况下能正确回答,但在不熟悉的信息上表现不佳。
效率与成本
本次评估主要关注准确性,而非处理时间,后者受基础设施影响较大。MultiFinRAG在Google Colab T4 GPU上处理200页PDF(含200个表格和150张图片)平均需25分钟。目前,MultiFinRAG和基线系统均可在Google Colab免费版上运行,实验无额外费用。ChatGPT-4o作为对比基准也使用免费版,未产生额外成本。
模块评估:通过系统性消融实验量化各组件影响。
用户反馈:未来将进行更广泛的用户研究以评估可用性。
结构化数据管道:开发系统处理大表格,提供自然语言接口,直接供给RAG生成器。
跨文档与纵向分析:构建多文档索引,支持时间比较和趋势检测,提供可视化和自动摘要。
抗噪声与错误修正:通过多种OCR引擎和一致性检查提高解析准确性,使用微调的LLM进行后处理。
扩展领域覆盖:方法可推广至其他金融文档,适应不同布局和元数据。
微调与领域适应:在高质量金融QA数据集上微调检索和生成模型。
网页内容摄取与实时多模态问答:扩展至在线新闻,整合文本、表格和图形,提升实时问答能力。
MultiFinRAG在处理复杂金融查询时,准确性超过ChatGPT-4o,尤其在文本、表格和图像方面。结合模态感知检索阈值与轻量化量化开源LLM,框架在普通硬件上高效运行,减少60%以上的token使用,提升响应速度。在挑战性的多模态问答任务中,MultiFinRAG实现超过75%的准确率,提供实用、可扩展且经济高效的解决方案。