开篇:我们活在AIGC的“托勒密时代”
过去几年,我们仿佛活在AIGC(人工智能生成内容)的“托勒密时代”。
在这个时代里,整个领域都找到了一个看似完美、不容置疑的“宇宙中心”——语义(Semantic)。从开发者社区到顶级实验室,一种信念如地心说般深入人心:通往更强AI的唯一路径,就是让模型更“懂”人类的语言和世界的概念。
这场“文艺复兴”的起点,是2021年OpenAI发布的CLIP模型[1]。它如同一位先知,首次通过海量的图文对齐,让机器学会了用人类的语言去理解视觉世界,实现了石破天惊的“零样本”分类能力。这一刻,被公认为视觉-语言模型的“ImageNet时刻”[2],它所建立的“语义为王”的法则,成为了驱动后续几乎所有主流生成模型的“第一推动力”。正如Andrej Karpathy所洞察的那样,现代AI的本质是一种通用的token流建模技术[3],而CLIP正是那个将视觉和语言这两种最重要token流完美对齐的“罗塞塔石碑”。无论是名声大噪的Stable Diffusion,还是风格独树一帜的Midjourney,其核心架构都深深地依赖于CLIP或类似文本编码器所提供的语义“导航”,将人类的抽象指令,转化为像素世界的奇观。
在这个“语义为王”的时代背景下,诞生了诸多“地心说”最忠实的信徒。VA-VAE、MAETok等一系列明星分词器(Tokenizer)应运而生,它们的首要任务,就是将图像“翻译”成一种特殊的语言(Latent),而翻译的最高纲领,就是无限逼近CLIP这类大型语言模型的“语义心意”。它们就像一群“奉旨翻译官”,力求让每一个翻译出来的词汇,都闪耀着语义的金色光芒。
一切看起来如此和谐、自洽。遵循着“语义”这个宇宙中心,AIGC的世界似乎正沿着一条清晰、光明的轨道稳定运行。
直到,天空中出现了无法解释的“行星逆行”。
“异象”出现:无法解释的行星逆行
当这些被“语义圣经”加持过的“优等生”分词器,遇到了一个看似“异类”的自回归(Autoregressive)模型时,一个让所有人都始料未及的“异象”出现了:模型性能非但没有提升,反而急剧恶化,仿佛一颗在星图上完美运行的行星,突然开始了诡异的逆行。
这惊人的“异象”,被记录在一篇2025年7月由USC、MIT、Google DeepMind和OpenAI等四大顶尖机构联手发布的论文《Latent Denoising Makes Good Visual Tokenizers》[4]中。
论文的核心证据,就藏在下方的这张图表里。它揭示了一个灾难性的后果:当使用基于“语义蒸馏”的VA-VAE分词器时,自回归模型MAR的FID(一种评估生成图像质量的指标,越低越好)从基线的3.71,飙升至16.66;另一个自回归模型RandomAR的FID更是从11.78,灾难性地恶化到了38.13。
| |
| |
|---|
| 标准分词器 (MAR-VAE) | 3.71 | 11.78 | 7.99 |
| 语义蒸馏分词器 (VA-VAE) |
16.66 (性能恶化349%) | 38.13 (性能恶化224%) | 15.88 (性能恶化99%) |
| 我们的新主角 (l-DeTok) | 2.43 (性能提升35%) | 5.22 (性能提升56%) |
4.46 (性能提升44%) |
(数据来源: Latent Denoising Makes Good Visual Tokenizers[5], Table 1. 语义蒸馏分词器在自回归模型上导致性能急剧恶化,而l-DeTok则实现了巨大提升。)
这组数据,就像当年让天文学家彻夜不眠的“火星逆行”轨迹一样,旧的“语义地心说”理论无法再提供完美的解释。整个AIGC领域赖以生存的基石开始动摇,一个根本性的问题浮出水面:我们追求的终极目标,真的是让分词器“更懂语义”吗?
或者说,一个更尖锐、更本质的问题是:“可理解性”和“可生成性”之间,是否存在着不可调和的矛盾?
不妨做一个思想实验:面对一幅毕加索的画,你是希望AI能写一篇长篇大论来“理解”其解构主义的内涵,还是希望AI能精准“重建”出它每一笔疯狂又精确的笔触?对于一个生成任务而言,后者的重要性,可能远远超乎我们的想象。正如一些医学影像生成研究[6]发现的那样,模型越是追求像素级的“完美复现”,其内部对语义的“可解释性”反而会下降。
这个“异象”迫使我们停下来思考:或许,我们从一开始就问错了问题。
新宇宙的诞生:回归“去噪”的日心说
AIGC的宇宙,真正的“太阳”并非高高在上的“语义”,而是一个更朴素、更底层、也更强大的力量——去噪(Denoising)。
这正是那篇四大机构联合论文所提出的、足以颠覆整个领域的“日心说”。这个理论的核心观点如同一道闪电划破长夜:无论是复杂的扩散模型(Diffusion),还是序列化的自回归模型(AR),它们的本质都可以被统一到一种行为上——从一个损坏、残缺、充满噪声的信号中,重建出清晰、完整的原始信号。
这一思想并非凭空出现,它的根源可以一直追溯到机器学习的早期。早在2008年,Vincent等人奠基性的工作《去噪自编码器(Denoising Autoencoders)》[7]就确立了这一思想的核心,即强迫模型学习如何从损坏的数据中恢复其内在结构,从而获得更鲁棒的特征。而现代扩散模型,正是这一思想的极致体现:
- 扩散模型,去的是我们熟悉的高斯噪声。它的工作过程,就像一位顶级文物修复师,小心翼翼地抹去一张布满雪花点的老照片上的所有干扰,让照片重现光彩。它遵循的物理学类比,正是热力学中从“无序”到“有序”的熵减过程[8]。
- 自回归模型,去的则是“遮蔽噪声”。它的工作过程,更像一位博学的考古学家,根据上下文,补完一本被撕掉一半的古籍。
两种模型,路径不同,但终点一致——都是在对抗“熵增”,从混沌中恢复秩序。
而这篇论文的主角l-DeTok,就是人类历史上第一台完全用“去噪日心说”来武装自己的“哥白尼的望远镜”。它的设计哲学简单到极致,甚至有些“反智”:与其学习如何“看懂”世界,不如练习如何“复原”世界。
l-DeTok
的训练方式堪称“魔鬼训练营”。它不像那些“语义分词器”一样,费尽心思地去对齐CLIP的语义空间。恰恰相反,它故意“破坏”信息。
 l-DeTok Framework
l-DeTok Framework(图注:l-DeTok的训练框架。在训练时,它故意在潜在空间中注入噪声和遮蔽,强迫解码器从混乱中重建清晰图像。来源:Latent Denoising Makes Good Visual Tokenizers[9])
它的训练过程分为两步“酷刑”:
- 随机高强度遮蔽: 像随机抠掉一大块拼图一样,强行遮蔽掉图像70%甚至更多的部分。
- 潜在空间加噪: 在模型初步“翻译”出的潜在表征(Latent)中,注入大量高斯噪声。这就像把收音机调到两个电台之间,让信号充满了刺耳的杂音。
l-DeTok的唯一目标,就是从这种“一团乱麻”的信息废墟中,重建出最原始、最清晰的图像。它不关心“这幅画是不是猫”,它只关心“我能不能把这幅画完美地拼回来”。
而这种看似“返璞归真”的笨功夫,却带来了惊人的效果。l-DeTok不仅完美解决了“行星逆行”的问题,在自回归模型上取得了SOTA的成绩,更令人震惊的是,它在另外六种主流的、不同架构的生成模型上,都实现了一致的、巨大的性能提升。
这不再是巧合。l-DeTok的普适性成功,如同一道无可辩驳的证据,宣告了“去噪日心说”的胜利。AIGC的宇宙,有了新的中心。
新宇宙的运行法则与我们的生存指南
这场“哥白尼革命”不仅仅是技术圈的理论之争,它更深刻地揭示了未来AI发展的内在法则,并为身处其中的我们,提供了宝贵的生存指南。
启示一:告别“炼金术”,拥抱“第一性原理”
l-DeTok的胜利,标志着AI工程正在经历一场深刻的变革:从依赖经验和外部大模型“黑箱”的“炼金术时代”,走向基于深刻洞察和问题本质的“物理学时代”。
在科技史上,这样的故事一再上演。当所有人都认为火箭必须是一次性的昂贵消耗品时,伊隆·马斯克回归到“第一性原理”,他问:一枚火箭的原材料成本只占总成本的2%,那剩下的98%究竟是什么?这个问题,最终诞生了可回收火箭和SpaceX[10]。当所有人都抱怨在线支付接入流程繁琐、接口丑陋时,Stripe的创始人问:让开发者用7行代码完成支付,这件事的本质障碍是什么?这个问题,最终诞生了重塑全球数字支付格局的Stripe[11]。
l-DeTok的作者们做的也是同样的事情。他们没有问“如何让分词器更懂语义”,而是回归本质,问“所有生成模型的共同任务是什么?”——答案是“去噪”。这个回归,带来了降维打击。对于所有AI从业者而言,这无疑是一个提醒:与其盲目追逐SOTA模型的“术”,不如深入思考你所解决问题的“道”。
启示二:重新定义 AIGC 时代的“核心资产”
这场革命还让我们重新审视,在AIGC时代,什么才是真正的“核心资产”。l-DeTok的成功证明,一种不依赖任何外部大模型的、通用的底层技术,其价值可能远超一个依赖特定模型的上层应用。
这让我们想起了AWS与ARM的成功之道[12]。它们的长期价值不在于某一个应用,而在于它们提供了整个行业赖以生存的、通用的“基础设施”。它们不直接参与应用层的竞争,却能从整个生态的繁荣中持续获益。
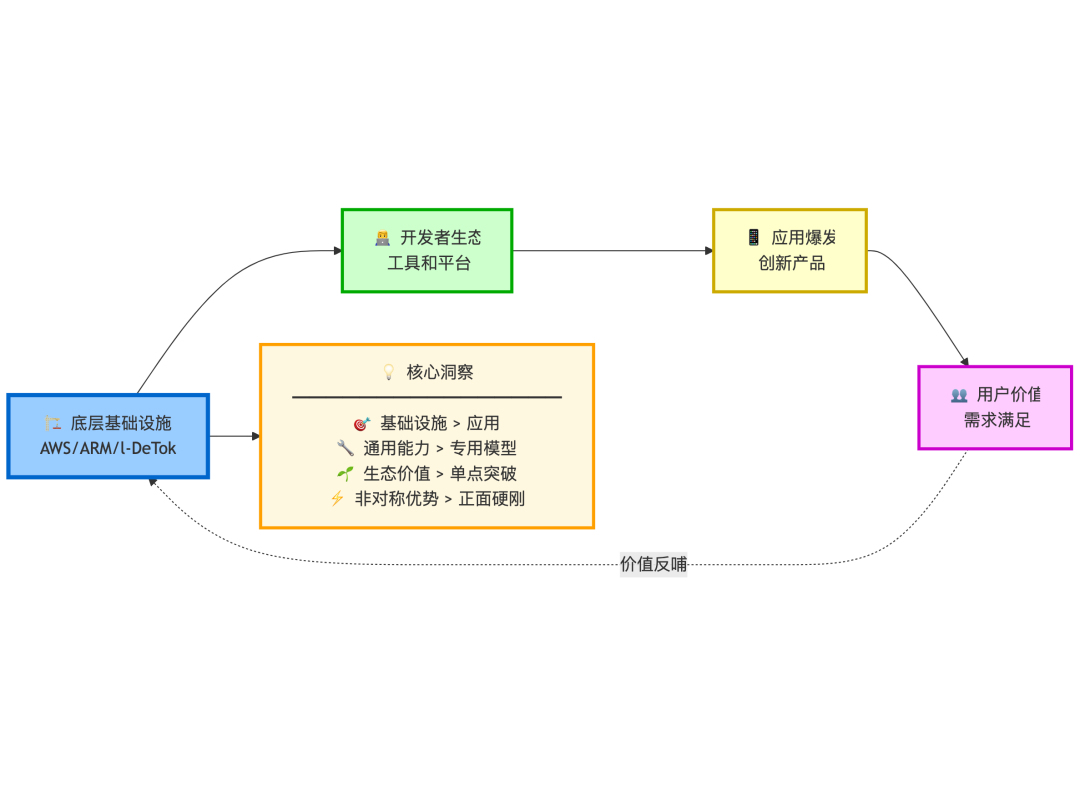
(图注:底层基础设施通过赋能生态,捕获更长远的价值)
未来的核心竞争力,可能不再是谁拥有更大的“语义模型”,而是谁掌握了更多像“去噪”这样可跨模型、跨模态的“通用底层能力”。这是一种更本质、更具护城河的资产。对于渴望在AI浪潮中寻找机会的创业者和投资者,这指明了一条新路:无需在算力和数据上与巨头硬碰硬,通过底层核心技术的创新,同样可以实现非对称优势。
最终思考:智能的“演化捷径”
智能的本质,不是“知道答案”,而是“永远在预测,并从错误中学习”。l-DeTok的成功或许暗示了一条通往通用人工智能被忽视的演化捷径。
这与神经科学中一个影响深远的理论——预测编码(Predictive Coding)[13]不谋而合。该理论认为,我们的大脑并非被动处理感官信息,而是一台主动的“预测机”,它不断生成对世界的预测,并只将“预测误差”向上传递。大脑通过持续不断地最小化预测误差来学习和理解世界。
包括图灵奖得主Yoshua Bengio在内的许多AI领袖都已开始关注这一方向,认为当前深度学习模型并非人脑的工作方式[14],而预测编码这种机制,可能是通往更通用、更鲁棒AI的真正路径。而另一位神经科学家Karl Friston更是基于此提出了“自由能原理”[15],并将其视为构建通用人工智能(AGI)的系统性蓝图[16]。
从这个角度看,l-DeTok的“去噪”训练,本质上也是一种最小化“预测误差”的行为——模型预测被噪声破坏后的信号应该是什么样,并通过重建来修正这个预测。
在AIGC这场波澜壮阔的革命中,我们需要的或许不只是更强大的模型,更是回归本质的勇气和洞察未来的智慧。而这场由“去噪”引发的哥白尼革命,才刚刚拉开序幕。
[1] CLIP模型: https://openai.com/index/clip/
[2] “ImageNet时刻”: https://thegradient.pub/nlp-imagenet/
[3] 通用的token流建模技术: https://simonwillison.net/2024/Sep/14/andrej-karpathy/
[4] 《Latent Denoising Makes Good Visual Tokenizers》: https://arxiv.org/abs/2507.15856
[5] Latent Denoising Makes Good Visual Tokenizers:
https://arxiv.org/abs/2507.15856
[6] 医学影像生成研究: https://ojs.aaai.org/index.php/AAAI/article/view/30095
[7] 《去噪自编码器(Denoising Autoencoders)》: https://www.iro.umontreal.ca/~vincentp/Publications/denoising_autoencoders_tr1316.pdf
[8] 熵减过程: https://www.linkedin.com/pulse/diffusion-models-inspiration-from-non-equilibrium-ankur-kumar-mandal-iv6ff
[9] Latent Denoising Makes Good Visual Tokenizers: https://arxiv.org/abs/2507.15856
[10] 可回收火箭和SpaceX: https://productify.substack.com/p/case-study11-learning-first-principles
[11] 重塑全球数字支付格局的Stripe: https://www.lennysnewsletter.com/p/first-principles-thinking
[12]
AWS与ARM的成功之道: https://www.klover.ai/arm-holdings-ai-strategy-analysis-of-dominance-in-semiconductors/
[13] 预测编码(Predictive Coding): https://en.wikipedia.org/wiki/Predictive_coding
[14] 当前深度学习模型并非人脑的工作方式: https://www.lesswrong.com/posts/4qPy8jwRxLg9qWLiG/yoshua-bengio-on-ai-progress-hype-and-risks
[15] “自由能原理”: https://en.wikipedia.org/wiki/Free_energy_principle
[16] 构建通用人工智能(AGI)的系统性蓝图: https://hackernoon.com/exclusive-interview-dr-karl-fristons-blueprint-for-artificial-general-intelligence








