就像手机从90年代的大哥大,到零几年的诺基亚,再到现在的智能手机一样,编码器-解码器架构也经历了三次关键的技术迭代。每一次技术迭代都解决了前一代的核心痛点,让AI的"理解与表达"能力越来越强。
第一代:基础RNN编码器-解码器
(1)这一代的设计思路是什么?
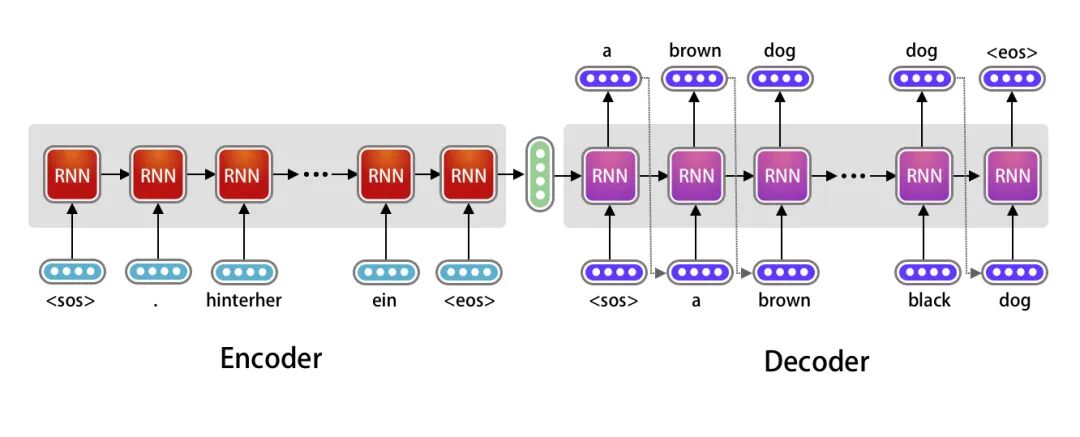
第一代编码器-解码器就像一个刚学会读书写字的小学生——能够理解简单的内容,也能表达基本的想法,但处理复杂长文时就力不从心了。
-
编码器:使用RNN/LSTM逐词处理输入,最终输出一个固定长度的"理解向量"
- 解码器:从这个"理解向量"开始,逐词生成输出序列
- 连接方式:编码器的最后状态直接传给解码器作为初始状态
(2)这一代解决了什么问题?
首次实现了真正的"端到端"序列学习——不需要人工设计复杂的规则,AI就能学会输入序列到输出序列的映射关系。
(3)存在什么致命缺陷?
刚才提到的信息瓶颈问题,就像要把一整本书的内容压缩成一句话的摘要,长序列的重要信息很容易在"压缩"过程中丢失。特别是序列开头的信息,往往在处理到结尾时就被"遗忘"了。
第二代:带注意力机制的编码器-解码器
(1)这一代的突破在哪里?
第二代就像一个学会了"翻书查资料"的中学生——不再依赖死记硬背,而是学会了在需要时主动查找相关信息。
解码器不再只能看编码器的"最终总结",而是通过注意力机制可以回头查看编码器处理过程中的所有"中间笔记",并且能够智能地决定当前最需要关注哪部分信息。整个工作过程就像智能搜索。
第一步:明确需求(Query)解码器说:"我现在要翻译'beautiful'这个词,我需要什么信息?"
第二步:匹配搜索(Key-Value)编码器回应:"我这里有'美丽'、'漂亮'、'好看'等相关信息,相关度分别是0.8、0.6、0.3"
第三步:权重融合(Attention)解码器决定:"好,我重点关注'美丽'(0.8权重),适当参考'漂亮'(0.6权重)"
(2)这一代解决了什么问题?
彻底解决了信息瓶颈问题,让模型能够处理更长的序列,翻译质量显著提升。
(3)还有什么局限?
由于底层仍然是RNN,存在串行处理限制,必须按顺序处理,训练速度慢,难以利用现代GPU的并行计算能力。
第三代:Transformer编码器-解码器
(1)这一代的革命性在哪里?
第三代就像从"手工作坊"升级到"现代化工厂"——不仅质量更高,生产效率也实现了质的飞跃。
既然注意力机制这么有效,Transformer的作者心想,我们还需要RNN吗?能不能完全抛弃顺序处理,让所有位置同时"对话"?
1. 自注意力(Self-Attention)- 内部民主讨论
序列中每个词都能直接与其他所有词"对话",理解彼此关系。就像一个会议中每个人都能直接与任何人交流,不需要通过固定的发言顺序。
2. 多头注意力(Multi-Head Attention)- 多维度理解
就像用多个不同角度的摄像头同时拍摄一个场景:
- 第一个头:专注语法关系(主谓宾结构)
- 第二个头:专注语义关系(词汇含义)
- 第三个头:专注长距离依赖(句子间逻辑)
3. 位置编码(Positional Encoding)- 秩序维持者
由于抛弃了天然的顺序结构,需要人工告诉模型每个词的位置信息。就像给演员分配座位号,确保大家知道自己在剧本中的位置。
Transformer完全基于注意力机制构建了第三代的编码器-解码器的双塔协作架构。
1. 编码器塔:深度理解专家。
- 多层自注意力层堆叠
- 每个词与所有词建立关系网络
- 输出:每个输入位置的深度理解表示
2. 解码器塔:智能生成专家
- 掩码自注意力:只能看到前面已生成的词
- 编码器-解码器注意力:动态关注输入序列
- 逐步生成高质量输出
(2)这一代带来了什么改变?
1. 训练效率革命:并行处理让训练速度提升10-100倍,使大规模模型训练成为可能。
2. 可扩展性突破:为GPT、BERT等大语言模型奠定了基础,开启了AI的"大模型时代"。
3. 应用领域扩展:从单纯的文本任务扩展到图像、语音、多模态等各个领域。
从最初的信息瓶颈到注意力突破,再到Transformer的并行革命,编码器-解码器架构用三次关键演进,为AI奠定了"理解与表达"的基础。
有趣的是,今天的AI界又出现了新的转向——GPT、Claude等主流大模型都采用了decoder-only架构。这看似是对编码器-解码器的"背叛",实际上却是它最好的传承:decoder-only把"理解"和"表达"融合在一个统一的生成过程中,让AI可以在生成每个词的同时持续理解上下文。
这就像是从"先完整理解,再完整表达"进化到了"边理解,边表达"——技术在变,但编码器-解码器教给AI的核心智慧没变:理解与表达,始终是智能的两翼。









