
龙哥寄语:
想知道如何将强大的Vision Transformer架构应用于表格数据分类吗?VisTabNet为你提供解决方案!这篇论文的创新之处在于将视觉领域的Transformer模型成功迁移到表格数据处理中,在小样本场景下表现优异,为解决表格数据深度学习难题提供了新思路。
论文标题:
VisTabNet: Adapting Vision Transformers for Tabular Data
发表日期:
2025年1月
作者:
Witold Wydmanski, Ulvi Movsum-zada, Jacek Tabor, Marek Smieja
发表单位:
Jagiellonian University
原文链接:
https://arxiv.org/pdf/2501.00057v2
开源代码链接:
https://github.com/wwydmanski/VisTabNet
引言
表格数据在生物、金融和工业领域无处不在,但深度学习在该领域的表现一直不如传统集成方法。VisTabNet通过创新的跨模态迁移学习,将预训练的Vision Transformer应用于表格数据处理,在小样本场景下取得了突破性进展。本文将深入解析这一创新方法的核心原理和实验效果。
表格数据是现实世界中最常见的数据类型之一,广泛应用于生物、医疗、金融和制造业等领域。然而,与自然语言处理和计算机视觉不同,深度学习在表格数据上的表现往往不如传统的集成方法(如XGBoost和随机森林)。
表格数据的异构性和小样本特性给深度学习带来了巨大挑战。虽然已有一些尝试将Transformer架构应用于表格数据,但预训练和迁移这些模型到下游任务仍然困难重重。
VisTabNet提出了一种全新的跨模态迁移学习方法,将预训练的Vision Transformer(ViT)应用于表格数据处理,在小样本场景下取得了显著效果。
VisTabNet的核心思想是通过一个适配网络将表格输入投影到ViT可以处理的patch embedding空间。具体来说:
适配层:将表格数据转换为ViT可以处理的嵌入表示
预训练ViT编码器:处理转换后的表格数据
分类头:对处理后的数据进行分类
这种方法避免了为表格数据设计特定架构的概念成本,同时减少了从头训练模型的计算成本。
ViT(Vision Transformer):一种将Transformer架构应用于图像分类的模型,将图像分割为小块(patch)进行处理
Patch Embedding:将图像块投影到高维空间的嵌入表示
跨模态迁移学习:将一个模态(如图像)预训练的模型应用于另一个模态(如表格数据)
VisTabNet的核心创新在于其适配网络的设计:
多视图投影:通过多个前馈网络创建表格数据的多个视图,模拟ViT中的patch embedding
CLS token:与ViT类似,添加可学习的CLS token用于最终分类
冻结ViT编码器:在训练过程中通常冻结预训练ViT编码器的参数,只训练适配网络和分类头
这种设计使得VisTabNet能够充分利用预训练ViT的强大表示能力,同时适应表格数据的特性。
应用场景:小样本表格数据分类任务
问题建模:将表格数据分类问题转化为ViT可处理的形式
模型Backbone:预训练的Vision Transformer
训练方法:冻结ViT编码器,只训练适配网络和分类头
跨模态迁移:首次将图像预训练模型成功应用于表格数据
适配网络设计:创新的适配层设计,将表格数据映射到ViT可处理的空间
小样本优势:在小样本场景下显著优于传统方法
VisTabNet的核心公式展示了表格数据如何被投影到ViT可处理的空间:
其中P是patch大小,C是通道数,D是嵌入维度。这个投影将表格数据转换为类似图像patch的表示。
实验使用了多个UCI数据集,样本量均小于1000。采用双重交叉验证:
训练/验证/测试划分:12/20训练,3/20验证,5/20测试
评价指标:使用马修斯相关系数(MCC),对类别不平衡问题更鲁棒
对比方法:包括随机森林、XGBoost等传统方法和NODE等深度学习方法
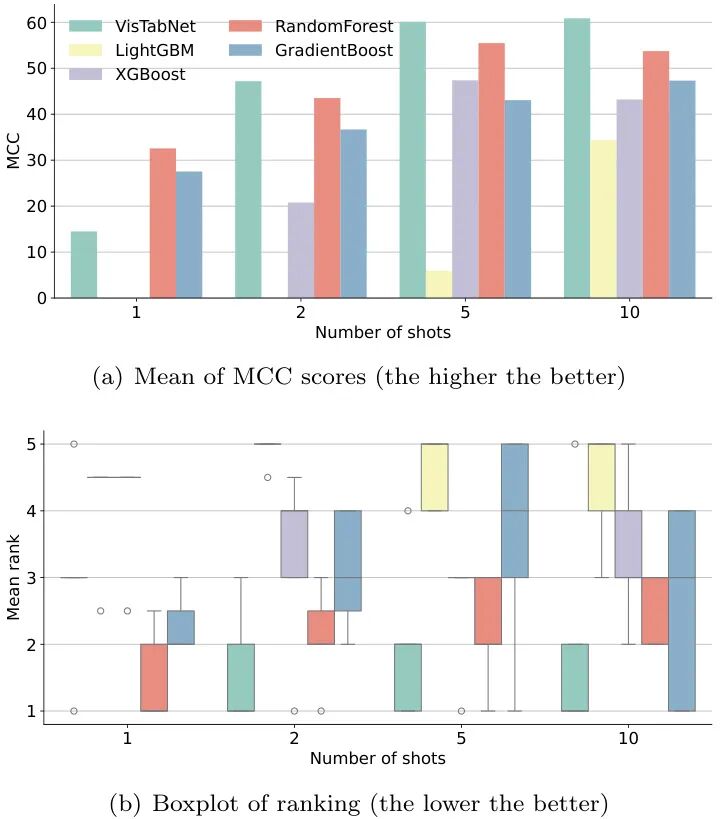
图2:在1-10样本的少样本场景下,VisTabNet在5个数据集上的平均表现。当样本数超过2时,VisTabNet显著优于其他方法
在20个UCI数据集上的对比实验中,VisTabNet以67.43的平均MCC分数领跑榜单,比第二名的随机森林(65.81)高出1.62个百分点。特别是在Connectionist数据集上达到84.6分,比传统方法最高分(76.2)提升11%!
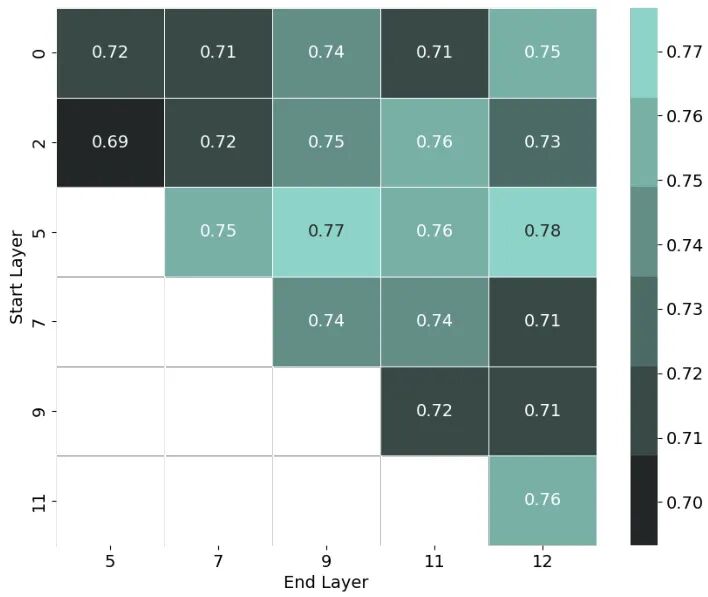
图4:当移除ViT编码器的不同层时VisTabNet的性能变化。结果显示使用第5-12层时效果最佳
预训练层的魔力:ViT中间层(5-12层)的抽象表征能力更适合处理表格数据,这与图像处理中底层特征优先的模式截然不同
少样本优势的奥秘:在2-10样本场景下,VisTabNet通过预训练模型提供的归纳偏置有效防止过拟合,这是传统树模型难以实现的
模型规模的反直觉:ViT-Large的表现反而不如ViT-Base,说明在小数据场景下并非模型越大越好
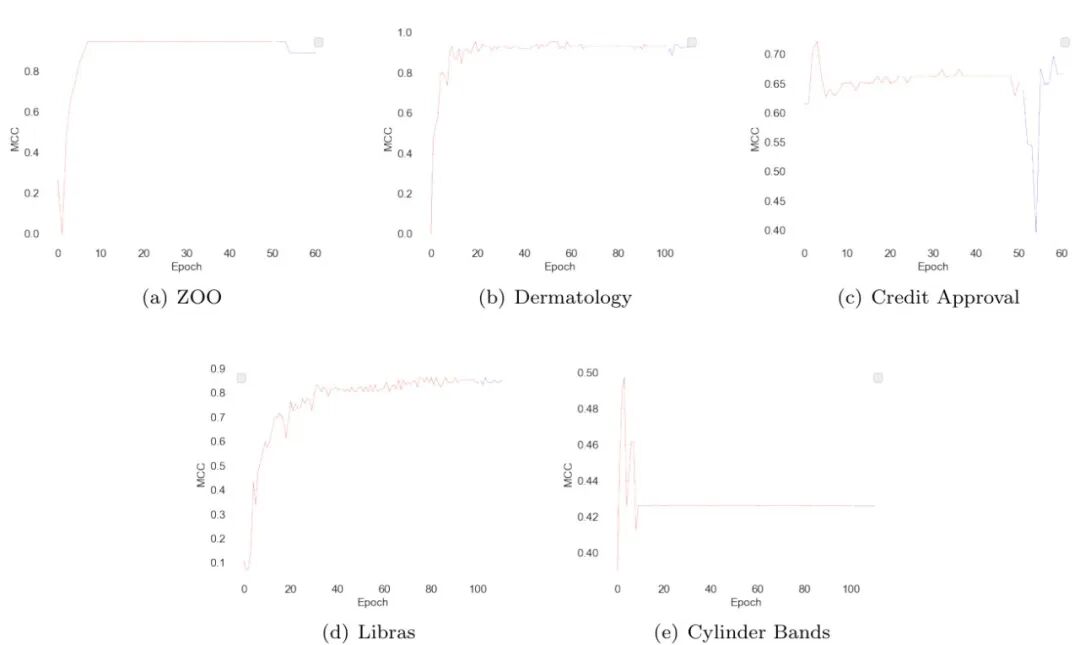
图6:VisTabNet在不同训练阶段的损失曲线。红色为适配层训练阶段,蓝色为ViT微调阶段
为什么用图像模型处理表格数据?这就像用菜刀削苹果——关键在转换接口。VisTabNet的适配层把表格数据"伪装"成图像patch,让ViT以为自己还在处理老本行
适配层具体怎么工作?相当于给每个特征列配了个私人翻译官(前馈网络),把原始特征转成ViT能理解的"外语"(patch embedding)
小样本优势从何而来?预训练模型就像带着经验转行的程序员,虽然新领域数据少,但底层逻辑(注意力机制)是相通的
VisTabNet的成功证明了跨模态迁移的可行性,为小样本表格数据处理开辟了新航道。未来的研究方向可能包括:
动态层选择:根据数据集特点自动选择最优的ViT层组合
论文创新性分数:★★★★☆
跨模态迁移思路新颖,但适配层设计相对传统
实验合理度:★★★★☆
对比实验设计全面,但部分数据集规模过小
学术研究价值:★★★★★
开创了视觉模型处理表格数据的新范式
复现难度:★★★☆☆
需要预训练ViT权重,但代码已开源
可能的问题:部分实验结论依赖小规模数据集,需要更大规模验证
特征工程新思路:将表格特征转换为其他模态的嵌入表示
恭喜你!你又跟着龙哥读完了一篇人工智能领域的前沿论文,棒棒哒!

*本文仅代表个人理解及观点。想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文"查看更多原论文细节哦!

龙哥带你飞,论文轻松读!如果觉得对你有帮助,别忘了关注、点赞、分享或者在看哦~

更多算法或者行业讨论,欢迎加入龙哥读论文粉丝群,扫描上方二维码,或者添加龙哥助手微信号加群:kangjinlonghelper,1478篇去噪、调光、大语言模型等前沿论文原文免费送!









