Benchmarking deep learning methods for biologically conserved single-cell integration
刊登日期:2025 Nov 20
发表杂志:Genome Biology
IF:9.4

深度学习方法在单细胞数据批次校正和整合中的成功很大程度上取决于损失函数的设计。然而,目前尚且缺乏对于损失函数和整合性能的系统性基准测试。同时,现有的评估基准——尤其是广泛使用的 scIB 指标——也存在明显的局限:它主要聚焦于批次去除的效果和基于预定义细胞类型的生物学信息保留,却容易忽略对于细胞类型内部生物学变异的量化评估。
这一局限性在实践中导致了一个问题:即使模型在传统的评估指标上表现优异,也可能因为过度依赖细胞类型标签的监督而陷入“过度校正”,也就是说,当一个模型为了完美地让不同批次的细胞混合(高批次校正分数),并严格地将已知细胞类型分开(高生物学保守分数),它可能会将属于同一大类、但具有细微生物学差异的细胞强行聚集在一起,无意中抹除了这些关键但未被标注的生物学细节。
本研究使用统一的变分自编码器(VAE)框架,结合批次和细胞类型信息,对 16 种深度学习的损失函数进行了全面的基准测试。并且,为了解决上述问题,研究提出了 Corr-MSE 损失函数来缓解“过度校正”的现象,在现有的 scIB 评估体系中新增了“细胞类型内生物学保留”作为核心评估维度,将其扩展为 scIB-E 框架。
核心框架
图A 展示了基准研究使用的基础架构——变分自编码器,输入是单个细胞的基因表达数据,通过编码器将高维基因表达数据压缩成低维的潜在嵌入,解码器则尝试从潜在嵌入中重构出原始的基因表达数据。
图B 表明,研究中将损失函数的设计分为了 3 个层级,第 1 级主要侧重于批次效应的去除(GAN、HSIC、Orthog、MIM、RBP、RCE),第 2 级侧重于生物学信息的保留(CellSupcon、IRM、Domain meta-learning),而第 3 级则是结合了第 1 级和第 2 级的联合优化,同时去除批次效应和保留生物信息(Domain Class Triplet loss、RCE-CellSupcon、RBP-CellSupcon、HSIC-CellSupcon、Orthog-CellSupcon、MIM-CellSupcon、RCE-CE)。
图C 展示了单细胞整合的评估维度,传统评估指标主要关注前两个维度,而 scIB-E 则新增了细胞类型内生物学保留的评估维度。
图D 展示了本研究为解决细胞类型内变异保留问题而提出的新型损失函数 Corr-MSE 的原理示意图。
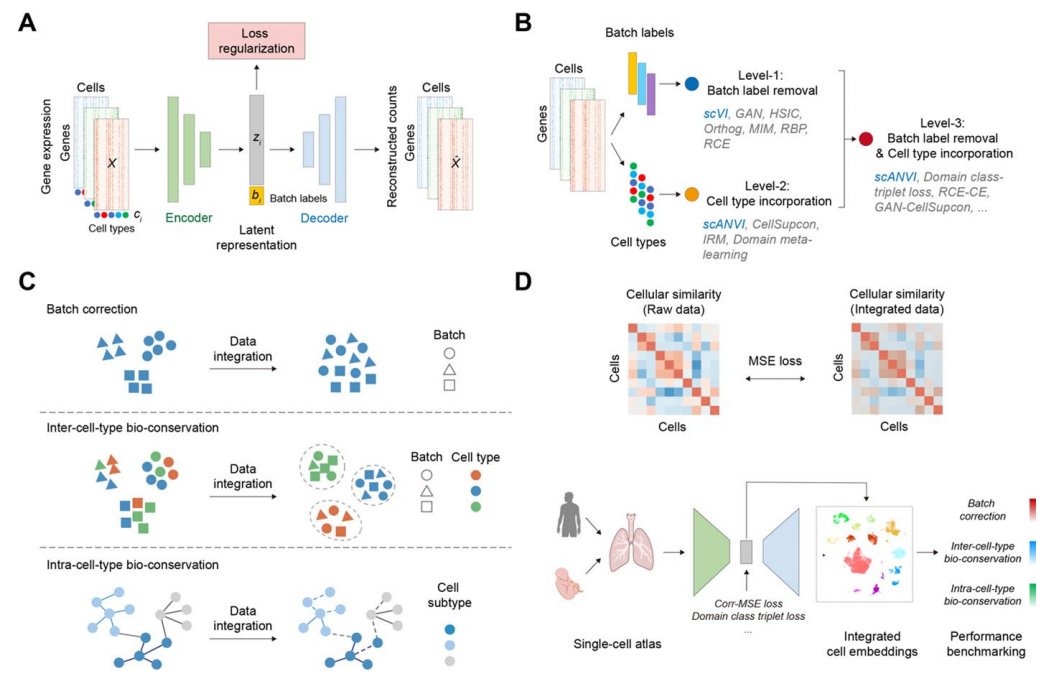
Corr-MSE 损失函数的计算
下面来看一看 Corr-MSE 损失函数是如何发挥它的作用的:
首先,对每个批次,使用整合前的原始数据(通常是经过 PCA 降维后的数据 ),单独计算该批次内所有细胞两两之间的 Pearson 相关性矩阵。这个矩阵捕获了这个批次内,哪些细胞在表达谱上更相似,哪些更不同。
然后,对于同一个批次,取出模型整合后输出的细胞嵌入 ,计算这个批次在整合后空间中的细胞相关性矩阵。
最后,计算这两个相关性矩阵之间的均方误差(MSE)。Corr-MSE 损失函数就是所有批次上 MSE 的总和。
数学表达式为:
其中, 表示批次数目, 表示批次 的原始 PCA 嵌入, 表示整合后的嵌入。Corr-MSE 损失函数要求模型在消除批次间全局差异同时,必须尽可能地保留每个批次内部细胞与细胞之间固有的相似性关系。
细胞类型内生物学保留评估维度
scIB-E 框架通过两个指标来进行细胞类型内部生物学信息保留的评估。
指标一:PCR Comparison-Batch
这个指标原本在 scIB 中用于评估批次去除效果,但这里将它作为评估 intra-cell-type Bio-conservation 的代理指标。它衡量的是在整合
前后,数据的主成分的方差中,有多少比例是可以由批次变量解释的。
为整合前的数据, 为整合后的数据, 表示批次,
表示数据 的方差能被批次 解释的比例。这个指标降低,意味着整合后数据中残留的批次信息变少,这通常是好事。
但文章中发现,当使用强细胞类型监督(也就是第 2 级损失函数的权重比较高)时,这个指标会降到一个异常低的水平。这说明它可能不仅去除了批次效应,连带着将那些与批次效应一起的细微生物学变异也去除了。比如说,如果一个细胞亚型主要出现在某一个批次中,强细胞类型监督的方法会把这种细胞亚型当成批次效应给去除掉。因此,异常低的值可以理解成被“过度校正”了。
在这个评估维度下,PCR 指标并不是越高越好,也不是越低越好,而是需要一个合理的、非极端的值,表明批次效应被有效移除,但并未伤及根本的生物学结构。
指标二:Jaccard Index
对于每个批次内部的细胞,分别构建其在整合前(PCA 空间)和整合后(嵌入空间)的
k-最近邻图。然后,为每个细胞计算其在这两个图中的邻居集合的 Jaccard 相似度(即交集大小除以并集大小),最后对所有细胞取平均值。
高 Jaccard Index 意味着整合过程忠实地保留了每个批次内部细胞的局部微观结构。细胞类型内部的发育顺序、状态梯度等关系没有被破坏。
基准评估结果
图的上半部分为不加入 Corr-MSE 损失时,各方法的 scIB-E 得分;下半部分为加入 Corr-MSE 损失后,各方法的 scIB-E 得分。
无论是否加入 Corr-MSE,Domain Class Triplet Loss 都是所有被测试损失函数中最强大,最稳健的一个。对比上下两个表格,可以直观看到,在加入了 Corr-MSE 之后,几乎所有方法的细胞内得分都得到了提升,从而也带动了总分的提高。

将同一个方法在“有 Corr-MSE ”和“无 Corr-MSE ”两种情况下的指标进行 Wilcoxon 配对检验。
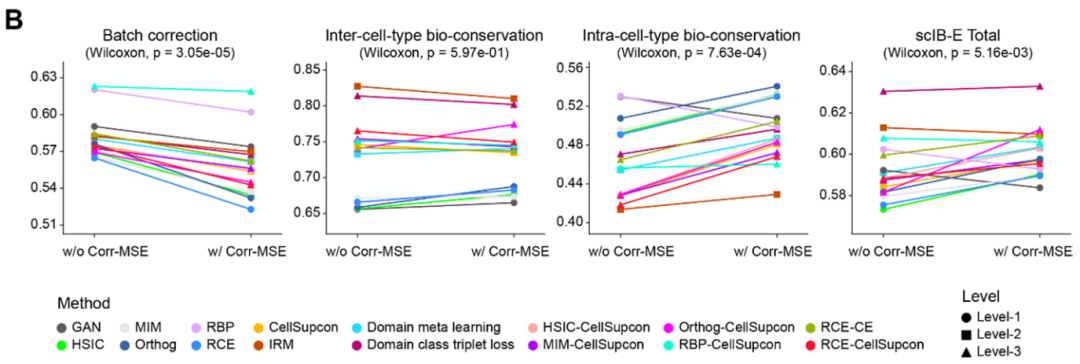
批次校正指标出现了轻微但显著的下降,这是可以理解的,因为 Corr-MSE 的目的是保留每个批次内部的结构,其中可能包含一些与批次相关的噪音,这必然会轻微影响批次的完全混合。细胞类型内生物学信息的保留出现了显著的提升。总分依旧实现了显著的净增长。
讨论
- 整合方法的性能高度依赖于信息正则化的强度,过强的正则化虽能提升细胞类型间的分离度,但会导致过度校正,牺牲细胞类型内部的细微变异。最佳整合效果并非追求单一指标的最大化,而是在去除技术噪音与保留多层次生物信号之间取得精巧的平衡。
- 如果使用细胞类型标签进行监督整合,同时在评估的时候又使用相同的细胞类型标签进行评估,会导致评估指标的得分虚高。
- Corr-MSE 虽然旨在保留批次内结构,但批次内的生物学信号本身也可能被技术噪音等无关变异所污染。因此,它保留的未必全是“纯净”的生物学信息,而真实生物信号与批次特异性噪音又是没办法区分的。








