GitHub 不装了,摊牌了。
从 4 月 24 日起,你跟 GitHub Copilot 说的每句话、输入的每段代码、接受或拒绝的每条建议,都会被拿去训练 AI 模型。
不同意?你得自己去设置里关掉。
不关,就算你默认同意了。
昨天,GitHub 首席产品官 Mario Rodriguez 发了一篇官方博客。
Copilot Free、Pro、Pro+ 用户的交互数据,会默认拿去训练 AI。
注意这个「默认」。不是询问你的意见,是通知你已经默认开启了。

你跟 Copilot 互动的几乎所有东西,都包括在内。
代码片段、生成建议、你接受还是拒绝了、光标周围的上下文、注释、文件名、仓库结构,连你给建议点的赞和踩都算。
GitHub 说已经拿微软员工的交互数据测过了,代码接受率在多个编程语言上都有提升。效果验证完了,现在要把所有人都拉进来。
GitHub 对私有仓库的定义很有说法。
官方原文是,私有仓库「静态存储」的代码不会拿去训练。
但你用 Copilot 写代码的时候,它正在实时读你私有仓库里的文件。这部分数据,GitHub 认为这属于「交互数据」,不是「静态存储」。
也就是说,你的私有代码是安全的,只要你别让 Copilot 碰它。碰了,性质就变了。

Copilot Business 和 Enterprise 企业用户不受影响。
个人开发者?一不注意你就成了高质量语料的来源。
GitHub 是全球最大的代码托管平台,1.8 亿开发者,Copilot 用户超 2000 万人。这 2000 万人跟 Copilot 的每次交互,现在多了一个用途。
科技媒体 The Register 说,「这是免费用户帮 GitHub 改进产品,企业客户花钱买数据安全。」
数据还会和 GitHub 的「关联公司」共享。也就是微软。
GitHub 承诺不与「第三方 AI 供应商」分享数据。但微软自己其实就是全球最大的 AI 供应商之一。
GitHub 社区讨论帖的投票结果说明了一切。
几乎清一色的「踩」。
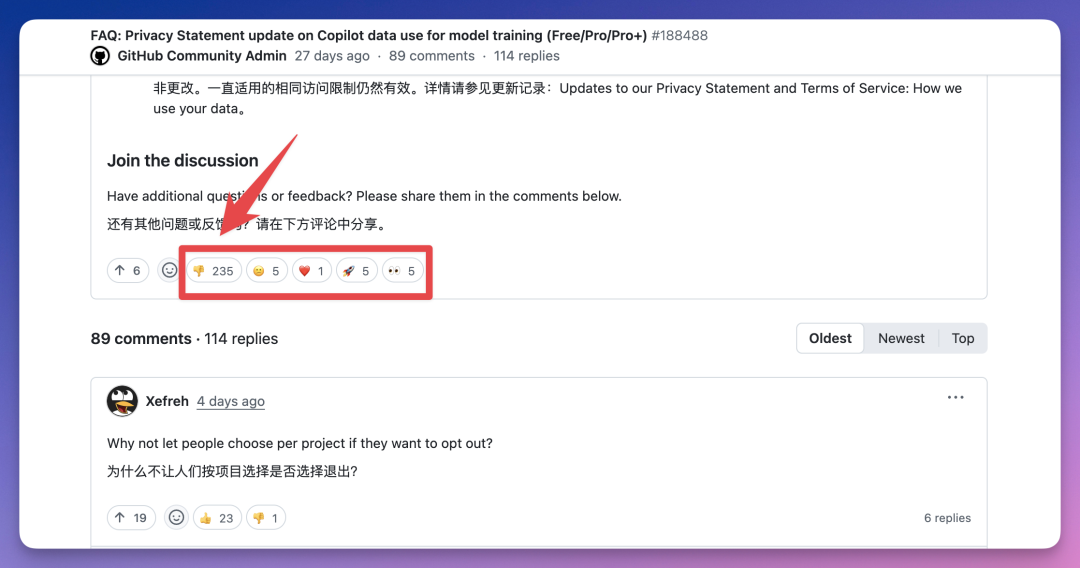
Hacker News 论坛有网友表示,「前几天刚取消勾选了数据训练选项,刷新页面后,开关又自动弹回来了。」
也有人提了个更实际的问题。Copilot 没有自动忽略 .env 配置文件的机制。
这意味着,你的 API Key、数据库密码、私钥,都可能混进训练数据里。
GitHub 自己找的挡箭牌是:「行业惯例」。
官方专门点名,Anthropic、JetBrains、微软,都有类似的「默认参加、手动退出」的数据策略。
但 Anthropic 和 JetBrains 是工具提供商。GitHub 是代码托管平台,1.8 亿开发者的代码存在这里。当平台方同时成了数据训练方,性质就不一样了。
打开 GitHub,进 Settings → Copilot,找到 Privacy 那一栏,关掉「Allow GitHub to use my data for AI model training」。
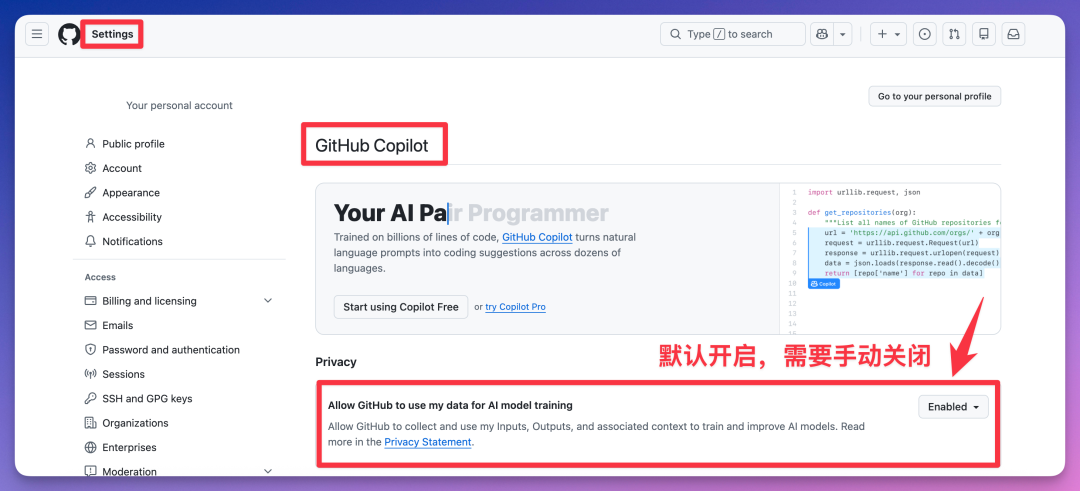
关掉不影响 Copilot 的任何功能。只是你的数据不会被拿去训练模型了。
记得 4 月 24 日之前设置。
我是木易,Top2 + 美国 Top10 CS 硕,现在是 AI 产品经理。
关注「AI信息Gap」,让 AI 成为你的外挂。









