
编者按:人工智能和大数据时代,分布式机器学习解决了大量最具挑战性的问题。为了帮助机器学习从业者更加深入地了解分布式机器学习领域的基本框架、典型算法、理论和系统,帮助大家在这个领域打下扎实基础,微软亚洲研究院机器学习核心团队撰写《分布式机器学习:算法、理论与实践》一书,全面介绍了分布式机器学习的现状,深入分析其中的核心技术问题,并且讨论该领域未来的发展方向。
本书由鄂维南院士和周志华教授倾心撰写推荐序,现已在京东上线,并跻身新书销量榜前十名,购买地址请戳“阅读原文”。

分布式机器学习并非分布式处理技术与机器学习的简单结合。一方面,它必须考虑机器学习模型构成与算法流程本身的特点,否则分布式处理的结果可能失之毫厘谬以千里;另一方面,机器学习内含的算法随机性、参数冗余性等,又会带来一般分布式处理过程所不具备的、宜于专门利用的便利。
值得一提的是,市面上关于机器学习的书籍已有许多,但是分布式机器学习的专门书籍还颇少见。
刘铁岩博士是机器学习与信息检索领域的国际著名专家,带领的微软亚洲研究院机器学习研究团队成果斐然。此次他们基于分布式机器学习方面的丰富经验推出《机器学习:分布式算法、理论与实践》一书,将是希望学习和了解分布式机器学习的中文读者的福音,必将有力促进相关技术在我国的推广和发展。
最近几年,机器学习在许多领域取得了前所未有的成功,由此也彻底改变了人工智能的发展方向,引发了大数据时代的到来。其中最富有挑战性的问题是由分布式机器学习解决的。所以,要了解机器学习究竟能够带来什么样前所未有的新机遇、新突破,就必须了解分布式机器学习。
相比较而言,机器学习这个领域本身是比较单纯的领域。其模型和算法问题基本上都可以被看成是纯粹的应用数学问题。而分布式机器学习则不然。它更像是一个系统工程,涉及到数据、模型、算法、通信、硬件等许多方面。这更增加了系统了解这个领域的难度。刘铁岩博士和他的合作者的这本书,从理论、算法和实践等多个方面对这个新的重要学科给出了系统、深刻的讨论。这无疑是雪中送炭。这样的书籍在现有文献中还难以找到。对我个人而言,这也是我早就关注,但一直缺乏系统了解的领域。所以看了这本书,对我也是受益匪浅。相信对众多关注机器学习的工作人员和学生,这也是一本难得的好书。
本书的目的,是给读者全面展示分布式机器学习的现状,深入分析其中的核心技术问题,并且讨论该领域未来发展的方向。本书既可以作为研究生从事分布式机器学习方向研究的参考文献,也可以作为人工智能从业者进行算法选择和系统设计的工具书。
全书共12章。第1章是绪论,向大家展示分布式机器学习这个领域的全景。第2章介绍机器学习的基础知识,其中涉及到的基本概念、模型和理论,会为读者在后续章节中更好地理解分布式机器学习的各项技术奠定基础。第3章到第8章是本书的核心部分,向大家细致地讲解分布式机器学习的框架,及其各个功能模块。其中第3章对整个分布式机器学习框架做综述,而第4章到第8章则针对其中的数据与模型划分模块、单机优化模块、通信模块、数据与模型聚合模块分别加以介绍,展示每个模块的不同选项并讨论其长处与短板。接下来的三个章节,是对前序内容的总结与升华。其中第9章介绍了由分布式机器学习框架中不同选项所组合出来的各式各样的分布式机器学习算法,第10章讨论了这些算法的理论性质(例如收敛性),第11章则介绍几个主流的分布式机器学习系统(包括Spark MLlib,Multiverso参数服务器系统,和TensorFlow数据流系统)。最后的第12章是全书的结语,在对全书内容进行简要总结之后,着重讨论分布式机器学习这个领域未来的发展方向。
大规模训练数据的出现为训练大模型提供了物质基础,因此近年来涌现出了很多大规模的机器学习模型。这些模型动辄可以拥有几百万、甚至几十亿个参数。一方面,这些大规模机器学习模型具备超强的表达能力,可以帮助人们解决很多难度非常大的学习问题;而另一方面,它们也有自己的弊端:非常容易过拟合(也就是在训练集上取得非常好的效果,然而在未知测试数据上则表现得无法令人满意),因此倒逼训练数据的规模;结果无可避免地导致大数据和大模型的双重挑战,从而对计算能力和存储容量都提出新的要求。计算复杂度高,导致单机训练可能会消耗无法接受的时长,因而不得不使用并行度更高的处理器、或者计算机集群来完成训练任务;存储容量大,导致单机无法满足需求,不得不使用分布式存储。在这个背景下,涌现出很多新的软、硬件技术,包括图形处理器(GPU)的兴起和大规模计算机集群的广泛使用。
GPU和CPU相比,有更强的并行度和计算能力,可以使复杂的训练过程变得更加高效。
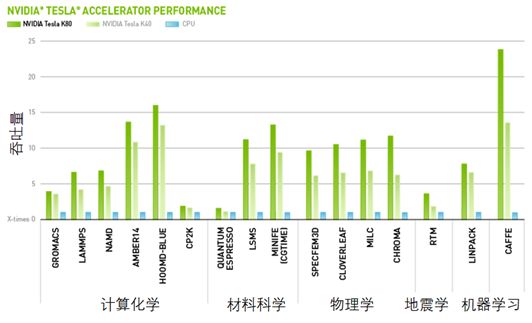
图3.1 GPU在各种计算领域的突出表现(出处:英伟达官网)
GPU的运算能力虽然很强,但是当训练数据更大、计算复杂度更高时,单块GPU还是会捉襟见肘。这时就需要利用分布式集群,尤其是GPU集群来完成训练任务。这使得亚马逊AWS、微软Azure、谷歌Google Cloud等云计算公司获得了巨大的发展机遇。之前,云计算服务的主要目的是解决企业的IT管理问题——将IT集中化、服务化;而近年来随着人工智能的飞速发展,大规模机器学习和科学计算越来越多地成为了云计算上的典型任务。比如AWS推出的P2虚拟机,包含1-16个GPU的配置选择;而Azure上的N系列虚拟机,也提供了1-4块GPU的配置选项;人们开始利用它们来实现人工智能模型的训练。与此同时,很多大型公司和学术机构开始建立属于自己的私有GPU集群。在这些大规模计算资源的支持下,如今很多前沿的学术研究和高端人工智能产品背后,都在使用包含成百上千块卡的GPU集群进行运算。
之所以需要使用分布式机器学习,大体有三种情形:一是计算量太大,二是训练数据太多,三是模型规模太大。对于计算量太大的情形,可以采取基于共享内存(或虚拟内存)的多线程或多机并行运算。对于训练数据太多的情形,需要将数据进行划分,并分配到多个工作节点上进行训练,这样每个工作节点的局部数据都在容限之内。每个工作节点会根据局部数据训练出一个子模型,并且会按照一定的规律和其他工作节点进行通信(通信的内容主要是子模型参数或者参数更新),以保证最终可以有效整合来自各个工作节点的训练结果得到全局的机器学习模型。对于模型规模太大的情形,则需要对模型进行划分,并且分配到不同的工作节点上进行训练。与数据并行不同,在模型并行的框架下各个子模型之间的依赖关系非常强,因为某个子模型的输出可能是另外一个子模型的输入,如果不进行中间计算结果的通信,则无法完成整个模型训练。因此一般而言,模型并行对通信的要求较高。读者请注意,以上三种分布式机器学习的情形在实际中通常是掺杂在一起发生的。比如,我们遇到的实际问题可能训练数据也多、模型也大、计算量也大。所以有时候不太容易清楚地划分这些不同情形的边界。如果一定要区分它们的占比,到目前为止,数据并行还是最常见的情形,因为训练数据量过大导致训练速度慢仍是分布式机器学习领域的主要矛盾。因此在本书行文过程中,我们将用大部分篇幅来讲解数据并行时需要解决的一些问题,同时也会尽量覆盖与计算并行和模型并行有关的问题。
无论是上面提到的哪种情形,分布式机器学习都可以用图3.2加以描述。它包含以下几个主要模块:数据与模型划分模块、单机优化模块、通信模块、以及数据与模型聚合模块。这些模块的具体实现和相互关系可能因不同算法和系统而异,但一些基本的原理是共通的。接下来我们会对这些模块加以简要综述。
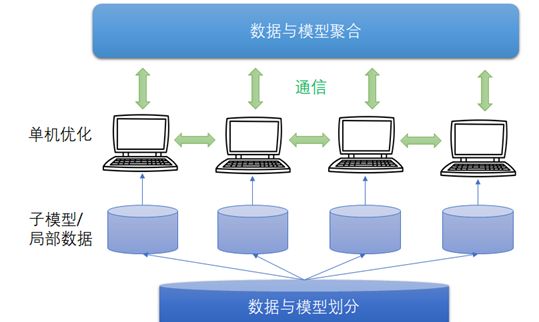
图3.2 分布式机器学习系统框架
同步和异步算法有各自的优缺点和适用场景。如果可以把它们结合起来应用,取长补短,或许可以更好地达到收敛速度与收敛精度的平衡。例如:对于机器数目很多、本地工作节点负载不均衡的集群,我们可以考虑按照工作节点的运算速度和网络连接情况进行聚类分组,将性能相近的节点分为一组。由于组内的工作节点性能相近,可以采用同步并行的方式进行训练;而由于各组间运算速度差异大,更适合采用异步并行的方式进行训练。这种混合并行方法既不会让运行速度慢的本地工作节点过度拖累全局训练速度,也不会引入过大的异步延迟从而影响收敛精度。图9.10展示了一个能够完成这种混合并行的原型系统框架。
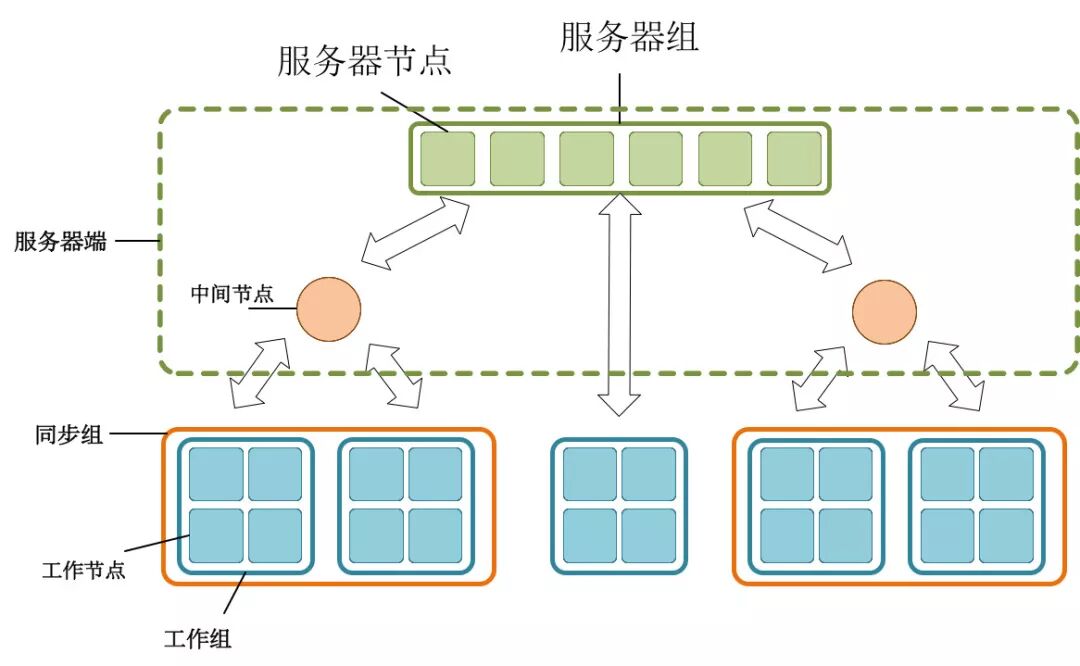
图9.10 有分组的并行机器学习系统
混合并行算法的核心挑战是如何找到一种合理的工作节点分组方式。对于分组方式的简单暴力搜索是不可行的,因为组合数非常大。比如对于16个工作节点组成的集群,不同的分组情况有10,480,142,147种。一种比较实用的方法是对工作节点按照某种指标进行聚类,再按照聚类结果,采用组内同步、组间异步的方式来规划分布式机器学习系统的运行逻辑。不过,显而易见,当采取不同的指标时, 聚类的结果会有很大差别。为了取得更好的聚类效果,我们可以利用另外一个机器学习模型,也就是采取所谓元学习(meta learning或learning to learn)的思路。
图9.11给出了一个可行的元学习系统流程:首先针对工作节点和运行的学习任务提取一系列的特征。工作节点的特征可以包括CPU/GPU的计算性能、内存、硬盘的信息,以及工作节点两两之间的网络连接情况等;学习任务的特征可以包括数据的维度,模型的大小和结构等。我们可以首先利用工作节点的特征,采用层次聚类的方法得到若干候选分组。然后用这些候选分组在抽样的数据集上进行试训练,得到分布式训练的速度(比如到达特定的精度所需要的时间)。而后针对这些分组和学习任务的特征,训练一个预测优化速度的神经网络模型。利用这个模型对于未知的候选分组进行打分,最终找到这个任务上最好的分组。
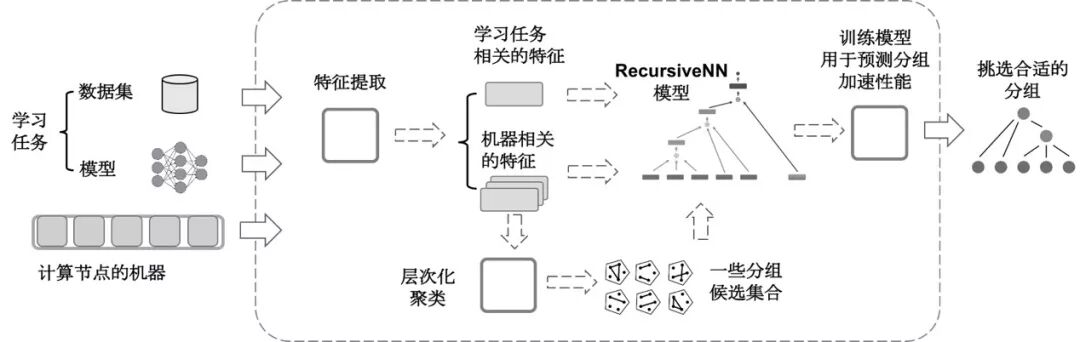
图9.11 一种可行的混合并行选取框架

刘铁岩,微软亚洲研究院副院长。刘博士的先锋性研究促进了机器学习与信息检索之间的融合,被国际学术界公认为“排序学习”领域的代表人物。近年来他在深度学习、分布式学习、强化学习等方面也颇有建树,发表论文200余篇,被引用近两万次。多次获得最佳论文奖、最高引用论文奖、Springer十大畅销华人作者、Elsevier 最高引中国学者等。受邀担任了包括SIGIR、WWW、KDD、ICML、NeurIPS、AAAI、ACL在内顶级国际会议的程序委员会主席或领域主席和多家国际学术期刊副主编。他被聘为卡内基-梅隆大学(CMU)客座教授、诺丁汉大学荣誉教授、中国科技大学教授、博士生导师;他被评为国际电子电气工程师学会(IEEE)会士,国际计算机学会( ACM)杰出会员。他担任了中国计算机学会青工委副主任,中文信息学会信息检索专委会副主任,中国云体系创新战略联盟常务理事。他的团队发布了LightLDA、LightGBM、Multiverso等知名的机器学习开源项目,并且为微软CNTK项目提供了分布式训练的解决方案,他的团队所参与的开源项目在Github上已累计获得2万余颗星。
陈薇,微软亚洲研究院机器学习组主管研究员,研究机器学习各个分支的理论解释和算法改进,尤其关注深度学习、分布式机器学习、强化学习、博弈机器学习、排序学习等。陈薇于2011年于中国科学院数学与系统科学研究院获得博士学位,同年加入微软亚洲研究院,负责机器学习理论项目,先后在NeurIPS、ICML、AAAI、IJCAI等相关领域顶级国际会议和期刊上发表文章。
王太峰,蚂蚁金服人工智能部总监、资深算法专家。他在蚂蚁金服负责AI算法组件建设,包括文本理解,图像理解,在线学习,强化学习等等,算法工作服务于蚂蚁金服的支付,国际,保险等多条业务线。在加入蚂蚁之前他在微软亚洲研究院工作11年,任主管研究员,他的研究方向包括大规模机器学习,数据挖掘,计算广告学等等。他在国际顶级的机器学习会议上发表近20篇的论文和4次大规模机器学习专题讲座,并被多次邀请为各个会议程序委员。他目前还是中国人工智能开源软件发展联盟的副秘书长,他在大规模机器学习工具开源方面也做出过很多贡献,在微软期间主持开发过DMTK的开源项目,在Github上获得综述超过8千的点赞,获得广泛的好评。
高飞,微软亚洲研究院副研究员,主要从事分布式机器学习和深度学习的研究工作,并在国际会议上发表多篇论文。2014年设计开发了当时规模最大的主题模型算法和系统LightLDA。他还开发了一系列分布式机器学习系统,并通过微软分布式机器学习工具包(DMTK)开源在GITHUB上。
本书已经在京东上架。点击“阅读原文”,直达购买页面









