《Python
TensorFlow机器学习实战》通过开发实例和项目案例,详细介绍TensorFlow开发所涉及的主要内容。书中的每个知识点都通过实例进行通俗易懂的讲解,便于读者轻松掌握有关TensorFlow开发的内容和技巧,并能够得心应手地使用TensorFlow进行开发。《Python
TensorFlow机器学习实战》内容共分为11章,首先介绍TensorFlow的基本知识,通过实例逐步深入地讲解线性回归、支持向量机、神经网络算法和无监督学习等常见的机器学习算法模型。然后通过TensorFlow在自然语言文本处理、语音识别、图形识别和人脸识别等方面的成功应用讲解TensorFlow的实际开发过程。《Python TensorFlow机器学习实战》适合有一定Python基础的工程师阅读;对于有一定基础的读者,可通过《Python
TensorFlow机器学习实战》快速地将TensorFlow应用到实际开发中;对于高等院校的学生和培训机构的学员,《Python
TensorFlow机器学习实战》也是入门和实践机器学习的优秀教材。
对于语音识别的目标就是听懂人员语言,最基础的一类语言就是数字。在本文中,我们将创建一个简单的英文数字识别器。
对于识别英文数字,在训练数据集上,我们选择spoken_numbers_pcm数据集。该数据集是许多人阅读0~9这十个数字英文的音频,分男声和女声。在数据集中的一段音频(wav文件)只有一个数字对应英文声音,文件名的命名方法为“数字_人名_xxx”,例如:
8_Susan_200.wav
8_Kate_300.wav
对于数据的预处理主要是对音频文件的声学特征的提取,采用最常用的梅尔频率倒谱系数(MFCC)方法[1],具体实现如下:

由于输入数据只是某一个数字的读音,是单个声音元素的处理,不需要额外使用声学模型和字典。对于训练网络使用LSTM循环神经网络。使用TFLearn第三方库来实现,具体实现如下:

对于识别模型的训练,并在完成训练后保存模型。具体实现如下:
01 model = tflearn.DNN(net, tensorboard_verbose=0)
02 while 1:
03 model.fit(trainX,trainY, n_epoch=10, validation_set=(testX, testY), show_metric=True,
batch_size=batch_size)
04 _y=model.predict(X)
05 model.save("tflearn.lstm.model")
使用训练的模型,任意输入一个数据集中的文件,进行预测评估,具体实现如下:
demo_file="8_Susan_200.wav"
demo=speech_data.load_wav_file(speech_data.path+demo_file)
result=model.predict([demo])
result=numpy.argmax(result)
print("the file is %s :result is %d"%(demo_file,result))
在完成了模型的训练后,运行该代码进行测试,其结果如下:
the file is 8_Susan_200.wav :result is 8
结果是准确的,能够正确的识别出数字为“8”。
对于简单的数字语音识别的训练模型较简单而且训练的准确率也较高。
除了能够听懂数字,机器学习也能听懂中文。在进行英文数字这样的单音素的语音识别时,由于输入音素和识别结果这样的场景相对简单,在实现的过程也相对简单。但是对于真实环境中的自然语言的语音识别就需要增加语音的前期处理,主要包括词汇表的生成等。
接下来,我们详细讲解一个简单中文语音识别的构建。
在数据集上,我们使用公开的清华大学连续普通话数据库(THCHS-30),是清华大学录制的30小时中文语音库。该语料库文本选取大量的新闻稿件,由大学生使用流利的普通话在安静的办公室环境下进行录音的,总时长超过30个小时。数据集文件如下:
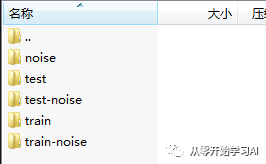
图1 THCHS-30数据集
数据集按照有无噪声分为了两类。
对于无噪音数据集,分别存放在train文件夹和test文件夹中,区别了训练数据集和测试数据集。对训练数据集train文件夹中的数据分为了ABC三组。A组的句子ID是0~249,B组的句子ID是250~499,C组的句子ID是500~749,这三组共包括30个人的10893句发音,主要作为训练数据集。对测试数据集test文件夹的数据分为D组一组,D组的句子ID是751~1000,包括10个人的2496句发音,用来做测试。
对于噪音集,分别存放在noise文件夹、train-noise文件夹以及test-noise文件夹中。其中,noise文件夹中,存放的是白噪声,如汽车噪声和咖啡馆噪声等。train-noise文件夹和test-noise文件夹分别存放的是原始录音和噪声进行了波形混合之后的结果。
对于数据集的处理,主要包括了原始数据的获取、生成词汇表、转化词编码等步骤。
1.原始数据获取
在数据集中包括了训练用的音频文件和对应的文本文件。首先,我们获取音频文件,具体实现如下:

在文本文件是语音对应的文本,将文本文件作为语音文件的标签进行一一对应,具体实现如下:

2.生成词汇表
从训练数据中提取出所有的单词,并统计各个单词出现的次数,生成使用的词汇表,具体实现如下:
01 all_words = []
02 for label inlabels:
03 all_words += [wordfor word in label]
04 counter =Counter(all_words)
05 count_pairs =sorted(counter.items(), key=lambda x: -x[1])
06 words, _ =zip(*count_pairs)
07 words_size =len(words)
08 print(u"词汇表大小:", words_size)
3.生成词编码
对于语音的输入,需要根据词汇表进行编码,然后才能使用。编码过程具体实现如下:
01 word_num_map =dict(zip(words, range(len(words))))
02 to_num = lambda word:word_num_map.get(word, len(words))
03 # 将单个file的标签映射为num 返回对应list,最终all file组成嵌套list
04 labels_vector =[list(map(to_num, label)) for label in labels]
完成了对应的词汇映射后,为了后续分块处理,获取最长句子的字数以及最长的语音长度,具体实现如下:
01 label_max_len =np.max([len(label) for label in labels_vector])
02 print(u"最长句子的字数:" + str(label_max_len))
03 wav_max_len=0
04 for wav in wav_files:
05 wav,sr =librosa.load(wav,mono=True)#处理语音信号的库librosa
06 #加载音频文件作为a floating point time series
07 mfcc=np.transpose(librosa.feature.mfcc(wav,sr),[1,0])# 特征提取函数,转置特征参数
08 iflen(mfcc)>wav_max_len:
09 wav_max_len =len(mfcc)
10 print("最长的语音", wav_max_len)
由于涉及识别问题,考虑使用卷积神经网络。为了提高在训练过程中的效果,使用在残次网络(Residual Network)这种在深神经网络算法中常用的技巧。
1.神经网络架构
对于整体神经网络的架构实现如下:

对于上述实现的神经网络模型中,在conv1d_layer卷积层中完成对应的卷积处理,具体实现如下:

对于aconv1d_layer的具体实现如下:

2.获取每批数据
在实际训练中,对于每批次数据进行处理。在数据的处理中个,主要包括了数据的转化、对齐等,具体实现如下:
01 batch_size=8 #每次取8个文件
02 n_batch = len(wav_files)//batch_size
03 pointer =0 #全局变量初值为0,定义该变量用以逐步确定batch
04 def get_next_batches(batch_size): #获取批次数据方法
05 global pointer
06 batches_wavs = []
07 batches_labels = []
08 for i inrange(batch_size):
09 wav,sr=librosa.load(wav_files[pointer],mono=True)
10 mfcc=np.transpose(librosa.feature.mfcc(wav,sr),[1,0])
11 batches_wavs.append(mfcc.tolist()) #转换成列表表存入
12 batches_labels.append(labels_vector[pointer])
13 pointer+=1
14 #补0对齐
15 for mfcc inbatches_wavs:
16 whilelen(mfcc)
17 mfcc.append([0]*20)
18 for label inbatches_labels:
19 whilelen(label)
20 label.append(0)
21 returnbatches_wavs,batches_labels
22 X=tf.placeholder(dtype=tf.float32,shape=[batch_size,None,20]) #定义输入格式
23 sequence_len =tf.reduce_sum(tf.cast(tf.not_equal(tf.reduce_sum(X,reduction_indices=2),
0.), tf.int32), reduction_indices=1)
24 Y= tf.placeholder(dtype=tf.int32,shape=[batch_size,None]) #输出格式
使用数据集数据对构建的识别模型进行训练,并在完成训练后保存模型。具体实现如下:
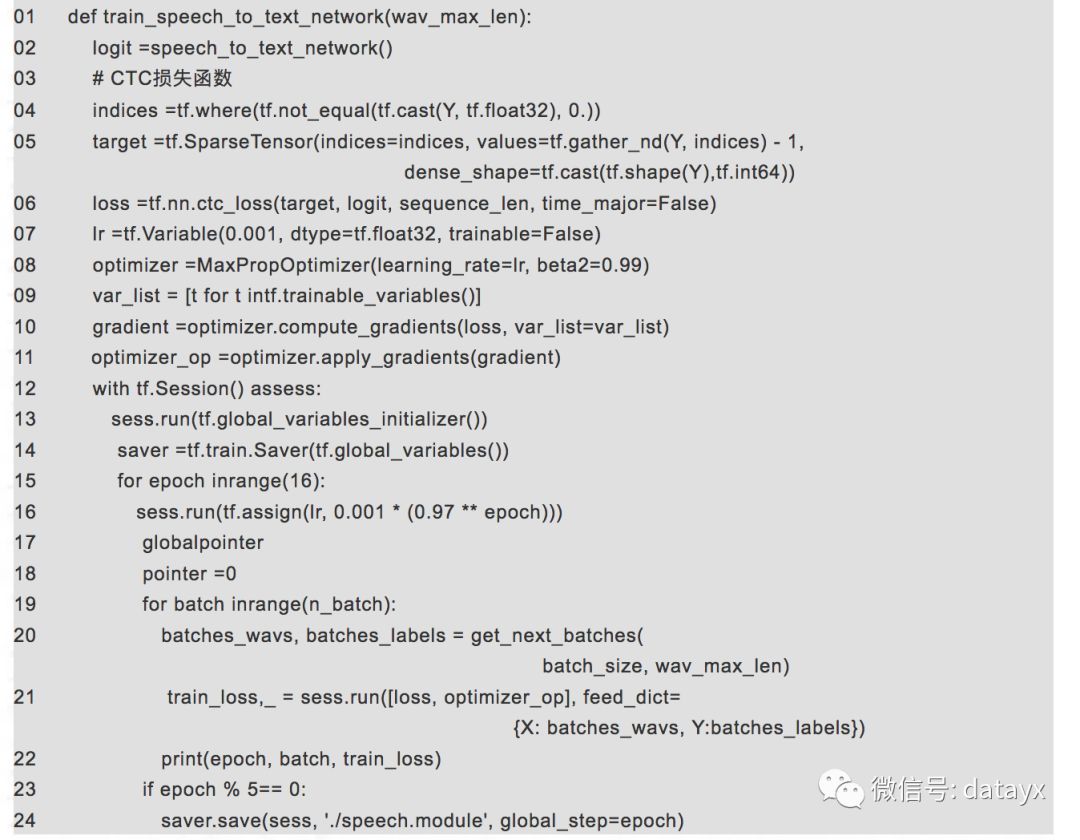
对于数据的训练时间和使用的设备性能有关,如果使用非GPU进行训练的话,一般时间会在2到3天。
完成了对模型的构建和训练。接下来使用测试数据集中的数据对模型进行测试,具体实现如下:

通过本节的练习,我们掌握了最基础的语言识别的处理方式。
本文章摘自---清华大学出版社《Python+TensorFlow机器学习实战》一书中











