
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
深度学习在个性化推荐中的应用
深度学习的概念源于人工神经网络的研究。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的有效表示,而这种使用相对较短、稠密的向量表示叫做分布式特征表示(也可以称为嵌入式表示)。本部分主要对于目前使用较广的一些学习算法进行一个简单的回顾。
首先介绍一些浅层的分布式表示模型。目前在文本领域,浅层分布式表示模型得到了广泛的使用,例如word2vec、GloVec、fasttext等 [2]。与传统词袋模型对比,词嵌入模型可以将词或者其他信息单元(例如短语、句子和文档等)映射到一个低维的隐含空间。在这个隐含空间中,每个信息单元的表示都是稠密的特征向量。词嵌入表示模型的基本思想实际还是上来自于传统的“Distributional semantics”[3],概括起来讲就是当前词的语义与其相邻的背景词紧密相关。因此,词嵌入的建模方法就是利用嵌入式表示来构建当前词和背景词之间的语义关联。相比多层神经网络,词嵌入模型的训练过程非常高效,而且实践效果很好、可解释性也不错,因此得到了广泛的应用
对应于神经网络模型,最为常见的模型包括多层感知器、卷积神经网络、循环神经网络、递归神经网络等 [4]。多层感知器主要利用多层神经元结构来构建复杂的非线性特征变换,输入可以为提取得到的多种特征,输出可以为目标任务的标签或者数值,本质上可以构建一种复杂的非线性变换;卷积神经网络可以直接部署在多层感知器上,感知器的输入特征很有可能是不定长或者有序的,通过多个卷积层和子采样层,最终得到一个固定长度的向量。循环神经网络是用来对于时序序列建模的常用模型,刻画隐含状态的关联性,可以捕捉到整个序列的数据特征。针对简单的循环神经网络存在长期依赖问题(“消失的导数”),不能有效利用长间隔的历史信息,两个改进的模型是长短时记忆神经网络(LSTM) 和基于门机制的循环单元(GRU)。递归神经网络根据一个外部给定的拓扑结构,不断递归得到一个序列的表示,循环神经网络可以被认为是一种简化的递归神经网络。
应用
1.相似匹配
1.1.嵌入式表示模型
通过行为信息构建用户和物品(或者其他背景信息)的嵌入式表示,使得用户与物品的嵌入式表示分布在同一个隐含向量空间,进而可以计算两个实体之间的相似性。
很多推荐任务,本质可以转换为相关度排序问题,因此嵌入式表示模型是一种适合的候选方法。一般来说,浅层的嵌入式表示模型的训练非常高效,因此在大规模数据集合上有效性和复杂度都能达到不错的效果。
在[5]中,嵌入式表示被应用到了产品推荐中,给定一个当前待推荐的产品,其对应的生成背景(context)为用户和上一个交易的产品集合,利用这些背景信息对应的嵌入式表示向量可以形成一个背景向量,刻画了用户偏好和局部购买信息的依赖关系。然后基于该背景向量,生成当前待推荐的产品。经推导,这种模型与传统的矩阵分解模型具有很强的理论联系。在[6]中,Zhao等人使用doc2vec模型来同时学习用户和物品的序列特征表示,然后将其用在基于特征的推荐框架中,引入的嵌入式特征可以在一定程度上改进推荐效果。在[7]中,嵌入式表示模型被用来进行地点推荐,其基本框架就是刻画一个地理位置的条件生成概率,考虑了包括用户、轨迹、临近的地点、类别、时间、区域等因素。
1.2.语义匹配模型
[8]深度结构化语义模型(Deep Structured Semantic Models,简称为DSSM)是基于多层神经网络模型搭建的广义语义匹配模型 。其本质上可以实现两种信息实体的语义匹配。基本思想是设置两个映射通路,两个映射通路负责将两种信息实体映射到同一个隐含空间,在这个隐含空间,两种信息实体可以同时进行表示,进一步利用匹配函数进行相似度的刻画。
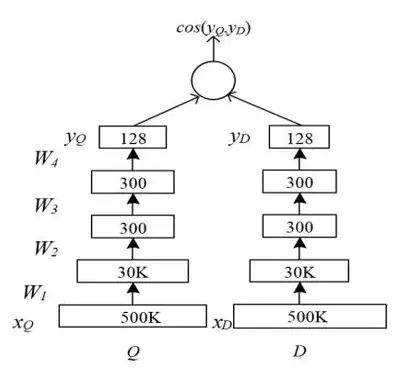
DSSM
如图展示了一个DSSM的通用示意图,其中Q表示一个Query,D表示一个Document,对应到推荐系统里面的用户和物品。通过级联的深度神经网络模型的映射与变换,最终Query和Document在同一个隐含空间得到了表示,可以使用余弦相似度进行计算。DSSM最初主要用在信息检索领域,用来刻画文档和查询之间的相似度。
[9]随后被用在推荐系统中:一端对应着用户信息,另外一端对应着物品信息 。以DSSM为主的这些工作的基本出发点实际上和浅层嵌入式表示模型非常相似,能够探索用户和物品两种不同的实体在同一个隐含空间内的相似性。其中一个较为关键的地方,就是如何能够融入任务特定的信息(例如物品内容信息)以及模型配置(例如可以使用简单多层神经网络模型或者卷积神经网络模型),从而获得理想的结果。
2.评分预测
2.1.基于用户的原始评分(或者反馈)来挖掘深度的数据模式特征(神经网络矩阵分解)
[10]限制玻尔兹曼机进行评分预测。
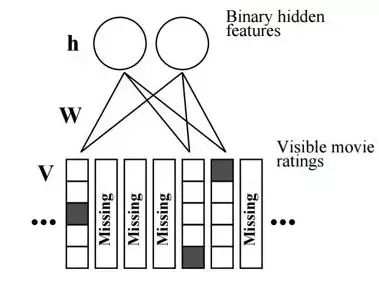
限制玻尔兹曼机
如图所示,其所使用的模型具有一个两层的类二部图结构,其中用户层为隐含层 (h),可见层为用户的评分信息 (V),通过非线性关联两层上的数据信息。其中隐含层为二元变量,而用户评分信息被刻画为多项式分布变量。建立用户隐含表示信息以及其评分信息的联合能量函数,然后进行相应的参数求解。该方法的一个主要问题是连接隐含层和评分层的权重参数规模过大(对于大数据集合),也就是权重矩阵W。
[11]优化计算的改进,作者进一步提出使用将W分解为两个低秩矩阵,减小参数规模。不过实验效果表明所提出的方法并没有比基于矩阵分解的方法具有显著的改进,而且参数求解使用较为费时的近似算法。
[12]优化改进,Zheng 等人提出使用Neural Autoregressive Distribution Estimator来改进上述问题,该方法不需要显式对于二元隐含变量进行推理,减少了模型复杂度,并且使用排序代价函数来进行参数最优化。实验表明所提出的方法能够取得非常好的效果。
[13]Wu等人使用去噪自动编码模型(Denoising Autoencoder)进行top-N物品推荐,其输入为加入噪声的对于物品的偏好(采纳为1,否则为0),输出为用户对于物品的原始评分,通过学习非线性映射关系来进行物品预测。
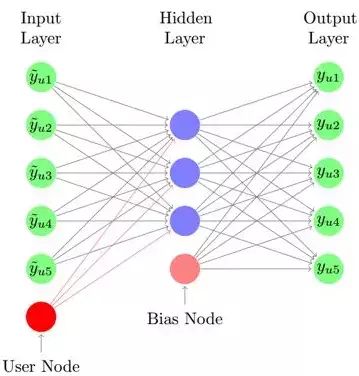
去噪自动编码模型
如图所示,用户可见的评分数据通过加上噪音后进入输入层,然后通过非线性映射形成隐含层,再由隐含层经映射后重构评分数据。注意,该模型中加入了用户偏好表示(User Node)和偏置表示(Bias Node)。
[14]Devooght提出将协同过滤方法可以看作时间序列的预测问题。
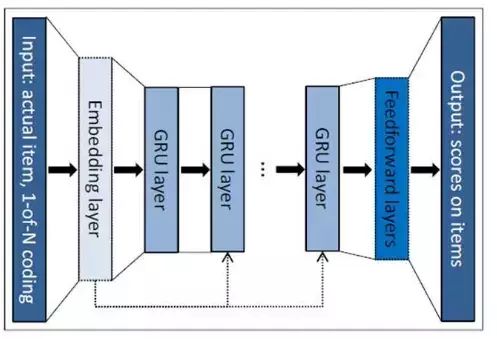
CFRNN
作者提出,传统基于协同过滤的推荐方法,无论基于何种特征,都没有考虑用户历史行为的时间属性,只是将历史行为中的每个item统一考虑。这样处理带来的最大问题在于推荐系统无法分析用户喜好的变化情况,从而给出更符合用户现阶段喜好的推荐结果。那么,如果基于协同过滤“由过去,看未来”的思想,如果将该问题视作序列预测问题,一方面可以更好的分析用户的兴趣爱好的变化情况给出更好的推荐结果,另一方面也可以将在时序预测问题中广泛使用的RNN深度网络模型引入到推荐系统中。
[15]NCF 作者提出一种通用的神经网络协同过滤框架,通过用神经网络结构多层感知机去学习用户-项目之间交互函数替代传统的矩阵分解中的内积运算,从而从数据中学习任意函数(非线性)。
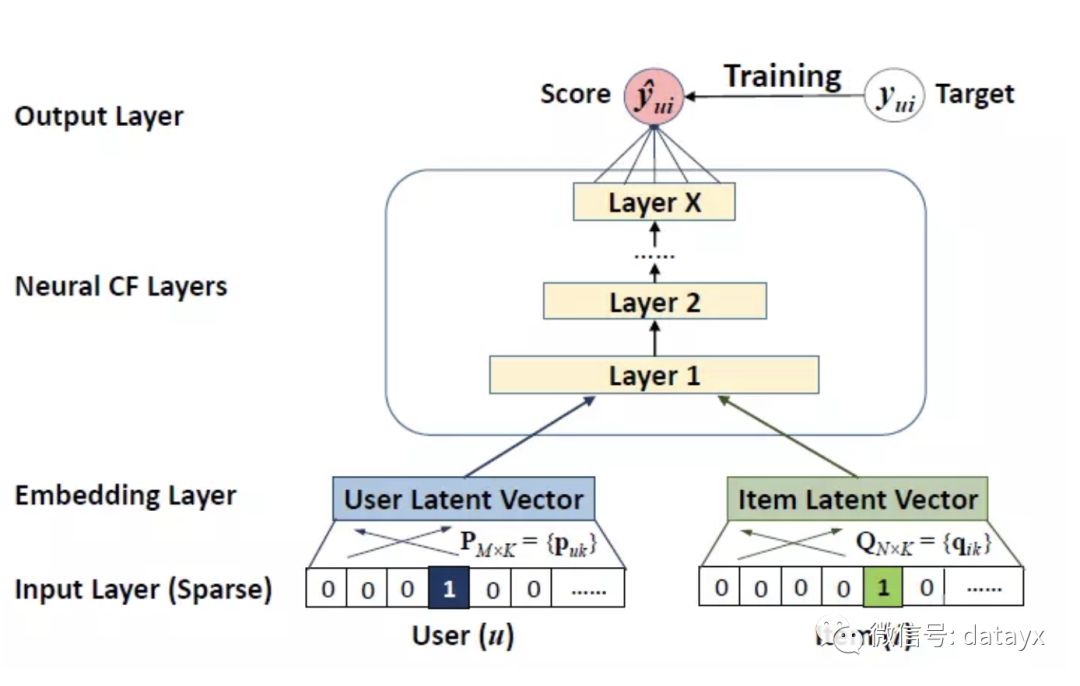
CFDNN
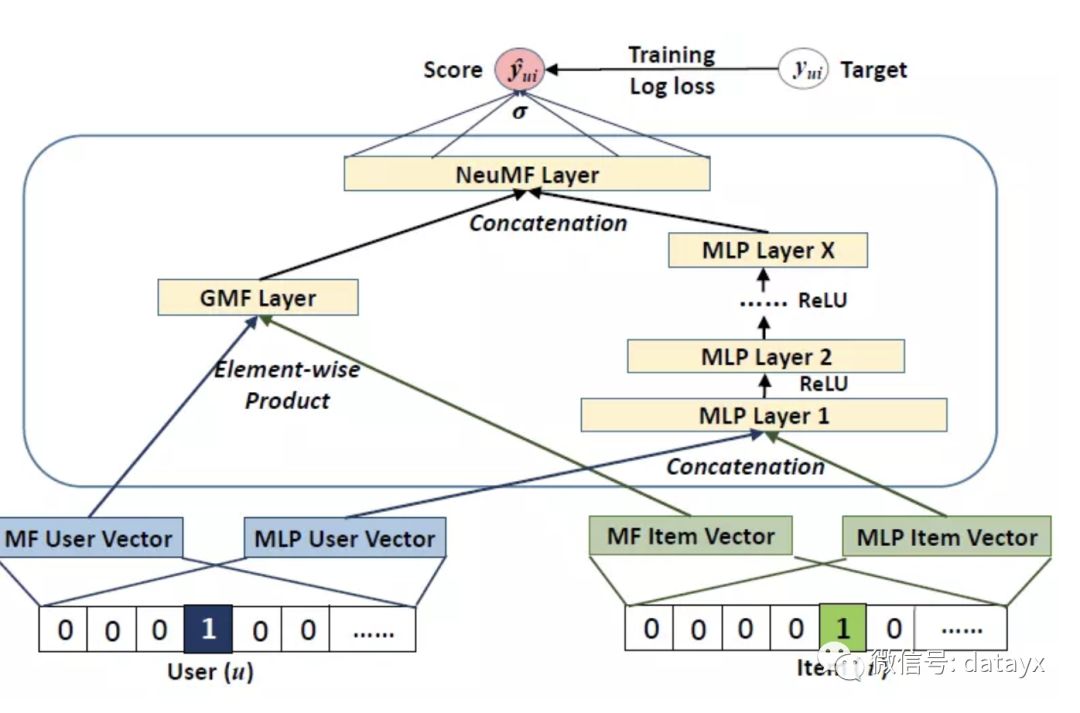
并提出了两种NCF实例:基于线性核的GMF(广义矩阵分解),基于非线性核的MLP。并且将GMF与MLP融合,使他们相互强化。(tf model zoo)
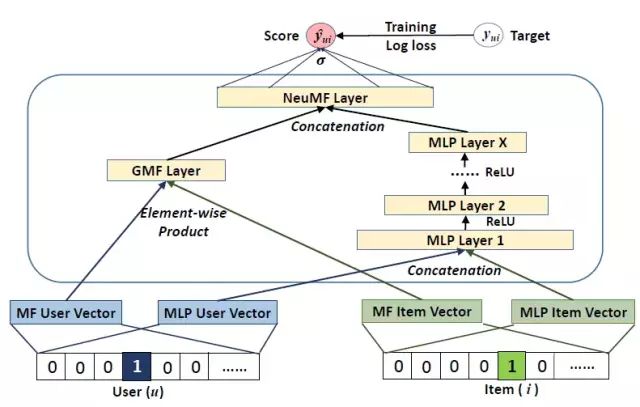
CFDNN2
3.排序
Deep CTR [https:/mp.weixin.qq.com/s/xWqpIHHISSkO97O_fKkb6A]
DeepCTR
3.1. 总结(结论先行)
FM其实是对嵌入特征进行两两内积实现特征二阶组合;FNN 在 FM 基础上引入了 MLP;
2.DeepFM通过联合训练、嵌入特征共享来兼顾 FM 部分与 MLP 部分不同的特征组合机制;
3.NFM、PNN 则是通过改造向量积的方式来延迟FM的实现过程,在其中添加非线性成分来提升模型表现力;
4.AFM 更进一步,直接通过子网络来对嵌入向量的两两逐元素乘积进行加权求和,以实现不同组合的差异化,也是一种延迟 FM 实现的方式;
5.DCN 则是将 FM 进行高阶特征组合的方向上进行推广,并结合 MLP 的全连接式的高阶特征组合机制;
6.Wide&Deep 是兼容手工特征组合与 MLP 的特征组合方式,是许多模型的基础框架;
7.Deep Cross 是引入残差网络机制的前馈神经网络,给高维的 MLP 特征组合增加了低维的特征组合形式,启发了 DCN;
8.DIN 则是对用户侧的某历史特征和广告侧的同领域特征进行组合,组合成的权重反过来重新影响用户侧的该领域各历史特征的求和过程;
9.多任务视角则是更加宏观的思路,结合不同任务(而不仅是同任务的不同模型)对特征的组合过程,以提高模型的泛化能力。
3.2. DNN
深度排序模型( embedding-神经网络),embedding+MLP 是对于分领域离散特征进行深度学习 CTR 预估的通用框架。深度学习在特征组合挖掘(特征学习)方面具有很大的优势。比如以 CNN 为代表的深度网络主要用于图像、语音等稠密特征上的学习,以 W2V、RNN 为代表的深度网络主要用于文本的同质化、序列化高维稀疏特征的学习。CTR 预估的主要场景是对离散且有具体领域的特征进行学习,所以其深度网络结构也不同于 CNN 与 RNN。
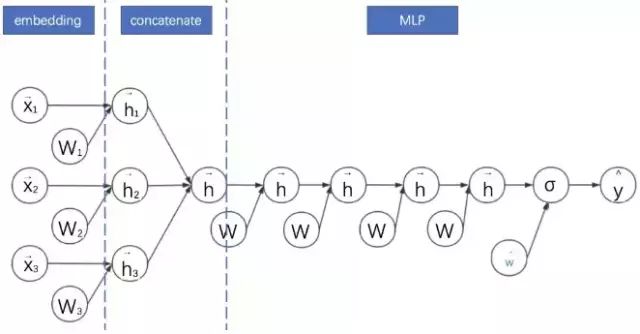
embedding_mlp
embedding+MLP 的过程如下:
对不同领域的 one-hot 特征进行嵌入(embedding),使其降维成低维度稠密特征。
然后将这些特征向量拼接(concatenate)成一个隐含层。
之后再不断堆叠全连接层,也就是多层感知机(Multilayer Perceptron, MLP,有时也叫作前馈神经网络)。
最终输出预测的点击率。
3.3. Wide & Deep Network(连续特征->交叉特征+LR、离散特征->onehot->DNN)
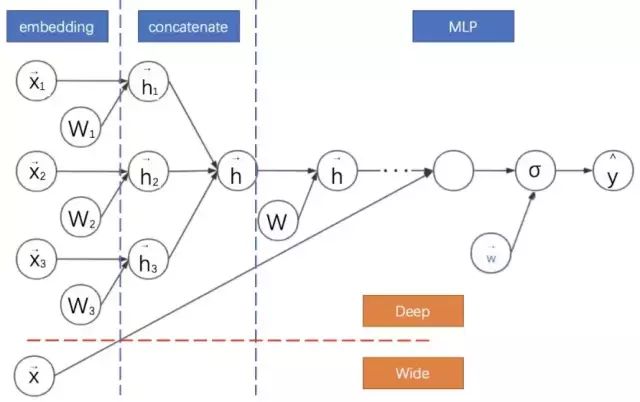
Wide and Deep Network
Google 在 2016 年提出的宽度与深度模型(Wide&Deep)在深度学习 CTR 预估模型中占有非常重要的位置,它奠定了之后基于深度学习的广告点击率预估模型的框架。Wide&Deep将深度模型与线性模型进行联合训练,二者的结果求和输出为最终点击率。其计算图如下:
3.4. DeepFM
在Wide & Deep Network基础上进行的改进,DeepFM的Wide部分是 FM
3.5. Deep & Cross Network(特征->cross netword+LR、DNN)
Ruoxi Wang 等在 2017 提出的深度与交叉神经网络(Deep & Cross Network,DCN)借鉴了FM的特征点击交叉。DCN 的计算图如下:
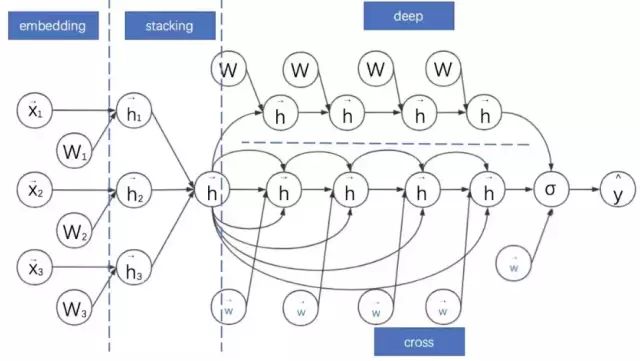
Deep and Cross Network
DCN 的特点如下:
1. Deep 部分就是普通的 MLP 网络,主要是全连接。
2. 与 DeepFM 类似,DCN 是由 embedding + MLP 部分与 cross 部分进行联合训练的。Cross 部分是对 FM 部分的推广。
3. Cross 部分的公式如下:
4. 可以证明,cross 网络是 FM 的过程在高阶特征组合的推广。完全的证明需要一些公式推导,感兴趣的同学可以直接参考原论文的附录。
5. 而用简单的公式证明可以得到一个很重要的结论:只有两层且第一层与最后一层权重参数相等时的 Cross 网络与简化版 FM 等价。
6. 此处对应简化版的 FM 视角是将拼接好的稠密向量作为输入向量,且不做领域方面的区分(但产生这些稠密向量的过程是考虑领域信息的,相对全特征维度的全连接层减少了大量参数,可以视作稀疏链接思想的体现)。而且之后进行 embedding 权重矩阵 W 只有一列——是退化成列向量的情形。
7. 与 MLP 网络相比,Cross 部分在增加高阶特征组合的同时减少了参数的个数,并省去了非线性激活函数
3.6. DIN [Deep Interest Network]对同领域历史信息引入注意力机制的MLP
以上神经网络对同领域离散特征的处理基本是将其嵌入后直接求和,这在一般情况下没太大问题。但其实可以做得更加精细。
由 Bahdanau et al. (2015) 引入的现代注意力机制,本质上是加权平均(权重是模型根据数据学习出来的),其在机器翻译上应用得非常成功。受注意力机制的启发,Guorui Zhou 等在 2017 年提出了深度兴趣网络(Deep Interest Network,DIN)。DIN 主要关注用户在同一领域的历史行为特征,如浏览了多个商家、多个商品等。DIN 可以对这些特征分配不同的权重进行求和。其网络结构图如下:
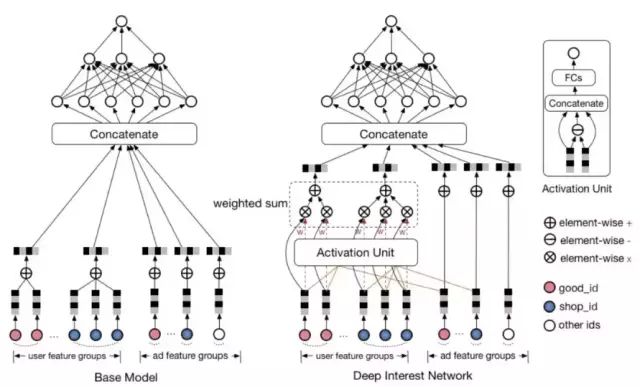
Deep Interest Network
此处采用原论文的结构图,表示起来更清晰。
DIN 考虑对同一领域的历史特征进行加权求和,以加强其感兴趣的特征的影响。
用户的每个领域的历史特征权重则由该历史特征及其对应备选广告特征通过一个子网络得到。即用户历史浏览的商户特征与当前浏览商户特征对应,历史浏览的商品特征与当前浏览商品特征对应。
权重子网络主要包括特征之间的元素级别的乘法、加法和全连接等操作。
AFM 也引入了注意力机制。但是 AFM 是将注意力机制与 FM 同领域特征求和之后进行结合,DIN 直接是将注意力机制与同领域特征求和之前进行结合。
3.7. FM -> FNN -> NFM -> PNN -> AFM
LR:
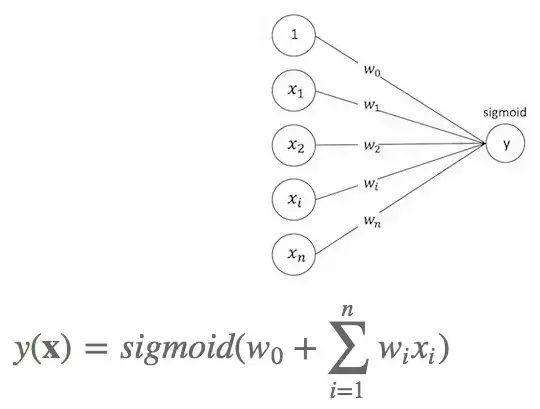
LR
FM:
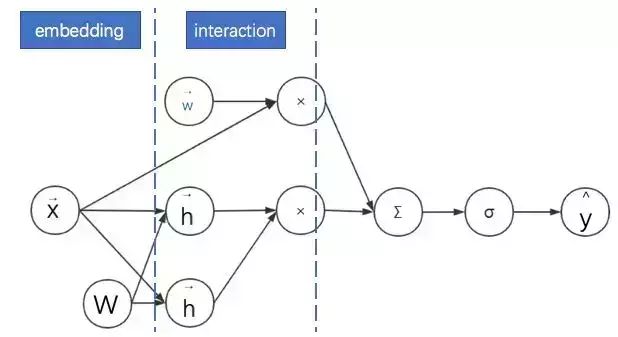
FM2
FNN:FM隐向量 + 拼接 + MLP
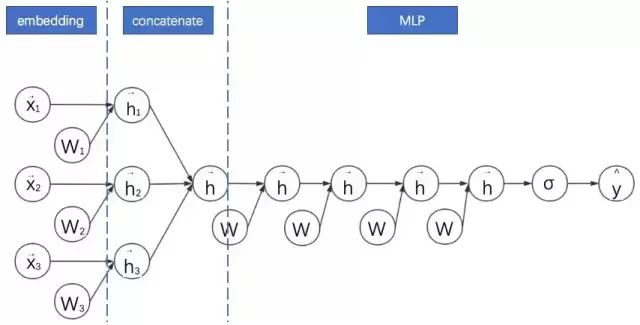
FNN
NFM:FM隐向量 + 特征交叉(逐元素向量乘法)+ 求和 + MLP
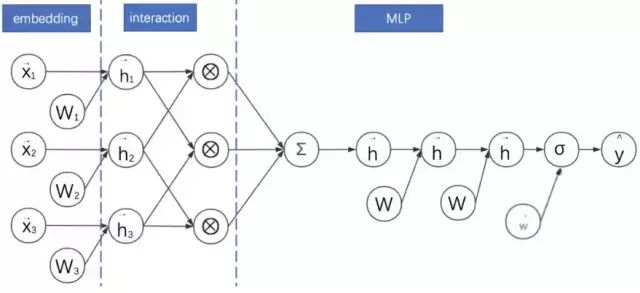
NFM
PNN:与NFM类似,特征交叉法采用了向量积的方法 + 拼接 + mlp
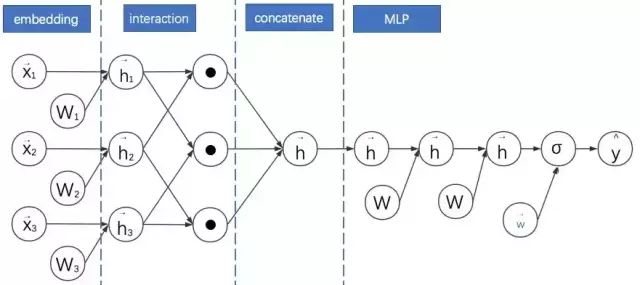
PNN
AFM:基于NFM的改进,通过在逐元素乘法之后形成的向量进行加权求和(Attention Net),去除了MLP部分直接接一个softmax
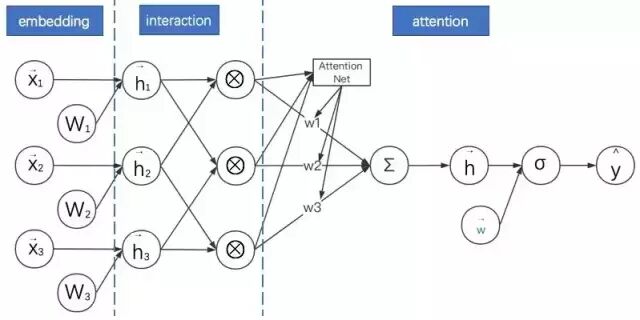
AFM
3.8. 多任务学习:同时学习多个任务
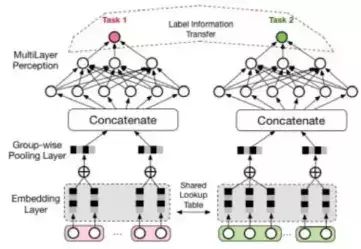
MultiTask
- 完全共享网络层的参数
- 只共享embedding层参数
4.序列预测
循环神经网络(刻画隐含状态的关联性,可以捕捉到整个序列的数据特征)
[19]Hidasi等人使用循环神经网络进行基于session的推荐,该工作是对于RNN的一个直接应用。
[20]Brébisson等人使用神经网络模型进行解决2015年的ECML/PKDD 数据挑战题目“出租车下一地点预测”,取得了该比赛第一名。在[20]中,作者对于多种多层感知器模型以及循环神经网络模型进行对比,最后发现基于改进后的多层感知器模型取得了最好的效果,比结构化的循环神经网络的效果还要好。
在[21]中,Yang等人同时结合RNN及其变种GRU模型来分别刻画用户运动轨迹的长短期行为模式,通过实验验证,在“next location”推荐任务中取得了不错的效果。如图5所示,给定一个用户生成的轨迹序列,在预测下一个地点时,直接临近的短期访问背景和较远的长期访问背景都同时被刻画。
此外还有一些基于RNN的优化模型[https:/zhuanlan.zhihu.com/p/30720579]
GRU4REC[22],使用GRU单元
GRU4REC+item features[23],加入内容特征
GRU4REC+sampling+Dwell Time[24], 将用户在session中item上的停留时间长短考虑进去
Hierachical RNN[25],一种层次化的RNN模型,相比之前的工作,可以刻画session中用户个人的兴趣变化,做用户个性化的session推荐。
GRU4REC+KNN[26], 将session 中的RNN模型,与KNN方法结合起来,能够提高推荐的效果。
Improvenment GRU4REC[27],基于GRU4REC的训练优化
GRU + attention[28],加入attention机制
原因:
网易新闻推荐:深度学习排序系统及模型
首先看一下在信息流场景中,个性化推荐的产品形态。左边是网易新闻的头条频道,右边是短视频频道,在经过召回、排序、重排之后信息流的最终呈现。作为流量较大的两个频道,我们在对它构建排序系统和排序模型的时候,通常会根据文章、视频、图像相关的内容特征,用户画像,场景,关注关系等对内容候选集进行排序。接下来,问题来了,如何衡量排序的效果呢?线上优化指标通常包括:CTR、阅读时长、留存、刷新次数等,其中最容易建模的就是点击率了,如果要用一个范式进行表示,就是图中这个概率公式。
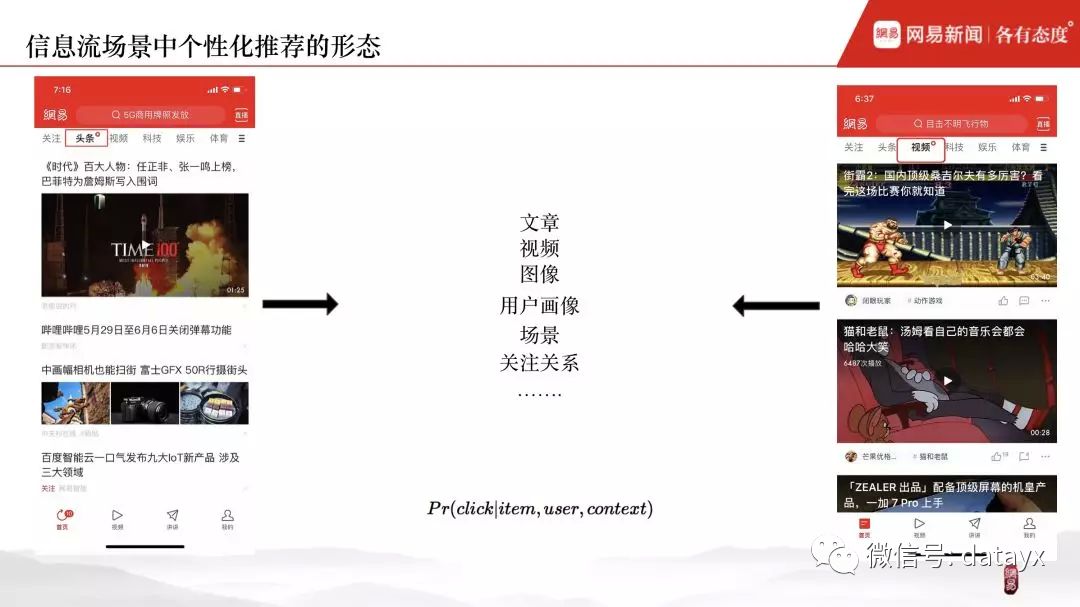
接下来考虑一个问题,当面临一个具体的推荐业务场景时,如何高效地构建排序系统和排序模型?
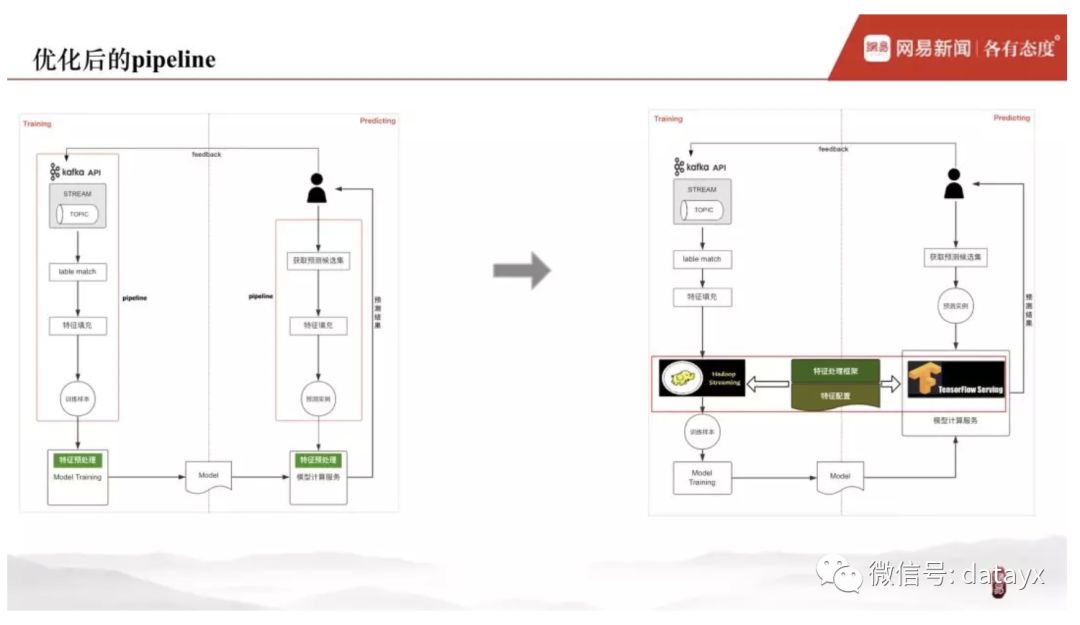
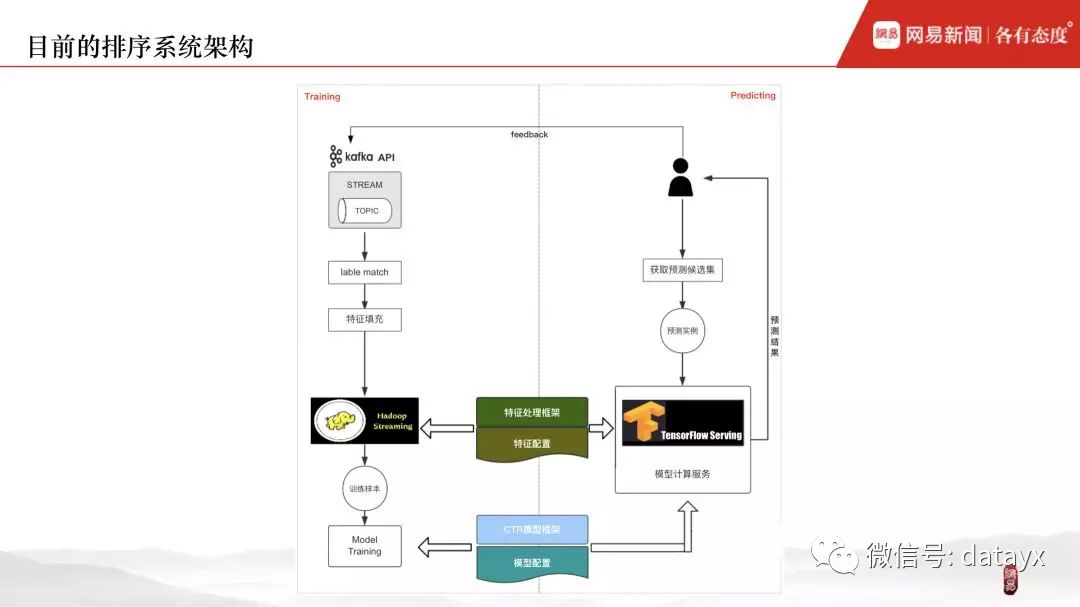
一般来说,排序系统由三部分构成:pipeline、排序模型、模型计算服务。
线下阶段,pipeline 将客户端传过来的实时反馈日志,按照不同 session 进行聚合,曝光和点击数据进行 label match,然后经过特征填充生成原始样本,接着特征预处理后,生成用于模型训练所需的训练样本。线上阶段的 pipeline 跟线下基本相同,不同之处在于各自依赖的上游数据源,一个来自客户端的实时反馈,一个来自召回请求及预测候选集。
下图为排序系统的基本流程。然而,在具体实践中,处于对各模块的计算平台、流程一致性、组件通用性以及模型训练性能等各方面的考虑,我们需要对这个 basic 的排序系统做对应的改造。而我们的改造主要集中在两块:特征预处理 & 模型。
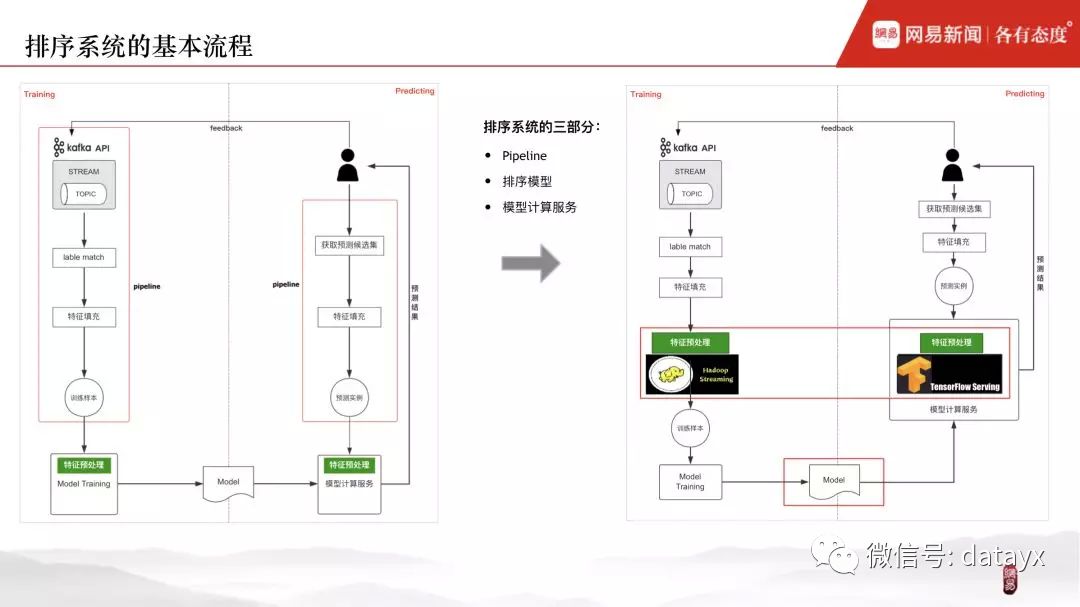
为什么要对基础流程进行改造以及具体如何改造?这里需要了解一下整个排序系统研发过程中我们所面临的核心问题和挑战。
首先关于 pipeline,我们知道,排序模型在训练和预测之间的差异会对模型的准确性产生很大的影响。而差异的产生来源于:特征、特征处理。只有保证 pipeline 线上线下的一致性,才能保证线上模型能够得出正确的预测结果。特征方面,我们将进行在线预测时的特征保存下来,然后填充到线下的训练样本中,这样就保证了训练和预测阶段的特征是一致的;特征处理方面,实践中一般采用 tf.data 和 feature_column 进行读取样本数据和特征处理,这种做法虽然避免了线上线下一致性的问题,但是这种基于原生 TensorFlow 的实现也带来了线上计算和线下训练的性能问题。如何在特征处理模块即保证线上线下的一致性又能同时保障系统整体的性能,这是我们所面临的一个挑战。
然后对于深度学习排序模型,我们需要支持网易新闻不断增多的业务需求,这就要求排序模型框架有足够的通用性和可扩展性,以支持模型的快速迭代和迁移。同时要求模型有足够好的灵活性,以支持业务定制化。

针对 pipeline 中的特征处理模块以及排序模型框架,我们做了如下优化:
首先特征处理库,将模型训练阶段跑在 CPU 上的特征处理任务转移到 pipeline 阶段的大规模计算集群上 ( Haddop Streaming ),以免影响模型训练阶段对 GPU 计算的影响,同时也避免了训练阶段的重复计算。基于这样的思想,我们将特征处理库从模型中独立出来,线下阶段在 pipeline 中而非模型中调用此库,线上阶段在模型中调用此库,但是这样会带来线上线下不一致的问题。我们的解决方案是将特征处理库独立出来之后,线上和线下调用对应的我们自定义 OP ( 样本读取和数据处理模块 ) 即可。
关于自定义 OP,我们主要对样本读取和数据处理模块进行了对应的改造。原生 TensorFlow 通常使用 tf.data 进行数据读取,通过 feature_column 进行数据预处理,但是在大规模数据场景中,存在性能瓶颈,因此我们重新实现了数据读取和预处理模块,并优化了性能;另外,为了支持多值带权的特征,我们使用了自定义的样本格式,而原生接口对样本格式的解析也并不友好,所以自定义了解析模块;或者想要手动融合一些操作或 TensorFlow 原生不支持的一些操作,也需要我们通过自定义 OP 来实现。

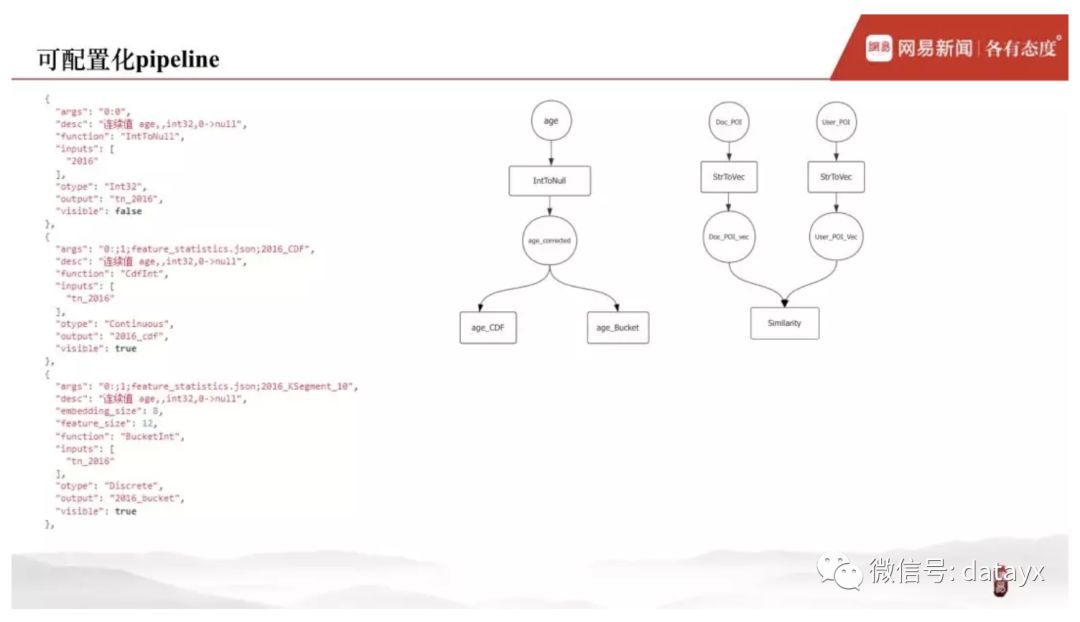
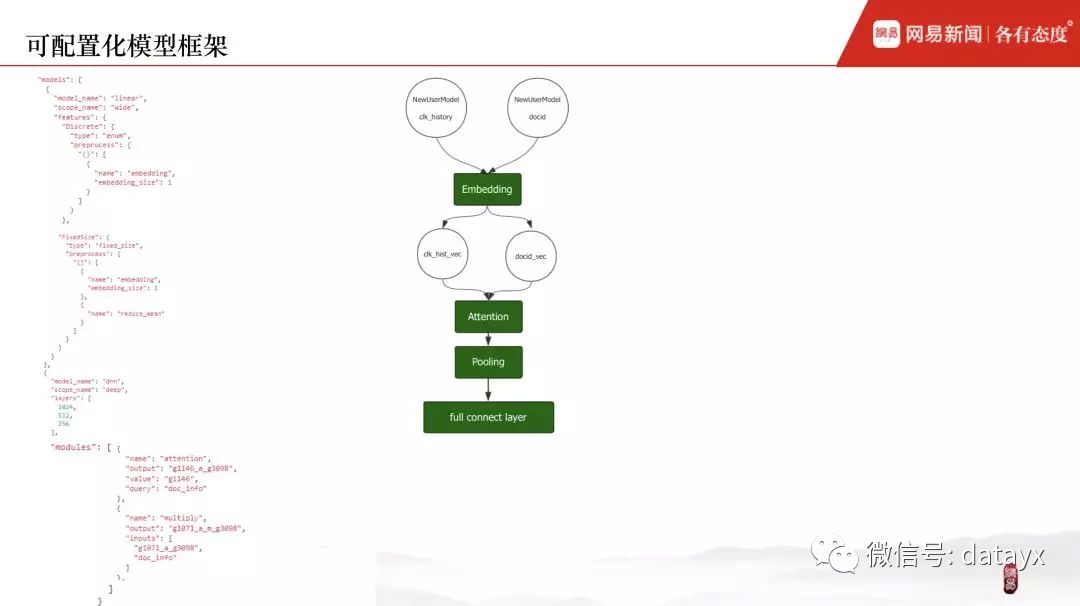
完成 pipeline 的底层改造之后,如何快速使用特征处理框架呢?很简单,在配置文件中将特征处理流程描述出来即可。
在配置文件中,对于每个特征,描述它对应的特征处理流程。如下图,圆形代表原始特征值和经过各个算子处理后的特征中间值,方形表示特征处理库内的算子,所以特征处理流程可以视为各个 DAG 图。右边的两个例子是用 DAG 图来描述特征处理流程的相关配置。
1)特征 age,先经过校正算子(将上游传入为 0 的 age 特征字段校正为 Null)得到中间值 age_corrected,再经过算子 CDF 或者 Bucket 处理得到可以作为模型输入的特征值 age_cdf 和 age_bucket。
2)特征 Doc_POI 和 User_POI,经过算子 StrToVec 处理之后再经过相似度算子,得到二者的相似度。
以上经过一系列算子处理后的特征将作为排序模型的输入。若在训练样本中增加特征,只需要在特征处理框架中实现对应的算子,并在配置文件来描述新增特征的处理流程。
我们使用 DAG 图来描述特征处理过程的思想,源自于 TensorFlow,先实现底层算子 API,然后将对特征的处理流程构建 Graph,再通过上层 API 接口 session.run 启动运行 Graph。而解析配置文件的过程就相当于解析 DAG 图。
至此,完成 pipeline 的优化。回看一下,排序系统经过改造之后的模样。排序系统变成由一个特征处理框架进行特征处理,而这个框架既可以跑在线下阶段的 hadoop streaming 上,也可以跑在线上 TensorFlow 深度学习框架之上。
深度学习排序模型方面,同样面临一系列的问题。如何构建通用 & 可扩展的推荐算法库框架,来支持新的业务场景,保证模型的快速迭代?如何保证框架的灵活性,根据变化的业务需求对模型做定制化?如何通过高度可配置的方式来构建模型?

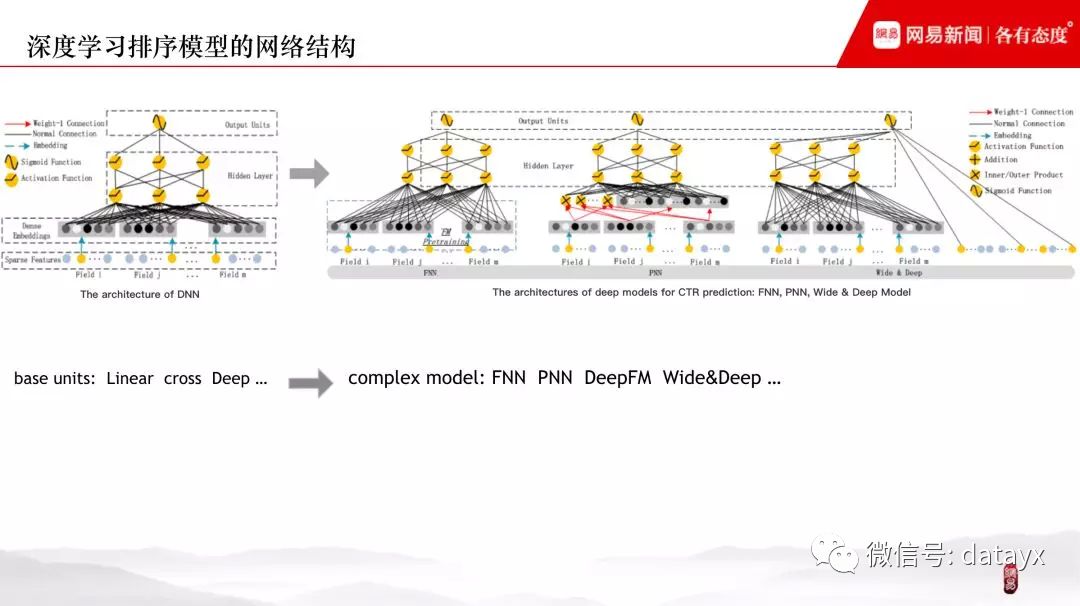
先看几个经典的深度学习排序模型的网络结构,左边是 DNN,右边为它的几种变体:FNN、PNN、Wide&Deep。虽然 4 种模型结构各异,但抽象一下会发现共通之处,基本单元包括:linear、cross、deep 模块,从层次结构来看包括: 特征表征层、特征交叉层、全连接层,其中特征交叉既可以通过人工方式 ( Wide 部分 ) 也可以通过内积或矩阵乘法的方式来进行。经过以上分析,其实提供了一种思路:我们可以将深度学习模型的各个基本单元进行模块化来构建模型。
沿着以上的抽象和分析,接下来用两个网络结构相对复杂的深度学习排序模型来进行验证。
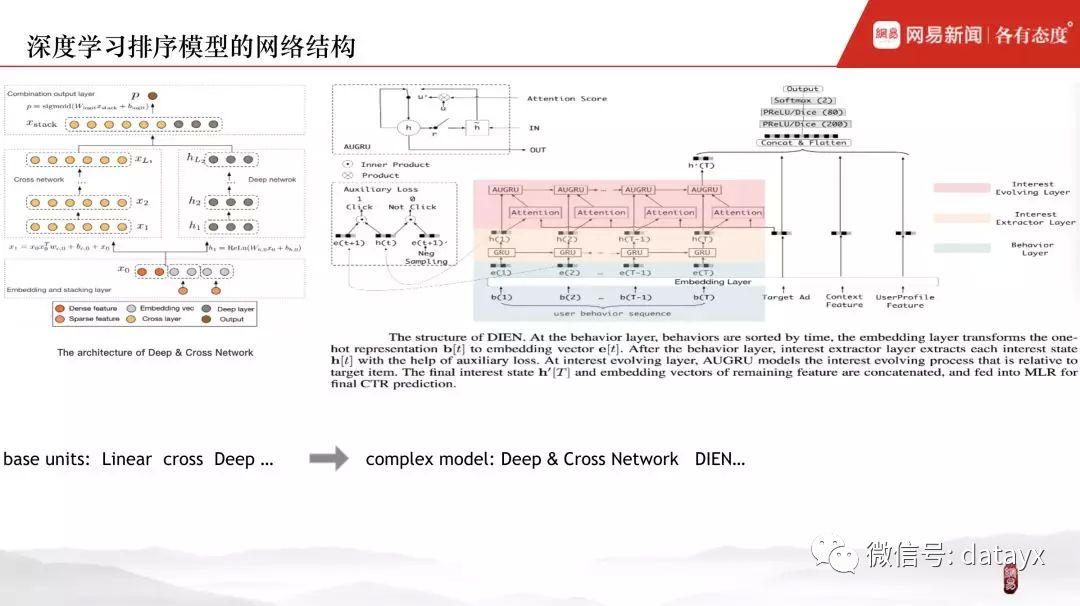
下图左边为 DCN ( Deep & Cross NetWork ) 模型,右边为 DIEN ( Deep Interest Evolution Network ),可以观察到,层次结构同上:特征表征层、特征交叉层、全连接层,与上面不同的是:特征交叉不再受限于人工交叉或各种方式的 2 阶交叉,而是让 NN 网络去进行更高阶的特征交叉表达。网络的基本单元仍然包括:linear、cross、deep。
根据前面对几种深度学习排序模型的网络结构的分析,总结起来如下表所示:
输入层到 Embedding 层,该过程把大规模的稀疏特征通过 embedding 操作或其它表征方式映射为低维稠密的 embedding 向量;对于生成的 embedding 向量,我们可以对它进行包括特征交叉在内的其它各种操作,比如:concat、sum or average pooling 等操作,大部分排序模型改造主要集中在这一层;最后将经过各种处理之后的 embedding 向量输入至全连接框架中。
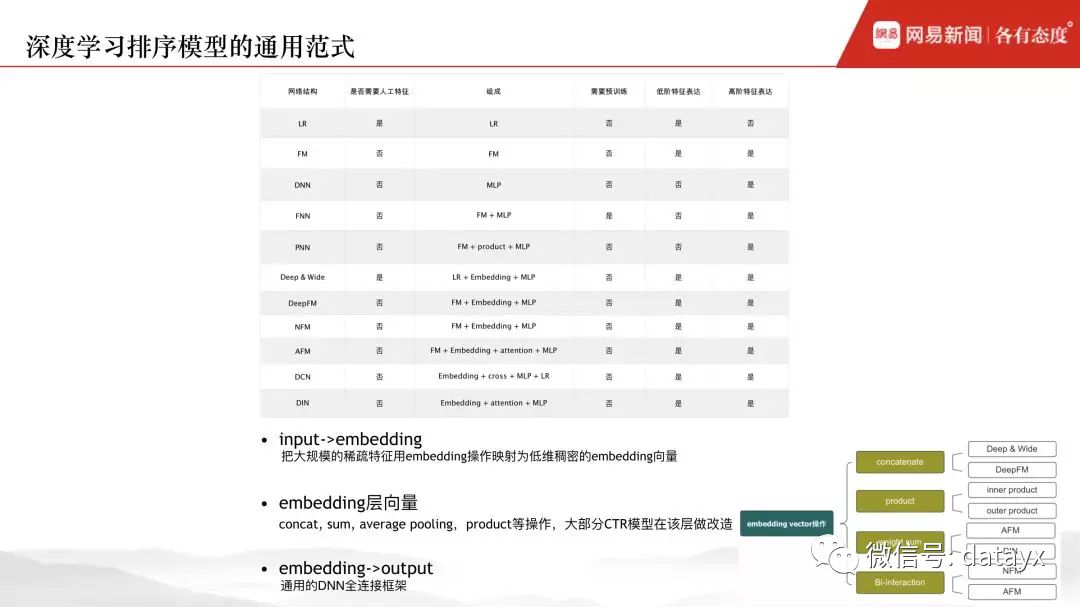
有了深度学习排序模型的通用范式,我们便针对网易新闻推荐业务设计了通用模型框架。

用层次结构图来表示的话,即下图:
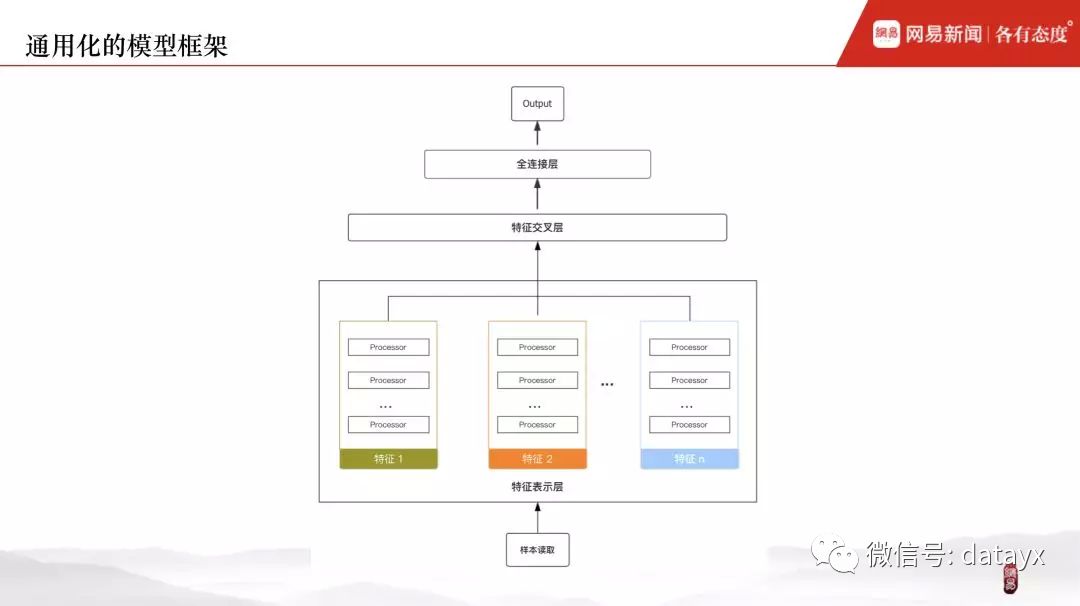
与特征处理框架的思路相同,这里对模型框架也采用子模块可配置化的方式。比如输入特征为用户点击历史 clk_history 和目标 docid,首先两个特征经过 Embedding 后得到对应的向量表示,再经过 Attention 得到权重分配,随后 Pooling 操作将变长向量转化为定长,最后输入全连接网络。底层实现各个模型子模块,具体的业务场景对应的模型只需在其配置文件中将模型结构描述出来即可。
经过对 pipeline 及模型框架的优化,我们的排序系统最终能够很好的解决了 pipeline 线上线下一致性、系统整体的性能问题、深度学习模型框架的通用性 & 可扩展、灵活性等问题。
同时模型效果在各个推荐业务中相对 baseline 也有比较显著的提升。

阅读过本文的人还看了以下:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech












