
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
前言:深度学习驱动的 CTR 预估技术演化
0. 浅层模型时代:以 MLR 为例
2005-2015 这十年间,大规模机器学习模型 (特指浅层模型) 一度统治着 CTR 预估领域,以 G/B 两家为代表的”大规模离散特征 + 特征工程 + 分布式线性 LR 模型”解法几乎成为了那个时代的标准解。相关的工作相信读者们耳熟能详,甚至据我所知今天业界的不少团队依然采用这样的技术。
阿里在 2011-2012 年左右由 @盖坤同学创新性地提出了 MLR(Mixed Logistic Regression) 模型并实际部署到线上系统,同时期也有如 FM 模型等工作出现。这些模型试图打破线性 LR 模型的局限性,向非线性方向推进了一大步。
我在 2014 年加入阿里定向广告团队,不久负责了 Ranking 方向,推进 CTR 技术的持续迭代是我工作的主航道之一。作为 MLR 模型的诞生团队,显然我们对它有着强烈的偏爱。最初 MLR 模型的主要使用方式是”低维统计反馈特征 +MLR”,这是受阿里技术发展初期的轨道限制,读者不用太惊讶。
我们做的第一个工作,就是试图将 MLR 模型推向大规模离散特征体系,核心思考是细粒度的特征刻画携带的信息量要远比统计平均特征的分辨率高,这种特征体系至今在整个业界都是最先进的。要完成这样一个升级,背后有巨大的挑战 (在 DL 时代启动初期,我们也遇到了类似的挑战),具体包括:
从数百维统计特征到数十亿离散特征,训练程序要做重大升级,从数据并行模式要升级到模型并行方式,且非线性模型复杂度高,需要充分利用数据的结构化特点进行加速;
”大规模离散特征 + 分布式非线性 MLR 模型”解法直接从原始离散特征端到端地进行数据模式学习,至少在初期时我们没有做任何的特征组合,完全依赖模型的非线性能力。在这种互联网尺度 (百亿参数 & 样本) 的数据上,模型能不能学习到兼具拟合能力与泛化能力的范式?
这种超大规模数据上的非凸优化 (MLR 加入正则后进一步变成非光滑) 学术界鲜有先例。它的收敛性是一个巨大的问号。
当然,结果是我们成功了。15 年初的时候成为了新的技术架构,在定向广告的所有场景都生产化落地,取得了巨大的成功。但是我们不得不承认,”大规模离散特征 + 分布式非线性 MLR 模型”的解法在业界并没有大规模地被采纳,有多种原因,技术上来讲 MLR 模型的实现细节我们直到 17 年才正式地写了一篇论文挂在了 arxiv 上,代码也没有开源,大家想要快速尝试 MLR 也不太方便;其次 LR+ 特征工程的解法深深影响了很多技术团队的思考方式和组织结构,我们后面会谈到,这种对特征工程的依赖直到 DL 时代还大量保留着,一个重要的因素也是因为特征工程比较符合人的直观认知,可以靠快速试错并行迭代,MLR 这类非线性端到端的解法需要比较强的模型信仰和建模能力。
大约从 14 年到 16 年,我们在基础 MLR 架构上做了大量的优化,后来以 MLR 的论文公布为契机,我在阿里技术官微里面写了一篇介绍文章,里面披露了大量的改进细节,大家有兴趣可以翻阅翻阅,算是致敬 MLR 时代: MLR 深度优化细节。
1. 技术拐点:端到端深度学习网络的突破
15 年的时候,基于 MLR 的算法迭代进入瓶颈。当时认识到,要想进一步发挥 MLR 模型的非线性能力,需要提高模型的分片数——模型的参数相应地会线性增长,需要的训练样本量同样要大幅度增加,这不太现实。期间我们做了些妥协,从特征的角度进行优化,比如设计了一些直观的复合特征,典型的如”hit 类特征”:用户历史浏览过商品 A/B/C,要预估的广告是商品 C,通过集合的”与”操作获得”用户历史上浏览过广告商品”这个特征。
细心的读者应该很容易联想到后来我们进一步发展出来的 DIN 模型,通过类似 attention 的技巧拓展了这一方法。后来进一步引入一些高阶泛化特征,如 user-item 的 PLSA 分解向量、w2v embedding 等。但这些特征引入的代价大、收益低、工程架构复杂。
15 年底 16 年初的时候我们开始认真地思考突破 MLR 算法架构的限制,向 DL 方向迈进。这个时间在业界不算最早的,原因如前所述,MLR 是 DL 之前我们对大规模非线性建模思路的一个可行解,它助力了业务巨大的腾飞,因此当时够用了——能解决实际问题就是好武器,这很重要。
在那个时间点,业界已经有了一些零散的 DL 建模思路出现,最典型的是 B 家早期的两阶段建模解法——先用 LR/FM 等把高维离散特征投影为数千规模的稠密向量,然后再训练一个 MLP 模型。我们最初也做过类似的尝试如 w2v+MLR/DNN,但是效果不太显著,看不到打败 MLR 的希望 (不少团队从 LR 发展过来,这种两阶段建模打败 LR 应该是可行的)。这里面关键点我们认为是端到端的建模范式。

实践和思考不久催生了突破。16 年 5-6 月份我构思出了第一代端到端深度 CTR 模型网络架构 (内部代号 GwEN, group-wise embedding network),如图 1 所示。对于这个网络有多种解释,它也几乎成为了目前业界各个团队使用深度 CTR 模型最基础和内核的版本。
图 1 给出了思考过程,应该说 GwEN 网络脱胎换骨于 MLR 模型,是我们对互联网尺度离散数据上端到端进行非线性建模的第二次算法尝试。当然跟大规模 MLR 时期一样,我们再一次遭遇了那三个关键挑战,这里不再赘述。
有个真实的段子: 16 年 6 月份我们启动了研发项目组,大约 7 月份的时候有同学发现 G 在 arxiv 上挂出了 WDL(wide and deep) 那篇文章,网络主体结构与 GwEN 如出一辙,一下子浇灭了我们当时想搞个大新闻的幻想。客观地讲当时技术圈普遍蔓延着核心技术保密的氛围,因此很多工作都在重复造轮子。16 年 8 月份左右我们验证了 GwEN 模型大幅度超越线上重度优化的 MLR,后来成为了我们第一代生产化 deep CTR model。
因为 WDL 的出现我们没对外主推 GwEN 模型,只作为 DIN 论文里的 base model 亮了相。不过我在多次分享时强调,GwEN 模型虽看起来简单直接,但是背后对于 group-wise embedding 的思考非常重要,去年我受邀的一个公开直播中对这一点讲得比较透,感兴趣的同学可以翻阅 GwEN 分享资料:https://zhuanlan.zhihu.com/p/34940250
2. 技术拐点:模型工程奠基
GwEN 引爆了我们在互联网场景探索 DL 技术的浪潮,并进而催生了这个领域全新的技术方法论。以阿里定向广告为例,16-17 年我们大刀阔斧地完成了全面 DL 化的变革,取得了巨大的技术和业务收益。如果给这个变革的起点加一个注脚,我认为用“模型工程”比较贴切。这个词是我 17 年在内部分享时提出来的 (不确定是不是业界第一个这么提的人),后来我看大家都普遍接受了这个观点。
如果说大规模浅层机器学习时代的特征工程 (feature engineering, FE) 是经验驱动,那么大规模深度学习时代的模型工程 (model engineering, ME) 则是数据驱动,这是一次飞跃。当然 ME 时代不代表不关注特征,大家熟悉的 FE 依然可以进行,WDL 式模型本来就有着调和 feature 派和 model 派的潜台词 (听过不同渠道的朋友类似表述,G 家的同学可以证实下) 不过我要强调的是,传统 FE 大都是在帮助模型人工预设一些特征交叉关系先验,ME 时代特征有更重要的迭代方式:给模型喂更多的、以前浅层模型难以端到端建模的 signal(下一节细说),DL model 自带复杂模式学习的能力。
说到这,先交代下 GwEN/WDL 端到端 deep CTR model 成功后业界的情况:很多技术团队奉 WDL 为宝典,毕竟 G 背书的威力非常大。随后沿着“把特征工程的经验搬上 DL 模型”这个视角相继出了多个工作,如 PNN/DeepFM/DCN/xDeepFM 等。
这些模型可以总结为一脉相承的思路:用人工构造的代数式先验来帮助模型建立对某种认知模式的预设,如 LR 模型时代对原始离散特征的交叉组合 (笛卡尔乘积),今天的 DL 时代演变为在 embedding 后的投影空间用內积、外积甚至多项式乘积等方式组合。理论上这比 MLP 直接学习特征的任意组合关系是有效的——"No Free Lunch" 定理。但我经常看到业界有团队把这些模型逐个试一遍然后报告说难有明显收益,本质是没有真正理解这些模型的作用点。
16 年底的时候,在第一代 GwEN 模型研发成功后我们启动了另一条模型创新的道路。业界绝大部分技术团队都已跨入了个性化时代,尤其在以推荐为主的信息获取方式逐渐超越了以搜索为主的信息获取方式时更是明显,因此在互联网尺度数据上对用户的个性化行为偏好进行研究、建模、预测,变成了这个时期建模技术的主旋律之一。
具体来说,我们关注的问题是:定向广告 / 推荐及个性化行为丰富的搜索场景中,共性的建模挑战都是互联网尺度个性化用户行为理解,那么适合这种数据的网络结构单元是什么?图像 / 语音领域有 CNN/RNN 等基础单元,这种蕴含着高度非线性的大规模离散用户行为数据上该设计什么样的网络结构?显然特征工程式的人工代数先验是无法给出满意的解答的,这种先验太底层太低效。这个问题我们还没有彻底的认知,探索还在继续进行中,但至少在这条路上我们目前已经给出了两个阶段性成果:
DIN 模型 (Deep Interest Network,KDD’18),知乎 @王喆同学有一篇实践性较强的解读,推荐参阅《DIN 解读》:https://zhuanlan.zhihu.com/p/51623339
DIEN 模型 (Deep Interest Evolution Network,AAAI’19),知乎 @杨镒铭同学写过详细的解读,推荐阅读《DIEN 解读》:https://zhuanlan.zhihu.com/p/50758485
 到深度兴趣网络 DIN(右)")
DIN/DIEN 都是围绕着用户兴趣建模进行的探索,切入点是从我们在阿里电商场景观察到的数据特点并针对性地进行了网络结构设计,这是比人工代数先验更高阶的学习范式:DIN 捕捉了用户兴趣的多样性以及与预测目标的局部相关性;DIEN 进一步强化了兴趣的演化性以及兴趣在不同域之间的投影关系。DIN/DIEN 是我们团队生产使用的两代主力模型,至今依然服务着很大一部分流量。这方面我们还在继续探索,后续进展会进一步跟大家分享。
当然,模型工程除了上述”套路派”之外,还兴起了大一堆”DL 调结构工程师”。可以想象很多人开始结合着各种论文里面的基本模块 FM、Product、Attention 等组合尝试,昏天暗地堆结构 + 调参。效果肯定会有,但是这种没有方法论的盲目尝试,建议大家做一做挣点快钱就好,莫要上瘾。
3. 技术拐点:超越单体模型的建模套路
模型工程还有另外一个重要延伸,我称之为”超越单体模型”的建模思路,这里统一来介绍下。事实上前面关于模型工程的描述里面已经提到,因为 DL 模型强大的刻画能力,我们可以真正端到端地引入很多在大规模浅层模型时代很难引入的信号,比如淘宝用户每一个行为对应的商品原图 / 详情介绍等。

图 3 给出了我们团队建模算法的整体视图。主模型结构在上一节已经介绍,与其正交的是一个全新的建模套路:跳出上一时代固化的建模信号域,开辟新的赛道——引入多模态 / 多目标 / 多场景 / 多模块信号,端到端地联合建模。注意这里面关键词依然是端到端。两篇工作我们正式对外发表了,包括:
ESMM 模型 (Entire-Space Multi-task Model, SIGIR’18),知乎 @杨旭东同学写过详细的解读并给出了代码实现,推荐参阅《ESMM 解读》:https://zhuanlan.zhihu.com/p/37562283
CrossMedia 模型 (论文里面叫 DICM, Deep Image CTR Model, CIKM’18),这个工作结合了离散 ID 特征与用户行为图像两种模态联合学习,模型主体采用的是 DIN 结构。最大的挑战是工程架构,因此论文详细剖析了我们刚刚开源的 X-DeepLearning 框架中,超越 PS 的 AMS 组件设计。不过目前好像没看到有人解读过,感兴趣的同学可以读一读写个分析。

关于 ESMM 模型多说两句,我们展示了对同态的 CTR 和 CVR 任务联合建模,帮助 CVR 子任务解决样本偏差与稀疏两个挑战。事实上这篇文章是我们总结 DL 时代 Multi-Task Learning 建模方法的一个具体示例。图 4 给出了更为一般的网络架构。
据我所知这个工作在这个领域是最早的一批,但不唯一。今天很多团队都吸收了 MTL 的思路来进行建模优化,不过大部分都集中在传统的 MTL 体系,如研究怎么对参数进行共享、多个 Loss 之间怎么加权或者自动学习、哪些 Task 可以用来联合学习等等。ESMM 模型的特别之处在于我们额外关注了任务的 Label 域信息,通过展现 > 点击 > 购买所构成的行为链,巧妙地构建了 multi-target 概率连乘通路。
传统 MTL 中多个 task 大都是隐式地共享信息、任务本身独立建模,ESMM 细腻地捕捉了契合领域问题的任务间显式关系,从 feature 到 label 全面利用起来。这个角度对互联网行为建模是一个比较有效的模式,后续我们还会有进一步的工作来推进。
应该要指出 MTL 的应用范围极广,如图 3 中我们的过往工作。它尤其适合多场景、多模块的联动,典型的例子是数据量较大的场景可以极大地帮助小场景优化。此外 MTL 这类模型工程解法与上一节介绍的单模型结构设计可以互补和叠加,两者的发展没有先后关系、可以并行推进。
4. 技术拐点:嵌入工程系统的算法设计
实际的工业系统,除了上面抽象出来的 CTR 预估问题,还有很多独立的话题。介绍下我们在既有系统架构中算法层面的一些实践。以广告系统为例,从算法视角来看至少包括以下环节:匹配 > 召回 > 海选 > 粗排 > 精排 > 策略调控,这些算法散落在各个工程模块中。
现在让我们保持聚焦在 CTR 相关任务,看看在系统中不同的阶段都可以有哪些新的变化。几个典型的系统瓶颈:海选 / 粗排所在的检索引擎,精排所在的在线预估引擎,以及这些算法离线所依赖的模型生产链路。在 DL 时代以前,技术已经迭代形成了一些既有的共识,如检索引擎性能关键不宜涉及复杂的模型计算。但是跨入 DL 时代后,既有的共识可以被打破、新的共识逐渐形成。
4.1 海选 / 粗排的复杂模型化升级
在我们原有的系统中,检索过程中涉及到的排序是用一个静态的、非个性化的质量分来完成,可以简单理解为广告粒度的一个统计分数,显然跟精排里面我们采用的各种各样复杂精细的模型技术 (前几节的内容) 相比它很粗糙。据我了解业界也有团队用了一些简化版的模型,如低配版 LR 模型来完成这个过程。背后的核心问题是检索时候选集太大,计算必须精简否则延迟太长。图 5 给出了我们升级后的深度个性化质量分模型,约束最终的输出是最简单的向量內积。这种设计既迎合了检索引擎的性能约束,同时实测跟不受限 DL 模型 (如 DIN) 在离线 auc 指标上差距不太显著,但比静态模型提升巨大。

这里有两个延伸: 1) 海选 / 粗排 DQM 模型只帮助缩减候选集规模,不作为最终广告的排序分,因此它的精度可以不像精排模型那样追求极致,相应地多考虑系统性能和数据循环扰动;
DQM 模型对于检索匹配召回等模块同样适用,例如现在很多团队已经普通接受的向量化召回架构,跟 DQM 在模型架构上完全吻合。只不过作用在召回模块,其建模信号和训练样本有很大的不同,更多地要考虑用户兴趣泛化。提到向量化高效计算,F/M 两家都开源了优秀的架构,推荐大家参阅《faiss 和 SPTAG》:https://github.com/Microsoft/SPTAG
4.2 面向在线预估引擎的模型压缩
在 LR/MLR 时代在线预估引擎的计算相对简单、压力不大。但当复杂的 DL 模型层出不穷后,在线引擎的算力瓶颈凸显。为了缓解这个问题,我们在 17 年试水了一个工作:轻量级模型压缩算法 (Rocket Training, AAAI’18),形象地称之为无极调速模式。知乎上没看到到位的解读,这里放出一作 @周国瑞同学自己的文章《Rocket Training 解读》:https://zhuanlan.zhihu.com/p/28625922

DL 模型的 over-parameterization 使得我们可以通过不同的优化方法寻找更好的解路径,Rocket 只是一条,未来在这个方向上我们还会有更多的工作。但有可以肯定模型 DL 化带来的在线预估引擎的算力瓶颈是一个新常态,这个方向上会引起更大的关注并演化成新一代系统架构。
4.3 打破资源依赖的增量 / 实时化算法架构
DL 模型的复杂化除了带来在线预估引擎的性能挑战外,对离线生产链路的资源挑战也急剧放大。容易理解的是全量模型的训练时间及占用机器规模肯定会逐步增加,同时模型的并行研发规模也会大增,即:”模型个数 x 模型时长 x 机器规模”全面膨胀。在这种情况下增量 / 实时模型训练架构就成为了胜负手。
虽然业界很多时效性强的场景 (如信息流)online 模型的效果收益是巨大和关键的,但这里我不想过多地强调效果层面的收益,而更愿意从资源架构层面做探讨。虽然 DL 模型采用了 sgd-based 优化算法,直觉来看 batch 训练和 incremental 或 online 训练应该同构。然而 ODL(Online Deep Learning) 所存在的问题和挑战绝不止于此,且它跟 LR 时代的 Online Learning 有很多的差异性。目前同时完成了全面 DL 并进而 ODL 化的团队不太多。
当然也有团队是从 OL 系统直接向 ODL 升级的,这个路径固然看似更快捷,但也许错过了 DL 模型盛宴的不少美妙菜肴——batch 训练是纯模型探索的更优土壤。我们从 17 年底开始从 DL 到 ODL 升级,18 年初落地、经历了 18 年双十一大促,我认为只是刚刚走完了 ODL 的最基础阶段,这方面我们还在持续推进。
在计算广告场景中,需要平衡和优化三个参与方——用户、广告主、平台的关键指标,而预估点击率CTR(Click-through Rate)和转化率CVR(Conversion Rate)是其中非常重要的一环,准确地预估CTR和CVR对于提高流量变现效率,提升广告主ROI(Return on Investment),保证用户体验等都有重要的指导作用。
传统的CTR/CVR预估,典型的机器学习方法包括:
①人工特征工程 + LR(Logistic Regression)[1]
②GBDT(Gradient Boosting Decision Tree)[2] + LR
③FM(Factorization Machine)[3]和FFM(Field-aware Factorization Machine)[4]等模型。
相比于传统机器学习方法,深度学习模型近几年在多领域多任务(图像识别、物体检测、翻译系统等)的突出表现,印证了神经网络的强大表达能力,以及端到端模型有效的特征构造能力。同时各种开源深度学习框架层出不穷,美团集团数据平台中心也迅速地搭建了GPU计算平台,提供GPU集群,支持TensorFlow、MXNet、Caffe等框架,提供数据预处理、模型训练、离线预测、模型部署等功能,为集团各部门的策略算法迭代提供了强有力的支持。
美团海量的用户与商家数据,广告复杂的场景下众多的影响因素,为深度学习方法的应用落地提供了丰富的场景。本文将结合广告特殊的业务场景,介绍美团搜索广告场景下深度学习的应用和探索。主要包括以下两大部分:
CTR/CVR预估由机器学习向深度学习迁移的模型探索
CTR/CVR预估基于深度学习模型的线下训练/线上预估的工程优化
二、从机器学习到深度学习的模型探索
2.1 场景与特征
美团搜索广告业务囊括了关键词搜索、频道筛选等业务,覆盖了美食、休娱、酒店、丽人、结婚、亲子等200多种应用场景,用户需求具有多样性。同时O2O模式下存在地理位置、时间等独特的限制。
结合上述场景,我们抽取了以下几大类特征:
用户特征
人口属性:用户年龄,性别,职业等。
行为特征:对商户/商圈/品类的偏好(实时、历史),外卖偏好,活跃度等。
建模特征:基于用户的行为序列建模产生的特征等。
商户特征
属性特征:品类,城市,商圈,品牌,价格,促销,星级,评论等。
统计特征:不同维度/时间粒度的统计特征等。
图像特征:类别,建模特征等。
业务特征:酒店房型等。
Query特征
分词,意图,与商户相似度,业务特征等。
上下文特征
时间,距离,地理位置,请求品类,竞争情况等。
广告曝光位次。
结合美团多品类的业务特点及O2O模式独特的需求,着重介绍几个业务场景以及如何刻画:
用户的消费场景
“附近”请求:美团和大众点评App中,大部分用户发起请求为“附近”请求,即寻找附近的美食、酒店、休闲娱乐场所等。因此给用户返回就近的商户可以起到事半功倍的效果。“请求到商户的距离”特征可以很好地刻画这一需求。
“指定区域(商圈)”请求:寻找指定区域的商户,这个区域的属性可作为该流量的信息表征。
“位置”请求:用户搜索词为某个位置,比如“五道口”,和指定区域类似,识别位置坐标,计算商户到该坐标的距离。
“家/公司”:用户部分的消费场所为“家” 或 “公司”,比如寻找“家”附近的美食,在“公司”附近点餐等,根据用户画像得到的用户“家”和“公司”的位置来识别这种场景。
多品类
针对美食、酒店、休娱、丽人、结婚、亲子等众多品类的消费习惯以及服务方式,将数据拆分成三大部分,包括美食、酒店、综合(休娱、丽人、结婚、亲子等)。其中美食表达用户的餐饮需求,酒店表达用户的旅游及住宿需求,综合表达用户的其他生活需求。
用户的行为轨迹
实验中发现用户的实时行为对表达用户需求起到很重要的作用。比如用户想找个餐馆聚餐,先筛选了美食,发现附近有火锅、韩餐、日料等店,大家对火锅比较感兴趣,又去搜索特定火锅等等。用户点击过的商户、品类、位置,以及行为序列等都对用户下一刻的决策起到很大作用。
2.2 模型
搜索广告CTR/CVR预估经历了从传统机器学习模型到深度学习模型的过渡。下面先简单介绍下传统机器学习模型(GBDT、LR、FM & FFM)及应用,然后再详细介绍在深度学习模型的迭代。
GBDT
GBDT又叫MART(Multiple Additive Regression Tree),是一种迭代的决策树算法。它由多棵决策树组成,所有树的结论累加起来作为最终答案。它能自动发现多种有区分性的特征以及特征组合,并省去了复杂的特征预处理逻辑。Facebook实现GBDT + LR[5]的方案,并取得了一定的成果。
LR
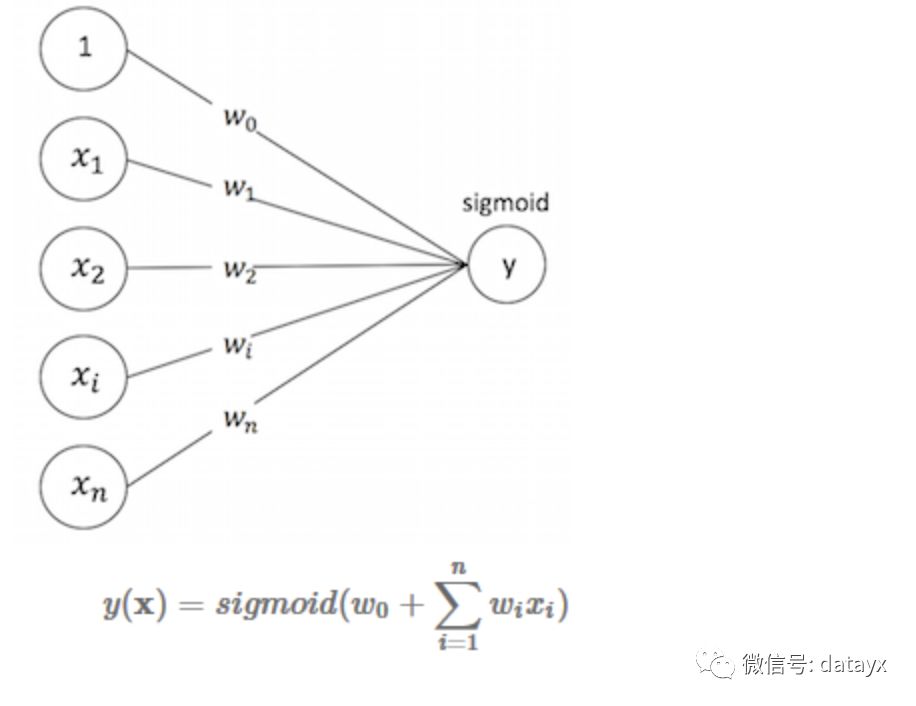
LR可以视作单层单节点的“DNN”, 是一种宽而不深的结构,所有的特征直接作用在最后的输出结果上。模型优点是简单、可控性好,但是效果的好坏直接取决于特征工程的程度,需要非常精细的连续型、离散型、时间型等特征处理及特征组合。通常通过正则化等方式控制过拟合。
FM & FFM

从神经网络的角度考虑,可以看做下图的简单网络搭建方式:

模型覆盖了LR的宽模型结构,同时也引入了交叉特征,增加模型的非线性,提升模型容量,能捕捉更多的信息,对于广告CTR预估等复杂场景有更好的捕捉。
在使用DNN模型之前,搜索广告CTR预估使用了FFM模型,FFM模型中引入field概念,把( n )个特征归属到( f )个field里,得到( nf)个隐向量的二次项,拟合公式如下:

上式中,( f_j ) 表示第( j) 个特征所属的field。设定隐向量长度( k ),那么相比于FM的( nk)个二次项参数,FFM有( nkf )个二次项参数,学习和表达能力也更强。
例如,在搜索广告场景中,假设将特征划分到8个Field,分别是用户、广告、Query、上下文、用户-广告、上下文-广告、用户-上下文及其他,相对于FM能更好地捕捉每个Field的信息以及交叉信息,每个特征构建的隐向量长度8*( k ), 整个模型参数空间为8 ( k ) ( n ) +( n ) + 1。
Yu-Chin Juan实现了一个C++版的FFM模型工具包,但是该工具包只能在单机训练,难以支持大规模的训练数据及特征集合;并且它省略了常数项和一次项,只包含了特征交叉项,对于某些特征的优化需求难以满足,因此我们开发了基于PS-Lite的分布式FFM训练工具(支持亿级别样本,千万级别特征,分钟级完成训练,目前已经在公司内部普遍使用),主要添加了以下新的特性:
支持FFM模型的分布式训练。
支持一次项和常数项参数学习,支持部分特征只学习一次项参数(不需要和其他特征做交叉运算),例如广告位次特征等。拟合公式如下:

支持多种优化算法。
从GBDT模型切到FFM模型,积累的效果如下所示,主要的提升来源于对大规模离散特征的刻画及使用更充分的训练数据:

DNN
从上面的介绍大家可以看到,美团场景具有多样性和很高的复杂度,而实验表明从线性的LR到具备非线性交叉的FM,到具备Field信息交叉的FFM,模型复杂度(模型容量)的提升,带来的都是结果的提升。而LR和FM/FFM可以视作简单的浅层神经网络模型,基于下面一些考虑,我们在搜索广告的场景下把CTR模型切换到深度学习神经网络模型:
通过改进模型结构,加入深度结构,利用端到端的结构挖掘高阶非线性特征,以及浅层模型无法捕捉的潜在模式。
对于某些ID类特别稀疏的特征,可以在模型中学习到保持分布关系的稠密表达(embedding)。
充分利用图片和文本等在简单模型中不好利用的信息。
我们主要尝试了以下网络结构和超参调优的实验。
Wide & Deep
首先尝试的是Google提出的经典模型Wide & Deep Model[6],模型包含Wide和Deep两个部分,其中Wide部分可以很好地学习样本中的高频部分,在LR中使用到的特征可以直接在这个部分使用,但对于没有见过的ID类特征,模型学习能力较差,同时合理的人工特征工程对于这个部分的表达有帮助。Deep部分可以补充学习样本中的长尾部分,同时提高模型的泛化能力。Wide和Deep部分在这个端到端的模型里会联合训练。
在完成场景与特征部分介绍的特征工程后,我们基于Wide & Deep模型进行结构调整,搭建了以下网络:
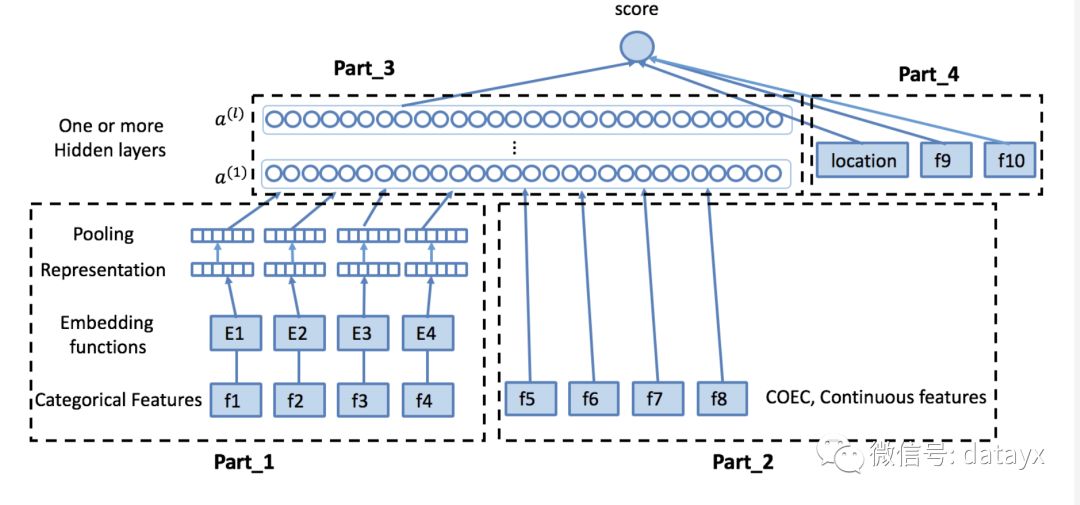
在搜索广告的场景中,上图的Part_1包含离散型特征及部分连续型特征离散化后的结果 (例如用户ID、广告ID、商圈ID、品类ID、GEO、各种统计类特征离散化结果等等)。离散化方式主要采用等频划分或MDLP[7]。每个域构建自己的embedding向量 (缺失特征和按照一定阈值过滤后的低频特征在这里统一视作Rare特征),得到特征的Representation,然后通过Pooling层做采样,并拼接在一起进行信息融合。
右侧的Part_2部分主要包含我们场景下的统计类特征及部分其他途径建模表示后输入的特征 (例如图片特征、文本特征等),和Part_1的最后一层拼接在一起做信息融合。

深度学习模型在图像语音等数据上有显著作用的原因之一是,我们在这类数据上不太方便产出能很好刻画场景的特征,人工特征+传统机器学习模型并不能学习出来全面合理的数据分布表示,而深度学习end-to-end的方式,直接结合Label去学习如何从原始数据抽取合适的表达(representation)。但是在美团等电商的业务场景下,输入的数据形态非常丰富,有很多业务数据有明确的物理含义,因此一部分人工特征工程也是必要的,提前对信息做一个合理的抽取表示,再通过神经网络学习进行更好的信息融合和表达。
在美团搜索广告的场景下,用户的实时行为有非常强的指代性,但是以原始形态直接送入神经网络,会损失掉很多信息,因此我们对它进行了不同方式描述和表示,再送入神经网络之中进行信息融合和学习。另一类很有作用的信息是图像信息,这部分信息的一种处理方式是,可以通过end-to-end的方式,用卷积神经网络和DNN进行拼接做信息融合,但是可能会有网络的复杂度过高,以及训练的收敛速度等问题,也可以选择用CNN预先抽取特征,再进行信息融合。
下面以这两类数据特征为例,介绍在Wide & Deep模型中的使用方式。
用户实时行为
a) 行为实体 用户的实时行为包括点击商户(C_P)、下单商户(O_P)、搜索(Q)、筛选品类(S)等。商户的上层属性包括品类(Type: C_Type, O_Type)、位置(Loc: C_Loc, O_Loc)等。
b) Item Embedding 对用户的行为实体构建embedding向量,然后进行Sum/Average/Weighted Pooling,和其他特征拼接在一起。实验发现,上层属性实体(C_Type, O_Type, C_Loc, O_Loc)的表现很正向,离线效果有了很明显的提升。但是C_P, O_P, Q, S这些实体因为过于稀疏,导致模型过拟合严重,离线效果变差。因此,我们做了两方面的改进:
使用更充分的数据,单独对用户行为序列建模。例如LSTM模型,基于用户当前的行为序列,来预测用户下一时刻的行为,从中得到当前时刻的“Memory信息”,作为对用户的embedding表示;或Word2Vec模型,生成行为实体的embedding表示,Doc2Vec模型,得到用户的embedding表示。实验发现,将用户的embedding表示加入到模型Part_2部分,特征覆盖率增加,离线效果有了明显提升,而且由于模型参数空间增加很小,模型训练的时间基本不变。
使用以上方法产生的行为实体embedding作为模型参数初始值,并在模型训练过程中进行fine tuning。同时为了解决过拟合问题,对不同域的特征设置不同的阈值过滤。
c) 计数特征 即对不同行为实体发生的频次,它是对行为实体更上一层的抽象。
d)Pattern特征 用户最近期的几个行为实体序列(例如A-B-C)作为Pattern特征,它表示了行为实体之间的顺序关系,也更细粒度地描述了用户的行为轨迹。
图片
i) 描述 商户的头图在App商品展示中占据着很重要的位置,而图片也非常吸引用户的注意力。
ii) 图片分类特征 使用VGG16、Inception V4等训练图片分类模型,提取图片特征,然后加入到CTR模型中。
iii) E2E model 将Wide & Deep模型和图片分类模型结合起来,训练端到端的网络。
从FFM模型切到Wide & Deep模型,积累到目前的效果如下所示,主要的提升来源于模型的非线性表达及对更多特征的更充分刻画。

比起Wide & Deep的LR部分,DeepFM采用FM作为Wide部分的输出,在训练过程中共享了对不同Field特征的embedding信息。
我们在部分业务上尝试了DeepFM模型,并进行了超参的重新调优,取得了一定的效果。其他业务也在尝试中。具体效果如下:

Multi-Task
广告预估场景中存在多个训练任务,比如CTR、CVR、交易额等。既考虑到多个任务之间的联系,又考虑到任务之间的差别,我们利用Multi-Task Learning的思想,同时预估点击率、下单率,模型结构如下图所示:

1 由于CTR、CVR两个任务非常类似,所以采用“Hard Parameter Sharing”的结构,完全共享网络层的参数,只在输出层区分不同的任务。
2 由于下单行为受展现位次的影响非常小,所以下单率的输出层不考虑位次偏差的因素。
3 输出层在不同任务上单独增加所需特征。
4 离线训练和线上预估流程减半,性能提升;效果上相对于单模型,效果基本持平:

近期,阿里发表论文“Entire Space Multi-Task Model”[9],提出目前CVR预估主要存在Sample Selection Bias(SSB)和Data Sparsity(DS)两个问题,并提出在全局空间建模(以pCTCVR和pCTR来优化CVR)和特征Transform的方法来解决。具体的Loss Function是:

网络结构是:

超参调优
除了以上对网络结构的尝试,我们也进行了多组超参的调优。神经网络最常用的超参设置有:隐层层数及节点数、学习率、正则化、Dropout Ratio、优化器、激活函数、Batch Normalization、Batch Size等。不同的参数对神经网络的影响不同,神经网络常见的一些问题也可以通过超参的设置来解决:
过拟合
网络宽度深度适当调小,正则化参数适当调大,Dropout Ratio适当调大等。
欠拟合
网络宽度深度适当调大,正则化参数调小,学习率减小等。
梯度消失/爆炸问题
合适的激活函数,添加Batch Normalization,网络宽度深度变小等。
局部最优解
调大Learning Rate,合适的优化器,减小Batch Size等。
Covariate Shift
增加Batch Normalization,网络宽度深度变小等。
影响神经网络的超参数非常多,神经网络调参也是一件非常重要的事情。工业界比较实用的调参方法包括:
①网格搜索/Grid Search:这是在机器学习模型调参时最常用到的方法,对每个超参数都敲定几个要尝试的候选值,形成一个网格,把所有超参数网格中的组合遍历一下尝试效果。简单暴力,如果能全部遍历的话,结果比较可靠。但是时间开销比较大,神经网络的场景下一般尝试不了太多的参数组合。
②随机搜索/Random Search:Bengio在“Random Search for Hyper-Parameter Optimization”[10]中指出,Random Search比Grid Search更有效。实际操作的时候,可以先用Grid Search的方法,得到所有候选参数,然后每次从中随机选择进行训练。这种方式的优点是因为采样,时间开销变小,但另一方面,也有可能会错过较优的超参数组合。
③分阶段调参:先进行初步范围搜索,然后根据好结果出现的地方,再缩小范围进行更精细的搜索。或者根据经验值固定住其他的超参数,有针对地实验其中一个超参数,逐次迭代直至完成所有超参数的选择。这个方式的优点是可以在优先尝试次数中,拿到效果较好的结果。
我们在实际调参过程中,使用的是第3种方式,在根据经验参数初始化超参数之后,按照隐层大小->学习率->Batch Size->Drop out/L1/L2的顺序进行参数调优。
在搜索广告数据集上,不同超参的实验结果如下:

2.3 小结
搜索广告排序模型经历了从GBDT –> FFM –> DNN的迭代,同时构建了更加完善的特征体系,线下AUC累积提升13%+,线上CTR累积提升15%+。
三、基于深度学习模型的工程优化
3.1 线下训练
TensorFlow程序如果单机运行中出现性能问题,一般会有以下几种问题:
a)复杂的预处理逻辑耦合在训练过程中。
b)选择正确的IO方式。
剥离预处理流程
i)在模型的试验阶段,为了快速试验,数据预处理逻辑与模型训练部分都耦合在一起,而数据预处理包含大量IO类型操作,所以很适合用HadoopMR或者Spark处理。具体流程如下:
ii)在预处理阶段将查表、join字典等操作都做完,并且将查询结果与原始数据merge在一起。
将libfm格式的数据转为易于TensorFlow操作的SparseTensor方式:
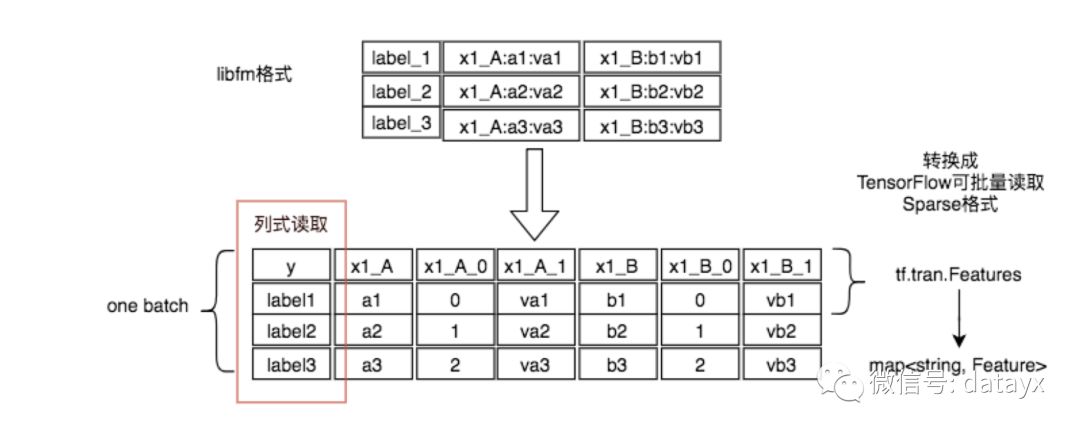
iii)将原始数据转换为TensorFlow Record。
选择正确的IO方式
TensorFlow读取数据的方式主要有2种,一般选择错误会造成性能问题,两种方式为:
①Feed_dict 通过feed_dict将数据喂给session.run函数,这种方式的好处是思路很清晰,易于理解。缺点是性能差,性能差的原因是feed给session的数据需要在session.run之前准备好,如果之前这个数据没有进入内存,那么就需要等待数据进入内存,而在实际场景中,这不仅仅是等待数据从磁盘或者网络进入内存的事情,还可能包括很多前期预处理的工作也在这里做,所以相当于一个串行过程。而数据进入内存后,还要串行的调用PyArrayToTF_Tensor,将其copy成tensorflow的tensorValue。此时,GPU显存处于等待状态,同时,由于tf的Graph中的input为空,所以CPU也处于等待状态,无法运算。
②RecordReader 这种方式是tf在Graph中将读取数据这个操作看做图中一个operation节点,减少了一个copy的过程。同时,在tf中还有batch与threads的概念,可以异步的读取数据,保证在GPU或者CPU进行计算的时候,读取数据这个操作也可以多线程异步执行。静态图中各个节点间的阻塞:在一个复杂的DAG计算图中,如果有一个点计算比较慢时,会造成阻塞,下游节点不得不等待。此时,首先要考虑的问题是图中节点参数所存储的位置是否正确。比如如果某个计算节点是在GPU上运算,那么如果这个节点所有依赖的variable对象声明在CPU上,那么就要做一次memcpy,将其从内存中copy到GPU上。因为GPU计算的很快,所以大部分时间花在拷贝上了。总之,如果网络模型比较简单,那么这种操作就会非常致命;如果网络结构复杂,比如网络层次非常深,那么这个问题倒不是太大的问题了。
在这个Case中,因为需要提升吞吐,而不仅仅是在试验阶段。所以需要用RecordReader方式处理数据。
优化过程
1将整体程序中的预处理部分从代码中去除,直接用Map-Reduce批处理去做(因为批处理可以将数据分散去做,所以性能非常好,2亿的数据分散到4900多个map中,大概处理了15分钟左右)。
2 MR输出为TensorFlow Record格式,避免使用Feed_dict。
3 数据预读,也就是用多进程的方式,将HDFS上预处理好的数据拉取到本地磁盘(使用joblib库+shell将HDFS数据用多进程的方式拉取到本地,基本可以打满节点带宽2.4GB/s,所以,拉取数据也可以在10分钟内完成)。
4 程序通过TensorFlow提供的TFrecordReader的方式读取本地磁盘上的数据,这部分的性能提升是最为明显的。原有的程序处理数据的性能大概是1000条/秒,而通过TFrecordReader读取数据并且处理,性能大概是18000条/秒,性能大概提升了18倍。
5 由于每次run的时候计算都要等待TFrecordReader读出数据,而没用利用batch的方式。如果用多线程batch可以在计算期间异步读取数据。在TensorFlow所有例子中都是使用TFRecordReader的read接口去读取数据,再用batch将数据多线程抓过来。但是,其实这样做加速很慢。需要使用TFRecordReader的read_up_to的方法配合batch的equeue_many=True的参数,才可以做到最大的加速比。使用tf.train.batch的API后,性能提升了38倍。
此时,性能已经基本达到我们的预期了。例如整体数据量是2亿,按照以前的性能计算1000条/秒,大概需要运行55个小时。而现在大概需要运行87分钟,再加上预处理(15分钟)与预拉取数据(10分钟)的时间,在不增加任何计算资源的情况下大概需要2个小时以内。而如果是并行处理,则可以在分钟级完成训练。
3.2 线上预估
线上流量是模型效果的试金石。离线训练好的模型只有参与到线上真实流量预估,才能发挥其价值。在演化的过程中,我们开发了一套稳定可靠的线上预估体系,提高了模型迭代的效率。
模型同步
我们开发了一个高可用的同步组件:用户只需要提供线下训练好的模型的HDFS路径,该组件会自动同步到线上服务机器上。该组件基于HTTPFS实现,它是美团离线计算组提供的HDFS的HTTP方式访问接口。同步过程如下:
同步前,检查模型md5文件,只有该文件更新了,才需要同步。
同步时,随机链接HTTPFS机器并限制下载速度。
同步后,校验模型文件md5值并备份旧模型。
同步过程中,如果发生错误或者超时,都会触发报警并重试。依赖这一组件,我们实现了在2min内可靠的将模型文件同步到线上。
模型计算
当前我们线上有两套并行的预估计算服务。
一、基于TF Serving的模型服务
TF Serving是TensorFlow官方提供的一套用于在线实时预估的框架。它的突出优点是:和TensorFlow无缝链接,具有很好的扩展性。使用TF serving可以快速支持RNN、LSTM、GAN等多种网络结构,而不需要额外开发代码。这非常有利于我们模型快速实验和迭代。
使用这种方式,线上服务需要将特征发送给TF Serving,这不可避免引入了网络IO,给带宽和预估时延带来压力。我们尝试了以下优化,效果显著。
并发请求。一个请求会召回很多符合条件的广告。在客户端多个广告并发请求TF Serving,可以有效降低整体预估时延。
特征ID化。通过将字符串类型的特征名哈希到64位整型空间,可以有效减少传输的数据量,降低使用的带宽。
TF Serving服务端的性能差强人意。在典型的五层网络(512*256*256*256*128)下,单个广告的预估时延约4800μs,具体见下图:

二、定制的模型计算实现
由于广告线上服务需要极高的性能,对于主流深度学习模型,我们也定制开发了具体计算实现。这种方式可以针对性的优化,并避免TF Serving不必要的特征转换和线程同步,从而提高服务性能。
例如全连接DNN模型中使用Relu作为激活函数时,我们可以使用滚动数组、剪枝、寄存器和CPU Cache等优化技巧,具体如下:
// 滚动数组
int nextLayerIndex = currentLayerIndex ^ 1 ;
System.arraycopy(bias, bOff, data[nextLayerIndex], 0, nextLayerSize);
for (int i = 0; i < currentLayerSize; i ++) {
float value = data[currentLayerIndex][i];
// 剪枝
if (value > 0.0) {
// 寄存器
int index = wOff + i * nextLayerSize;
// CPU 缓存友好
for (int j = 0; j < nextLayerSize; j++) {
data[nextLayerIndex][j] += value * weights[index + j];
}
}
}
for (int i = 0; i < nextLayerSize; k++) {
data[nextArrayIndex][i] = ReLu(data[nextArrayIndex][i]);
}
arrayIndex = nextArrayIndex;
优化后的单个广告预估时延约650μs,见下图:

综上,当前线上预估采取“两条腿走路”的策略。利用TF Serving快速实验新的模型结构,以保证迭代效率;一旦模型成熟切换主流量,我们会开发定制实现,以保证线上性能。
模型效果
借助于我们的分层实验平台,我们可以方便的分配流量,完成模型的小流量实验上线。该分层实验平台同时提供了分钟粒度的小流量实时效果数据,便于模型评估和效果监控。
四、总结与展望
经过一段时间的摸索与实践,搜索广告业务在深度学习模型排序上有了一定的成果与积累。接下来,我们将继续在特征、模型、工程角度迭代优化。特征上,更深度挖掘用户意图,刻画上下文场景,并结合DNN模型强大的表达能力充分发挥特征的作用。模型上,探索新的网络结构,并结合CNN、RNN、Attention机制等发挥深度学习模型的优势。持续跟进业界动态,并结合实际场景,应用到业务中。工程上,跟进TensorFlow的新特性,并对目前实际应用中遇到的问题针对性优化,以达到性能与效果的提升。我们在持续探索中。
原文地址https://blog.csdn.net/MeituanTech/article/details/80618755
阅读过本文的人还看了以下:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加:
datayx

长按图片,识别二维码,点关注
访问AI图谱
https://loveai.tech











