
向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
机器学习和数据科学都是广义上的术语,它们涉及超级多的领域以及知识,一位数据科学家所做的事情可能与另一位有很大的不同,机器学习工程师也是如此。通常使用过去(数据)来理解或预测(构建模型)未来。
为了将上面刚刚提到的要点融入上下文中,我必须要解释我的角色是什么。曾经我呆在一个小机器学习咨询团队。我们做到了从数据收集到清洗、构建模型再到你能想到的多个行业的服务部署。因为团队很小,所以每个人头上都有很多头衔。
机器学习工程师的日常:
早上9点,我走进办公室,向同事问好,把食物放在冰箱里,倒一杯咖啡,走到我的办公桌前。然后我坐下来,看看前一天的笔记,打开Slack,阅读未读的消息并打开团队共享的论文或博客文章链接,因为这个领域发展很快,所以要多看一些前沿的东西。
我通常都是在读完未读消息后,会花一点时间来浏览论文和博客文章,并仔细研究那些理解起来困难的内容。不得不说这其中,有一些内容对我正在做的工作有很大的帮助。一般来说,阅读会花费我大概一个小时甚至更久,这取决于文章本身。有些朋友会问我为什么这么久?
在我看来,阅读是一种终极元技能。因为一旦有更好的方式来完成我当前在做的事情,我会立即通过学习使用它,从而节约更多的时间和精力。但也有特殊情况,如果有一个项目的截止日期临近,那么我将把阅读时间缩短来推进该项目。
完成阅读之后,我会检查前一天的工作,检查我的记事本,看看我需要从什么地方开始工作,为什么我可以这样做?因为我的记事本是流水账式的日记。
例如:「将数据处理为正确格式,现在需要在模型中训练这些数据。」如果我在工作过程中遇到了困难,则会写下类似于:「发生了数据不匹配的情况,接下来我将尝试修复混合匹配,并在尝试新模型之前获得基线。」
大约在下午4点的时候我会整理一下我的代码,大概涉及:让混乱代码变得清晰,添加注释,组合。为什么要这样做?因为这个问题我经常会问自己:如果其他人看不懂这个怎么办?如果是我要读这段代码,我最需要什么?有了这样的思考后,我觉得花费一段时间来整理代码变的格外有意义。大约在下午5点,我的代码应该会被上传到GitHub上。
这是理想的一天,但并不是每一天都是如此。有时候你会在下午4点有一个极好的想法,然后跟随它,然后就有可能是通宵。
现在你应该已经大致了解了机器学习工程师一天的日常了吧,接下来我会将我在其中获得的心得分享给你。
1.睁眼闭眼全是数据
很多时候,机器学习工程师都会专注于构建更好的模型,而不是改进构建它的数据。尽管可以通过投入足够的计算能力让模型提供令人兴奋的短期结果,但这始终不会是我们想要的目标。
首次接触项目时,必须要花费大量时间熟悉数据。因为从长远来看,熟悉这些数据在未来会将节省你更多的时间。
这并不意味着你不应该从细节着手,对于任何新数据集,你的目标应该是成为这方面的「专家」。检查分布、找到不同类型的特征、异常值、为什么它们是异常值等等此类问题。如果你无法讲出当前这些数据的故事,那又怎么让模型更好的处理这些数据呢?
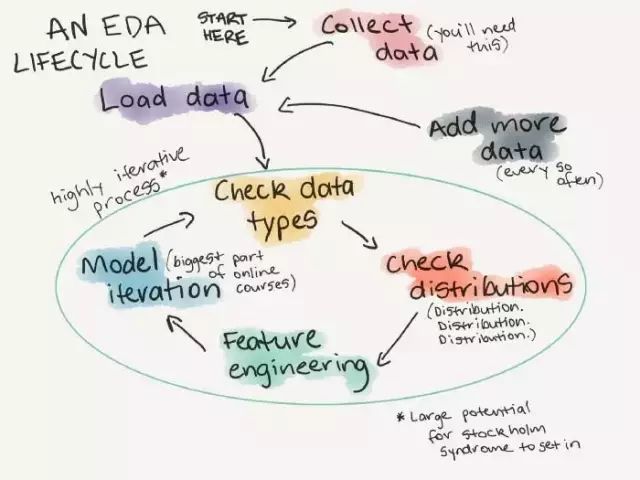
探索性数据分析生命周期的示例(每次遇到新数据集时都会执行的操作)。更多关于探索性数据分析的详细介绍。
2.沟通比解决技术问题更难
我遇到的大多数障碍都不是技术性的,而是涉及到沟通问题。当然,这其中也存在技术挑战,但作为工程师解决技术难题是我们的本职工作。
但永远不要低估内部和外部沟通的重要性。没有什么比技术选型错误更糟的了,因为这是要解决错误的技术挑战。到底什么情况会出现这样的情况呢?
从外部来看,这是因为客户所追求的与我们可以提供的东西之间的不匹配。而在内部,因为很多人都身兼数职,所以很难确保每个人都可以全身贯注于一件事情。
碰到这些问题时到底如何解决呢?
对于外部问题,我们只能不断的与客户沟通。你的客户是否了解你可以提供的服务?你了解你的客户的需求吗?他们是否了解机器学习可以提供什么以及它不能提供什么?怎么样才能更有效的传达你的想法?
对于内部问题,你可以根据我们使用解决问题的软件工具的数量来判断内部通信有多难:Asana,Jira,Trello,Slack,Basecamp,Monday,Microsoft Teams。我找到的最有效的方法之一是在一天结束时在相关项目频道中进行简单的消息更新。
它完美吗?不,但似乎有效。它给了我一个机会来反思我做了什么,并告诉大家我接下来的什么工作需要谁的支持,甚至可以从大家那里得到建议。
无论你是多么优秀的工程师,你维持和获得新业务的能力都与你沟通的技能能力有关。
3.稳定性>最先进的技术
现在有一个自然语言问题:将文本分类到不同的类别,目标是让用户将一段文本发送到服务并将其自动分类为两个类别之一。如果模型对预测没有信心,请将文本传递给人类分类器,每天的负载约为1000-3000个请求。
BERT虽然在最近一年很火。但是,如果没有谷歌那样规模的计算,用BERT训练模型来解决我们想要解决的问题时还是很复杂的,因为在投入生产之前,我们需要修改很多内容。相反,我们使用了另一种方法ULMFiT,尽管它不是最先进的,但仍然可以得到令人满意的结果,并且更容易使用。
4.机器学习初学者最常见的两个坑
将机器学习运用到实际生产中存在两个坑:一是从课程工作到项目工作的差距,二是从笔记本中的模型到生产模型(模型部署)的差距。
我在互联网上学习机器学习课程,以此来完成自己的AI硕士学位。但即使在完成了许多最好的课程之后,当我开始担任机器学习工程师时,我发现我的技能是建立在课程的结构化主干上,而项目并没有课程那样井井有条。
我缺乏很多在课程中无法学到的具体的知识,例如:如何质疑数据,探索什么数据与利用什么数据。
如何弥补这个缺陷呢?我很幸运能够成为澳大利亚最优秀的人才,但我也愿意学习并愿意做错。当然,错误不是目标,但为了正确,你必须弄清楚什么是错的。
如果你正在通过一门课程学习机器学习,那么继续学习这门课程,不过你需要通过自己的项目来学习你正在学习的知识,从而弥补课程中的不足。
至于如何进行部署?在这点上我仍然做的不是很好。还好我注意到了一种趋势:机器学习工程和软件工程正在融合。通过像Seldon,Kubeflow和Kubernetes这样的服务,很快机器学习将成为堆栈的另一部分。在Jupyter中构建模型是很简单的,但是如何让数千甚至数百万人使用该模型?这才是机器学习工程师应该思考的事情,这也是机器学习创造价值的前提。但是,根据最近在Cloud Native活动上的讨论情况来看,大公司以外的人并不知道如何做到这一点。
5. 20%的时间
20%的时间,这意味着我们20%的时间都花在了学习上。客观意义上,学习是一个松散的术语,只要是关于机器学习的都可以纳入到学习范畴内,相关业务也要不断的学习,作为机器学习工程师,懂业务可以极大的提高你的工作效率。
如果你的业务优势在于你现在所做的最好,那么未来的业务取决于你继续做你最擅长的事情,这意味着需要不断学习。
6.十分之一的论文值得阅读,但少用
这是一个粗略的指标。但是,探索任何数据集或者模型时,你很快就会发现这个规律是普遍存在的。换句话说,在每年数以千计的提交中,你可能会得到10篇开创性的论文。在这10篇开创性的论文中,有5篇可能来自于同一所研究所或者个人。
你无法跟上每一个新的突破,但可以在基本原则的坚实基础应用它们,这些基本原则经受住了时间的考验。
接下来是探索与开发的问题。
7.成为你自己最大的质疑者
探索与开发问题是尝试新事物和已经发挥作用事物之间的两难选择,你可以通过成为自己最大的怀疑者来处理这些问题。不断的向自己提问,选择这些取代旧的可以带来哪些好处?
开发
一般来说,运行你已经使用过的模型并获得高精度数字很容易,然后可以将其作为新基准报告给团队。但是如果你得到了一个好的结果,记得检查你的工作,并再次让你的团队也这样做。因为你是一名工程师,你应该有这样的意识。
探索
20%的时间花费在探索上是一个不错的决定,但是如果是70/20/10可能会更好。这意味着你需要在核心产品上花费70%的时间,在核心产品的二次开发上花费20%,在moonshots(未来要用的事情)上花费10%,虽然这些东西可能不会立即起作用。说起来很惭愧,我从来没有在我的角色中练习这个,但这是我正朝着这个方向发展的。
8.“玩具问题”非常有用
玩具问题可以帮你理解很多问题,特别是帮助解决一个复杂的问题。首先先建立一个简单的问题,它可能是关于你的数据或不相关数据集的一小部分。找出这个问题的解决方法,然后把他扩展到整个数据集中。在一个小团队中,处理问题的诀窍是抽象问题,然后理出头绪解决。
9.橡皮鸭
如果你遇到问题,坐下来盯着代码可能会解决问题,可能不会。这时,如果同你的同事探讨一下,假装他们是你的橡皮鸭,那么问题可能很容易就被解决了。
“Ron,我正在尝试遍历这个数组,并在循环通过另一个数组并跟踪状态,然后我想将这些状态组合成一个元组列表。”
“循环中的循环?你为什么不把它矢量化呢?“
“我能这样做吗?”
“让我们来尝试下吧。”
10.从0开始构建的模型数量正在下降
这与机器学习工程与软件工程正在融合有关。
除非你的数据问题非常具体,否则许多问题非常相似,分类、回归、时间序列预测、建议。
谷歌和微软的AutoML等服务正在为每个可以上传数据集并选择目标变量的人提供世界一流的机器学习。在面向开发人员方面,有像fast.ai这样的库,它们可以在几行代码中提供最先进的模型,以及各种模型动画(一组预先构建的模型),如PyTorch hub和TensorFlow集线器提供相同的功能。
这意味着我们不需要了解数据科学和机器学习的更深层次原理,只需要知道他们的基本原理即可,我们应该更关心如何将它们应用到实际问题中去创造价值。
11.数学还是代码?
对于我所处理的客户问题,我们都是代码优先,而且所有的机器学习和数据科学代码都是Python。有时我会通过阅读论文并复现它来涉足数学,但是现有的框架大都包含了数学。这并不是说数学是不必要的,毕竟机器学习和深度学习都是应用数学的形式。
掌握最小矩阵的操作、一些线性代数和微积分,特别是链式法则足以成为一个机器学习从业者。
请记住,大多数时候或者大多数从业者的目标不是发明一种新的机器学习算法,而是向客户展示潜在的机器学习对他们的业务有没有帮助。
12.你去年所做的工作明年可能会无效
这是大趋势,因为软件工程和机器学习工程的融合,这种情况正在变得越来越明显。
但这也是你进入这个行业的原因,框架将发生变化,各种实用库将发生变化,但基础统计数据、概率学、数学、这些事情都是不变的。最大的挑战仍然是:如何应用它们创造价值。
现在怎么办?
机器学习工程师的成长道路上应该还有很多坑需要去探,如果你是一个新手,先掌握这12条就足够了!
阅读过本文的人还看了以下文章:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech












