
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
目前在深度学习领域分类两个派别,一派为学院派,研究强大、复杂的模型网络和实验方法,为了追求更高的性能;另一派为工程派,旨在将算法更稳定、高效的落地在硬件平台上,效率是其追求的目标。复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。
最近正好在关注有关深度学习模型压缩的方法,发现目前已有越来越多关于模型压缩方法的研究,从理论研究到平台实现,取得了非常大的进展。
2015年,Han发表的Deep Compression
(https://arxiv.org/abs/1510.00149)
是一篇对于模型压缩方法的综述型文章,将裁剪、权值共享和量化、编码等方式运用在模型压缩上,取得了非常好的效果,作为ICLR2016的best paper,也引起了模型压缩方法研究的热潮。其实模型压缩最早可以追溯到1989年,Lecun老爷子的那篇Optimal Brain Damage(OBD)
http://papers.nips.cc/paper/250-optimal-brain-damage.pdf
就提出来,可以将网络中不重要的参数剔除,达到压缩尺寸的作用,想想就可怕,那时候连个深度网络都训练不出来,更没有现在这么发达的技术,Lecun就已经想好怎么做裁剪了,真是有先见之明,目前很多裁剪方案,都是基于老爷子的OBD方法。
目前深度学习模型压缩方法的研究主要可以分为以下几个方向:
更精细模型的设计,目前的很多网络都具有模块化的设计,在深度和宽度上都很大,这也造成了参数的冗余很多,因此有很多关于模型设计的研究,如SqueezeNet、MobileNet等,使用更加细致、高效的模型设计,能够很大程度的减少模型尺寸,并且也具有不错的性能。
模型裁剪,结构复杂的网络具有非常好的性能,其参数也存在冗余,因此对于已训练好的模型网络,可以寻找一种有效的评判手段,将不重要的connection或者filter进行裁剪来减少模型的冗余。
核的稀疏化,在训练过程中,对权重的更新进行诱导,使其更加稀疏,对于稀疏矩阵,可以使用更加紧致的存储方式,如CSC,但是使用稀疏矩阵操作在硬件平台上运算效率不高,容易受到带宽的影响,因此加速并不明显。
除此之外,量化、Low-rank分解、迁移学习等方法也有很多研究,并在模型压缩中起到了非常好的效果。
基于核的稀疏化方法
核的稀疏化,是在训练过程中,对权重的更新加以正则项进行诱导,使其更加稀疏,使大部分的权值都为0。核的稀疏化方法分为regular和irregular,regular的稀疏化后,裁剪起来更加容易,尤其是对im2col的矩阵操作,效率更高;而irregular的稀疏化后,参数需要特定的存储方式,或者需要平台上稀疏矩阵操作库的支持,可以参考的论文有:
Learning Structured Sparsity in Deep Neural Networks
论文地址
http://papers.nips.cc/paper/6504-learning-structured-sparsity-in-deep-neural-networks.pdf
本文作者提出了一种Structured Sparsity Learning的学习方式,能够学习一个稀疏的结构来降低计算消耗,所学到的结构性稀疏化能够有效的在硬件上进行加速。传统非结构化的随机稀疏化会带来不规则的内存访问,因此在GPU等硬件平台上无法有效的进行加速。作者在网络的目标函数上增加了group lasso的限制项,可以实现filter级与channel级以及shape级稀疏化。所有稀疏化的操作都是基于下面的loss func进行的,其中Rg为group lasso:
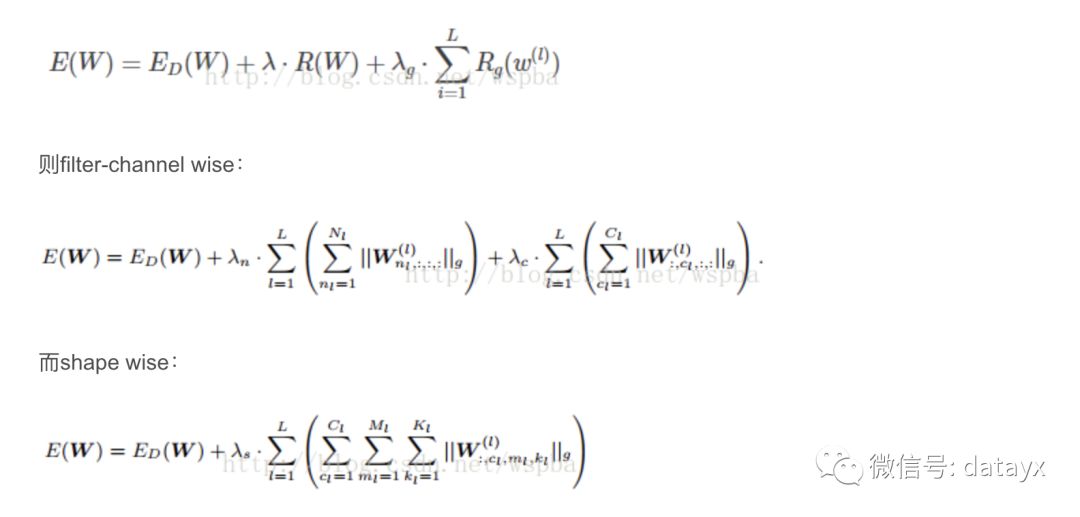
由于在GEMM中将weight tensor拉成matrix的结构,因此可以通过将filter级与shape级的稀疏化进行结合来将2D矩阵的行和列稀疏化,再分别在矩阵的行和列上裁剪掉剔除全为0的值可以来降低矩阵的维度从而提升模型的运算效率。该方法是regular的方法,压缩粒度较粗,可以适用于各种现成的算法库,但是训练的收敛性和优化难度不确定。作者的源码为:https://github.com/wenwei202/caffe/tree/scnn
Dynamic Network Surgery for Efficient DNNs 论文地址
http://arxiv.org/abs/1608.04493
作者提出了一种动态的模型裁剪方法,包括以下两个过程:pruning和splicing,其中pruning就是将认为不中要的weight裁掉,但是往往无法直观的判断哪些weight是否重要,因此在这里增加了一个splicing的过程,将哪些重要的被裁掉的weight再恢复回来,类似于一种外科手术的过程,将重要的结构修补回来,它的算法如下:

作者通过在W上增加一个T来实现,T为一个2值矩阵,起到的相当于一个mask的功能,当某个位置为1时,将该位置的weight保留,为0时,裁剪。在训练过程中通过一个可学习mask将weight中真正不重要的值剔除,从而使得weight变稀疏。由于在删除一些网络的连接,会导致网络其他连接的重要性发生改变,所以通过优化最小损失函数来训练删除后的网络比较合适。
优化问题表达如下:

该算法采取了剪枝与嫁接相结合、训练与压缩相同步的策略完成网络压缩任务。通过网络嫁接操作的引入,避免了错误剪枝所造成的性能损失,从而在实际操作中更好地逼近网络压缩的理论极限。属于irregular的方式,但是ak和bk的值在不同的模型以及不同的层中无法确定,并且容易受到稀疏矩阵算法库以及带宽的限制。论文源码:https://github.com/yiwenguo/Dynamic-Network-Surgery
Training Skinny Deep Neural Networks with Iterative Hard Thresholding Methods
论文地址
https://arxiv.org/abs/1607.05423
作者想通过训练一个稀疏度高的网络来降低模型的运算量,通过在网络的损失函数中增加一个关于W的L0范式可以降低W的稀疏度,但是L0范式就导致这是一个N-P难题,是一个难优化求解问题,因此作者从另一个思路来训练这个稀疏化的网络。算法的流程如下:

先正常训练网络s1轮,然后Ok(W)表示选出W中数值最大的k个数,而将剩下的值置为0,supp(W,k)表示W中最大的k个值的序号,继续训练s2轮,仅更新非0的W,然后再将之前置为0的W放开进行更新,继续训练s1轮,这样反复直至训练完毕。同样也是对参数进行诱导的方式,边训练边裁剪,先将认为不重要的值裁掉,再通过一个restore的过程将重要却被误裁的参数恢复回来。也是属于irregular的方式,边训边裁,性能不错,压缩的力度难以保证。
总结
以上三篇文章都是基于核稀疏化的方法,都是在训练过程中,对参数的更新进行限制,使其趋向于稀疏,或者在训练的过程中将不重要的连接截断掉,其中第一篇文章提供了结构化的稀疏化,可以利用GEMM的矩阵操作来实现加速。第二篇文章同样是在权重更新的时候增加限制,虽然通过对权重的更新进行限制可以很好的达到稀疏化的目的,但是给训练的优化增加了难度,降低了模型的收敛性。此外第二篇和第三篇文章都是非结构化的稀疏化,容易受到稀疏矩阵算法库以及带宽的限制,这两篇文章在截断连接后还使用了一个surgery的过程,能够降低重要参数被裁剪的风险。
基于模型裁剪的方法
对以训练好的模型进行裁剪的方法,是目前模型压缩中使用最多的方法,通常是寻找一种有效的评判手段,来判断参数的重要性,将不重要的connection或者filter进行裁剪来减少模型的冗余。同样也分为regular和irregular的方式。这类方法最多,下面列举几篇典型的方案。
Pruning Filters for Efficient Convnets 论文地址
https://arxiv.org/pdf/1608.08710.pdf
作者提出了基于量级的裁剪方式,用weight值的大小来评判其重要性,对于一个filter,其中所有weight的绝对值求和,来作为该filter的评价指标,将一层中值低的filter裁掉,可以有效的降低模型的复杂度并且不会给模型的性能带来很大的损失,算法流程如下:

裁剪方式如下:
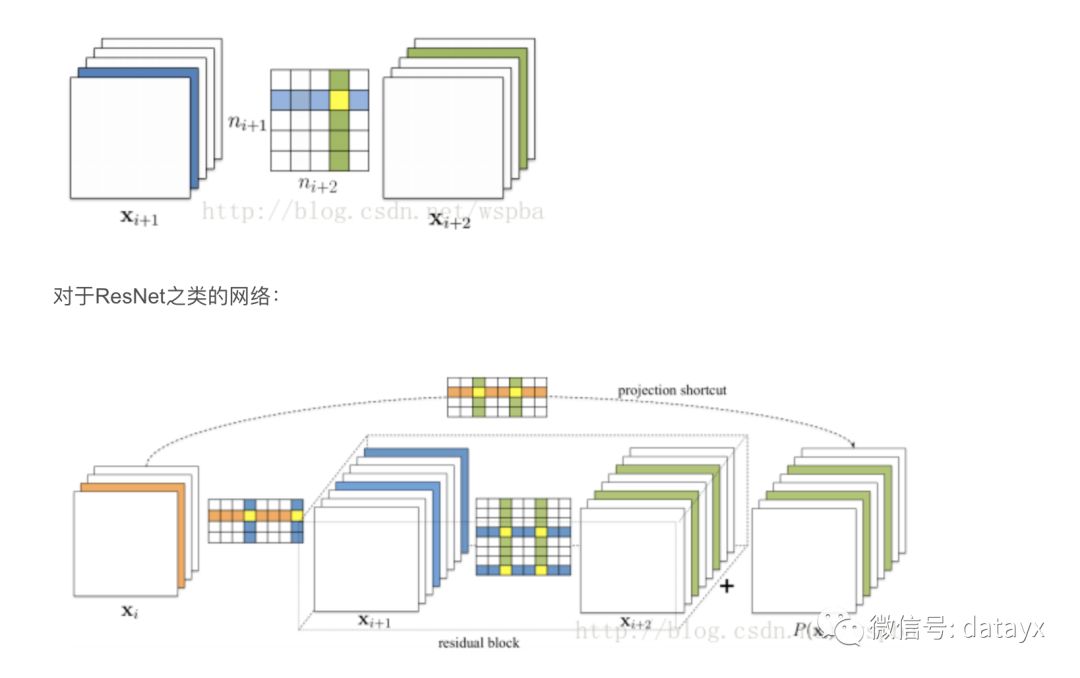
作者在裁剪的时候同样会考虑每一层对裁剪的敏感程度,作者会单独裁剪每一层来看裁剪后的准确率。对于裁剪较敏感的层,作者使用更小的裁剪力度,或者跳过这些层不进行裁剪。目前这种方法是实现起来较为简单的,并且也是非常有效的,它的思路非常简单,就是认为参数越小则越不重要。
Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures
论文地址
https://arxiv.org/abs/1607.03250
作者认为,在大型的深度学习网络中,大部分的神经元的激活都是趋向于零的,而这些激活为0的神经元是冗余的,将它们剔除可以大大降低模型的大小和运算量,而不会对模型的性能造成影响,于是作者定义了一个量APoZ(Average Percentage of Zeros)来衡量每一个filter中激活为0的值的数量,来作为评价一个filter是否重要的标准。APoZ定义如下:
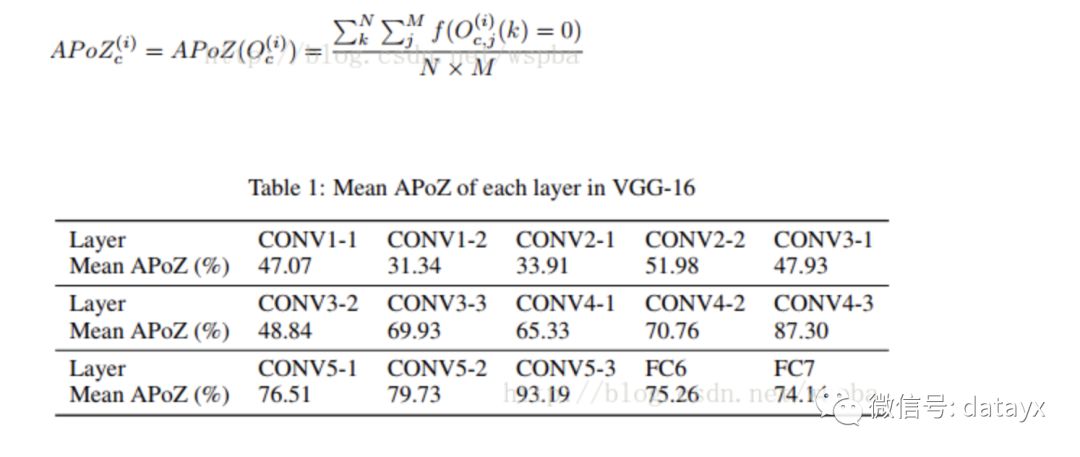
作者发现在VGG-16中,有631个filter的APoZ超过了90%,也就说明了网络中存在大量的冗余。作者的裁剪方式如下:
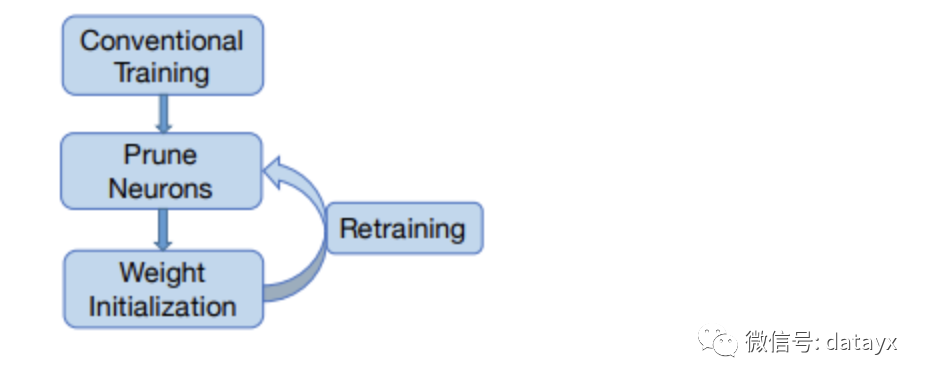
但是作者仅在最后一个卷积层和全连接层上进行了实验,因此该方法在实际中的效果很难保证。
An Entropy-based Pruning Method for CNN Compression
论文地址
https://arxiv.org/pdf/1706.05791.pdf
作者认为通过weight值的大小很难判定filter的重要性,通过这个来裁剪的话有可能裁掉一些有用的filter。因此作者提出了一种基于熵值的裁剪方式,利用熵值来判定filter的重要性。作者将每一层的输出通过一个Global average Pooling将feature map转换为一个长度为c(filter数量)的向量,对于n张图像可以得到一个n*c的矩阵,对于每一个filter,将它分为m个bin,统计每个bin的概率,然后计算它的熵值 利用熵值来判定filter的重要性,再对不重要的filter进行裁剪。第j个feature map熵值的计算方式如下:

在retrain中,作者使用了这样的策略,即每裁剪完一层,通过少数几个迭代来恢复部分的性能,当所有层都裁剪完之后,再通过较多的迭代来恢复整体的性能,作者提出,在每一层裁剪过后只使用很少的训练步骤来恢复性能,能够有效的避免模型进入到局部最优。作者将自己的retrain方式与传统的finetuning方式进行比较,发现作者的方法能够有效的减少retrain的步骤,并也能达到不错的效果。
在VGG16上作者的裁剪方式和结果如下,由于作者考虑VGG-16全连接层所占的参数量太大,因此使用GAP的方式来降低计算量:
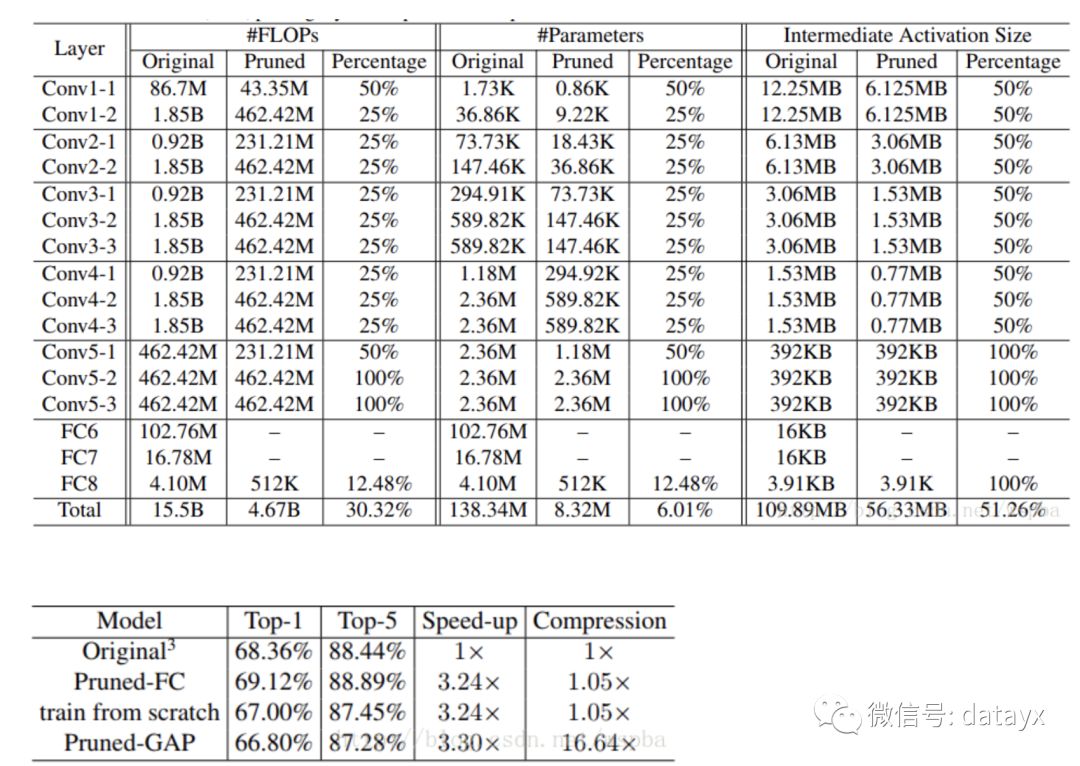
Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning
论文地址
https://arxiv.org/pdf/1611.05128.pdf
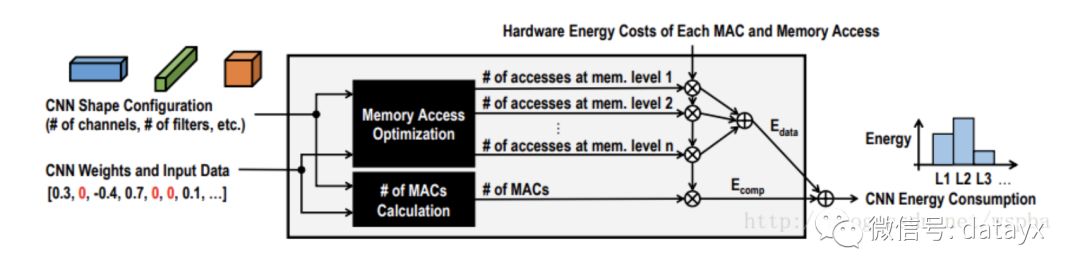
这篇文章也是今天的CVPR,作者认为以往的裁剪方法,都没有考虑到模型的带宽以及能量的消耗,因此无法从能量利用率上最大限度的裁剪模型,因此提出了一种基于能量效率的裁剪方式。作者指出一个模型中的能量消耗包含两个部分,一部分是计算的能耗,一部分是数据转移的能耗,在作者之前的一片论文中(与NVIDIA合作,Eyeriss),提出了一种估计硬件能耗的工具,能够对模型的每一层计算它们的能量消耗。然后将每一层的能量消耗从大到小排序,对能耗大的层优先进行裁剪,这样能够最大限度的降低模型的能耗,对于需要裁剪的层,根据weight的大小来选择不重要的进行裁剪,同样的作者也考虑到不正确的裁剪,因此将裁剪后模型损失最大的weight保留下来。
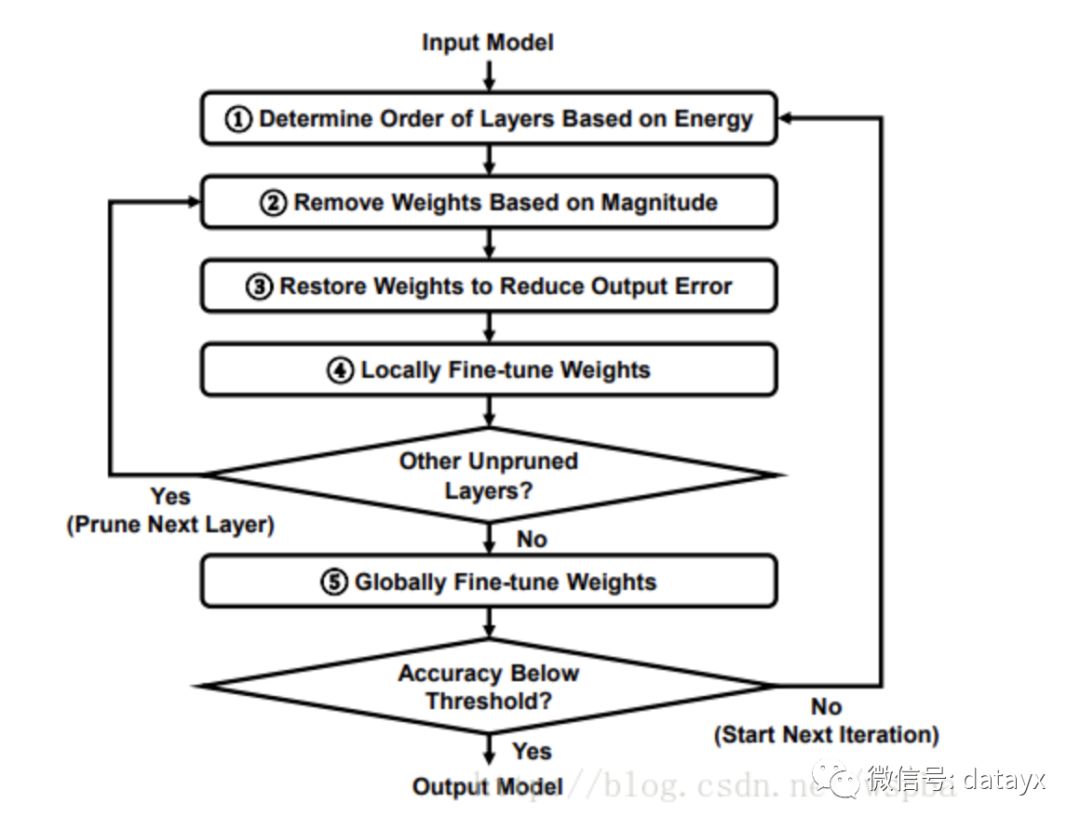
每裁剪完一层后,对于该层进行locally的fine-tune,locally的fine-tune,是在每一层的filter上,使用最小二乘优化的方法来使裁剪后的filter调整到使得输出与原始输出尽可能的接近。在所有层都裁剪完毕后,再通过一个global的finetuning来恢复整体的性能。整个流程如下:
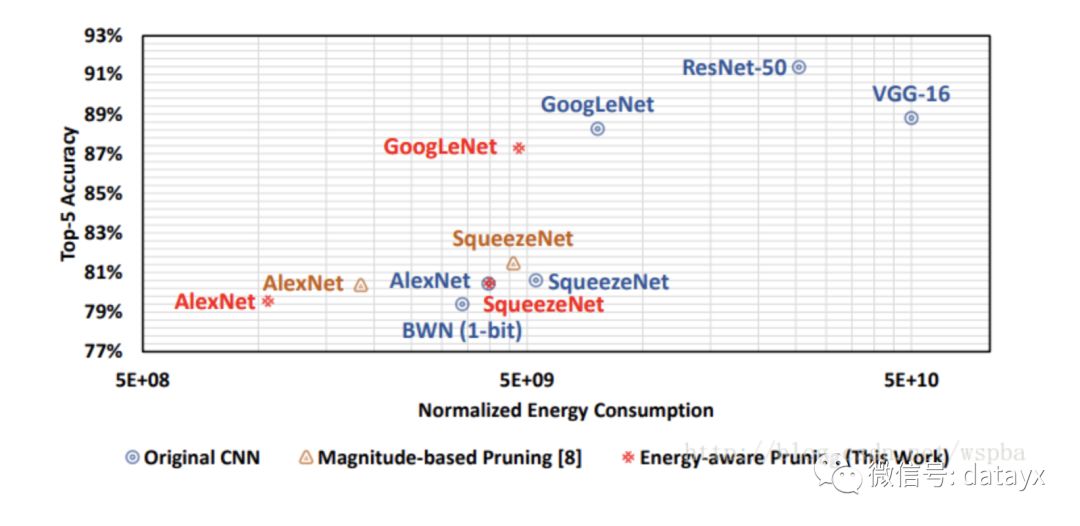
作者从能耗的角度对层的裁剪程度进行分析,经过裁剪后,模型的能耗压缩较大:
总结
可以看出来,基于模型裁剪的方法很多,其思路源头都是来自于Oracle pruning 的方法,即挑选出模型中不重要的参数,将其剔除而不会对模型的效果造成太大的影响,而如何找到一个有效的对参数重要性的评价手段,在这个方法中就尤为重要,我们也可以看到,这种评价标准花样百出,各有不同,也很难判定那种方法更好。在剔除不重要的参数之后,通过一个retrain的过程来恢复模型的性能,这样就可以在保证模型性能的情况下,最大程度的压缩模型参数及运算量。目前,基于模型裁剪的方法是最为简单有效的模型压缩方式。
我们介绍了一些在已有的深度学习模型的基础上,直接对其进行压缩的方法,包括核的稀疏化,和模型的裁剪两个方面的内容,其中核的稀疏化可能需要一些稀疏计算库的支持,其加速的效果可能受到带宽、稀疏度等很多因素的制约;而模型的裁剪方法则比较简单明了,直接在原有的模型上剔除掉不重要的filter,虽然这种压缩方式比较粗糙,但是神经网络的自适应能力很强,加上大的模型往往冗余比较多,将一些参数剔除之后,通过一些retraining的手段可以将由剔除参数而降低的性能恢复回来,因此只需要挑选一种合适的裁剪手段以及retraining方式,就能够有效的在已有模型的基础上对其进行很大程度的压缩,是目前使用最普遍的方法。然而除了这两种方法以外,本文还将为大家介绍另外两种方法:基于教师——学生网络、以及精细模型设计的方法。
基于教师——学生网络的方法
基于教师——学生网络的方法,属于迁移学习的一种。迁移学习也就是将一个模型的性能迁移到另一个模型上,而对于教师——学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。
Distilling the Knowledge in a Neural Network
论文地址
https://arxiv.org/pdf/1503.02531.pdf
较大、较复杂的网络虽然通常具有很好的性能,但是也存在很多的冗余信息,因此运算量以及资源的消耗都非常多。而所谓的Distilling就是将复杂网络中的有用信息提取出来迁移到一个更小的网络上,这样学习来的小网络可以具备和大的复杂网络想接近的性能效果,并且也大大的节省了计算资源。这个复杂的网络可以看成一个教师,而小的网络则可以看成是一个学生。
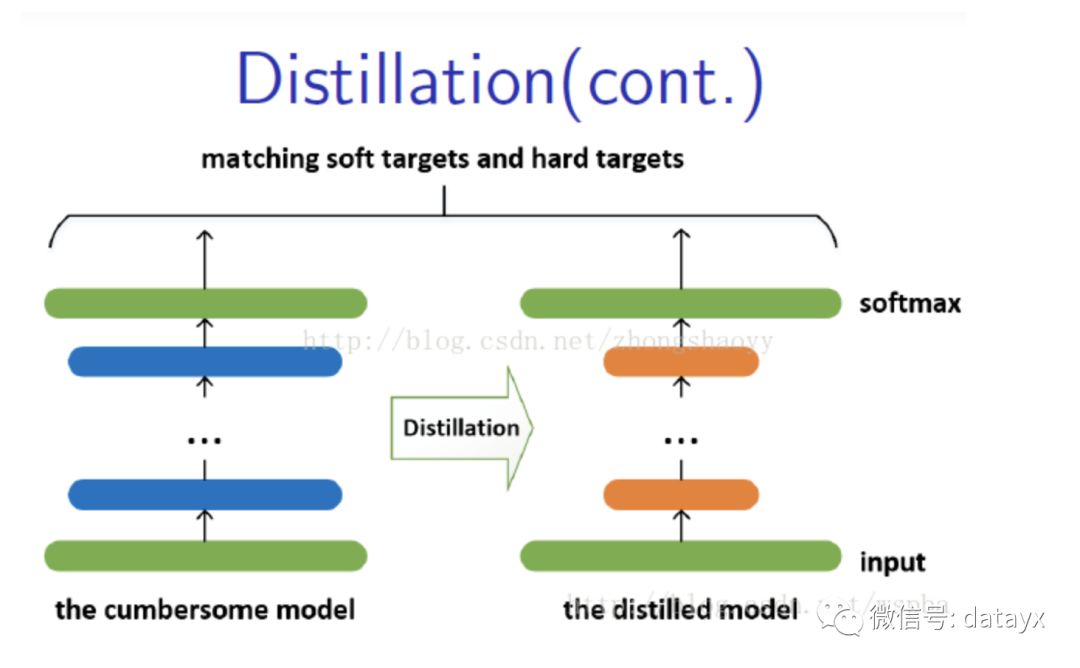
这个复杂的网络是提前训练好具有很好性能的网络,学生网络的训练含有两个目标:一个是hard target,即原始的目标函数,为小模型的类别概率输出与label真值的交叉熵;另一个为soft target,为小模型的类别概率输出与大模型的类别概率输出的交叉熵,在soft target中,概率输出的公式调整如下,这样当T值很大时,可以产生一个类别概率分布较缓和的输出:
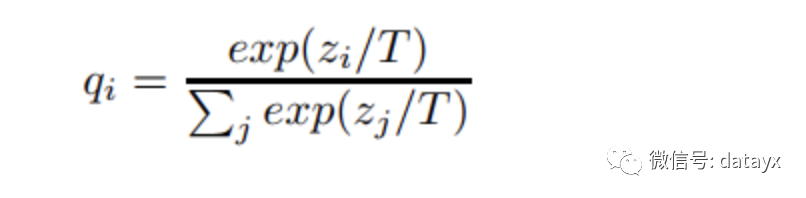
作者认为,由于soft target具有更高的熵,它能比hard target提供更加多的信息,因此可以使用较少的数据以及较大的学习率。将hard和soft的target通过加权平均来作为学生网络的目标函数,soft target所占的权重更大一些。作者同时还指出,T值取一个中间值时,效果更好,而soft target所分配的权重应该为T^2,hard target的权重为1。这样训练得到的小模型也就具有与复杂模型近似的性能效果,但是复杂度和计算量却要小很多。
对于distilling而言,复杂模型的作用事实上是为了提高label包含的信息量。通过这种方法,可以把模型压缩到一个非常小的规模。模型压缩对模型的准确率没有造成太大影响,而且还可以应付部分信息缺失的情况。
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
论文地址
https://arxiv.org/abs/1612.03928
作者借鉴Distilling的思想,使用复杂网络中能够提供视觉相关位置信息的Attention map来监督小网络的学习,并且结合了低、中、高三个层次的特征,示意图如下:
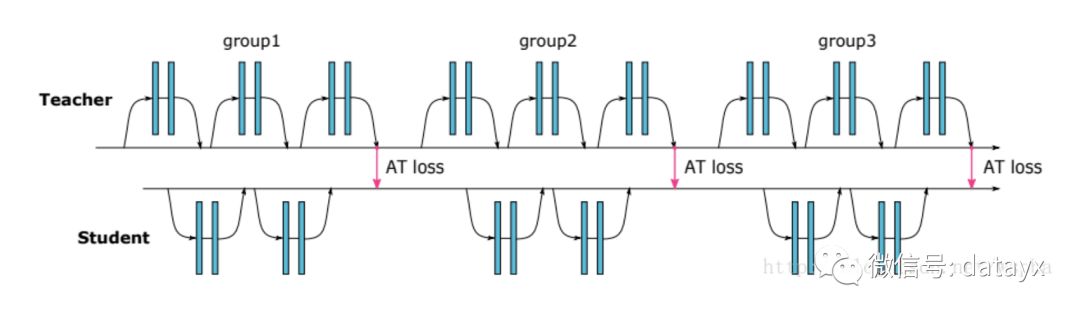
教师网络从三个层次的Attention Transfer对学生网络进行监督。其中三个层次对应了ResNet中三组Residual Block的输出。在其他网络中可以借鉴。这三个层次的Attention Transfer基于Activation,Activation Attention为feature map在各个通道上的值求和,基于Activation的Attention Transfer的损失函数如下:

但是就需要两次反向传播的过程,实现起来较困难并且效果提升不明显。基于Activation的Attention Transfer效果较好,而且可以和Hinton的Distilling结合。
目前已有基于Activation的实现源码:https://github.com/szagoruyko/attention-transfer
基于精细模型设计的方法
上述几种方法都是在已有的性能较好模型的基础上,在保证模型性能的前提下尽可能的降低模型的复杂度以及运算量。除此之外,还有很多工作将注意力放在更小、更高效、更精细的网络模块设计上,如SqueezeNet的fire module,ResNet的Residual module,GoogLenet的Inception Module,它们基本都是由很小的卷积(1*1和3*3)组成,不仅参数运算量小,同时还具备了很好的性能效果。
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文地址
https://arxiv.org/abs/1704.04861
这篇论文是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,取名为MobileNets。核心思想就是卷积核的巧妙分解,可以有效减少网络参数。所谓的卷积核分解,实际上就是将a × a × c分解成一个a × a × 1的卷积和一个1 ×1 × c的卷积,,其中a是卷积核大小,c是卷积核的通道数。其中第一个a × a × 1的卷积称为Depthwise Separable Convolutions,它对前一层输出的feature map的每一个channel单独进行a × a 的卷积来提取空间特征,然后再使用1 ×1 的卷积将多个通道的信息线性组合起来,称为Pointwise Convolutions,如下图:
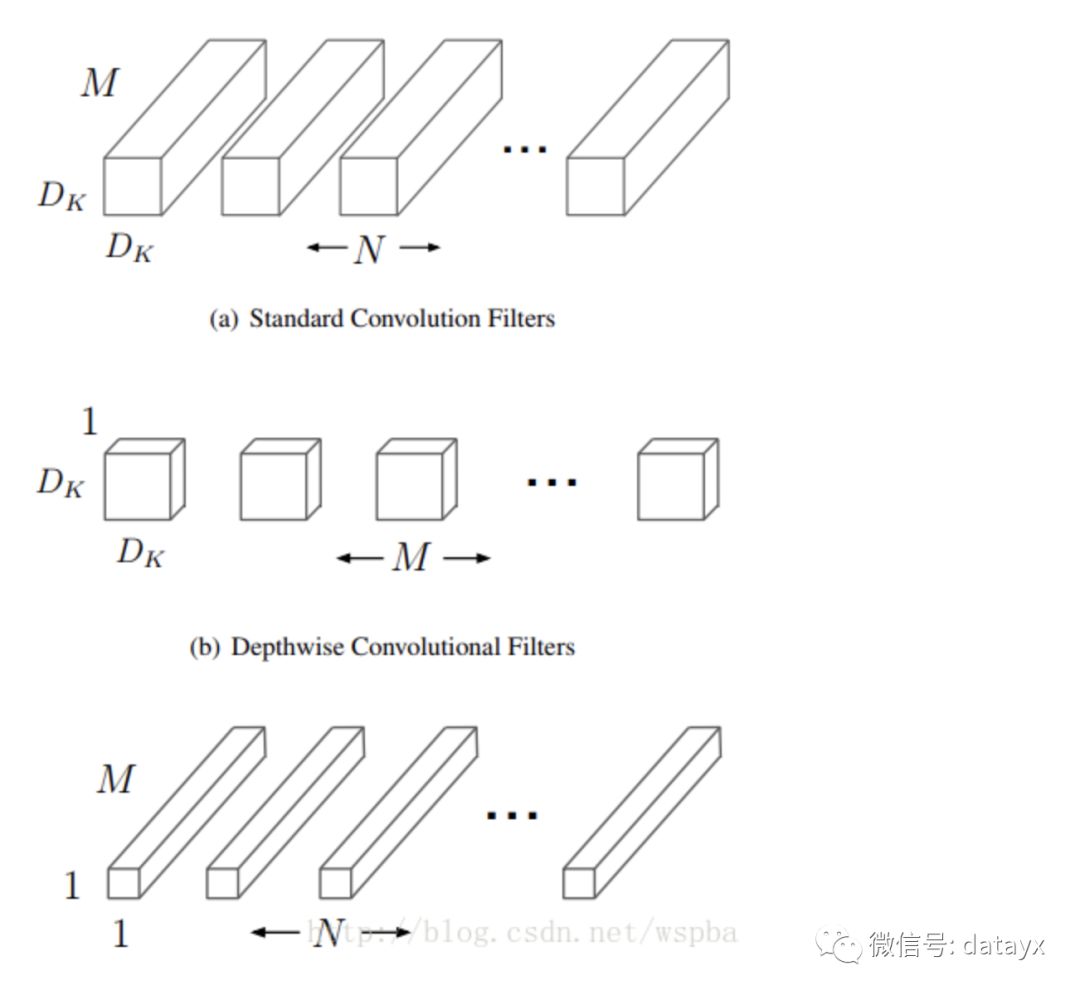

其中DK为原始卷积核的大小,DF为输入feature map的尺寸, 这样相当于将运算量降低DK^2倍左右。
MobileNet中Depthwise实际上是通过卷积中的group来实现的,其实在后面也会发现,这些精细模型的设计都是和group有关。本文的源码:https://github.com/shicai/MobileNet-Caffe
Aggregated Residual Transformations for Deep Neural Networks
论文地址
https://arxiv.org/pdf/1611.05431.pdf
作者提出,在传统的ResNet的基础上,以往的方法只往两个方向进行研究,一个深度,一个宽度,但是深度加深,模型训练难度更大,宽度加宽,模型复杂度更高,计算量更大,都在不同的程度上增加了资源的损耗,因此作者从一个新的维度:Cardinality(本文中应该为path的数量)来对模型进行考量,作者在ResNet的基础上提出了一种新的结构,ResNeXt:
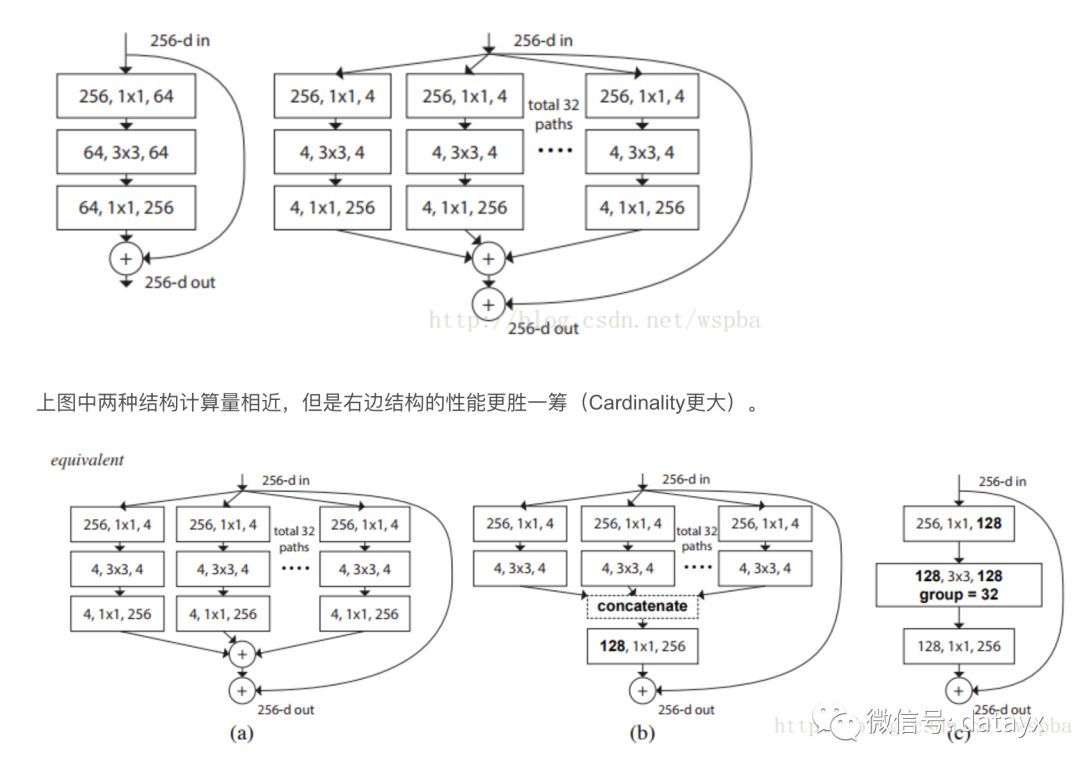
以上三种结构等价,因此可以通过group的形式来实现ResNeXt。其实ResNeXt和mobilenet等结构性质很相近,都是通过group的操作,在维度相同时降低复杂度,或者在复杂度相同时增加维度,然后再通过1*1的卷积将所有通道的信息再融合起来。因此全文看下来,作者的核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。本文的源码:https://github.com/facebookresearch/ResNeXt
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文地址
https://arxiv.org/abs/1707.01083?context=cs.CV
作者提出,虽然MobileNet、ResNeXt等网络能够大大的降低模型的复杂度,并且也能保持不错的性能,但是1 ×1卷积的计算消耗还是比较大的,比如在ResNeXt中,一个模块中1 ×1卷积就占据了93%的运算量,而在MobileNet中更是占到了94.86%,因此作者希望在这个上面进一步降低计算量:即在1 ×1的卷积上也采用group的操作,但是本来1 ×1本来是为了整合所有通道的信息,如果使用group的操作就无法达到这个效果,因此作者就想出了一种channel shuffle的方法,如下图:
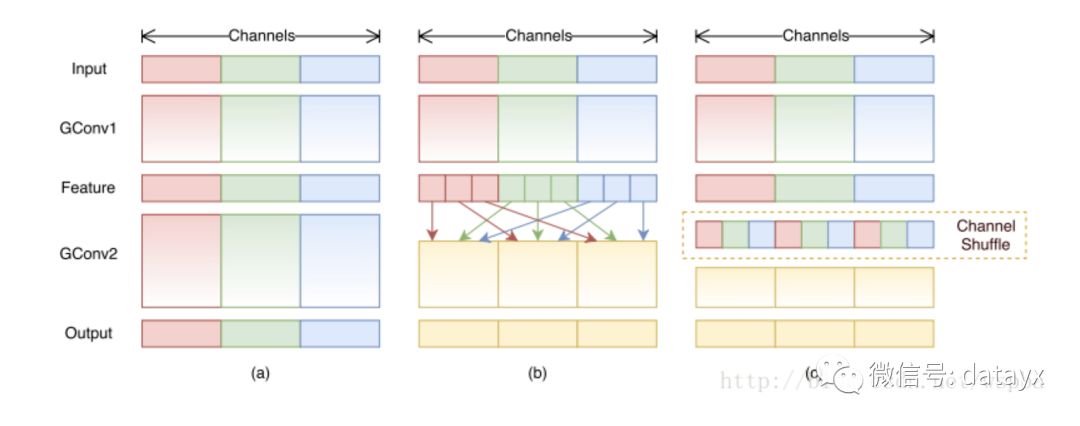
如上图b和c,虽然对1 ×1的卷积使用了group的操作,但是在中间的feature map增加了一个channel shuffle的操作,这样每个group都可以接受到上一层不同group的feature,这样就可以很好的解决之前提到的问题,同时还降低了模型的计算量,ShuffleNet的模块如下:
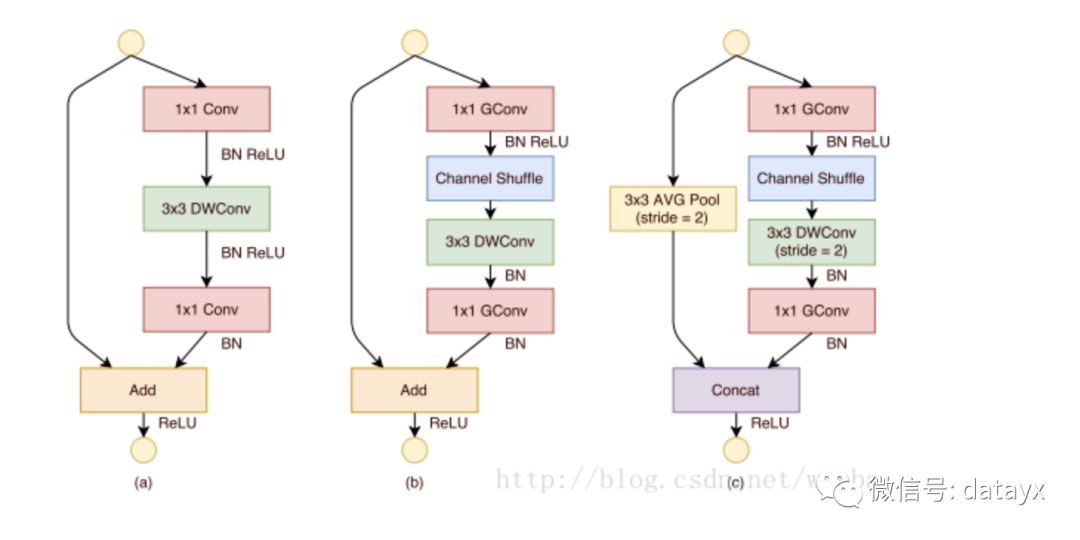
作者使用了不同的group数进行实验,发现越小的模型,group数量越多性能越好。这是因为在模型大小一样的情况下,group数量越多,feature map的channel数越多,对于小的模型,channel数量对于性能提升更加重要。
最后作者将shufflenet的方法和mobilenet的方法进行了比较,性能似乎更胜一筹:
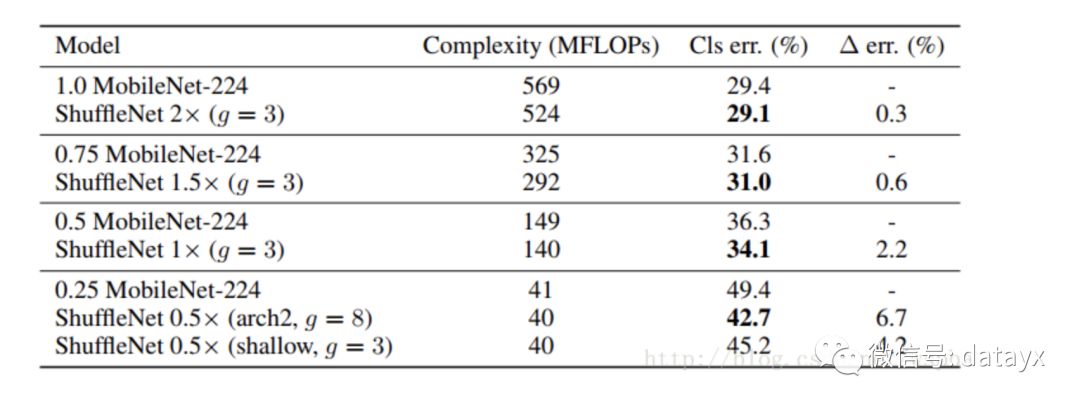
小结
本节的三篇论文都是对精细模型的设计方法,直接搭建出参数运算量小的模型,适用于嵌入式平台,基本上都是通过group的方式来实现,确实能够很大程度的将模型的计算量降到最低,尤其是最后一篇shufflenet,实际上利用了一个特征融合的思路,在一个下模型中,分为更细的模型(group),再将这些更细的模型有效的融合起来,能够充分的利用参数,而达到更好的压缩效果。
结论
目前关于深度学习模型压缩的方法有很多,本文从四个角度来对模型压缩的方法进行了介绍,总的来说,所列出的文章和方法都具有非常强的借鉴性,值得我们去学习,效果也较明显。其中基于核稀疏化的方法,主要是在参数更新时增加额外的惩罚项,来诱导核的稀疏化,然后就可以利用裁剪或者稀疏矩阵的相关操作来实现模型的压缩;基于模型裁剪的方法,主要是对已训练好的网络进行压缩,往往就是寻找一种更加有效的评价方式,将不重要的参数剔除,以达到模型压缩的目的,这种压缩方法实现简单,尤其是regular的方式,裁剪效率最高,但是如何寻找一个最有效的评价方式是最重要的。基于迁移学习的方法,利用一个性能好的教师网络来监督学生网络进行学习,大大降低了简单网络学习到不重要信息的比例,提高了参数的利用效率,也是目前用的较多的方法。基于精细模型设计的方法,模型本身体积小,运行速度快,性能也不错,目前小的高效模型也开始广泛运用在各种嵌入式平台中。
总的来说,以上几种方法可以结合使用,比如说先对参数进行结构化的限制,使得参数裁剪起来更加容易,然后再选择合适的裁剪方法,考虑不同的评价标准以及裁剪策略,并在裁剪过程中充分考虑参数量、计算量、带宽等需求,以及不同硬件平台特性,在模型的性能、压缩、以及平台上的加速很好的进行权衡,才能够达到更好的效果。
原文地址 https://blog.csdn.net/wspba/article/details/75671573
阿里云双11大促 服务器ECS 数据库 全场1折
活动地址

1核2G1M,86一年,¥229三年
2核4G3M,¥799三年
2核8G5M,¥1399三年
......
阅读过本文的人还看了以下文章:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech












