0 前言
数据根据结构可以分为结构化数据、非结构化数据和半结构化数据,前面介绍的数据处理函数针对于结构化数据,而字符串通常包含非结构化或者半结构化数据,这一部分介绍一下R和Python中的字符串函数。
1 目录
三种数据结构简介
R与Python字符串函数
字符串函数-基于R
字符串函数--基于Python
2 三种数据结构
数据根据结构分为三种:结构化数据、非结构化数据、半结构化数据。
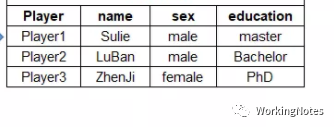
结构化数据可以使用关系数据库(RDBMS)存储,可以使用二维表来逻辑表达实现的数据(R和Python中的数据框类型数据)。数据以行为单位,每一行表示一个实体的信息,例如下图数据;结构化数据存储和排列很有规律,这有利于数据的查询和修改,但是扩展性不好,例如需要增加一个字段,需要对表进行添加列操作。
半结构化数据介于完全结构化数据和完全无结构化数据之间,具有一定的结构性。也就是说不符合关系型数据库而无法使用二维表逻辑表达的数据,和普通文本相比,半结构化数据具有一定的结构性,OEM(Object exchange Model)是一种典型的半结构化数据模型。XML、HTML文档就属于半结构化数据,数据的结果和内容混在一起,没有明显的区分。对于这种数据一般是化解为结构化数据。
非结构化数据,没有结构性的数据,各种文档、图片、视频、音频等都属于非结构化数据。对于非结构性数据,一般直接整体进行存储,而且通常存储为二进制的数据格式。
3 R与Python字符串函数
R语言中推荐使用stringr包里面的函数进行字符串处理,Python中有正则表达式库re和内置的字符串string包。
4 字符串函数--基于R
R语言中自带的字符串函数操作起来非常难用,而且函数名字经常记不住,因此这里介绍stringr包,提供了大部分字符串处理函数(如果发现很难使用stringr包中函数实现,可以考虑使用stringi,里面包含了全部字符串处理函数),函数名都是以str_开头,函数的名称更加直观,比较容易记住。
stringr包中函数按照是否使用正则表达式分为使用正则表达式函数和其他函数,函数参数中有pattern参数的则为使用正则表达式函数。按照函数功能可分为:字符串拼接函数、字符串计算函数、字符串匹配函数和字符串转换函数,如图:
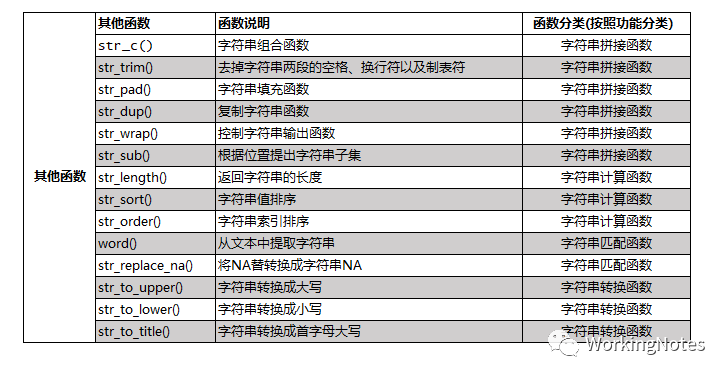
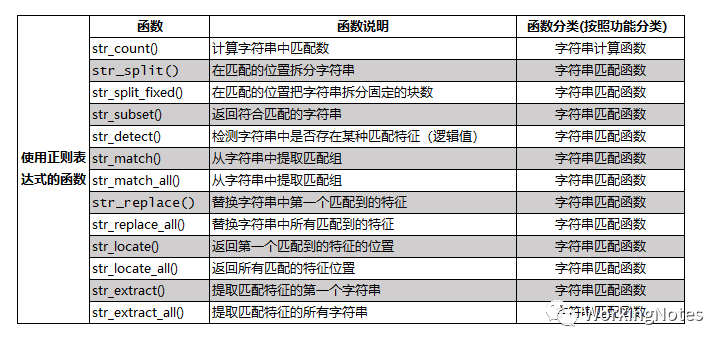
下面会按照字符串其他函数、R语言中正则表达式以及使用正则表达式的字符串函数进行介绍。
4.1 非正则表达式字符串函数
str_c()函数
字符串组合函数。组合两个或者多个字符串或者将字符向量合并为字符串,返回一个字符串
str_c(..., sep = "", collapse = NULL)
参数
sep : 字符串之间的分割方式使用sep参数控制
collapse : 控制字符串向量之间的连接方式
library(stringr)str_c("Flash", "Workingnots")str_c("Flash", "Workingnots", sep = "-")str_c("Flash", "Workingnots", sep = "&")
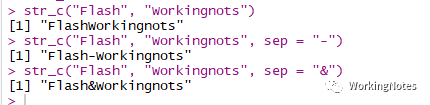
str_c()是向量化的,当一个短向量和一个长向量组合的时候,会自动循环短向量,返回字符串长度与长向量长度一致:
str_c("Flash", c(1:10), sep = "_")

将字符向量组合成字符串,分隔参数使用collapse:
str_c(c("Flash", "WorkingNotes"), collapse = "&")

str_trim()函数
删除字符串两端的空格、换行符以及制表符;
str_trim(string, side = c("both", "left", "right"))
参数
side : 制定删除的位置,both:两端的空格都删除;left:删除左边的空格;right:删除右边的空格
text str_trim(text, side = "both")str_trim(text, side = "left")str_trim(text, side = "right")

str_pad()函数
字符串填充函数。指定字符串的长度,不足长度的位置用填充符填充,字符串长度已经长于指定长度,不填充。
str_pad(string, width, side = c("left", "right", "both"), pad = " ")
参数
width :指定填充后的字符串长度
side : 填充的位置,同str_trim()的参数
pad : 指定填充的字符,默认为空格

str_pad(text, width = 30, side = "both", pad = "*")str_pad(text, width = 30, side = "left", pad = "*")str_pad(text, width = 30, side = "right", pad = "*")str_pad(text, width = 30, side = "both")str_pad(text, width = 10, side = "both")

str_dup()
字符串复制函数,使用参数控制复制的次数。
参数
times : 用于指定字符串复制的次数
str_dup("Flash", times = 3)str_dup("Flash", times = 2)

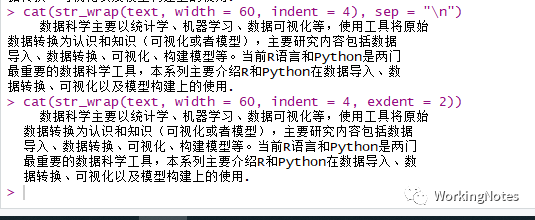
str_wrap()函数
用于控制字符串的输出格式,用于段落的划分,可以指定每行的长度,首行缩进等,和cat()函数一起使用。
str_wrap(string, width = 80, indent = 0, exdent = 0)
参数
width : 指定每一行的长度
indent : 指定第一行的缩进格式,默认无缩进
exdent : 指定第一行的之后其他行的缩进格式
cat(str_wrap(text, width = 60, indent = 4))cat(str_wrap(text, width = 60, indent = 4, exdent = 2))
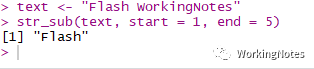
str_sub()
根据指定开始和结束位置提取字符串子集。
str_sub(string, start = 1L, end = -1L)
参数
start : 指定开始位置
end :指定结束位置
text str_sub(text, start = 1, end = 5)
参数start和end可以是向量:
str_sub(text, c(1,7), c(5, 13))

str_length()
返回字符串长度,如遇到NA,返回NA,若想遇到NA返回长度为2的话,需要使用str_replace_na()函数将NA转换成字符串NA。
str_length(c("Flash", "WorkingNotes", NA))str_length(c("Flash", "WorkingNotes", str_replace_na(NA)))

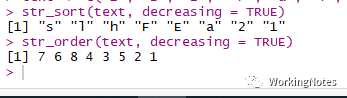
str_sort()和str_order()函数
字符串排序函数,两者的区别是str_sort()返回排序后的字符,str_order()返回排序后的索引下标。
str_order(x, decreasing = FALSE, na_last = TRUE, locale = "en", numeric = FALSE, ...)
str_sort(x, decreasing = FALSE, na_last = TRUE, locale = "en", numeric = FALSE, ...)
参数
decreasing : 排序方式,默认升序
na_last : 是否将缺失值排在最后
locale : 区域设置,一般默认是英语
text str_sort(text, decreasing = TRUE)str_order(text, decreasing = TRUE)
text str_sort(text, decreasing = TRUE, na_last = TRUE)str_sort(text, decreasing = TRUE, na_last = FALSE)

word()函数
从句子中根据位置提取单词。
word(string, start = 1L, end = start, sep = fixed(" "))
参数
start : 从第几个单词开始提取
end : 指定提取到哪个位置的单词
sep :单词之间的分隔符
text word(text, start = 1)word(text, start = 2)word(text, start = -1)word(text, start = 2, end = -1)

str_replace_na()函数
将NA转换成字符串NA,不然字符串之间操作缺失值会传染。
str_c("Flash", NA)str_c("Flash", str_replace_na(NA))

str_to_upper()、str_to_lower()、str_to_title()函数
str_to_upper()将字符串转换成大写;
str_to_lower()将字符串转换成小写;
str_to_title()将字符串首字母转换成大写;
text str_to_upper(text)str_to_lower(text)str_to_title(text)










