
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
这几天一直在用Pytorch来复现文本检测领域的CTPN论文,本文章将从数据处理、训练标签生成、神经网络搭建、损失函数设计、训练主过程编写等这几个方面来一步一步复现CTPN。CTPN算法理论可以参考这里。
https://www.cnblogs.com/skyfsm/p/9776611.html
本文项目代码 获取方式:
关注微信公众号 datayx 然后回复 CTPN 即可获取。
AI项目体验地址 https://loveai.tech
训练数据处理
我们的训练选择天池ICPR2018和MSRA_TD500两个数据集,天池ICPR的数据集为网络图像,都是一些淘宝商家上传到淘宝的一些商品介绍图像,其标签方式参考了ICDAR2015的数据标签格式,即一个文本框用4个坐标来表示,即左上、右上、右下、左下四个坐标,共八个值,记作[x1 y1 x2 y2 x3 y3 x4 y4]

天池ICPR2018数据集的风格如下,字体形态格式颜色多变,多嵌套于物体之中,识别难度大:

MSRA_TD500使微软收集的一个文本检测和识别的一个数据集,里面的图像多是街景图,背景比较复杂,但文本位置比较明显,一目了然。因为MSRA_TD500的标签格式不一样,最后一个参数表示矩形框的旋转角度。
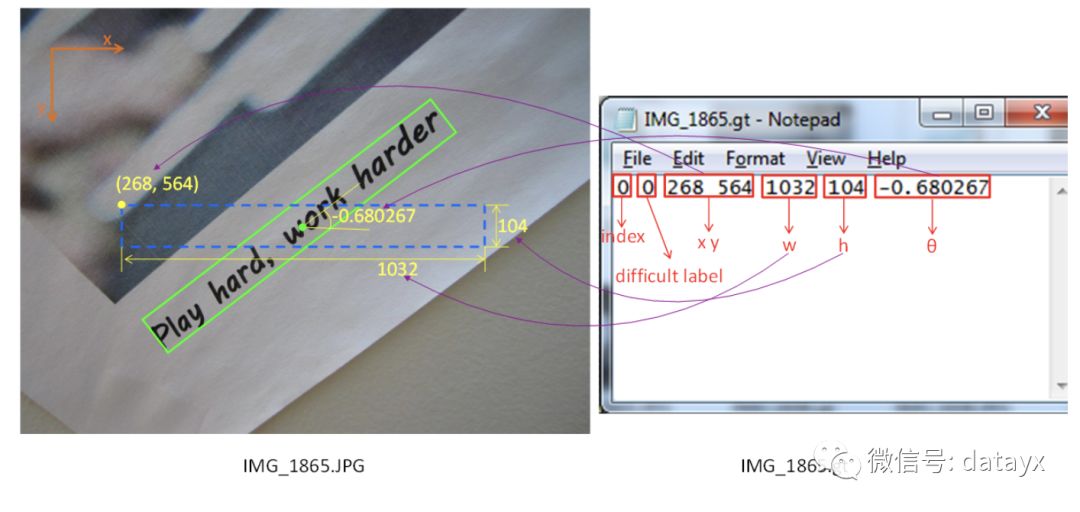
所以我们第一步就是将这两个数据集的标签格式统一,我的做法是将MSRA数据集格式改为ICDAR格式,方便后面的模型训练。因为MSRA_TD500采取的标签格式是[index difficulty_label x y w h angle],所以我们需要根据这个文本框的旋转角度来求得水平文本框旋转后的4个坐标位置。实现如下:

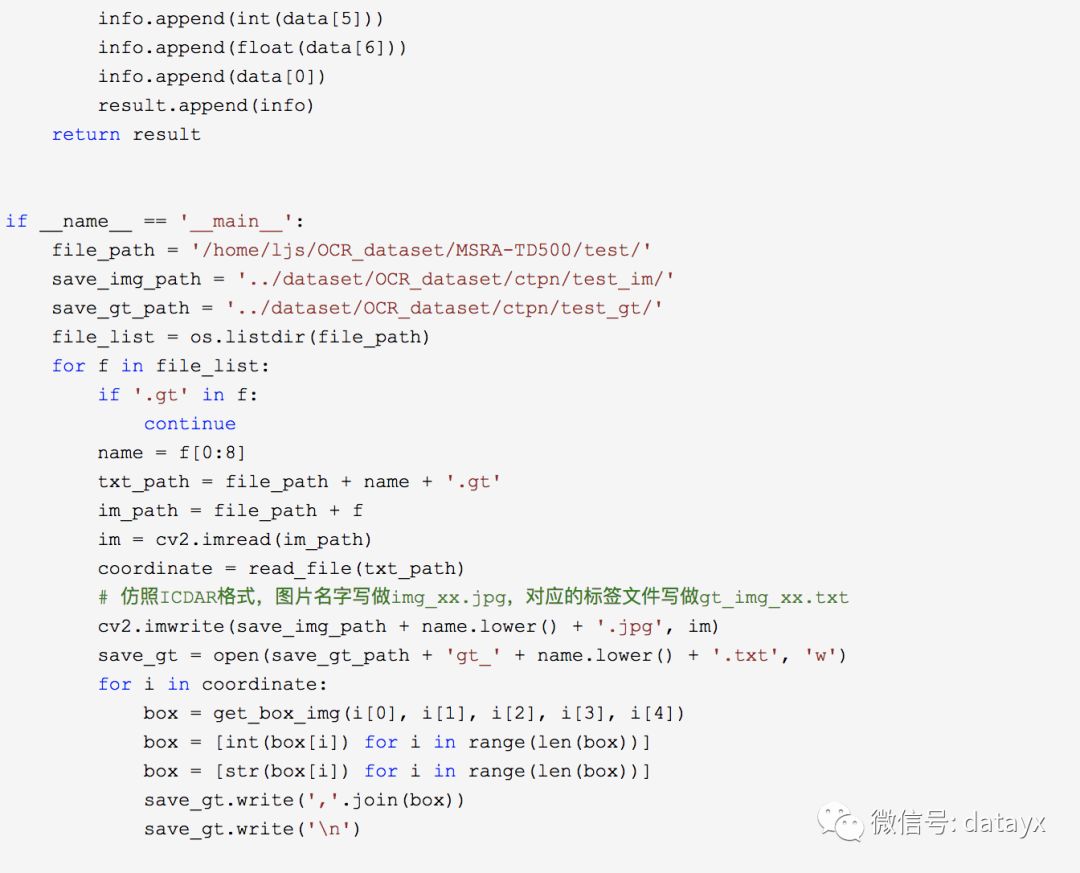
经过格式处理后,我们两份数据集算是整理好了。当然我们还需要对整个数据集划分为训练集和测试集,我的文件组织习惯如下:train_im, test_im文件夹装的是训练和测试图像,train_gt和test_gt装的是训练和测试标签。

训练标签生成
因为CTPN的核心思想也是基于Faster RCNN中的region proposal机制的,所以原始数据标签需要转化为
anchor标签。训练数据的标签的生成的代码是最难写,因为从一个完整的文本框标签转化为一个个小尺度文本框标签确实有点难度,而且这个anchor标签的生成方式也与Faster RCNN生成方式略有不同。下面讲一讲我的实现思路:
第一步我们需要将原先每张图的bbox标签转化为每个anchor标签。为了实现该功能,我们先将一张图划分为宽度为16的各个anchor。
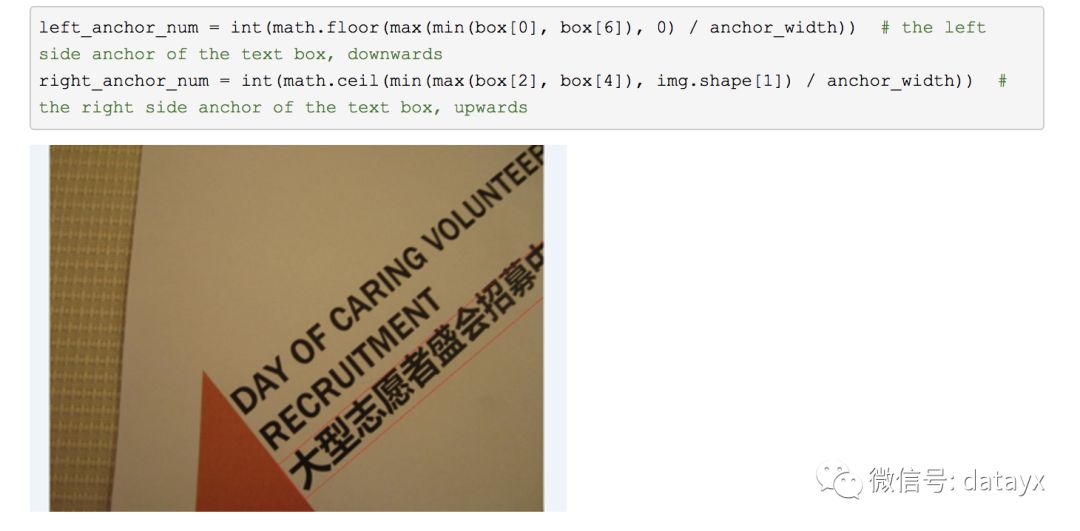
首先计算一张图可以分为多少个宽度为16的acnhor(比如一张图的宽度为w,那么水平anchor总数为w/16),再计算出我们的文本框标签中含有几个acnhor,最左和最右的anchor又是哪几个;
计算文本框内anchor的高度和中心是多少:此时我们可以在一个全黑的mask中把文本框label画上去(白色),然后从上往下和从下往上找到第一个白色像素点的位置作为该anchor的上下边界;
最后将每个anchor的位置(水平ID)、anchor中心y坐标、anchor高度存储并返回

计算anchor上下边界的方法:

经过上面的标签处理,我们已经将原先的标准的文本框标签转化为一个一个小尺度anchor标签,以下是标签转化后的效果:

以上标签可视化后看来anchor标签做得不错,但是这里需要提出的是,我发现这种anchor生成方法是不太精准的,比如一个文本框边缘像素刚好落在一个新的anchor上,那么我们就要为这个像素分配一个16像素的anchor,显然导致了文本框标签的不准确,引入了15像素的误差,这个是需要思考的。这个问题我们先不做处理,继续下面的工作。
当然转化期间我们也遇到很多奇怪的问题,比如下图这种标签都已经超出图像范围的,我们必须做相应的特殊处理,比如限定标签横坐标的最大尺寸为图像宽度。
CTPN网络结构
因为CTPN用到了CNN+双向LSTM的网络结构,所以我们分步实现CTPN架构。
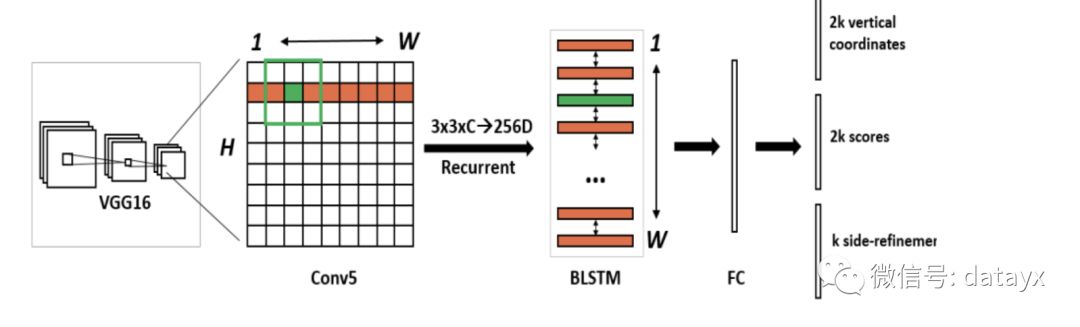
CNN部分CTPN采取了VGG16进行底层特征提取。
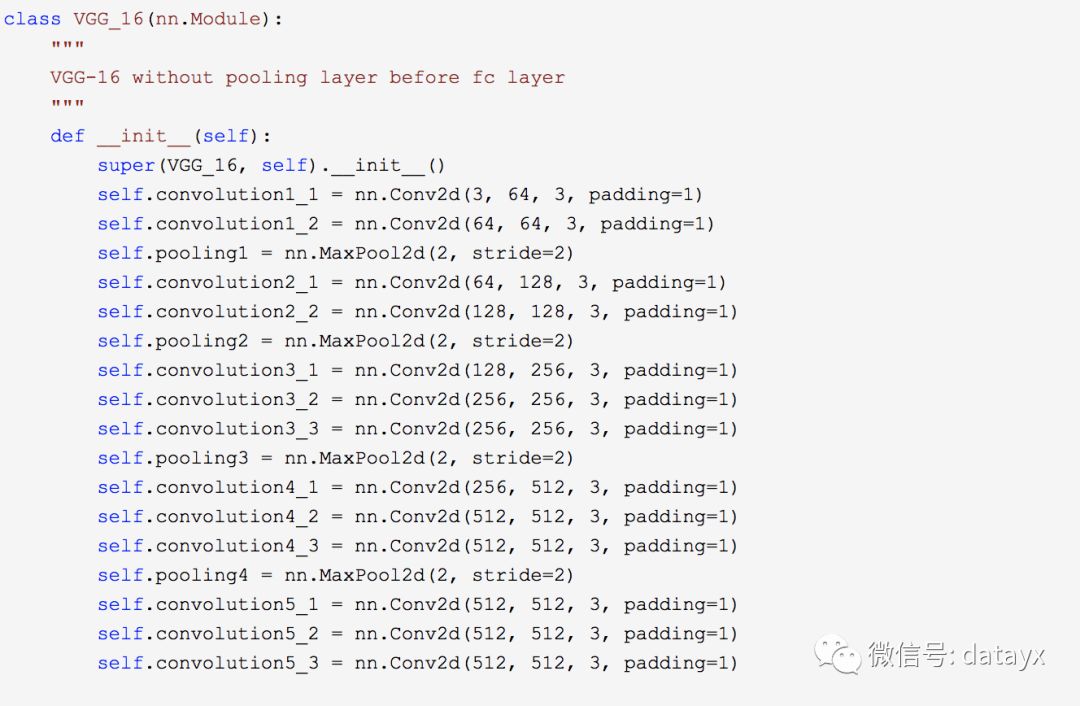
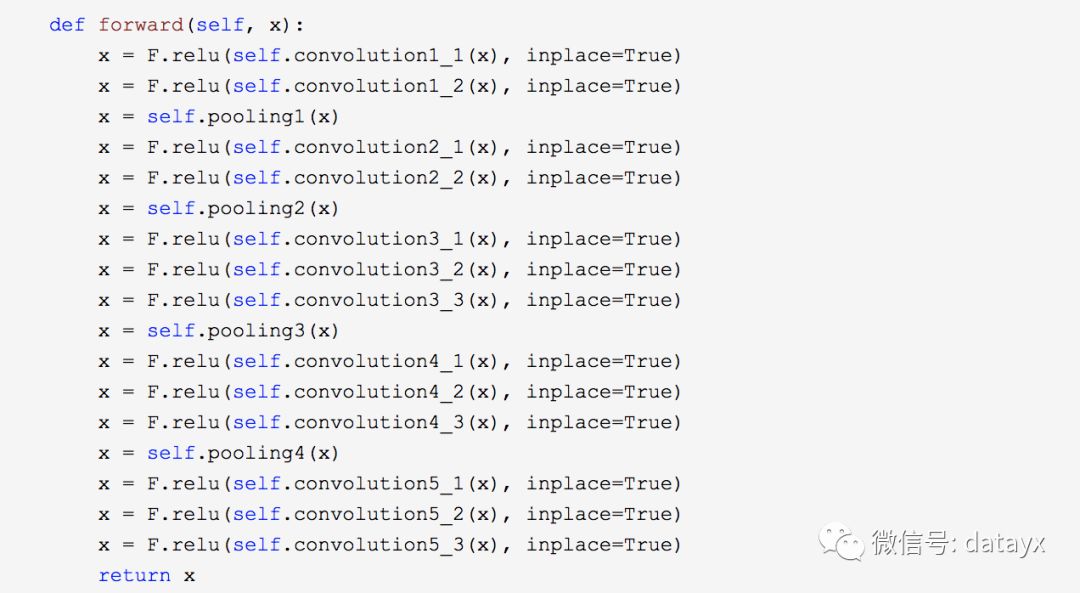
再实现双向LSTM,增强关联序列的信息学习。

这里实现多一层中间层,用于连接CNN和LSTM。将VGG最后一层卷积层输出的feature map转化为向量形式,用于接下来的LSTM训练。

最后将以上三部分拼接成一个完整的CTPN网络:底层使用VGG16做特征提取->lstm序列信息学习->output每个anchor分数,h, y, side_refinement



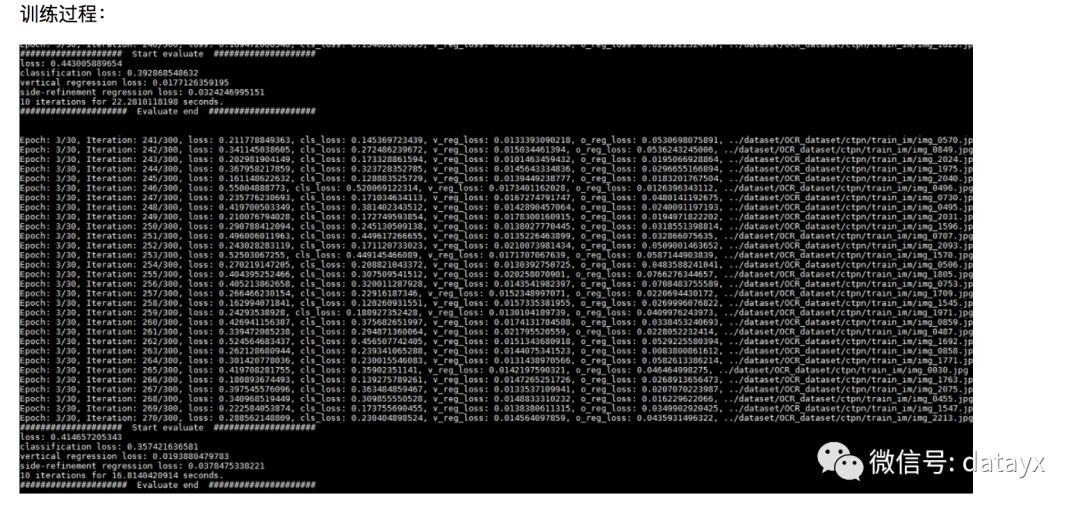
训练过程设计
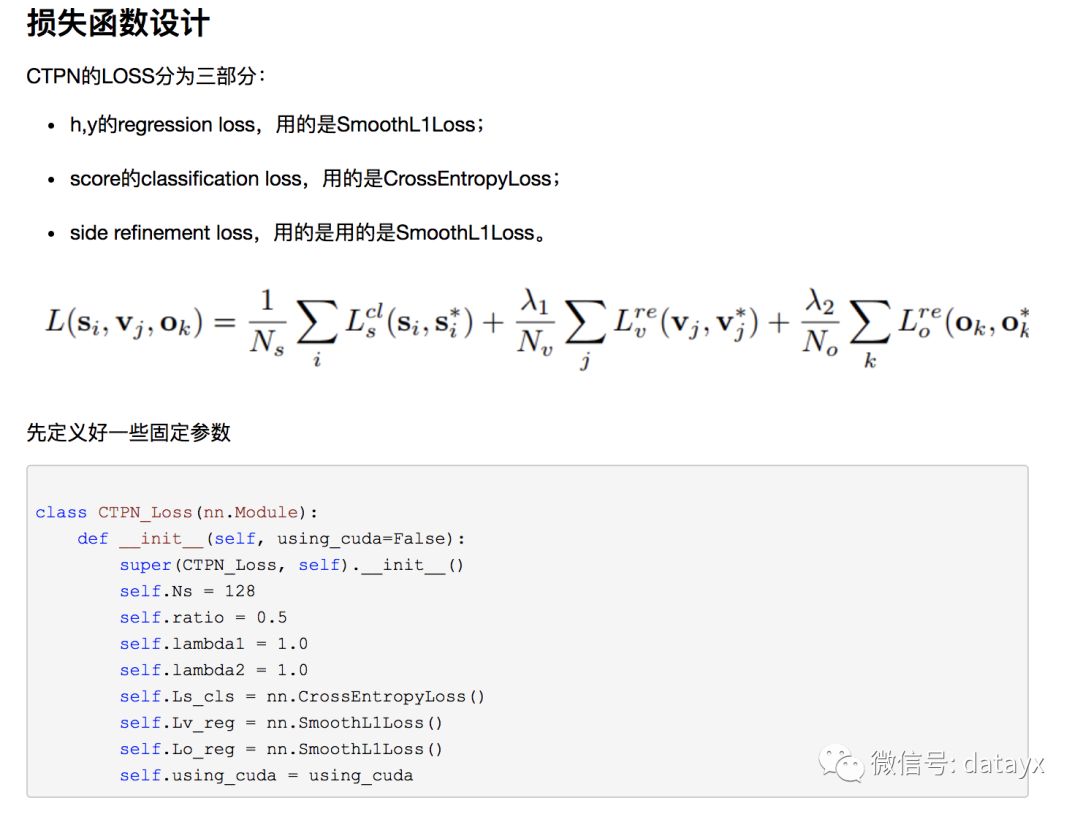
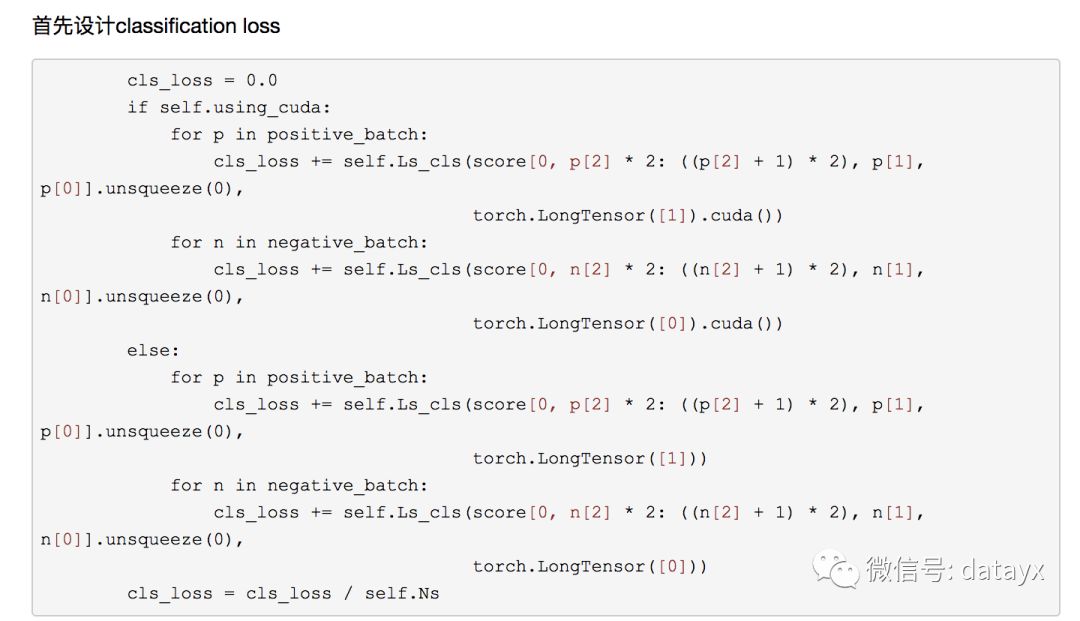
训练:优化器我们选择SGD,learning rate我们设置了两个,前N个epoch使用较大的lr,后面的epoch使用较小的lr以更好地收敛。训练过程我们定义了4个loss,分别是total_cls_loss,total_v_reg_loss, total_o_reg_loss, total_loss(前面三个loss相加)。
检测效果和总结
首先看一下训练出来的模型的文字检测效果,为了便于观察,我把anchor和最终合并好的文本框一并画出:


下面再看看一些比较好的文字检测效果吧:

在实现过程中的一些总结和想法:
CTPN对于带旋转角度的文本的检测效果不好,其实这是CTPN的算法特点决定的:一个个固定宽度的四边形是很难合并出一个准确的文本框,比如一些anchors很难组成一组,即使组成一组了也很难精确恢复成完整的精确的文本矩形框(推断阶段的缺点)。当然啦,对于水平排布的文本检测,个人认为这个算法思路还是很奏效的。
CTPN中的side-refinement其实作用不大,如果我们检测出来的文本是直接拿出识别,这个side-refinement优化的几个像素差别其实可以忽略;
CTPN的中间步骤有点多:从anchor标签的生成到中间计算loss再到最后推断的文本线生成步骤,都会引入一定的误差,这个缺点也是EAST论文中所提出的。训练的步骤越简洁,中间过程越少,精度更有保障。
CTPN的算法得出的效果可以看出,准确率低但召回率高。这种基于16像素的anchor识别感觉对于一些大的非文字图标(比如路标)误判率相当高,这是源于其anchor的宽度实在太小了,尽管使用了lstm关联周围anchor,但是我还是认为有点“一叶障目”的感觉。所以CTPN对于过大或过小的文字检测效果不会太好。
CTPN是个比较老的算法了(2016年),其思路在当年还是很创新的,但是也有很多弊端。现在提出的新方法已经基本解决了这些不足之处,比如EAST,PixelNet都是一些很优秀的新算法。
原文地址 https://www.cnblogs.com/skyfsm/p/10054386.html
阅读过本文的人还看了以下文章:
《美团机器学习实践》_美团算法团队.pdf
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
机器学习算法资源社群
不断上传电子版PDF资料
技术问题求解
QQ群号: 333972581
长按图片,识别二维码
海淘美妆












