2019 年 12 月 8 日-14 日,机器学习领域国际顶级会议 NeurIPS 于加拿大温哥华拉开帷幕,吸引了全球 1 万 3 千余名专家学者共赴盛会。本年度,自然语言处理领域在深度学习浪潮下取得了显著成就,成为大会的重要议题之一。百度也成为本届大会的重度参与者,向各国参与者展示了其最新的 NLP 技术。

本届 NeurIPS 大会共收到 6743 篇论文投稿,两年时间翻了一番。其中 1428 篇论文入选,入选率仅 21.1%。百度共有 8 篇论文被收录,覆盖量化压缩、对抗训练等诸多前沿方向。除了论文,百度在本届 NeurIPS 大会的竞赛上也有不俗的表现,在 NeurIPS 2019: Learn to Move 强化学习赛事中百度再度蝉联冠军,并受邀在 Deep RL workshop 中进行专题报告。本次比赛的难度非常大,在参赛的近 300 支队伍中,仅有 3 支队伍完成了最后挑战。百度基于飞桨的强化学习框架 PARL 不仅成功完成挑战,还大幅领先第二名(1490 vs 1346.9)。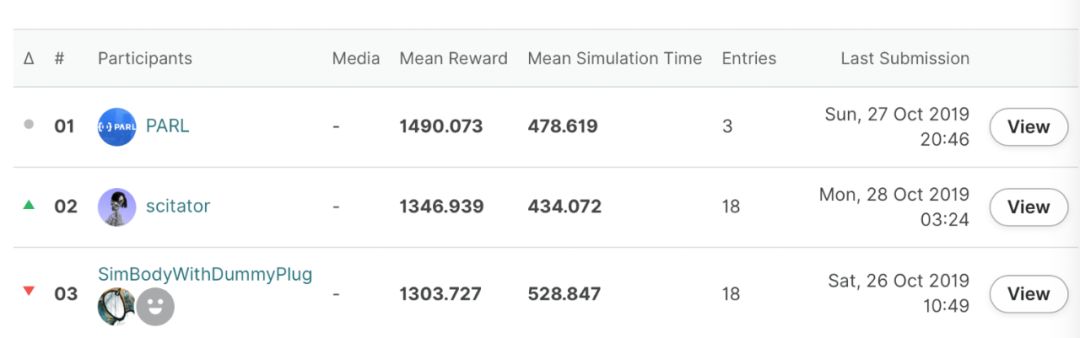
除了在 Best Performance Track 获得了第一,百度的相关技术论文也在该赛事的 Machine Learning Track 中获得了 Best Paper Reward。
ERNIE 2.0、D-NET、KT-NET、DAM 悉数亮相为了分享百度在 NLP 方向取得的最新成果,百度举办了自然语言处理专题研讨会,百度技术委员会主席、自然语言处理首席科学家吴华博士以及多名研究员和工程师,向现场参会者全面介绍了百度在这一领域的长期积累与全新突破。
基于具有完全自主知识产权的飞桨平台,百度自然语言处理在语义计算、阅读理解、多轮对话、机器翻译、开放平台与数据等方向均取得了突破性进展,并进行了大规模产业化应用。
预训练方面,12 月 10 日,百度 ERNIE 登顶自然语言处理领域权威数据集 GLUE,并以 9 个任务平均得分首次突破 90 大关刷新该榜单历史。ERNIE 今年的表现可谓惊艳,3 月,百度提出知识增强的语义表示模型 ERNIE 1.0,7 月底发布持续学习语义理解框架 ERNIE 2.0,当时在共计 16 个中英文任务上超越 BERT、XLNET,取得了 SOTA 的效果。11 月,百度发布基于 ERNIE 的语义理解开发套件。从原理、应用到开源及平台化,百度在 NLP 预训练领域进行了极具价值的创新及实践。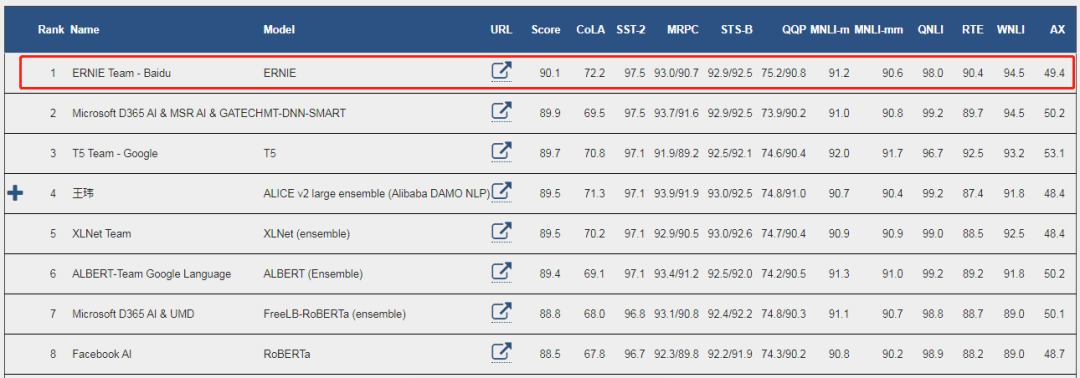
机器阅读理解已成为评估机器语言理解能力的重要方式,也是搜索引擎和对话系统等行业应用中的关键技术。百度建设及发布了最大规模的中文阅读理解数据集 DuReader;在泛化方面提出训练框架 D-NET,从多模型融合、多任务学习的角度提升模型的泛化能力。对于对抗样本的攻击,百度提出了一种面向阅读理解的对抗训练方法;提出文本表示和知识表示的融合模型 KT-NET,以解决需要外部知识和常识的问题。其中具有高鲁棒性和迁移能力的阅读理解模型在今年 MRQA 阅读理解评测中夺得冠军。对话方面,百度提出了基于深度注意网络的多轮响应选择匹配模型 DAM(Deep Attention Matching Network),显著提高了口语理解能力。在对话系统框架中,百度一方面提供了可编程的对话管理框架,并内置了多个常用标准对话范式,为在云端开发灵活可变的业务对话逻辑提供了便利。另一方面,百度提供了需求分发和全局记忆机制,支持多个对话任务的集成与联动,提高了对话技能的可复用性,降低了新业务的重复开发成本。百度可定制对话技术依托百度大脑 UNIT 3.0 平台,支持 5 万多个对话技能,广泛应用于行业客户。

在机器翻译领域,百度相继提出了多任务学习、多智能体联合训练等前沿方法,并在 2019 年国际权威 WMT 评测中取得中英翻译第一。在机器同声传译方面,百度走在领域前沿,提出了首个具有预测和可控时延的同传模型、首个语义单元驱动的上下文同传模型,并研发了业内首个语音到语音的同传系统,为用户提供高质量、低时延的同传体验。值得一提的是,基于在此领域取得的进步,百度将联合 Google、Facebook、Upenn、清华等海内外顶尖企业及高校共同组织首届机器同传研讨会,在本领域顶级会议 ACL 2020 召开,并将举办国际首届同传评测,以进一步促进技术发展。此外,百度还将在领域权威会议 EMNLP 2020 中举办机器同传 tutorial,就机器同传的原理、方法、前沿进展进行讲座。
百度自然语言处理领域产出的卓越成果背后所运用的底层框架,是自研的开源深度学习平台百度飞桨。近两年来,飞桨围绕深度学习框架的基本功能、性能、芯片支持的完备性等技术指标进行了一系列的易用性开发和性能迭代,为开发者提供了优于其他深度学习框架的使用体验。在开发能力方面,飞桨除了支持对常用 API 的调用之外,还在编程范式上同时支持声明式编程和命令式编程,兼具很好的灵活性和稳定性,可满足不同开发者的开发习惯,更易上手。在训练方面,飞桨平台突破了超大规模深度学习模型训练技术,研制了千亿特征、万亿参数、数百节点的开源大规模训练平台,实现了万亿规模参数深度学习模型的实时更新。在上述能力强化的基础上,飞桨官方支持 100 多个经过长期产业实践打磨的主流模型,其中包括在国际竞赛中夺得冠军的模型,同时开源开放 200 多个预训练模型,以助力快速产业应用。

除了密集的学术交流讨论、报告之外,NeurIPS 2019 的百度展台也吸引了世界各地的参会者。深度学习平台飞桨获得广泛关注,众多参会者到展台咨询使用及合作事宜;百度 AI 同传吸引了来自美国、俄罗斯、日本、加拿大等世界各国的参与者们纷纷体验。

从专题研讨、论文分享、竞赛报告到多样的现场系统演示,百度在今年的 NeurIPS 2019 上深度参与,全面展现了百度的前沿技术进展。以百度为代表的中国 AI 企业的频频身影,已成为国际人工智能学术顶会中的「新常态」。
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:机器之心








