为解决大规模数据集合多重数据种类带来的挑战,NoSQL 应运而生,但现在却也遇到了诸多问题,本文作者 Rick Negrin,曾在微软工作 12 年,并在 SQL Server 团队度过大部分光阴,他提出,是时候「和 NoSQL 说再见」了!

以下为译文:
是时候承认我们早就知道的事实了:NoSQL 并不适合现代应用程序,我们该对它说再见了。
由于数据超过了数据库能够处理的规模,NoSQL 技术就应运而生。这种新型的数据服务的兴起解决了十年前它出现时网络和数据快速增长的问题。NoSQL 还提供了冷存储或批量访问 PB 级数据的低成本的新途径。然而,由于急于解决大数据和高并发的挑战,NoSQL 放弃了数据库的一些高性能和简单易用的核心特性。
对大数据和高并发与高性能和易用性做出的权衡是 NoSQL 在数据库领域做出的最大贡献。将大数据和成熟的关系型结构和灵活性结合到一起,从而产生了一个可伸缩的关系数据库,造就了一场变革。
关系型数据库的发展创造了一个全新的系统,可以处理几乎所有的任务,具有现代应用程序所需的可伸缩性、可靠性和可用性要求。随着从传统的工作任务(例如事务处理应用程序和业务分析)到更新的工作任务(例如多租户服务和运营分析)的转变,一些新兴的数据库如 Google Spanner、Azure 数据仓库和 MemSQL 开始出现,证明了大多数情况下,关系型数据库比 NoSQL 更容易使用且表现通常也更好一些。
我知道上述言论可能引起争议。我也知道你可能会认为我的观点富有偏见。但是请让我介绍一下数据库的历史、架构和应用程序的相关知识,你再做出自己的判断也不迟。

NoSQL 的崛起
尽管 NoSQL 在更早的时候就已经开始了,然而,直到在 21 世纪 10 年代中后期才全面发挥作用。它的出现主要是为了解决现有数据库系统的规模问题。很明显,对于构造大型系统来说,能够横向拓展更划算。对于 Google、Facebook、微软和雅虎等最大的电子邮件和搜索系统来说,这是唯一的扩展方式。
2007 年,当我阅读詹姆斯·汉密尔顿 (James Hamilton) 关于设计和部署大规模互联网服务的论文时[1]
,我第一次懂得了扩展的价值。首先因为应用层无状态的系统拓展起来更容易。拓展存储层则不同。根据定义,数据库是有状态的,在分布式系统中维护状态(ACID)非常困难。存储层通常是基于现存的数据库系统(如 MsSQL、SQL Server 等)来构造分布式存储系统的。
当我在微软的 SQL Server 团队担任产品经理时,我碰到了下面几个例子。第一个例子发生在微软内部,微软在内部建立了 Webstore,它是 Hotmail 和相关服务使用的 SQL Server 之上的一个分片层。事实上,Webstore 是现在 Azure SQL 数据库的前身。虽然 Webstore 很笨重,缺少很多核心功能,但是它很有效,并且给微软提供了一种扩展到所需数据规模和实现高可用性的能力。但 Webstore 需要整个工程师团队来构建和维护。
在 21 世纪 10 年代中期, MySpace 使用大量的 SQL Server 服务器来管理快速增长的数据。由于该公司的用户增长非常快,导致该公司每天都要增加新的 SQL Server 机器。运行这些 SQL Server 服务器并且支持跨服务器查询的工作非常复杂,需要大量的工程师来维护。
同样的情况也出现在 Facebook 或其他企业的身上,因为所有新兴科技巨头都在不断扩大规模,所以都面临着相似的问题。
很明显,随着数据大规模的使用和增长,就需要新的数据解决方案来获取、管理和查询数据。理想情况下,我们需要一个可以提供接口并且可以通过加机器实现拓展性的工具。
最终,大规模的云服务(Google、 Facebook、雅虎、微软等) 都建立了自己定制的系统来满足这种数据需求。虽然这些系统各不相同,但是他们的思想都是通过直接的方式或者学术手段间接共享的。最终,开源系统开始借鉴这些思路,NoSQL 因此应运而生。
为了解决网络规模问题,NoSQL 在一些关键方面和传统的数据库相背离。接下来让我们看看它为什么要这么做。

最终一致性的表现和风险
ACID 代表原子性(Atomic)、一致性( Consistent)、隔离性(Isolation)和持久性(Durable)。它涵盖了大多数关系型数据库的保证。ACID 保证了写操作必须等数据落盘后才能给客户端返回成功。另外,如果很在意持久性(即不丢失数据),那么可以将数据库配置为等待,直到写操作通过网路传输到其他机器,并且待对方落盘为止。这就保证了写数据的正确性但是降低了写数据的性能。
BASE 是 NoSQL 系统的典型特征,即基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent)。因为程序不需要确认数据持久化完成,因此最终一致性写的性能更高。一旦数据存储设备接收到了一个写操作,它就可以在持久化或送达其他机器之前告知应用程序此次写操作已经成功,应用程序就可以执行下一个操作。虽然你获得了写性能的提高,但却冒着看不到刚才写入的数据和异常条件下数据可能完全丢失的风险。
最终一致性是持久化风险和可用性之间的合理权衡。如果你的业务是消费者参与,而延迟对你的收入有直接的影响 (对于所有的内容、社区和商业应用程序都是如此) ,那么你追求的是更快的响应速度。如果你必须要支持数百万计的用户并发,那么你就不能容忍任何瓶颈。如果偶尔丢失某人的帖子或评论这种风险是可以接受的话,就适合采用最终一致性的方案。
持久性与风险之间的另一面是金融应用程序。您不希望银行使用最终的一致性来存储 ATM 交易或股票销售的结果。在这些情况下,您仍然让用户要求很少甚至没有等待时间,但是不愿意接受未写入磁盘的事务。
最终一致性占有一席之地,但是它不是唯一的解决方案。数据系统的架构师和开发人员应该根据实际需要选择他们想要的一致性级别。这种选择应该在用例级别而不应该在平台级别进行。

无模式化
目前还不清楚为什么在 NoSQL 运动中丢失了模式。早期很难构造一个分布式元数据管理器来维护跨分布式系统的模式来操作,比如添加一列。因此,在早期设计中没有使用模式也不足为奇。但是,模式没有找到添加它的理由,被简单地删除掉了。很多人认为模式并没有那么敏捷。好的模式设计非常困难,需要仔细斟酌。当事物快速发生变化时,你不希望被模式所束缚。
但这是一个谬论。
的确,缺乏模式增加了工程师开发的敏捷性。然而,它把这个问题推给了数据的读者,这些读者的数量通常更多,而且在写数据时往往不知道数据的状态。这些用户通常需要重数据中挖掘价值,因此应该尽可能少地设置障碍。
打个比方,想象一下图书馆说他们正在废除杜威十进制图书分类法,只是把书扔到地上的一个大洞里,并宣称这是一个更好的系统,因为它对图书管理员来说工作量更少。对于半结构化数据有时间和地点属性,因为有时你事先并不知道某些数据结构,或者它是否稀疏。但是,如果你不知道即将到来的数据的任何特征,那么有啥用呢?
事实上,模式总是存在的。这些数据对某些人来说总是有意义的。有些人应该花时间将知识编码到一个平台上,以便下一个人可以学习使用。如果这些数据是不易理解和快速变化数据的混合体,那么可以将易变的部分放到数据库的半结构化的列中,然后确定以后可以映射到哪些列。15 年前 SQL Server 和 Oracle 就可以通过 XML 实现这个功能。其他现代数据库也可以通过 JSON 数据来实现这种功能。文档数据(键/值对)存储是现代数据库的一个特征,而不是唯一功能。

查询的非 SQL 语法
在 NoSQL 数据库设计中的这一决定遵循了无模式的原则。如果没有模式,那么抛弃 SQL 语法更合理。此外,很难为单个机器构建查询处理器,而构建分布式处理器则更难。最值得注意的是,如果你是一个开发者,想让一个新的应用程序启动并运行,基于 NoSQL 来构建系统会更容易。
MongoDB 在简化安装步骤和首次体验方面做得非常完善。但事实证明,关系模型是非常强大的。如果想实现“获取 id 为 2 的对象”这种功能,直接用 get 和 put 函数即可。但是大多数应用所需的并不止如此。如果你想学习一个使用 MongoDB 做了两个项目的人的感悟,可以看看这篇文章。这篇文章解释了文档数据库的不足[2]。
你总是希望以不同于存储数据的方式来查询数据。讽刺的是,为了解决这个问题,关系模型在 20 世纪 60 年代就被发明出来。一个具有连接功能的关系型数据库是获取数据的唯一方式。一开始比较困难,但总好于将所有的数据都加载到应用程序中自己去建立关联。但我却反复看到顾客一次一次在 NoSQL 中这么做,结果可想而知。
很多 NoSQL 系统实现了它们的目标。它们提供了具有统一接口的数据存储,这些接口可以拓展到很多机器上实现高可用。虽然已经取得了诸多成功,但是 NoSQL 还是遇到了一些阻碍。
原因有很多。性能是其中一个关键因素,特别是在对任意类型的服务等级协议(SLA)进行分析查询时。可治理性是另外一个原因,因为分布式系统本身就出名地难以治理。但是 NoSQL 的最大阻碍是需要对人员的重新培训。在过去的 10 年里,NoSQL 一直在试图改变世界,但是收效甚微。NoSQL 公司的只占 500 亿美元数据库市场份额的一小部分。
虽然软件工程师似乎很喜欢 NoSQL,但数据人员(DBA、数据架构师和数据分析师)却与之相反。因为这就意味着他们必须重新学习新的 API、工具和生态,意味着要抛弃多年来成功的方法、模式和经验。他们希望使用经过验证的模型来做事情,但是仍然可以在不妨害系统持久性、可用性和可靠性的情况下扩大规模。

从 NoSQL 到 NewSQL ——性能和规模无需妥协
当选择使用 MemSQL 时,首先我们假定用户喜欢关系型数据库的功能,却又想要拓展系统的可用性和可靠性。我们目标是两全其美。
MemSQL 是一个分布式的关系型数据库,支持交易和分析,并且支持硬件上的拓展。在 MemSQL 中,你可以看到熟悉的关系模型、SQL 查询语法和庞大的工具生态系统。它支持可拓展性和可用性的现代、云原生的系统。
让我们结合 NoSQL 系统的核心差异来重新审视这一点。

一致性和性能的平衡
MemSQL 提供了有一些“旋钮”,可以在一致性和性能之间进行权衡。权衡不可避免,但是你不必在平台级别对一致性和性能进行权衡,可以在用例级别对两者进行选择。
一致性和性能的选择并不是一个哲学问题,而是要根据应用的实际情况和需求进行选择。MemSQL 有两个设置可以让你调整。第一个是让你决定是否要等待磁盘持久化。在事务被持久化到磁盘之前会存储到内存的缓冲区中。你可以在成功访问缓冲区或磁盘后立即返回数据。如果在到达缓冲区就返回,可能会在持久化之前机器发生故障或者重启,那么数据就会丢失。另外一方面,如果等待数据持久化到磁盘就会耗费更多的时间。
此外,MemSQL 提供两种复制模式来实现高可用,分别是同步复制和异步复制。通过复制确保一个机器上的数据在另外一台机器上有副本。如果将复制设置为同步模式,则需要等到备份服务器上接收到事务后,才能将成功返回给客户端。如果打开了异步复制模式,则在将数据复制到备份服务器之前,事务将返回成功。这为你提供了在一致性和性能之间进行权衡的机会。
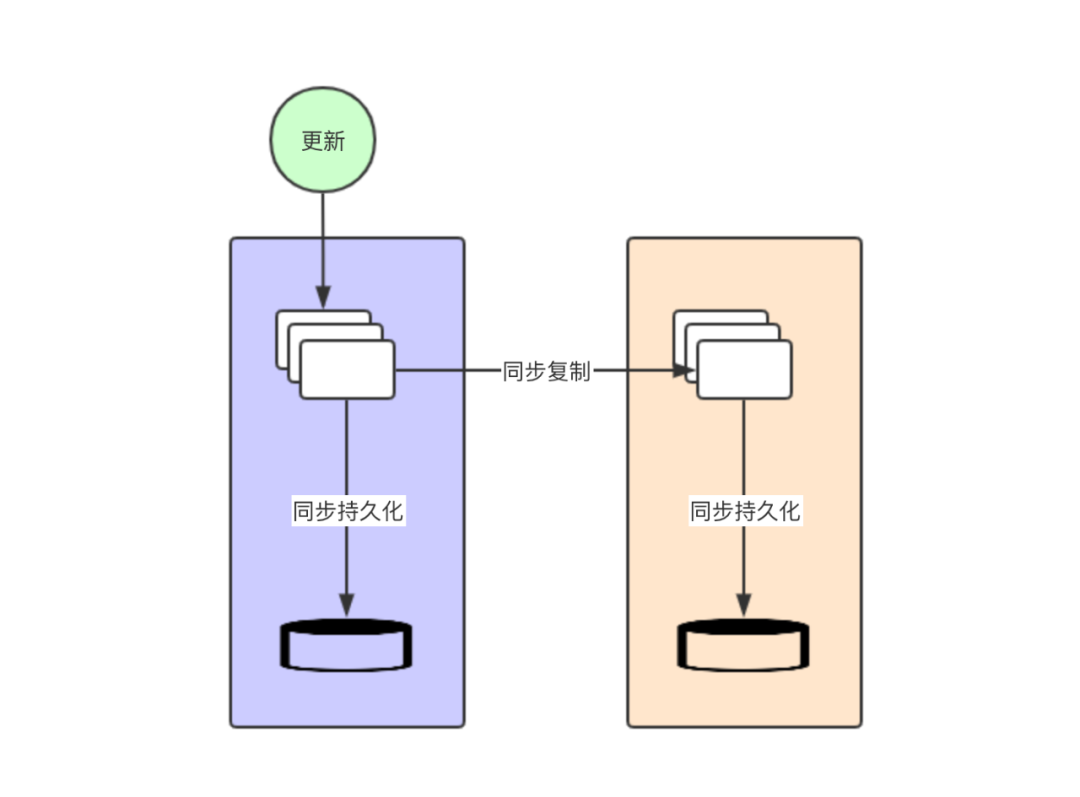
图:MemSQL 7.0 快速同步复制和同步持久化

分布式系统中模式的维护
MemSQL 通过在小型内部数据库中存储元数据,并在所有节点发生更改时同步复制元数据来实现模式。它使用两阶段提交来确保 DDL 更改可以正确地在集群中传播,以一种不会导致查询阻塞的方式实现。
MemSQL 不仅仅支持关系模型。您可以输入一个 JSON 列,并在其中存储到一个 JSON 文档。如果你以后要查询某一列,可以将该属性映射为列并对其进行索引。MemSQL 还支持空间类型和全文索引。客户需要在一个熟悉的系统中混合使用各种数据类型,并且所有类型的数据可以自然地共存。

保留 SQL“通用语言”
已经解决了在分布式数据库中大规模使用 SQL 语法的问题。分布式查询处理器允许您使用标准 SQL 语法表达查询,系统负责将查询任务分配到集群中的各个节点,并帮你汇总结果。MemSQL 支持所有常见的 ANSI SQL 操作符和函数。
MemSQL 通过系统中两种类型的节点实现这种功能,汇聚器和叶子节点。聚合器处理分布式系统的元数据、路由查询和聚合结果。叶子存储数据,并在分区上执行繁重的查询。如果可能 MemSQL 将在本地执行连接,这也说明了模式设计的重要性。如果不能,MemSQL 将根据需要对数据进行重组。因此,客户可以在不知道数据是如何分区的情况下使用 SQL 语言。
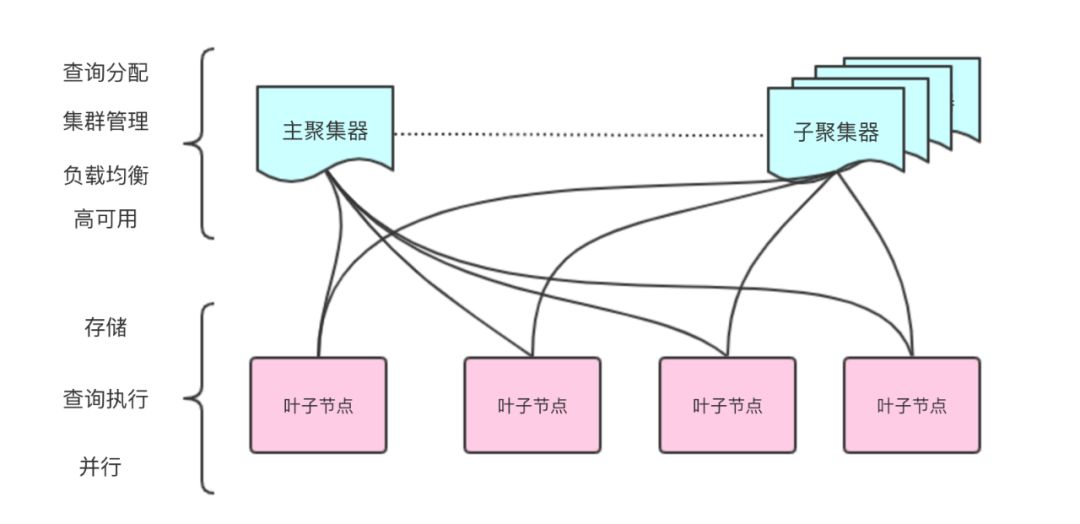
图:MemSQL 在聚集器和叶子节点分发数据
这意味着你可以利用你公司已有的技能、投资和工具使用 MemSQL。人们可以像使用其他关系数据库一样使用 MemSQL,而不需要再接受额外培训。此外,由于 MemSQL 支持 MySQL 有线协议,现有的大规模商业智能(BI)、 ETL(数据抽取、转换和加载) 和其他中间件工具都能与 MemSQL 一起协作。你不需要雇佣新的员工,学习一堆新的工具,或者引进新的软件。只管用就可以了。

向 NoSQL 说再见!
NoSQL 的出现是为了满足 Web 应用和多租户服务的规模需求。想想解决这些问题的难度,就能理解为何早期他们在存储层进行拓展时为何要迫使用户进行艰难地权衡了。
但是关系型数据库也已经有了长足的发展。它们可以处理几乎所有的工作负载,可以满足现代应用程序所需的可伸缩性、可靠性和可用性要求。
工作负载包含操作分析。当所有的公司意识到数据驱动的价值时,他们希望所有的员工都能获得最新的数据。要做到这一点,需要一种新型的分析系统,它可以扩展到数百个并发查询,不需要预先聚合就可以交付快速查询,并且在创建数据时就可以提取数据。最重要的是,他们希望向客户和合作伙伴公开数据,这需要一个可操作的服务等级协议(SLA)、安全性能、性能和规模,而目前的数据存储是不可能的。这只是其中一个特性,实现了遗留数据库和 NoSQL 系统所不能提供的新功能的需求。
关系模型经受住了时间的考验,而且它还在不断创新,比如 MemSQL SingleStore。此外,它还吸收了新的数据类型 (搜索、空间、半结构化等) 和一致性模型,使它们能够在一个系统中共存。关系模型或 SQL 查询语法没有固有的可伸缩性挑战。它只需要一个不同的存储实现即可利用横向扩展架构。
新的数据库如 MemSQL 已经证明,对于大多数用例来说,关系数据库更容易使用,并且通常比 NoSQL 系统执行得更好。
谢谢 NoSQL,是你对数据库社区施加了压力,迫使其解决云规模世界的各种挑战。这招很管用。然而,关系型数据库已经发展到可以满足这些需求的地步,接下来交给我们吧。
[1] https://www.usenix.org/legacy/event/lisa07/tech/full_papers/hamilton/hamilton_html/index.html
[2] http://www.sarahmei.com/blog/2013/11/11/why-you-should-never-use-mongodb/
英文:Thank You for Your Help NoSQL, but We Got It from Here
链接:https://www.memsql.com/blog/why-nosql-databases-wrong-tool-for-modern-application/
作者简介:Rick Negrin。Rick 负责 MemSQL 的产品管理团队,在微软工作了 12 年,大部分时间在 SQL Server 团队工作。
译者:明明如月,知名互联网公司 Java 高级开发工程师,CSDN 博客专家。
VS Code · 编程开发 · 业界资讯











