
文章作者:梦想做个翟老师
编辑整理:Hoh
内容来源:作者授权
出品平台:DataFunTalk
注:转载请联系作者本人。
导读:Attention 机制已广泛运用于图像、NLP、强化学习等领域。比如最早有 Attention 机制的 Image Caption 模型、seq2seq 模型,如今有大火的 transformer、bert 等,这些模型都用到了 Attention 机制。自然而然地,推荐模型也会应用 Attention 机制去增强模型的表达能力。其实几乎所有的 Attention 方法都可以归纳为:给定很多组 key 和 value,以及一个目标向量 query,通过计算 query 与每一组 key 的相似性,得到每个 key 的权重系数,然后通过对 value 进行加权求和,得到最终的 Attention 数值。本文将对 Attention 机制在深度学习推荐模型中的各种应用进行简单的整理。如有不对的地方,还请大家指正。
1. AFM:Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
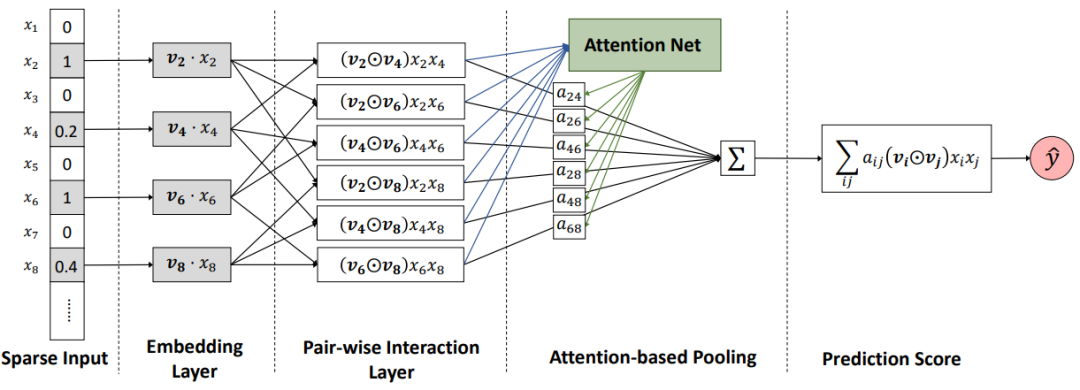
模型如上图所示,其中 sparse iput,embedding layer,pair-wise interaction layer 都和 FM 一样,后面加入了一个 attention net 生成一个关于特征交叉项的权重,将 FM 原来的二次项累加变成加权累加。这里的 attention net 其实很简单,就是简单的线性变换求出权重之后再和原来的输入进行加权求和。
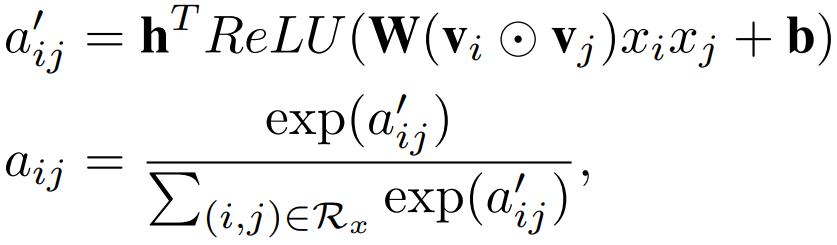
然后加权计算得到 AFM 的输出:
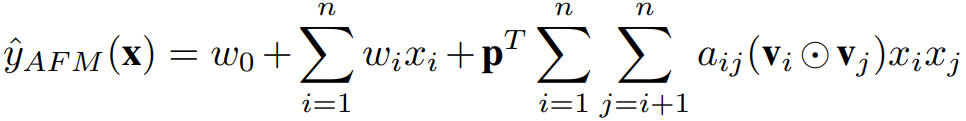
缺点:AFM 只是在 FM 的基础上添加了 attention 的机制,但实际上只利用了加权的二次项,并没有加入更深的网络去学习更高阶的非线性交叉特征,所以它的上限和 FFM 很接近,没有完全发挥出 dnn 的优势。
2. 阿里 DIN:Deep Interest Network for Click-Through Rate Prediction
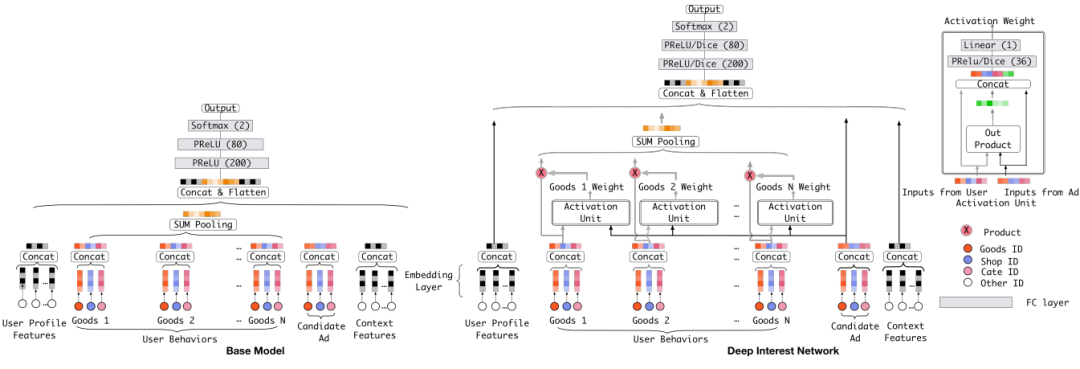
用户的历史行为数据是有多个的,在计算新的候选商品的 ctr 时,可以将用户多个历史行为的 embedding 加个 average pooling 平均一下,但是这样没有办法建模出不同历史行为对目标预测的影响程度。DIN 中加入了一种 Attention 机制来使得模型对用户相关的行为历史看重一些,对不相关的历史甚至可以忽略的效果。
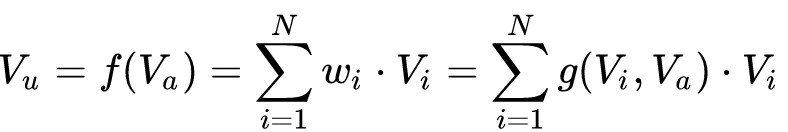
上式中,Vu 是用户的 embedding 向量,Va 是候选广告商品的 embedding 向量,Vi 是用户 u 的第 i 次行为的 embedding 向量,因为这里用户的行为就是浏览商品或店铺,所以行为的 embedding 的向量就是那次浏览的商品或店铺的 embedding 向量。Vu 从过去 Vi 的加和变成了 Vi 的加权和,Vi 的权重 wi 就由 Vi 与 Va 的关系决定,也就是上式中的 g(Vi,Va)。
那么怎么计算 g 呢,传统的做法可以直接将用户 embedding u 和候选商品 embedding v 做点积或者 uWv。DIN 的做法是将 u、v 和两者之间的差值这三个向量合并起来作为输入,输入到 mlp 中得到权重。
3. 阿里 DIEN:Deep Interest Evolution Network
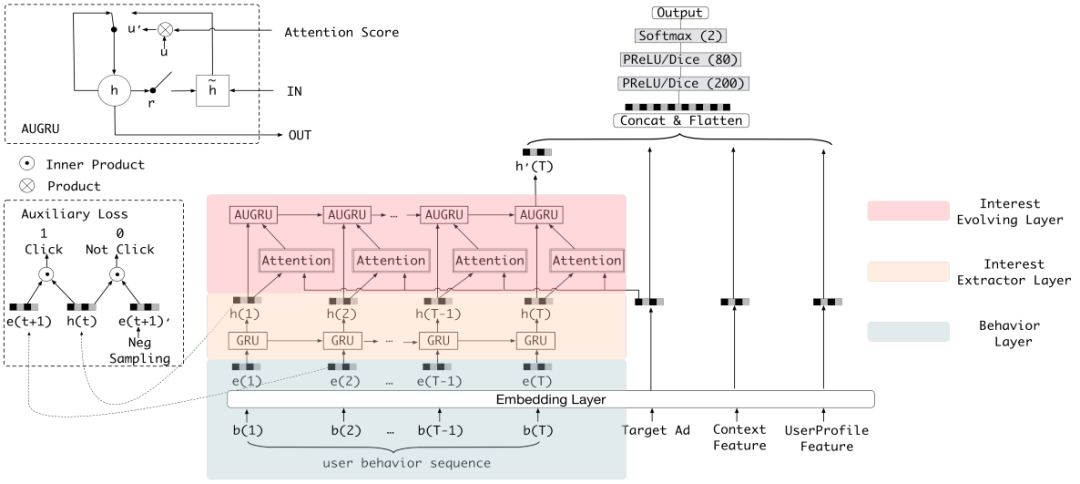
DIEN 先用 GRU 从用户的行为序列中去抽取兴趣,然后通过带 attention 的 GRU 单元来寻找与目标 item 相关的兴趣点。其中 attention 计算方式为:
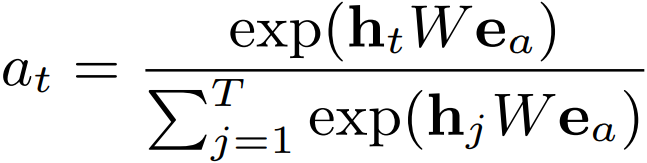
其中 ea 表示一个目标 item 中不同 field 特征的 embedding 向量的 concat,可以看到这里的 attention 是一种很传统的 u*W*v 的方式,然后将求得的 attention 权重结合 GRU 一起使用。
4. 阿里 DSIN:Deep Session Interest Network for Click-Through Rate Prediction
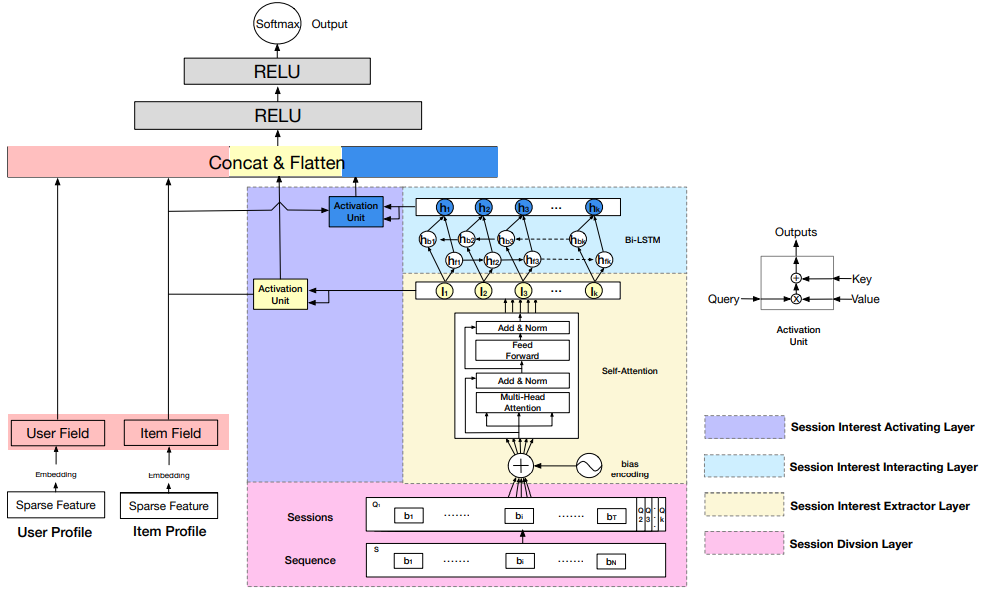
有三处用到了 attention 的结构,首先在 Session Interest Extractor Layer 中,使用了 transformer 来处理每个 session,得到一个 d 维的向量。多个 session 的 d 维向量经过双向 LSTM 得到隐层状态 ht。
另外两处用到 attention 的地方在 Session Interest Activating Layer 中,使用了和 DIEN 中一样的 attention 结构来刻画用户的会话兴趣与目标物品的相关性、LSTM 得到隐层状态 ht 与目标物品的相关性。

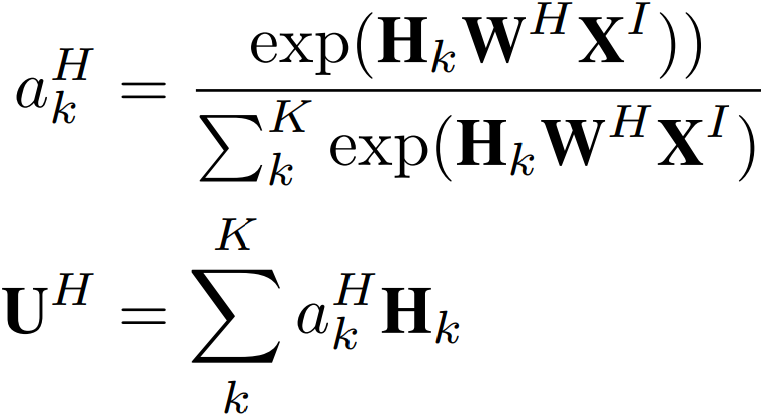
最后把四部分向量:用户特征向量、待推荐物品向量、会话兴趣加权向量 UI、带上下文信息的会话兴趣加权向量 UH 进行 concat,输入到全连接层中,得到输出。
5. 阿里:Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
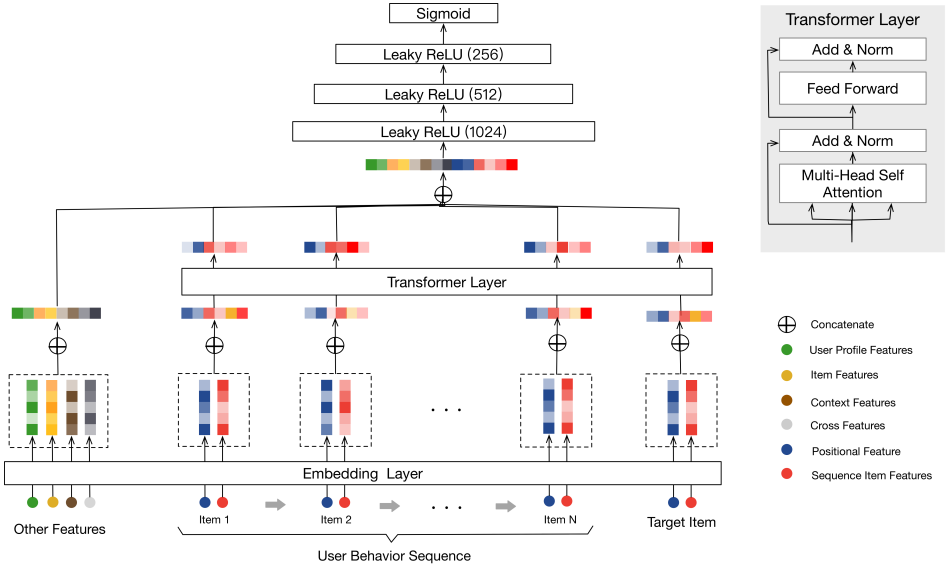
将用户的行为序列先通过 embedding 层处理,然后经过了一个 Transformer 层。
6. 阿里:Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction
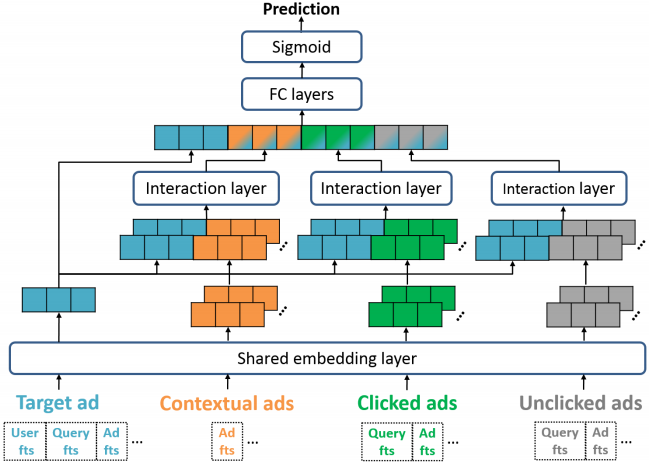
输入包括目标广告的信息、上下文广告信息、点击广告信息、曝光未点击广告信息,经过 embedding 层,然后有两种 attention 方式,第一种是 self-attention 方式:
其实就是比如上下文的 embedding 表示 xci 输入到一个函数 f 中,得到标量输出 βci,然后通过 softmax 将每个上下文 item 的权重归一化到0-1之间,随后基于权重进行加权求和。缺点就是没有考虑 target ad 的信息。
另外一种 attention 方式是交互式的,并且加入了目标广告的信息 xt:
7. ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation
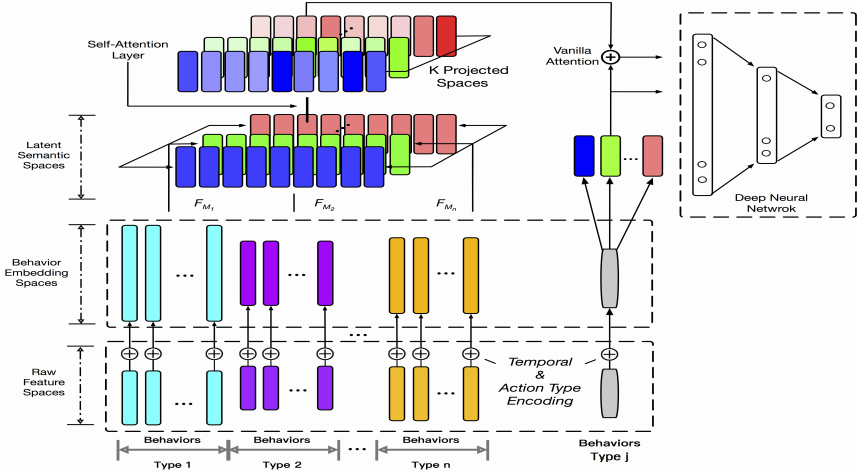
分为原始特征空间 ( raw feature spaces )、行为嵌入空间 ( behavior embedding spaces )、隐语义空间 ( latent semantic spaces )、行为交互层 ( behavior interaction layers )、下游网络层 ( downstream application network )。
模型中用到 attention 的地方在 latent semantic spaces 层后面,latent semantic spaces 层的目的是将每个行为组中的向量通过线性变换到多个不同的语义空间,然后采用 self-attention 结构:
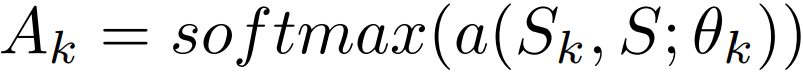
其中 S 是整个语义层拼接后的输出,Sk 是第 k 个语义空间上的投影。
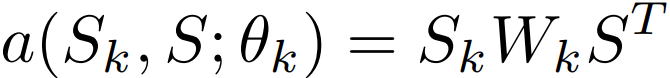
经过 self-attention 后,第 k 个语义空间的向量表示为:
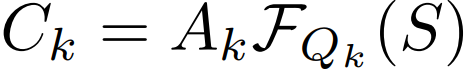
 是将 S 映射到第 k 个语义空间的另一个转换函数,文中用了一层的 MLP。
是将 S 映射到第 k 个语义空间的另一个转换函数,文中用了一层的 MLP。
总结:可以看出深度学习推荐模型中,使用的 attention 可以分为两大类,一类是 self-attention ( 比如 ATRank ),一类是传统的 soft attention ( 主要都是 u*W*v形式,比如 DIEN,DSIN 等 ),u 表示用户行为历史中一个 item 的 e mbedding,v 是待推荐的目标 item。求出乘积,通过 softmax 函数就可以得到用户历史行为中每个 item 的权重。另外 DIN 的做法比较特殊,是将 u、v 和两者之间的差值这三个向量合并起来作为输入,输入到 mlp 中得到用户历史行为中每个 item 的权重。
参考链接:
1. https://arxiv.org/pdf/1708.04617.pdf
2. https://arxiv.org/pdf/1706.06978.pdf
3. https://zhuanlan.zhihu.com/p/51623339
4. https://arxiv.org/pdf/1809.03672.pdf
5. https://arxiv.org/pdf/1905.06482.pdf
6. https://arxiv.org/pdf/1905.06874.pdf
7. https://arxiv.org/pdf/1906.03776.pdf
8. https://arxiv.org/pdf/1711.06632.pdf
原文链接:
https://zhuanlan.zhihu.com/p/78015378
今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:
欢迎加入 DataFunTalk 算法交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker
),回复:算法,逃课儿会自动拉你进群。

梦想做个翟老师,前京东算法工程师。从事计算广告、深度强化学习、深度学习、图像处理、深度学习推荐算法、分布式训练架构等方向。
关于我们:
DataFunTalk专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号DataFunTalk累计生产原创文章400+,百万+阅读,5万+精准粉丝。

一个在看,一段时光!👇









