点击上方“蓝色字体”,选择 “设为星标”
关键讯息,D1时间送达!
随着企业开始使用可将其数据投入使用的深度学习(DL)项目,他们必须保护这些数据,而数字孪生是成功的关键。
在当今世界,数据为王。无论是亚马逊、苹果、Facebook、谷歌、沃尔玛还是Netflix,世界上最有价值的公司都有一个共同点:数据是他们最有价值的资产。所有这些公司都使用深度学习(DL)将这些数据投入使用。
无论您从事什么业务,数据都是您最宝贵的资产。您需要通过执行自己的DL保护这些资产。深度学习成功的最重要因素是拥有足够的正确种类的数据。那就是数字孪生的由来。
数字孪生是实际物理过程、系统或设备的数字副本。简单说,数字孪生就是在虚拟世界中再造一个现实世界。最重要的是,数字孪生可能是深度学习项目成功的关键,尤其是涉及危险、昂贵或耗时的过程的深度学习项目。
到目前为止,包括半导体制造在内的几乎每个行业都已经意识到DL创造战略优势的潜力。深度学习使用神经网络来执行高级模式匹配。深度学习已应用于面部和语音识别、医学图像分析、生物信息学和材料检查等各种领域。
在半导体制造中,深度学习已经应用于产品缺陷分类等领域。大多数领先的公司都争先恐后地在这个充满希望的新竞争环境中获得优势。
随着企业开始探索深度学习及其如何为他们提供帮助,许多企业发现了两点:第一,获得深度学习原型很容易;其次,从“好的原型”到“生产质量”的结果很难。
如今,有了所有从低成本到免费的深度学习平台、工具和套件,与常规应用程序开发相比,深度学习应用的初始开发非常快速且相对容易。但是,产品化深度学习应用并不比产品化传统应用更容易,甚至更难。
原因在于数据。在没有提供生产质量结果的深度学习应用和彻底改变您解决特定问题方式的深度学习应用之间,通常有足够的数据以及足够的正确类型的数据。
深度学习基于模式匹配,它是通过向神经网络呈现表示要匹配的目标的数据来进行“编程”的。大量数据训练网络以识别目标(并知道何时不是目标)。
深度学习具有强大的功能,可快速生成原型并提供概念验证。但是深度学习的真正优势不是开发速度。这是事实,它释放了数据的力量来做其他任何方式都做不到的事情。
任何深度学习应用的成功都取决于训练中使用的数据集的深度和广度。如果训练数据集太小、太狭窄或太“正常”,那么深度学习方法将不会比标准技术做得更好。实际上,它可能会做得更差。重要的是,用足够多的数据来训练网络,以表示所有重要状态或演示的数据,以使网络学会掌握当前问题的正确本质。
对于某些领域(例如自动驾驶或半导体制造)而言,困难之处在于(非常幸运地)很少发生某些最严重的异常情况。但是,如果您想让深度学习应用识别出在汽车前面跑来跑去的孩子(或致命的光罩错误),则必须使用大量这些情况来训练网络,而在实际情况是现实世界中并没有太多这些数据。而数字孪生是创建足够的异常数据以正确训练网络识别这些条件的唯一方法。
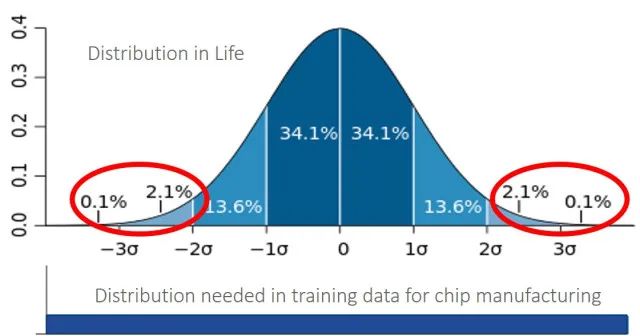
上图为带有标准偏差的正态分布曲线图。在半导体制造中,与驾驶一样,“异常”事件非常少见,但是必须对神经网络进行尽可能多的训练,因为最坏的事件会导致芯片故障。使得整体平均效果还不够好。
数字孪生,也就是实际过程、系统和设备的虚拟表示,是用于创建正确数量以及正确类型的数据以成功训练深度学习网络的关键工具。
使用数字双胞胎创建DL训练数据有以下几个原因:
您所处的数据可能属于您的客户,因此您不能将其用于深度学习训练。
您可能需要将创建深度学习所需数据的资源完全投入到客户项目中。
您已经开发了深度学习应用,但是发现您需要特定的数据来调整和训练您的神经网络以达到所需的准确性,但是使用晶圆厂资源创建数据的成本高得令人望而却步。
您知道您将无法找到足够的异常数据来适当地训练深度学习网络。最后一种情况几乎是普遍存在的。
理想情况下,要保持对数据的完全控制,您需要三个数字孪生:生产流程中先于您的过程/设备的数字孪生子,以提供用于模拟您自己的过程的输入数据;您自己的过程/设备的数字孪生;以及在生产流程中跟随您的过程/设备的数字孪生,以便您可以将输出馈送到下游进行验证。
在2019年SPIE光罩技术会议上,D2S展示了一篇论文,展示了使用深度学习技术创建的两个数字孪生,即扫描电子显微镜(SEM)数字孪生子和曲线反光刻技术(ILT)数字孪生(图2显示了SEM数字孪生的输出)。虽然数字孪生的输出通常不足以用于制造,但这些数字孪生已被用于训练深度学习神经网络和验证。重要的是,这些数字孪生是由深度学习而不是通过仿真生成的。
这是一个使用深度学习作为生成其他DL所需数据的工具的示例,它展示了投资深度学习的复合收益。
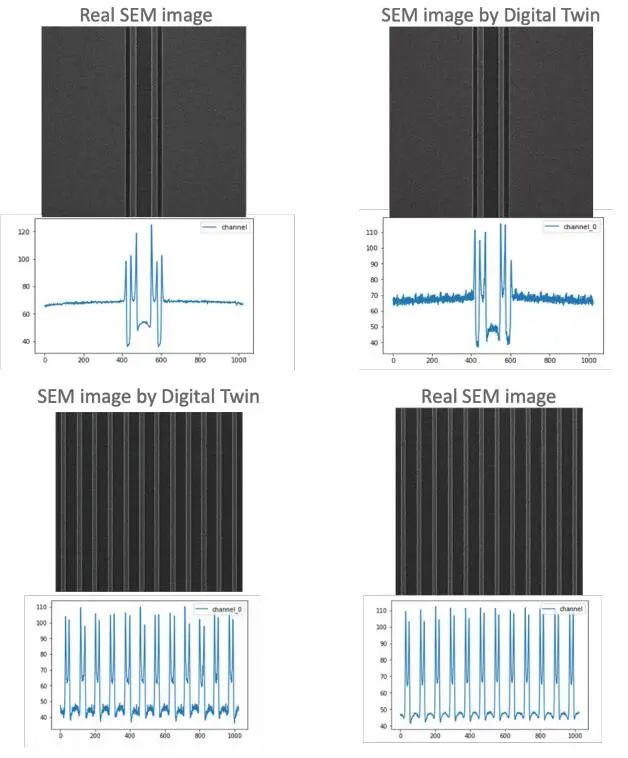
上图由SEM数字孪生生成的掩模SEM图像和真实SEM图像的两个示例。还显示了在同一位置的水平切割线上的图像强度。不仅图像看起来非常相似,而且边缘的信号响应也相似。
所有这些听起来都像是有很多工作要做。为什么不使用咨询公司为您做深度学习?因为,记住,数据为王!保护数据并自己执行深度学习。值得庆幸的是,我们可以遵循一条成功的既定道路。
首先,您需要确定将对深度学习产生影响的项目。您确实需要谨慎选择,深度学习是模式匹配,因此您需要选择属于该领域的内容。基于图像的应用,例如缺陷分类是比较匹配的。晶圆厂中的所有设备都会创建大量的运行数据,除非出现问题,否则很少引用这些数据。
您不仅可以事后将这些宝贵的数据仅用作诊断工具,还可以持续监控整个Fab上的数据,并训练深度学习应用程序以标记出问题之前的模式,这样您就可以在问题产生影响之前识别和纠正问题,节省停机时间。
例如,Mycronic在2020 SPIE Advanced Lithography Conference上的eBeam Initiative午餐时间演讲中披露,该公司如何利用其机器日志文件中的数据来使深度学习正常工作,以预测像“mura”之类的异常(不均匀的亮度影响,使人烦恼),但是众所周知,这对于图像处理算法来说很难在平板显示器(FPD)掩模上检测到。
通常,操作员执行的是非常乏味且容易出错的过程,但是很难使用传统算法实现自动化,因此这是深度学习的不错选择。无论是通过目视检查还是其他方式,检查特定情况的专业人员都会非常有可能正确执行任务。但是面对许多类似情况的例子,人类会犯错并变得越来越不可靠。
在特定情况下,深度学习可能不如人类所能做的那样好。但是它在一些情况下却做得比人类要好。随着执行任务时间的增加,人类会犯更多的错误;而深度学习的成功概率不会随着数量或时间的增加而降低。
一旦确定了深度学习项目,就会有多种可用资源,可带您迈向成功之路,同时仍然使您能够严格控制自己的数据。如果您是深度学习的新手,并希望为深度学习试点项目提供全面支持,则可以加入电子制造深度学习中心(CDLe),这是一个旨在联合起来的行业领导者联盟人才和资源来提升深度学习在我们独特的问题空间中的先进水平,并加快深度学习在我们企业的每种产品中的采用,从而改善我们为客户提供的产品。
如果您已经开始进行深度学习项目,但是由于深度学习数据缺口而遇到了问题,那么D2S可以帮助您构建数字双胞胎,您需要对它们进行扩充和调整才能使DL成功。
(来源:千家网)
如果您在企业IT、网络、通信行业的某一领域工作,并希望分享观点,欢迎给企业网D1Net投稿
 投稿邮箱:editor@d1net.com
投稿邮箱:editor@d1net.com
点击蓝色字体 关注
关注
企业网D1net旗下信众智是CIO(首席信息官)的智力、资源分享平台,也是国内最大的CIO社交平台。
信众智让CIO为CIO服务,提供产品点评、咨询、培训、猎头、需求对接等服务。也是国内最早的toB共享经济平台。
同时,企业网D1net和超过一半的央企信息部门主管联合成立了中国企业数字化联盟,主要面向各地大型企业,提供数字化转型方面的技术、政策、战略、战术方面的帮助和支撑。
扫描下方“二维码”或点击“阅读原文”可以查看更多详情









