这是作者网络安全自学教程系列,主要是关于安全工具和实践操作的在线笔记,特分享出来与博友们学习,希望您喜欢,一起进步。前文分享了传统的恶意代码检测技术,包括恶意代码检测的对象和策略、特征值检测技术、校验和检测技术、启发式扫描技术、虚拟机检测技术和主动防御技术。这篇文章将介绍基于机器学习的恶意代码检测技术,主要参考郑师兄的视频总结,包括机器学习概述与算法举例、基于机器学习方法的恶意代码检测、机器学习算法在工业界的应用。同时,我再结合自己的经验进行扩充,详细分享了基于机器学习的恶意代码检测技术,基础性文章,希望对您有所帮助~
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是关于安全工具和实践操作的在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习网络安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔~
推荐作者之前介绍的四篇机器学习宇恶意代码检测相关的文章,如下:
作者的github资源:
https://github.com/eastmountyxz/Software-Security-Course
https://github.com/eastmountyxz/NetworkSecuritySelf-study
https://github.com/eastmountyxz/Windows-Hacker-Exp
声明:本人坚决反对利用教学方法进行犯罪的行为,一切犯罪行为必将受到严惩,绿色网络需要我们共同维护,更推荐大家了解它们背后的原理,更好地进行防护。
参考推荐:
https://mooc.study.163.com/learn/1000003014?share=2&shareId=1000001005
前文学习:
[网络安全自学篇] 一.入门笔记之看雪Web安全学习及异或解密示例
[网络安全自学篇] 二.Chrome浏览器保留密码功能渗透解析及登录加密入门笔记
[网络安全自学篇] 三.Burp Suite工具安装配置、Proxy基础用法及暴库示例
[网络安全自学篇] 四.实验吧CTF实战之WEB渗透和隐写术解密
[网络安全自学篇] 五.IDA Pro反汇编工具初识及逆向工程解密实战
[网络安全自学篇] 六.OllyDbg动态分析工具基础用法及Crakeme逆向
[网络安全自学篇] 七.快手视频下载之Chrome浏览器Network分析及Python爬虫探讨
[网络安全自学篇] 八.Web漏洞及端口扫描之Nmap、ThreatScan和DirBuster工具
[网络安全自学篇] 九.社会工程学之基础概念、IP获取、IP物理定位、文件属性
[网络安全自学篇] 十.论文之基于机器学习算法的主机恶意代码
[网络安全自学篇] 十一.虚拟机VMware+Kali安装入门及Sqlmap基本用法
[网络安全自学篇] 十二.Wireshark安装入门及抓取网站用户名密码(一)
[网络安全自学篇] 十三.Wireshark抓包原理(ARP劫持、MAC泛洪)及数据流追踪和图像抓取(二)
[网络安全自学篇] 十四.Python攻防之基础常识、正则表达式、Web编程和套接字通信(一)
[网络安全自学篇] 十五.Python攻防之多线程、C段扫描和数据库编程(二)
[网络安全自学篇] 十六.Python攻防之弱口令、自定义字典生成及网站暴库防护
[网络安全自学篇] 十七.Python攻防之构建Web目录扫描器及ip代理池(四)
[网络安全自学篇] 十八.XSS跨站脚本攻击原理及代码攻防演示(一)
[网络安全自学篇] 十九.Powershell基础入门及常见用法(一)
[网络安全自学篇] 二十.Powershell基础入门及常见用法(二)
[网络安全自学篇] 二十一.GeekPwn极客大赛之安全攻防技术总结及ShowTime
[网络安全自学篇] 二十二.Web渗透之网站信息、域名信息、端口信息、敏感信息及指纹信息收集
[网络安全自学篇] 二十三.基于机器学习的恶意请求识别及安全领域中的机器学习
[网络安全自学篇] 二十四.基于机器学习的恶意代码识别及人工智能中的恶意代码检测
[网络安全自学篇] 二十五.Web安全学习路线及木马、病毒和防御初探
[网络安全自学篇] 二十六.Shodan搜索引擎详解及Python命令行调用
[网络安全自学篇] 二十七.Sqlmap基础用法、CTF实战及请求参数设置(一)
[网络安全自学篇] 二十八.文件上传漏洞和Caidao入门及防御原理(一)
[网络安全自学篇] 二十九.文件上传漏洞和IIS6.0解析漏洞及防御原理(二)
[网络安全自学篇] 三十.文件上传漏洞、编辑器漏洞和IIS高版本漏洞及防御(三)
[网络安全自学篇] 三十一.文件上传漏洞之Upload-labs靶场及CTF题目01-10(四)
[网络安全自学篇] 三十三.文件上传漏洞之绕狗一句话原理和绕过安全狗(六)
[网络安全自学篇] 三十四.Windows系统漏洞之5次Shift漏洞启动计算机
[网络安全自学篇] 三十五.恶意代码攻击溯源及恶意样本分析
[网络安全自学篇] 三十六.WinRAR漏洞复现(CVE-2018-20250)及恶意软件自启动劫持
[网络安全自学篇] 三十七.Web渗透提高班之hack the box在线靶场注册及入门知识(一)
[网络安全自学篇] 三十八.hack the box渗透之BurpSuite和Hydra密码爆破及Python加密Post请求(二)
[网络安全自学篇] 三十九.hack the box渗透之DirBuster扫描路径及Sqlmap高级注入用法(三)
[网络安全自学篇] 四十.phpMyAdmin 4.8.1后台文件包含漏洞复现及详解(CVE-2018-12613)
[网络安全自学篇] 四十一.中间人攻击和ARP欺骗原理详解及漏洞还原
[网络安全自学篇] 四十二.DNS欺骗和钓鱼网站原理详解及漏洞还原
[网络安全自学篇] 四十三.木马原理详解、远程服务器IPC$漏洞及木马植入实验
[网络安全自学篇] 四十四.Windows远程桌面服务漏洞(CVE-2019-0708)复现及详解
[网络安全自学篇] 四十五.病毒详解及批处理病毒制作(自启动、修改密码、定时关机、蓝屏、进程关闭)
[网络安全自学篇] 四十六.微软证书漏洞CVE-2020-0601 (上)Windows验证机制及可执行文件签名复现
[网络安全自学篇] 四十八.Cracer第八期——(1)安全术语、Web渗透流程、Windows基础、注册表及黑客常用DOS命令
[网络安全自学篇] 四十九.Procmon软件基本用法及文件进程、注册表查看
[网络安全自学篇] 五十.虚拟机基础之安装XP系统、文件共享、网络快照设置及Wireshark抓取BBS密码
[网络安全自学篇] 五十一.恶意样本分析及HGZ木马控制目标服务器
[网络安全自学篇] 五十三.Windows漏洞利用之Metasploit实现栈溢出攻击及反弹shell
[网络安全自学篇] 五十四.Windows漏洞利用之基于SEH异常处理机制的栈溢出攻击及shell提取
[网络安全自学篇] 五十五.Windows漏洞利用之构建ROP链绕过DEP并获取Shell
[网络安全自学篇] 五十六.i春秋老师分享小白渗透之路及Web渗透技术总结
[网络安全自学篇] 五十七.PE文件逆向之什么是数字签名及Signtool签名工具详解(一)
[网络安全自学篇] 五十八.Windows漏洞利用之再看CVE-2019-0708及Metasploit反弹shell
[网络安全自学篇] 五十九.Windows漏洞利用之MS08-067远程代码执行漏洞复现及shell深度提权
[网络安全自学篇] 六十.Cracer第八期——(2)五万字总结Linux基础知识和常用渗透命令
[网络安全自学篇] 六十一.PE文件逆向之数字签名详细解析及Signcode、PEView、010Editor、Asn1View等工具用法(二)
[网络安全自学篇] 六十二.PE文件逆向之PE文件解析、PE编辑工具使用和PE结构修改(三)
[网络安全自学篇] 六十三.hack the box渗透之OpenAdmin题目及蚁剑管理员提权(四)
[网络安全自学篇] 六十四.Windows漏洞利用之SMBv3服务远程代码执行漏洞(CVE-2020-0796)复现及详解
[网络安全自学篇] 六十五.Vulnhub靶机渗透之环境搭建及JIS-CTF入门和蚁剑提权示例(一)
[网络安全自学篇] 六十六.Vulnhub靶机渗透之DC-1提权和Drupal漏洞利用(二)
[网络安全自学篇] 六十七.WannaCry勒索病毒复现及分析(一)Python利用永恒之蓝及Win7勒索加密
[网络安全自学篇] 六十八.WannaCry勒索病毒复现及分析(二)MS17-010利用及病毒解析
[网络安全自学篇] 六十九.宏病毒之入门基础、防御措施、自发邮件及APT28样本分析
[网络安全自学篇] 七十.WannaCry勒索病毒复现及分析(三)蠕虫传播机制分析及IDA和OD逆向
[网络安全自学篇] 七十一.深信服分享之外部威胁防护和勒索病毒对抗
[网络安全自学篇] 七十二.逆向分析之OllyDbg动态调试工具(一)基础入门及TraceMe案例分析
[网络安全自学篇] 七十三.WannaCry勒索病毒复现及分析(四)蠕虫传播机制全网源码详细解读
[网络安全自学篇] 七十四.APT攻击检测溯源与常见APT组织的攻击案例
[网络安全自学篇] 七十五.Vulnhub靶机渗透之bulldog信息收集和nc反弹shell(三)
[网络安全自学篇] 七十六.逆向分析之OllyDbg动态调试工具(二)INT3断点、反调试、硬件断点与内存断点
[网络安全自学篇] 七十七.恶意代码与APT攻击中的武器(强推Seak老师)
[网络安全自学篇] 七十八.XSS跨站脚本攻击案例分享及总结(二)
[网络安全自学篇] 七十九.Windows PE病毒原理、分类及感染方式详解
[网络安全自学篇] 八十.WHUCTF之WEB类解题思路WP(代码审计、文件包含、过滤绕过、SQL注入)
[网络安全自学篇] 八十一.WHUCTF之WEB类解题思路WP(文件上传漏洞、冰蝎蚁剑、反序列化phar)
[网络安全自学篇] 八十二.WHUCTF之隐写和逆向类解题思路WP(文字解密、图片解密、佛语解码、冰蝎流量分析、逆向分析)
[网络安全自学篇] 八十三.WHUCTF之CSS注入、越权、csrf-token窃取及XSS总结
[网络安全自学篇] 八十四.《Windows黑客编程技术详解》之VS环境配置、基础知识及DLL延迟加载详解
[网络安全自学篇] 八十五.《Windows黑客编程技术详解》之注入技术详解(全局钩子、远线程钩子、突破Session 0注入、APC注入)
[网络安全自学篇] 八十六.威胁情报分析之Python抓取FreeBuf网站APT文章(上)
[网络安全自学篇] 八十七.恶意代码检测技术详解及总结
前文欣赏:
[渗透&攻防] 一.从数据库原理学习网络攻防及防止SQL注入
[渗透&攻防] 二.SQL MAP工具从零解读数据库及基础用法
[渗透&攻防] 三.数据库之差异备份及Caidao利器
[渗透&攻防] 四.详解MySQL数据库攻防及Fiddler神器分析数据包
随着互联网的繁荣,现阶段的恶意代码也呈现出快速发展的趋势,主要表现为变种数量多、传播速度快、影响范围广。在这样的形势下,传统的恶意代码检测方法已经无法满足人们对恶意代码检测的要求。比如基于签名特征码的恶意代码检测,这种方法收集已知的恶意代码,以一种固定的方式生成特定的签名,维护这样的签名库,当有新的检测任务时,通过在签名库中检索匹配的方法进行检测。暂且不说更新、维护签名库的过程需要耗费大量的人力物力,恶意代码编写者仅仅通过混淆、压缩、加壳等简单的变种方式便可绕过这样的检测机制。
为了应对上面的问题,基于机器学习的恶意代码检测方法一直是学界研究的热点。由于机器学习算法可以挖掘输入特征之间更深层次的联系,更加充分地利用恶意代码的信息,因此基于机器学习的恶意代码检测往往表现出较高的准确率,并且一定程度上可以对未知的恶意代码实现自动化的分析。下面让我们开始进行系统的介绍吧~
一.机器学习概述与算法举例
1.机器学习概念
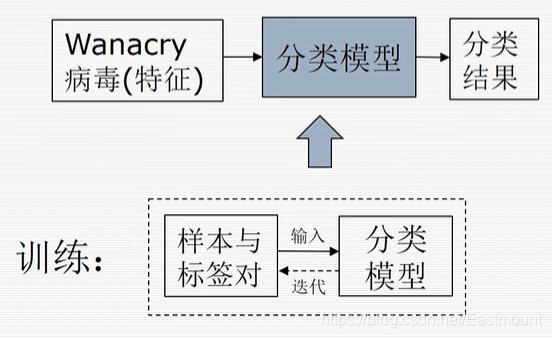
首先介绍下机器学习的基本概念,如下图所示,往分类模型中输入某个样本特征,分类模型输出一个分类结果。这就是一个标准的机器学习检测流程。机器学习技术主要研究的就是如何构建中间的分类模型,如何构造一组参数、构建一个分类方法,通过训练得到模型与参数,让它在部署后能够预测一个正确的结果。
训练是迭代样本与标签对的过程,如数学表达式 y=f(x) ,x表示输入的样本特征向量,y表示标签结果,使用(x,y)对f进行一个拟合的操作,不断迭代减小 y’ 和 y 的误差,使得在下次遇到待测样本x时输出一致的结果。该过程也称为学习的过程。
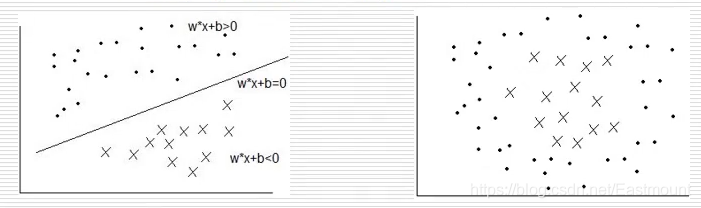
构造分类方法
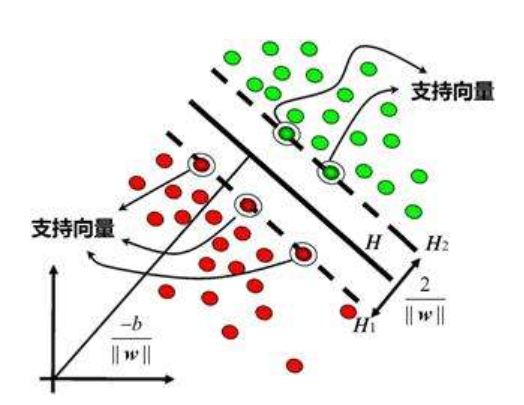
超平面(SVM)
softmax
2.机器学习算法举例
作者之前Python系列分享过非常多的机器学习算法知识,也推荐大家去学习:
机器学习系列文章(共48篇)
。
(1) 支持向量机(SVM)
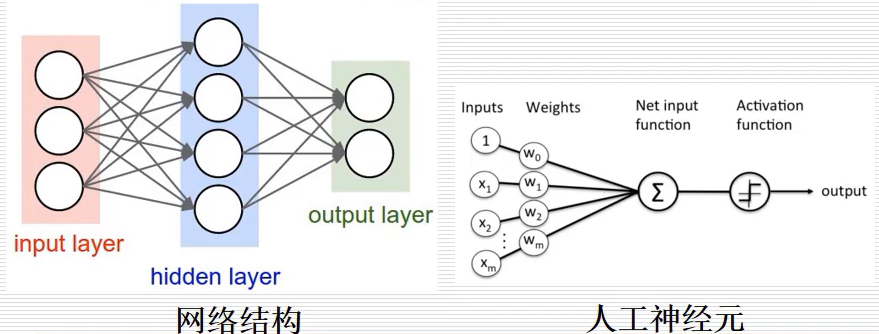
(2) 神经网络(Neural Network)
神经网络和机器学习基础入门分享
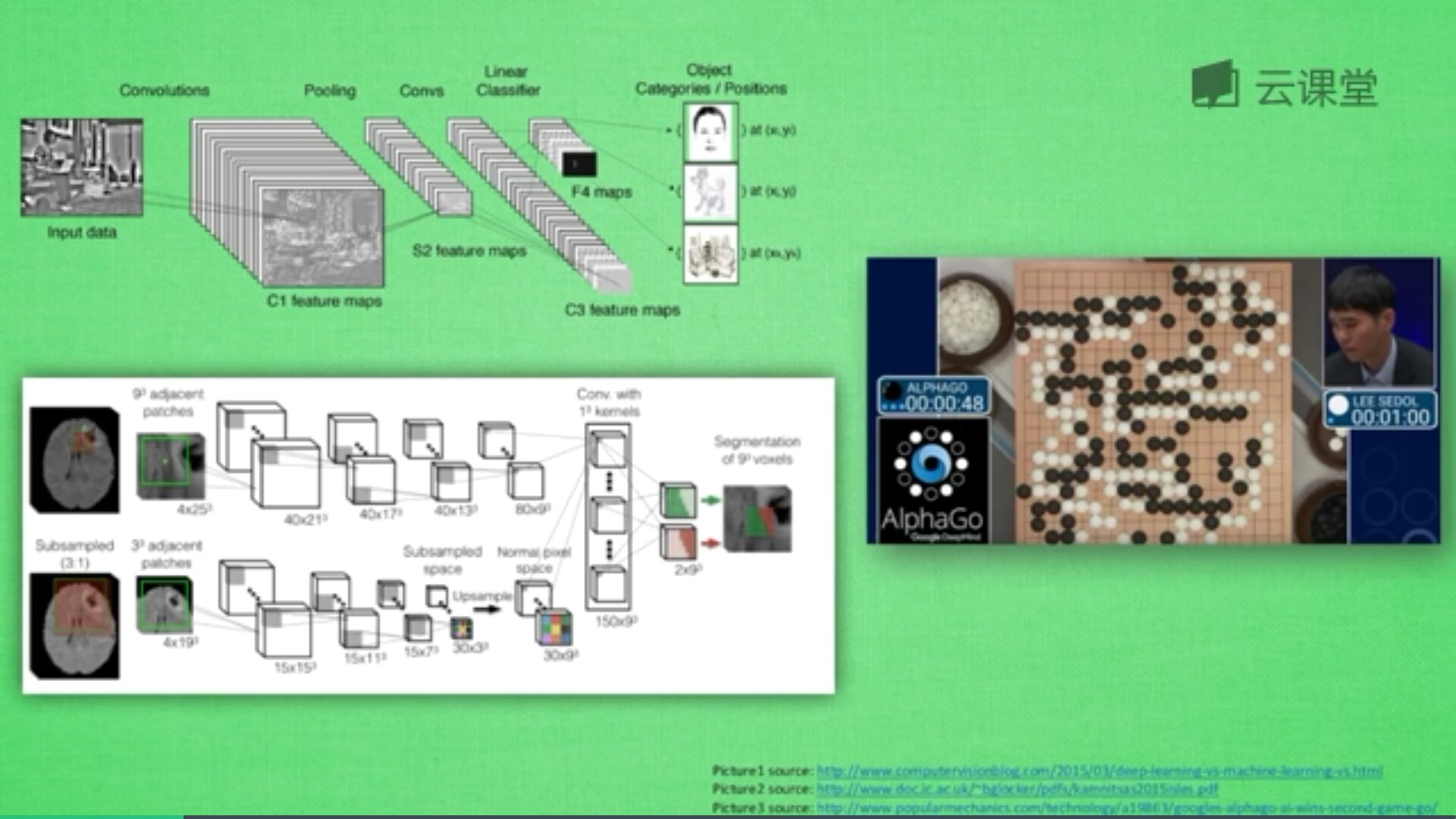
(3) 深度卷积神经网络
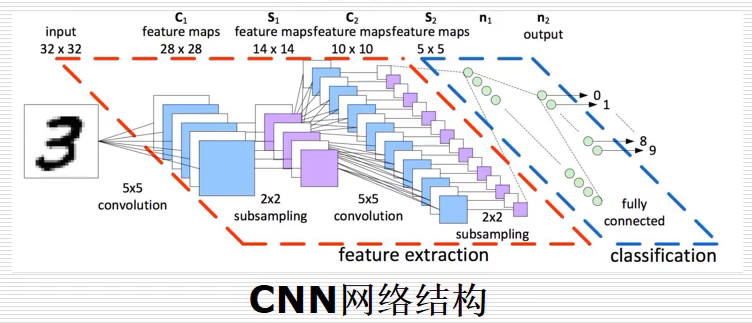
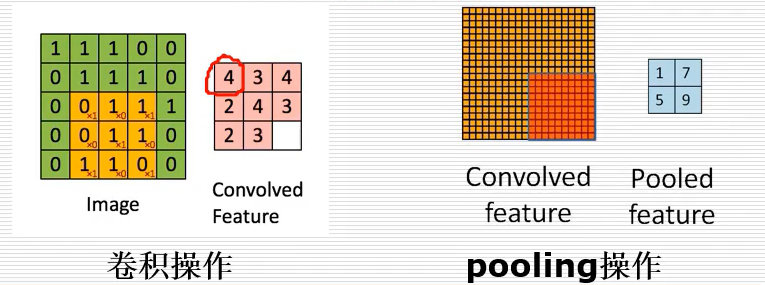
如上图所示,将手写数字“3”(32x32个像素)预测为最终的数字0-9的结果。模型首先使用了6个卷积核,对原始图片进行固定的计算,如下5x5的图像卷积操作后变成了 3x3 的图像。其原理是将特征提取的过程放至神经网络中训练,从而得到比较好的分类结果。卷积之后进行了一个2x2的下采样过程,将图片进一步变小(14x14),接着降维处理,一般采用平均池化或最大池化实现,选定一个固定区域,求取该区域的平均值或最大值,然后将向量进行组合,得到一个全连接网络,最终完成分类任务。
[Python人工智能] 四.神经网络和深度学习入门知识
深度神经网络是深度学习中模型,它主要的一个特点是将特征提取的过程放入到真个训练中,之前对于图片问题是采用手工特征,而CNN让在训练中得到最优的特征提取。
3.特征工程-特征选取与设计
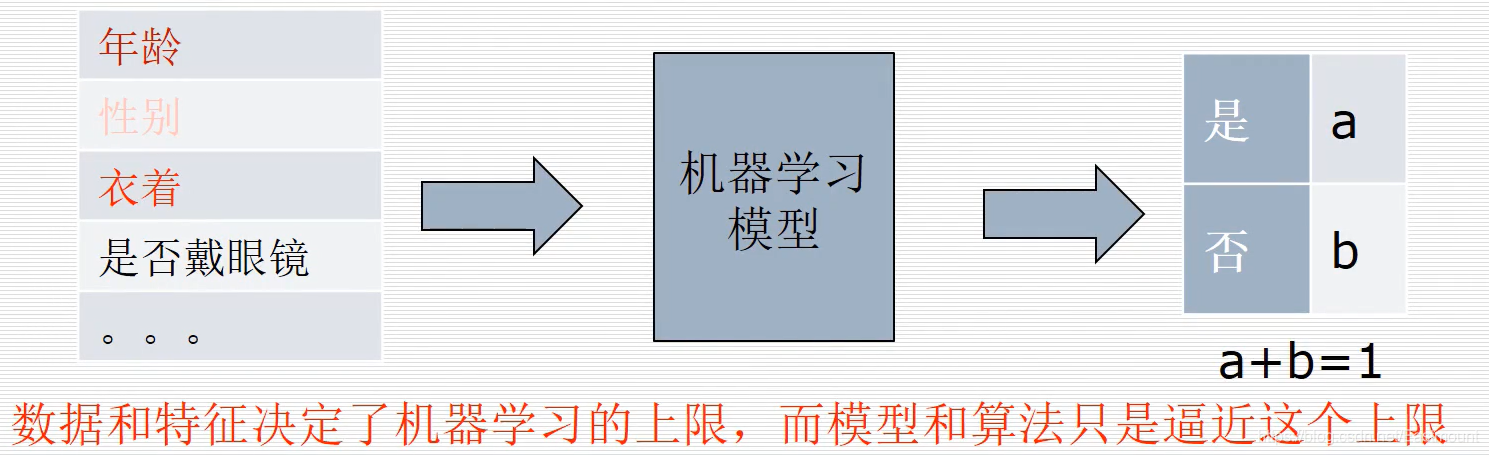
上面介绍了机器学习和深度学习方法,但是这些方法往往是该研究领域的学者所提出,而在恶意代码检测中,往往我们的主要工作量是一些特征的提取和特征的设计,这里面涉及一个特征工程的概念。
特征工程:选取特征,设计特征的过程。
在这些特征中,显然有些特征是非常重要的,比如年龄和衣着。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限,所以如何选取特征是机器学习的一个关键性因素。再比如淘宝的推荐系统,购买电脑推荐鼠标、键盘等。
当然,上面仅仅是一个比较简单的问题,当我们推广到恶意代码检测等复杂问题时,如果不了解这个领域,可能就会导致模型的结果不理想。
特征设计——人脸识别
该部分的最后,作者也推荐一些书籍供大家学习。
《统计学习方法》李航,数学理论较多
《机器学习》周志华,西瓜书,较通俗透彻
《Deep Learning》Ian Goodfellow,花书,深度学习内容全面
《精通特征工程》结合恶意代码特征学习,包括如何向量化
再看看我的桌面,这些都是作者最近看的一些安全、AI类书籍,希望也您喜欢~
二.基于机器学习方法的恶意代码检测
1.恶意代码的静态动态检测
(1) 特征种类
首先,特征种类如果按照恶意代码是否在用户环境或仿真环境中运行,可以划分为静态特征和动态特征。
静态特征:
没有真实运行的特征
字节码
:二进制代码转换成了字节码,比较原始的一种特征,没有进行任何处理
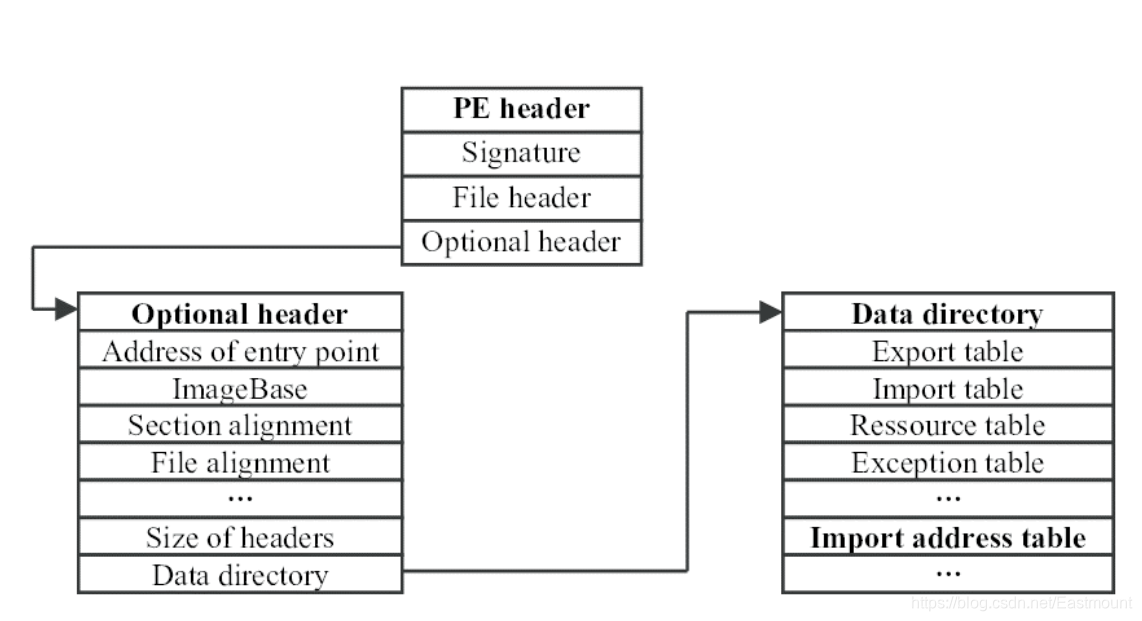
IAT表
:PE结构中比较重要的部分,声明了一些函数及所在位置,便于程序执行时导入,表和功能比较相关
Android权限表
:如果你的APP声明了一些功能用不到的权限,可能存在恶意目的,如手机信息
可打印字符
:将二进制代码转换为ASCII码,进行相关统计
IDA反汇编跳转块
:IDA工具调试时的跳转块,对其进行处理作为序列数据或图数据
动态特征:
相当于静态特征更耗时,它要真正去执行代码
API调用关系
:比较明显的特征,调用了哪些API,表述对应的功能
控制流图
:软件工程中比较常用,机器学习将其表示成向量,从而进行分类
数据流图
:软件工程中比较常用,机器学习将其表示成向量,从而进行分类
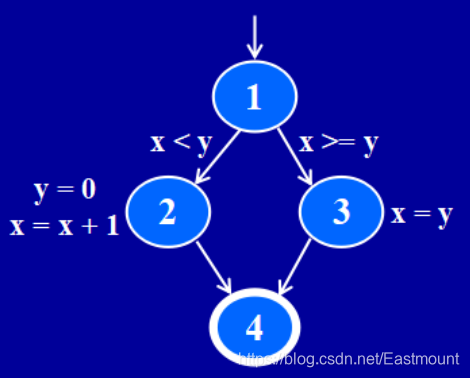
举一个简单的控制流图(Control Flow Graph, CFG)示例。
if ( x < y)
{
y = 0 ;
x = x + 1 ;
}
else
{
x = y;
}
(2) 常见算法
普通机器学习方法和深度学习方法的区别是,普通机器学习方法的参数比较少,相对计算量较小。
普通机器学习方法(SVM支持向量机、RF随机森林、NB朴素贝叶斯)
深度神经网络(Deep Neural Network)
长短时记忆网络(Long Short-Term Memory Network)
图卷积网络 (Graph Convolution Network)
2.静态特征设计举例
首先分享一个静态特征的例子,该篇文章发表在2015年,是一篇CCF C类会议文章。
Saxe J,Berlin K. Deep neural network based malware detection using two dimensional binary program features[C] // 2015 10th International Conference on Malicious and Unwanted Software(MALWARE). IEEE, 2015: 11-20
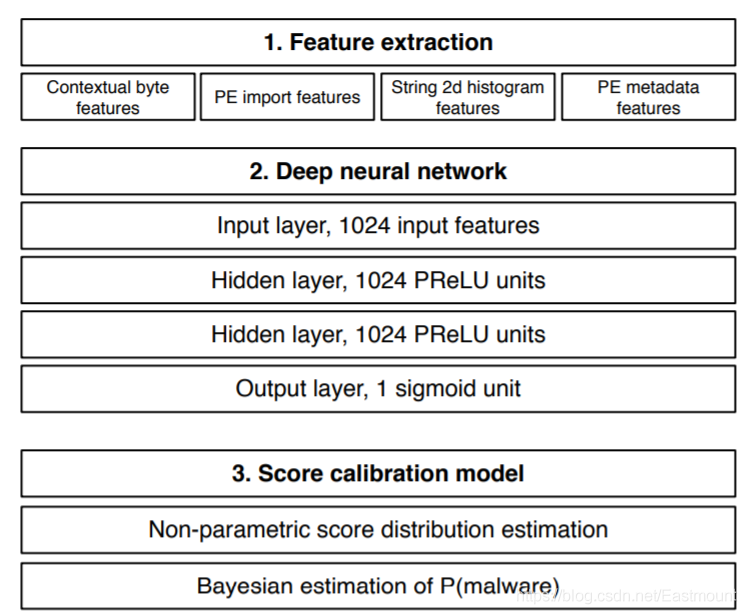
文章的主要方法流程如下所示:
该模型包含三个步骤:
特征抽取
特征抽取输入到深度神经网络
分数校正
特征抽取
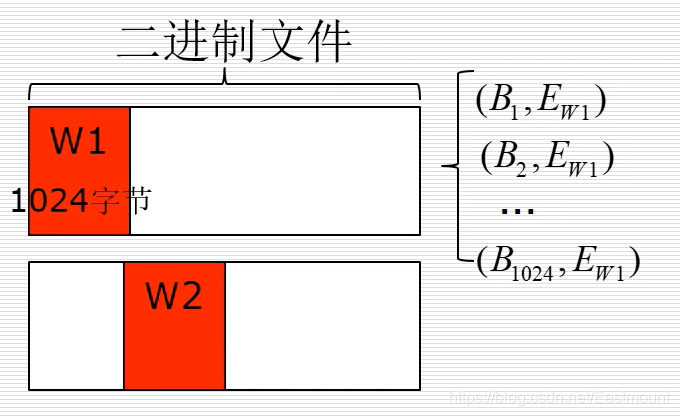
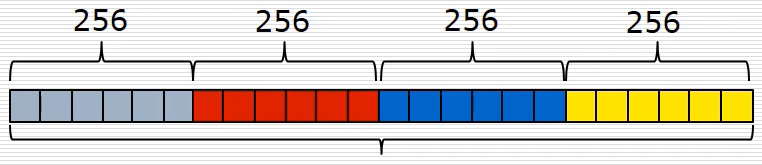
字节-熵对统计特征
:统计滑动窗口的(字节,熵)对个数
i
,E
wi
),最后滑动得到100x1024的字节熵对。
PE头IAT特征
:hashDLL文件名与函数名为[0-255)范围
可打印字符
:统计ASCII码的个数特征
PE元信息
:将PE信息抽取出来组成256维数组,例如编译时间戳
总共有上述四种特征,然后进行拼接得到4*256=1024维的数组,这个数组就代表一个样本的特征向量。假设有10000个样本,就有对应10000个特征向量。
得到特征向量之后,就开始进行模型的训练和测试,一般机器学习任务事先都有一个数据集,并且会分为训练数据集和测试数据集,按照4比1或9比1的比例进行随机划分。训练会将数据集和标签对输入得到恶意和非恶意的结果,再输入测试集得到最终结果。
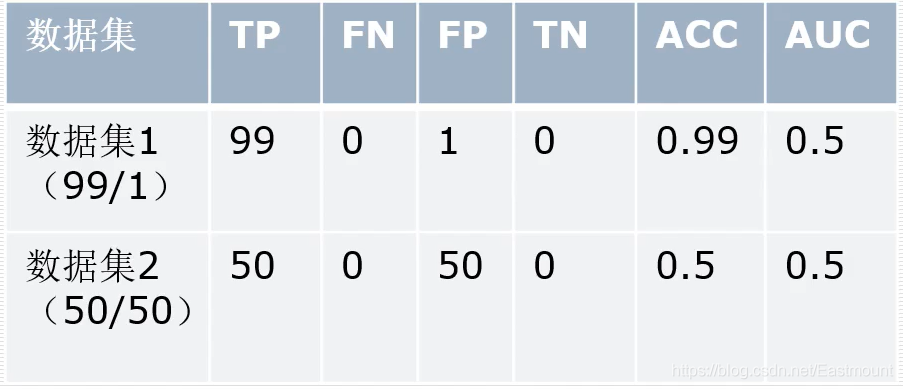
下面是衡量机器学习模型的性能指标,首先是一幅混淆矩阵的图表,真实类别中1代表恶意样本,0代表非恶意样本,预测类别也包括1和0,然后结果分为:
TP:本身是恶意样本,并且预测识别为恶意样本
FP:本身是恶意样本,然而预测识别为非恶意样本,这是误分类的情况
FN:本身是非恶意样本,然而预测识别为恶意样本,这是误分类的情况
TN:本身是非恶意样本,并且预测识别为非恶意样本
然后是Accuracy(准确率)、Precision(查准率)、Recall(查全率)、F1等评价指标。
通常Accuracy是一个评价恶意代码分类的重要指标,但本文选择的是AUC指标,为什么呢?
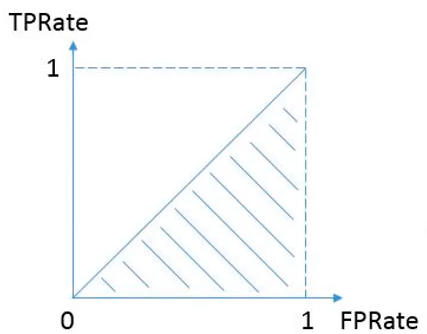
AUC指标包括TPRate和FPRate,然后得到一个点,并计算曲线以下所包围的面积即为AUC指标。其中,TPRate表示分类器识别出正样本数量占所有正样本数量的比值,FPRate表示负样本数量站所有负样本数量的比值。举个例子,我们撒网打鱼,一网下去,网中好鱼的数量占池子中所有好鱼的数量就是TPRate,而FPRate表示一网下去,坏鱼的数量占整个池子中所有坏鱼的数量比例,当然FPRate越小越好。最好的结果就是TPRate为1,而FPRate为0,此时全部分类预测正确。
该论文测试了六种特征集合,其计算的TPR和AUC值如下所示。
3.经典的图片特征举例
下面介绍另一种比较新兴经典的方法,就是图片特征。但一些安全界的人士会认为这种特征不太好,但其方法还是比较新颖的。
它的基本方法是按照每8位一个像素点将恶意软件的二进制文件转换为灰度图片,图片通常分为R、G、B通道,每个8位像素点表示2^8,最终每隔8位生成一个像素点从而转换为如下图所示的灰度图片。图片分别为Obfuscator_ACY家族、Lolipop家族、ramnit家族恶意软件样例,这些样例由微软kaggle比赛公布的数据生成。
这是因为对于某些恶意样本作者来说,他只是使用方法简单的修改特征码,从而每个家族的图片比较相似,最终得到了较好的结果。
4.动态特征设计举例
接下来分享一个动态特征的例子,该篇文章发表在2016年,文章的会议一般,但比较有代表性。
Kolosnjaji B,Zarras A,Webster G,et al. Deep learning for classification of malware system call sequences[C] // Australasian Joint Conference on Artificial Intelligence. Springer,Cham,2016:137-149.
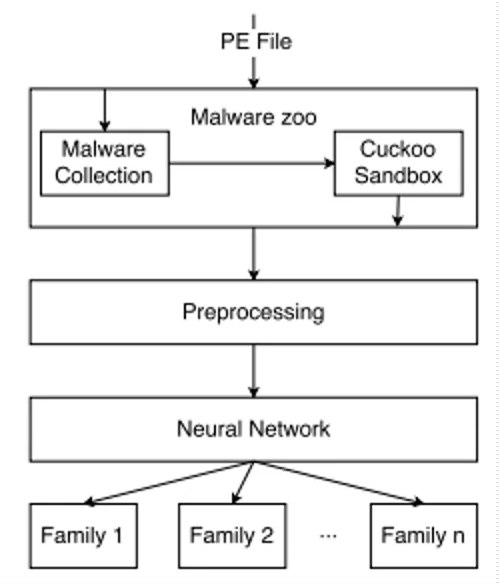
下图展示了该方法的整体流程图。PE文件进入后,直接进入Cuckoo沙箱中,它是一个开源沙箱,在学术论文中提取动态特征比较通用;接着进行进行预处理操作,将文本转换成向量表示的形式,比如提取了200个动态特征,可以使用200维向量表示,每个数组的位置表示对应API,再将所得到的序列输入卷积神经网络LSTM进行分类,最终得到家族分类的结构。
下图展示了实验的结构,其指标是高于单纯的神经网络和卷积网络的效果更好,这是一篇比较基础的文章。
5.深度学习静态检测举例
下面再看一个深度学习静态检测的文章。
Coull S E,Gardner C. Activation Analysis of Byte-Based Deep Neural Network for Malware Classification[C] // 2019 IEEE Security and Privacy Workshops(SPW). IEEE,2019:21-27.
这篇文章是火眼公司的两名员工发布的,所使用的也是静态检测特征,其流程如下所示。
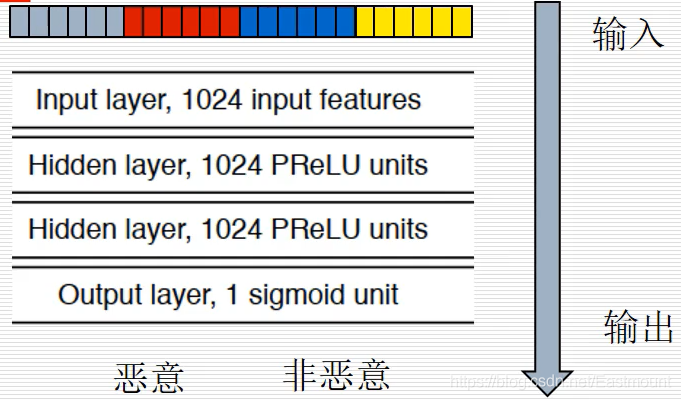
首先,原始的字节码特征直接输入一个Byte Embedding层(词嵌入),对单个元素进行向量化处理,将字节码中的每个字节表示成一个固定长度的向量,从而更好地将字节标记在一个空间维度中。词嵌入技术广泛应用于自然语言处理领域,比如“女人”和“女王”关系比较紧密,这篇文章的目的也是想要在恶意代码中达到类似的效果。
1024
10矩阵输入卷积神经网络中,最后通过全连接层完成恶意和非恶意的分类任务。
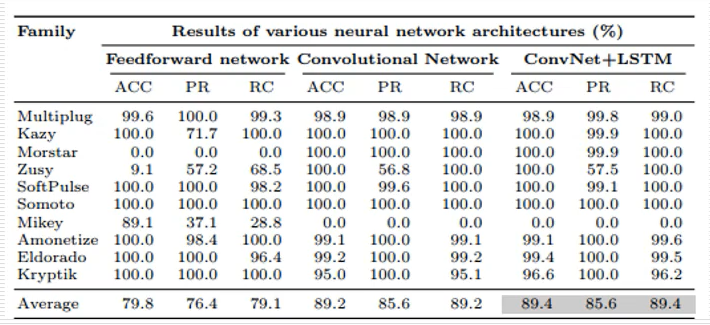
Fireeye使用了三个数据集进行训练和测试,其训练的模型分类效果结果如下表所示,博客Small、Baseline、Baseline+Dropout模型,其网络结构是一样的,其中Small表示使用小的数据集,Baseline表示使用大的数据集,Dropout表示对训练好的神经网络中随机丢弃一些神经元,从而抑制过拟合现象,也是比较常用的深度学习技术。
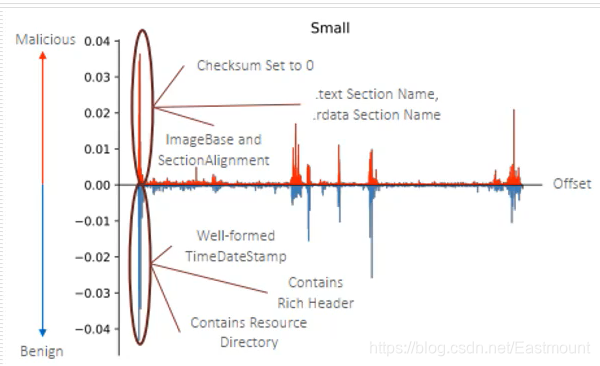
这篇文章的重点是对深度学习的解释性,就是解释深度学习是否能学习到恶意软件的本质特性。下图展示了不同特征对于分类结果的影响,横坐标是Offset偏移,通常用Offset记录字节,从0到右边也对应文件大小,前面可能就是PE头,中间有各种段。
它的横纵坐标分别表示了某些特征对于恶意性分类比较重要,还是非恶意性比较重要。如果它的校验和(CheckSum)是0,就对恶意性分类比较重要,这表示深度学习并没有学习到恶意软件为什么是恶意的,只是通过统计学去发现恶意软件和非恶意软件差别最大部分,以此进行数据建模。
深度学习进行恶意软件检测的问题:没有学习到恶意和非恶意特征,而是学习到区别的统计差异,而这种差异如果被黑客利用是可以被规避的。
6.优缺点
静态特征
优点
缺点
动态特征
优点
缺点
最后给出推荐资料:
7.静态分析和动态分析对比
下面简单总结静态分析和动态分析与深度学习结合的知识,该部分内容源自文章:
深度学习在恶意代码检测 - mbgxbz
,在此感谢作者,觉得非常棒,故引用至此!谢谢~
恶意代码的检测本质上是一个分类问题,即把待检测样本区分成恶意或合法的程序。基于机器学习算法的恶意代码检测技术步骤大致可归结为如下范式:
采集大量的恶意代码样本以及正常的程序样本作为训练样本;
对训练样本进行预处理,提取特征;
进一步选取用于训练的数据特征;
选择合适的机器学习算法训练分类模型;
通过训练后的分类模型对未知样本进行检测。
深度学习作为机器学习的一个分支,由于其可以实现自动化的特征提取,近些年来在处理较大数据量的应用场景,如计算机视觉、语音识别、自然语言处理时可以取得优于传统机器学习算法的效果。随着深度学习在图像处理等领域取得巨大的成功,许多人将深度学习的方法应用到恶意软件检测上来并取得了很好的成果。实际上就是用深度神经网络代替上面步骤中的人为的进一步特征提取和传统机器学习算法。根据步骤中对训练样本进行预处理的方式,可以将检测分为静态分析与动态分析:
静态分析不运行待检测代码,而是通过直接对程序(如反汇编后的代码)进行统计分析得到数据特征
动态分析则在虚拟机或沙箱中执行程序,获取程序执行过程中所产生的数据(如行为特征、网络特征),进行检测和判断。
(1) 静态分析
(2) 动态分析
在网络攻击趋于精细化、恶意代码日新月异的今天,基于深度学习算法的恶意代码检测中越来越受到学术界和众多安全厂商的关注。但这种检测技术在现实应用中还有很多尚未解决的问题。例如上面提到的静态分析与动态分析存在的不足,现在发展的主流方向是将静态、动态分析技术进行结合,使用相同样本的不同层面的特征相对独立地训练多个分类器,然后进行集成,以弥补彼此的不足之处。
除此之外,深度学习算法的可解释性也是制约其发展的一个问题,当前的分类模型一般情况下作为黑盒被加以使用,其结果无法为安全人员进一步分析溯源提供指导。我们常说攻防是息息相关的,螺旋上升的状态。既然存在基于深度学习的恶意代码检测技术,那么自然也有基于深度学习的或者是针对深度学习的恶意代码检测绕过技术,这也是近年来研究的热点问题,那么如何提高模型的稳健性,防止这些定制化的干扰项对我们的深度学习算法产生不利的影响,对抗生成网络的提出或许可以给出答案。
三.机器学习算法在工业界的应用
首先普及一个概念——NGAV。NGAV(Next-Gen AntiVirus)是下一代反病毒软件简称,它是一些厂商提出来的新的病毒检测概念,旨在用新技术弥补传统恶意软件检测的短板。
多家杀毒引擎厂商将机器学习视作NGAV的重要技术,包括McAfee[11], Vmware[9], CrowdStrike[10], Avast[6]
越来越多的厂商开始关注机器学习技术,并发表相关的研究(卡巴斯基[7],火眼[8]),火眼还是用机器学习技术对APT进行分析(组织相似度溯源)
越来越多的安全厂商将机器学习视为反病毒软件的一个关键技术,但需要注意,NGAV并不是一个清晰的定义,你没法去界定一个反病毒软件是上一代产品还是下一代产品。衡量反病毒软件的性能只有对恶意软件的检测率、计算消耗、误报率等,我们只是从现状分析得到越来越多安全领域结合了机器学习。
作为安全从业人员或科研人员,机器学习技术也是我们必须要关注的一个技术。
机器学习算法需要解决的问题如下:
算力问题
大规模的特征数据
训练的模型是可解释的
误报需要维持极度的低水平
算法需要根据恶意软件作者的变化快速适应新的检测特征
最后作者总结下机器学习算法的优势,具体如下:
(1) 传统方法
优点:速度快,消耗计算资源少
缺点:容易绕过,对于未知恶意软件检出率低
(2) 机器学习方法
优点:能够建立专家难以发现的规则与特征
缺点:资源消耗大,面临漂移问题,需要不断更新参数
四.总结
写到这里,这篇文章就介绍完毕,希望对您有所帮助,最后进行简单的总结:
机器学习方法与传统方法不是取代与被取代的关系,而是相互补充,好的防御系统往往是多种技术方法的组合。
机器学习的检测方法研究还不充分,安全领域的专有瓶颈与人工智能研究的共有瓶颈均存在、
机器学习算法本身也面对一些攻击方法的威胁,比如对应抗本。
对抗样本指的是一个经过微小调整就可以让机器学习算法输出错误结果的输入样本。在图像识别中,可以理解为原来被一个卷积神经网络(CNN)分类为一个类(比如“熊猫”)的图片,经过非常细微甚至人眼无法察觉的改动后,突然被误分成另一个类(比如“长臂猿”)。再比如无人驾驶的模型如果被攻击,Stop标志可能被汽车识别为直行、转弯。
学安全一年,认识了很多安全大佬和朋友,希望大家一起进步。这篇文章中如果存在一些不足,还请海涵。作者作为网络安全初学者的慢慢成长路吧!希望未来能更透彻撰写相关文章。同时非常感谢参考文献中的安全大佬们的文章分享,感谢师傅、师兄师弟、师姐师妹们的教导,深知自己很菜,得努力前行。
《珈国情》
欢迎大家讨论,是否觉得这系列文章帮助到您!任何建议都可以评论告知读者,共勉。
(By:Eastmount 2020-07-19 星期日 下午13点写于武汉
http://blog.csdn.net/eastmount/
)
参考文献:
[i] Saxe, J., & Berlin, K. (2015, October). Deep neural network-based malware detection using two-dimensional binary program features. In 2015 10th International Conference on Malicious and Unwanted Software (MALWARE) (pp. 11-20). IEEE.