这篇文章适合于python纯小白,里面可能很多语句是冗长的,甚至可能有一些尚未发现的BUG,这个伴随着我们继续学习来慢慢消解吧。接下来 我把里面会用到的东西在这里做一个总结吧:
用到的模块requests,re,os,jieba,glob,json,lxml,pyecharts,heapq,collection
找到需要爬取的内容,分析网页,抓包查看交互内容
首先我们先进入到我们需要抓取的内容的地址。http://music.163.com/# 这是网易云音乐的首页,我们的目的是抓取周杰伦的所有歌曲,歌词,已经评论,那我们在搜索处输入周杰伦
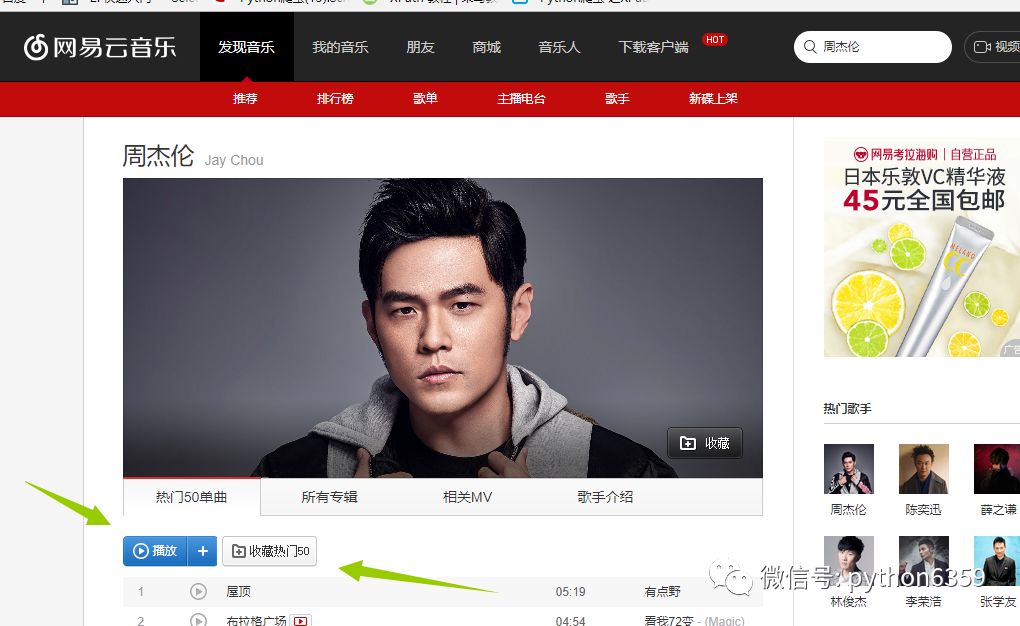
我们第一步抓取所有专辑 进入http://music.163.com/#/artist/album?id=6452如下图所示!
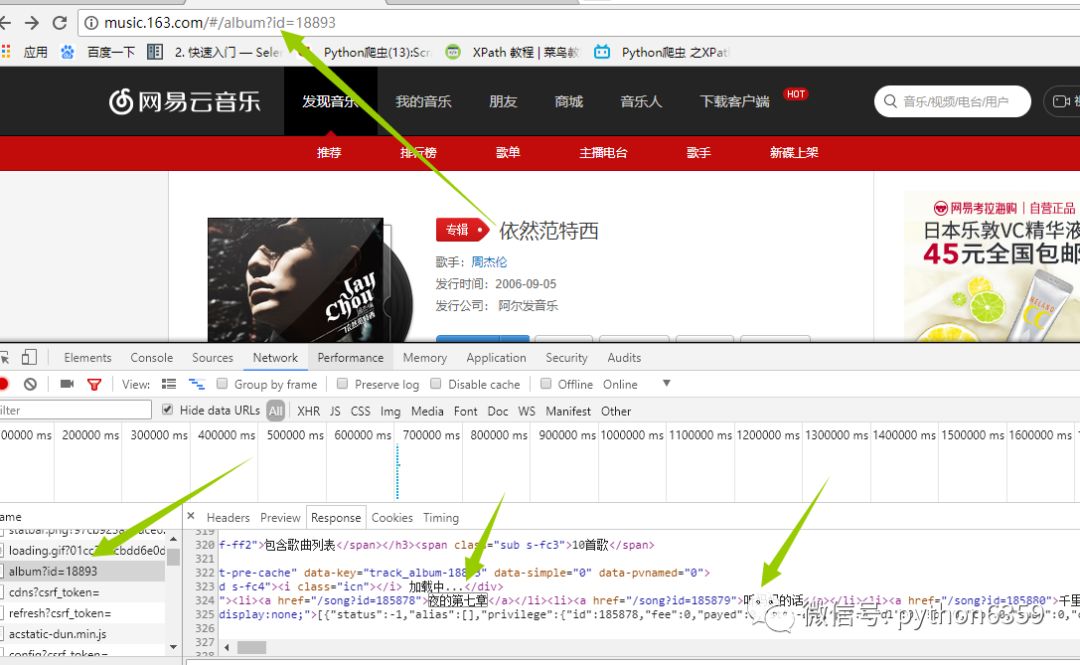
在谷歌的抓包工具(F12)里面查看交互信息发现如下:
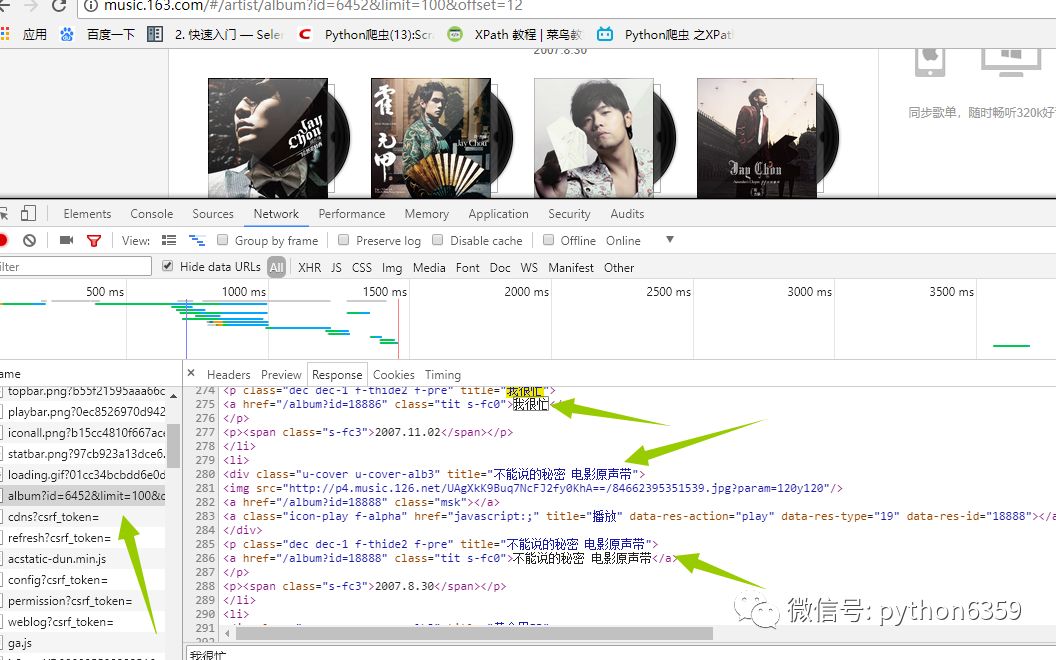
这就是我们想要的信息,那事情就变得简单的,我们没必要用复杂的工具比如(selenium)去加载整个页面,(事实上,如果还没想到抓取歌曲的方法,我估计就得用它了),我们再看header里面有什么
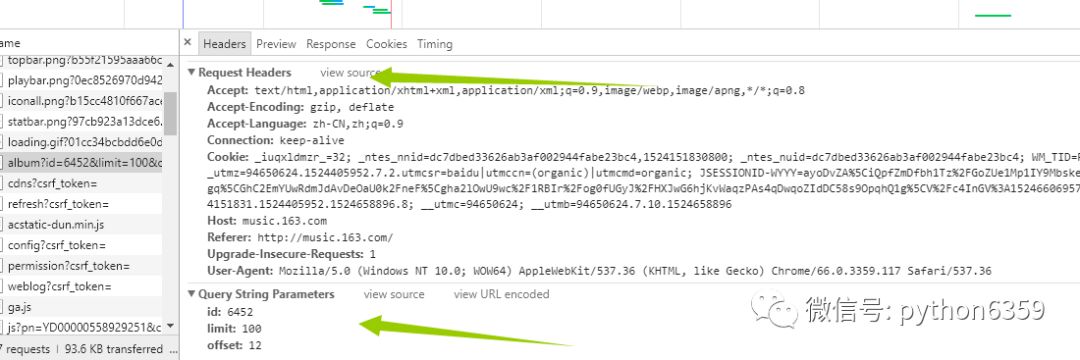
这里面的string我们不用管了,因为它已经在我们的url里面了,我们只需要看request headers 这个就是我们给服务器发送的东西,发送之后,服务器返回给我们的就是network里面的信息。好,接下来我们伪造浏览器发送请求。具体代码如下:
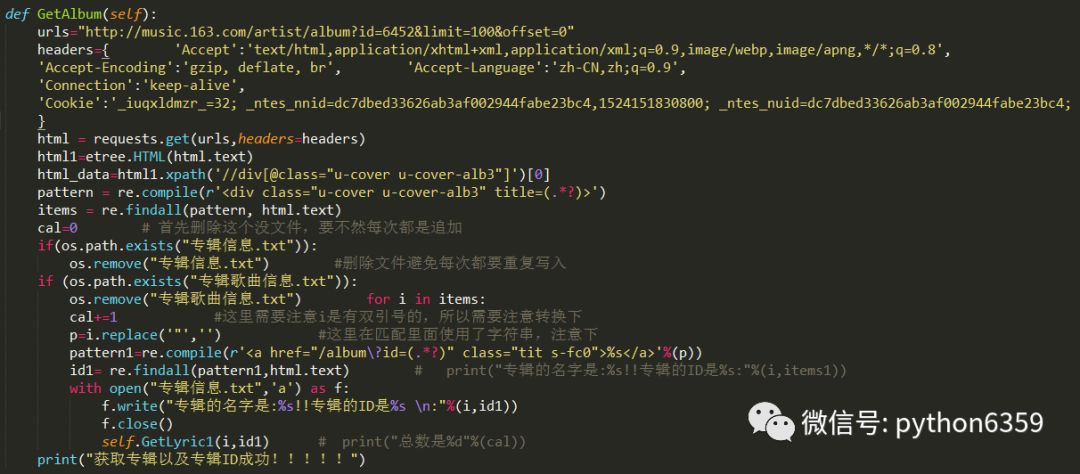
这里面用到了xpath来找到对应标签里面数据,代码不重要,思想懂了就行(代码单独执行可行)
执行结果如下
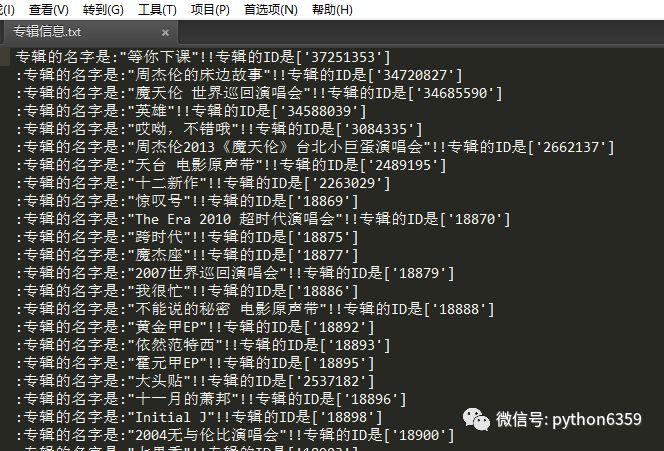
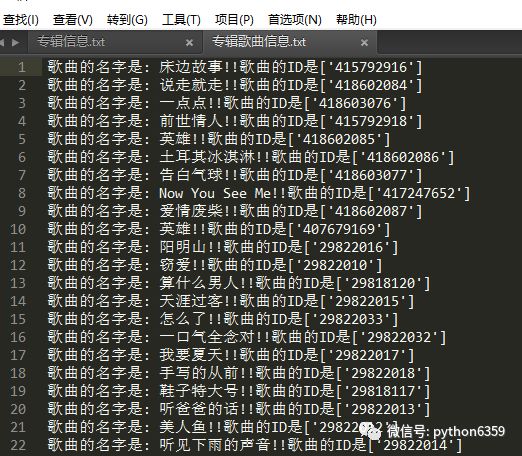
抓取歌曲信息
同样的道理我们通过伪造方式发送信息,获取歌曲信息!!直接上代码
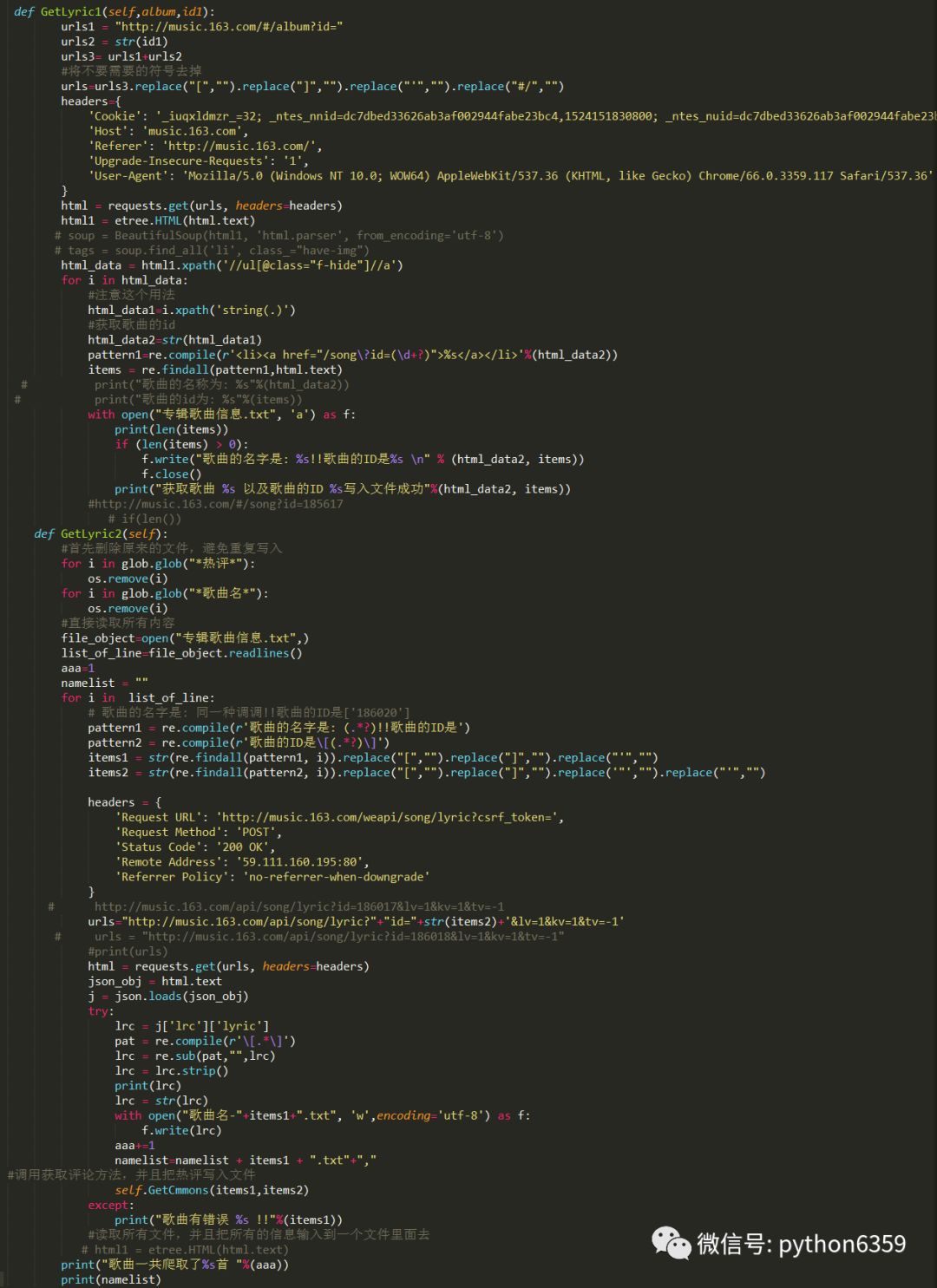
上面需要注意:xpath来获取需要的信息,利用正则来获取ID(其实有很多方法)
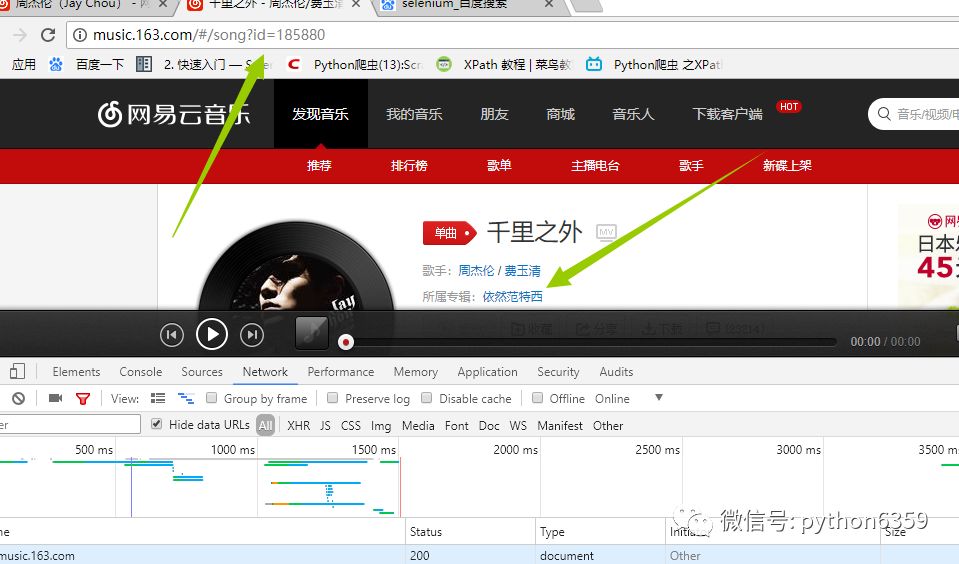
一样的道理,我们分析network来获取我们需要的信息歌词,评论!!直接上代码
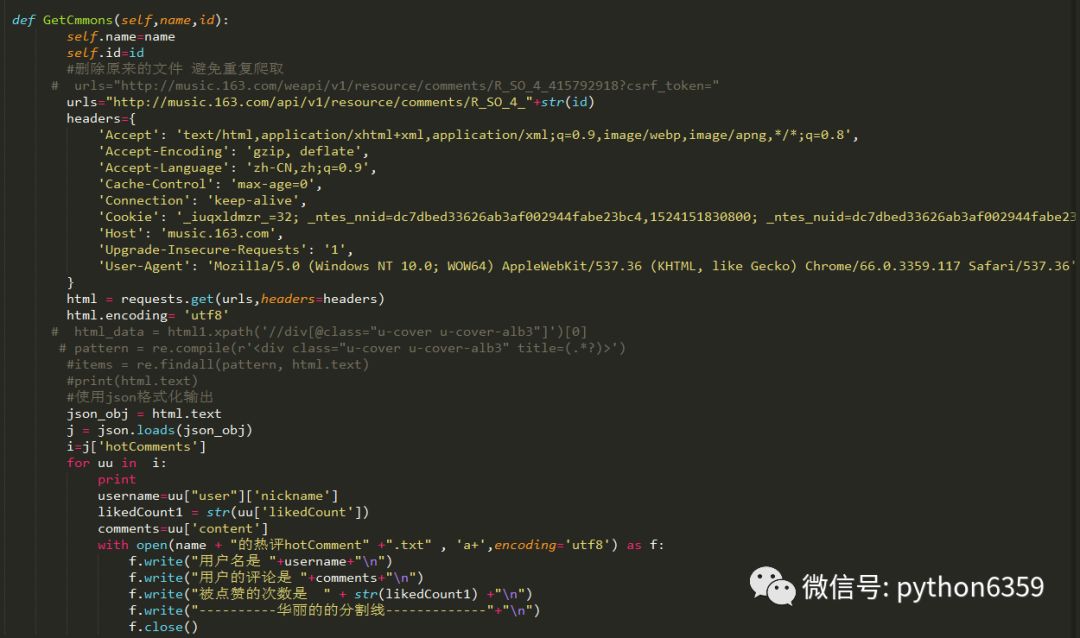
上面需要注意的是:利用json获取需要的数据(至少比正则快点)
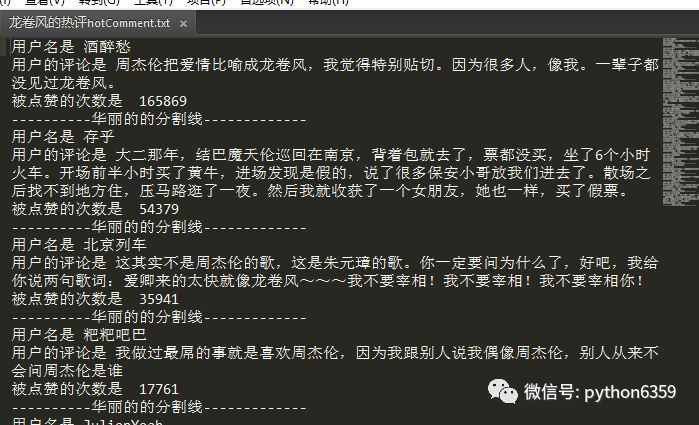
数据分析,可视化
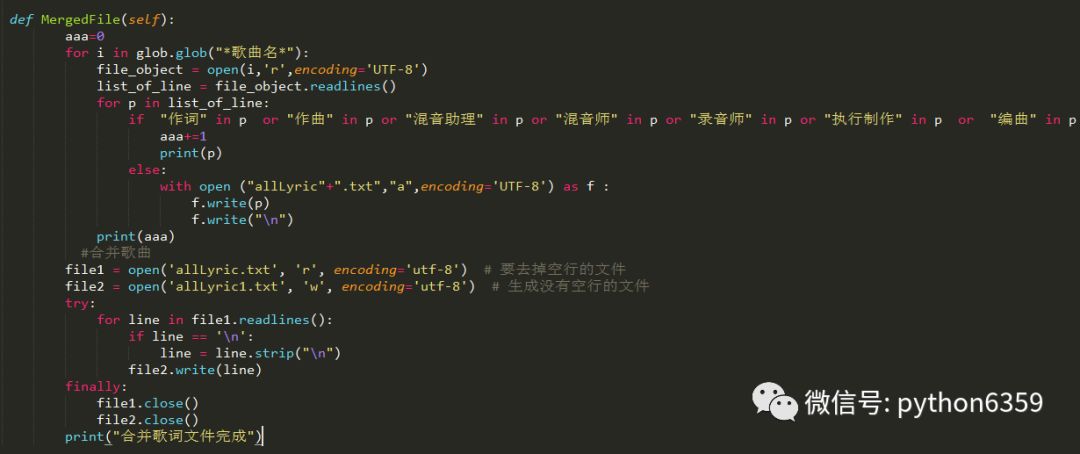
上面需要注意的是:我们合并数据的时候,可以选择性的删除一些无用数据
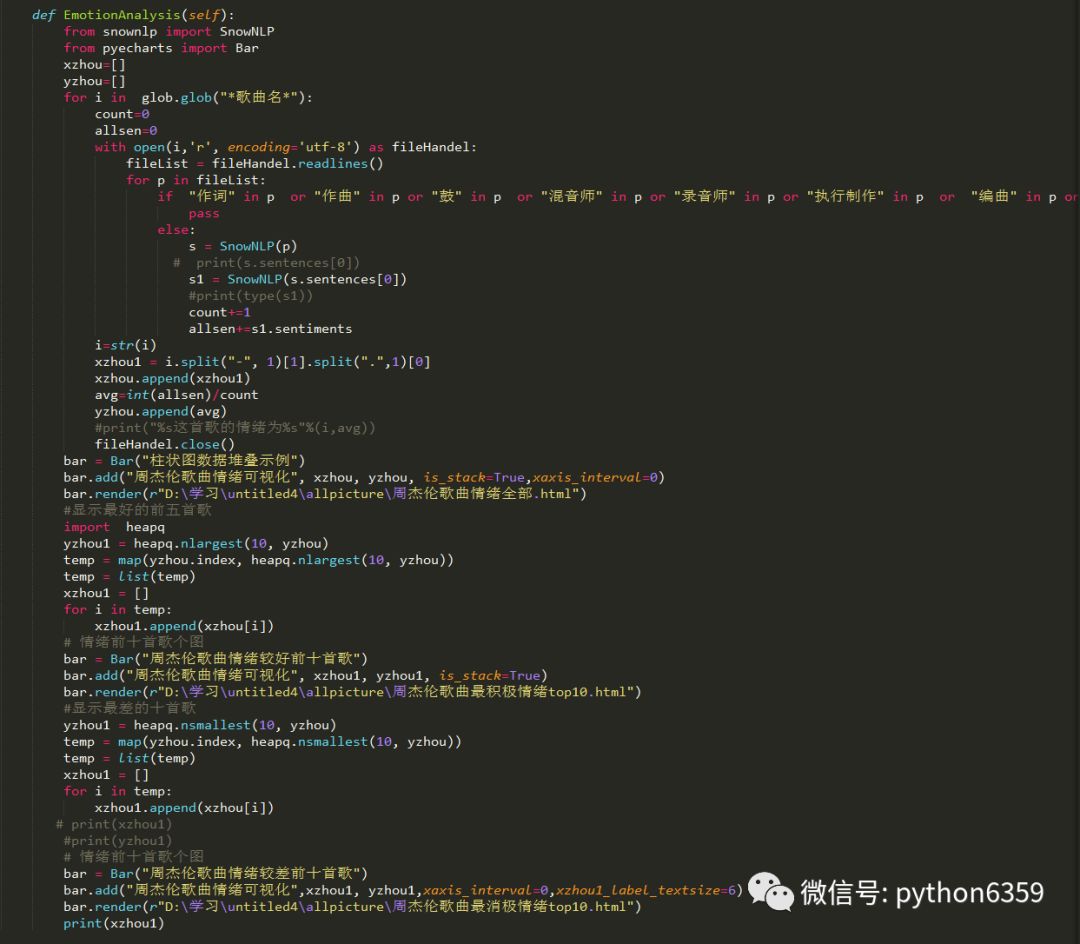
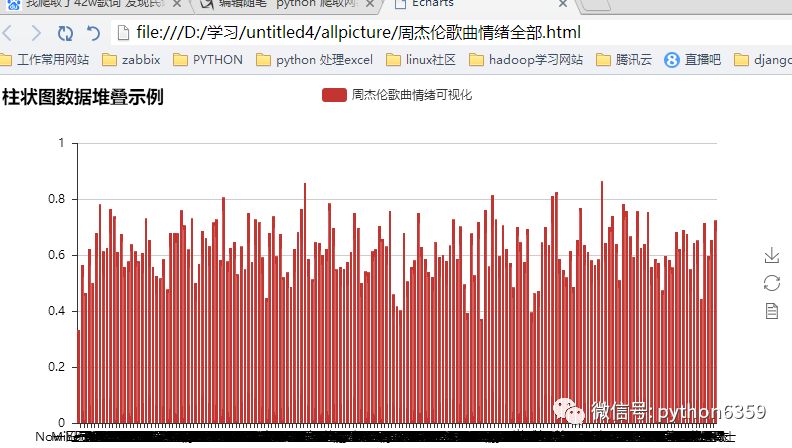
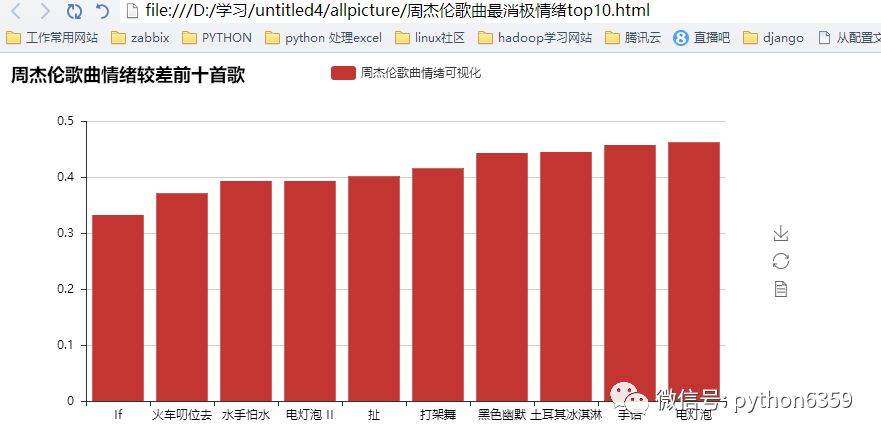
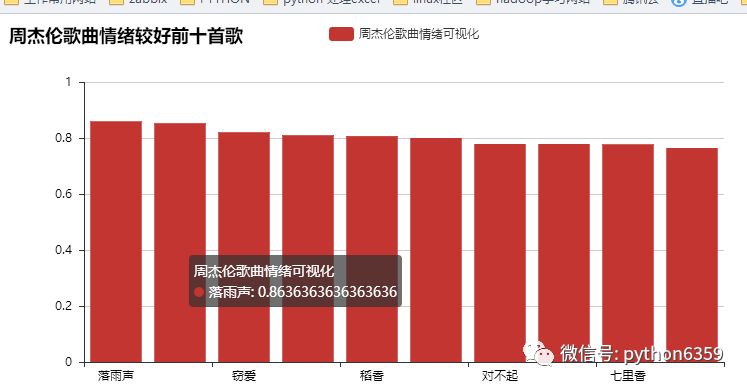
下面我们对周杰伦歌曲进行情绪化分析
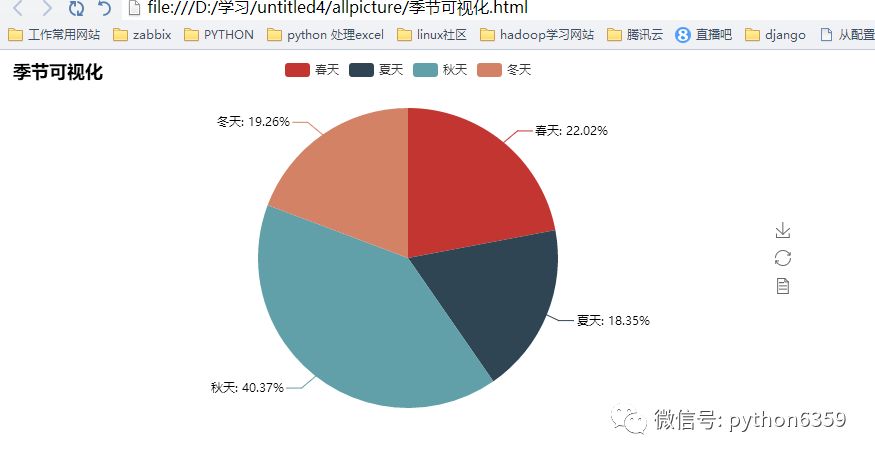
下面完成数据词频各种分析
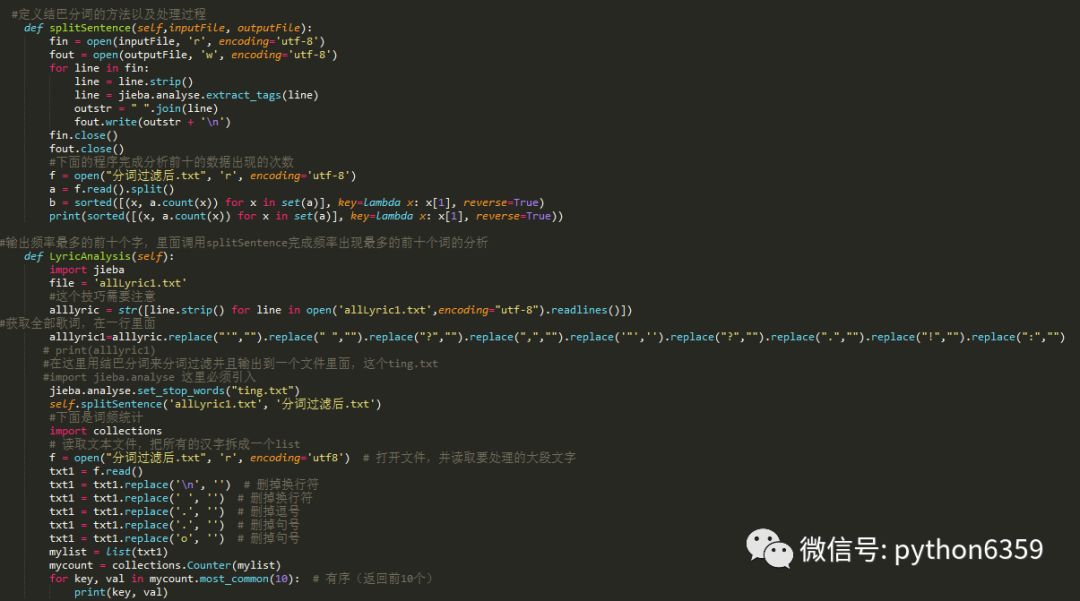
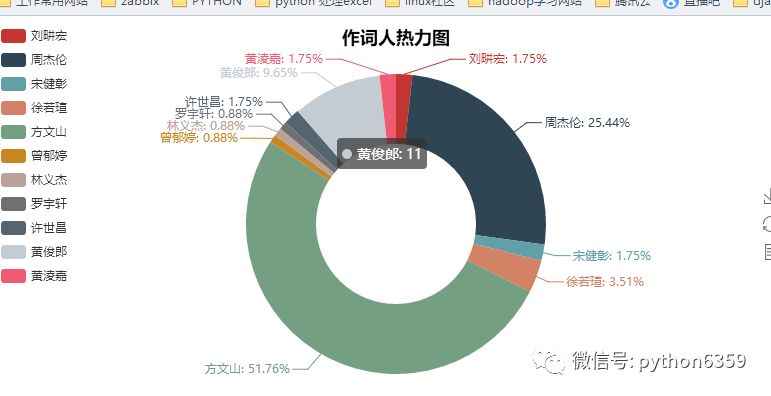
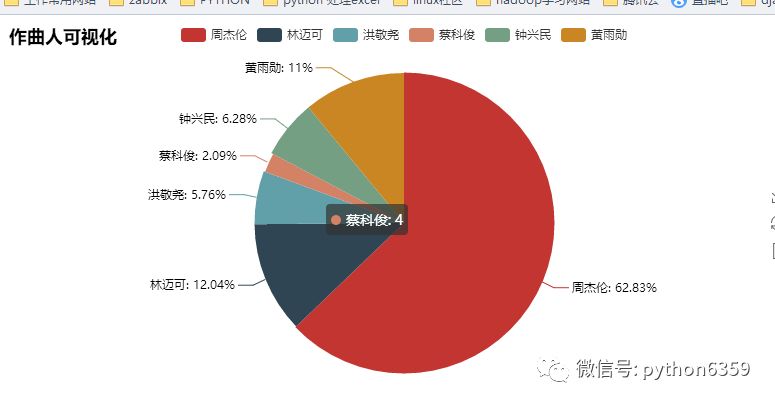
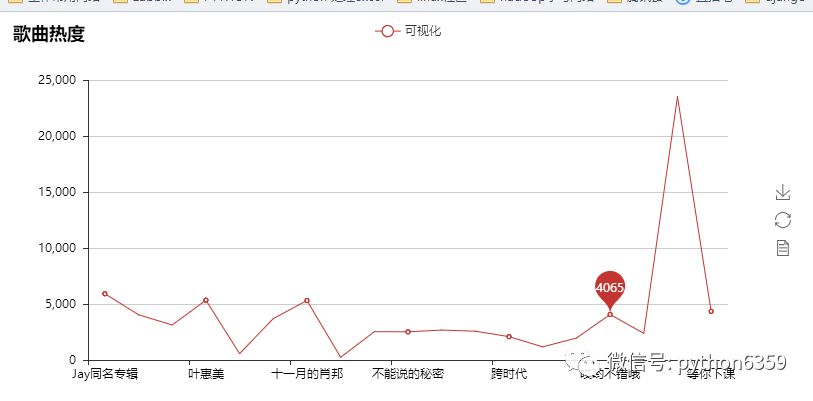
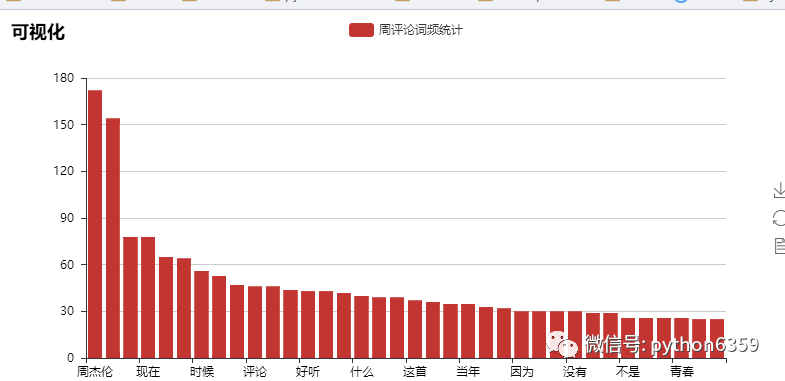
我们来看下结果



作者:zfno11
源自:www.cnblogs.com/ZFBG/p/8947541.html











