点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


机器学习是技术爱好者中高度关注的领域。作为人工智能(AI)的一个分支,它基本上是一种算法或模型,可以通过“学习”来改善自身,因此变得越来越精通执行其任务。机器学习的应用正在迅速发展,已迅速成为医学,电子商务,银行等不同领域不可或缺的一部分。今天,我们将把机器学习分解为一个过程,并了解从开始到实现的所有步骤。它的实际应用。

机器学习的过程将在下面列出的7个步骤中进行细分。为了说明每个步骤的重要性和功能,我们将使用一个简单模型的示例。该模型将负责区分苹果和橙子。机器学习能够胜任复杂任务。但是,为了以简单的方式解释该过程,以一个基本的例子来解释相关的概念。
为了开发我们的机器学习模型,我们的第一步将是收集可用于区分这两种成果的相关数据。可以使用不同的参数将水果分类为橙色或苹果。为简单起见,我们仅采用模型要利用的2个功能来执行其操作。第一个特征是水果本身的颜色,第二个特征是水果的形状。使用这些功能,我们希望我们的模型可以准确地区分两种水果。
颜色
| 形状
| 苹果还是橘子?
|
红色的
| 圆锥形
| 苹果
|
橙子
| 圆形的
| 橙子
|
需要一种机制来收集我们选择的两个功能的数据。例如,为了收集有关颜色的数据,我们可以使用光谱仪,对于形状数据,我们可以使用水果的图片,以便可以将它们视为2D图形。为了收集数据,我们将尝试获取尽可能多的不同类型的苹果和橙子,以便为我们的功能创建各种数据集。为此,我们可能会尝试在市场上寻找可能来自世界不同地区的橙子和苹果。
收集数据的步骤是机器学习过程的基础。选择错误的功能或专注于数据集的有限类型条目等错误可能会使模型完全失效。这就是为什么当收集数据时必须考虑必要的原因的原因,因为在此阶段所犯的错误只会随着我们进行到后续阶段而扩大。
一旦我们收集了这两个功能的数据,下一步就是准备数据以供进一步使用。此阶段的重点是识别并最小化我们针对这两个功能的数据集中的任何潜在偏差。首先,我们将随机化这两个水果的数据顺序。这是因为我们不希望订单与模型的选择有任何关系。此外,我们将检查我们的数据集是否偏向某个特定水果。这又将有助于识别和纠正潜在的偏见,因为这将意味着该模型将能够正确地识别一种水果,但可能会与另一种水果抗争。
数据准备的另一个主要组成部分是将数据集分为两部分。较大的部分(约80%)将用于训练模型,而较小的部分(约20%)用于评估。这很重要,因为在培训和评估中使用相同的数据集将无法公平评估模型在实际场景中的性能。除了拆分数据外,还需要采取其他措施来完善数据集。这可能包括删除重复的条目,丢弃不正确的读数等。
为模型准备充分的数据可以提高其效率。它可以帮助减少模型的盲点,从而提高预测的准确性。因此,有意义的是审议和检查你们的数据集,以便可以对其进行微调以产生更好和有意义的结果。
一旦完成了以数据为中心的步骤,选择模型类型就是我们的下一个行动方案。由数据科学家开发的各种现有模型可以用于不同的目的。这些模型在设计时考虑了不同的目标。例如,某些模型更适合处理文本,而另一种模型可能更适合处理图像。关于我们的模型,简单的线性回归模型适用于区分水果。在这种情况下,水果的类型将是我们的因变量,而水果的颜色和水果的形状将是两个预测变量或自变量。
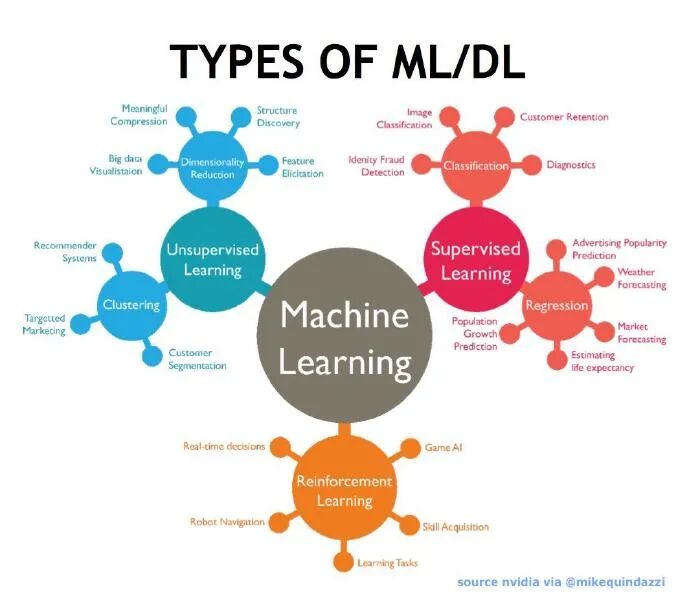
在我们的示例中,模型选择非常简单。在更复杂的情况下,我们需要做出与预期结果相匹配的选择。可以在3大类中探索机器学习模型的选项。第一类是监督学习模型。在这样的模型中,结果是已知的,因此我们不断改进模型本身,直到我们的输出达到所需的精度水平。为我们的水果模型选择的线性回归模型是监督学习的一个例子。如果结果未知,我们需要分类,则使用第二类,即无监督学习。无监督学习的示例包括K-means和Apriori算法。第三类是强化学习。它着重于学习在反复试验的基础上做出更好的决策。它们通常在商业环境中使用。马尔可夫的决策过程就是一个例子。
机器学习过程的核心是模型的训练。大量的“学习”在此阶段完成。在这里,我们使用分配给训练的数据集的一部分来教我们的模型来区分这两种成果。如果我们用数学术语查看模型,则输入(即我们的2个要素)将具有系数。这些系数称为特征权重。也将涉及一个常数或y截距。这称为模型的偏差。确定其值的过程是反复试验的。最初,我们为它们选择随机值并提供输入。将获得的输出与实际输出进行比较,并通过尝试不同的权重和偏差值将差异最小化。
培训需要耐心和实验。知道将在其中实施模型的领域的知识也很有用。例如,如果将机器学习模型用于识别保险公司的高风险客户,则由于可以在迭代过程中进行更多有根据的猜测,因此有关保险行业运作方式的知识将加快培训过程。如果该模型开始成功地发挥作用,那么培训将证明是非常有益的。这相当于孩子学习骑自行车的时间。最初,他们可能会摔倒多次,但过了一会儿,他们会更好地掌握过程,并能够在骑自行车时对不同情况做出更好的反应。
在训练好模型之后,需要对其进行测试,以查看其在现实环境中能否正常运行。这就是为什么将用于评估而创建的数据集的一部分用于检查模型的熟练程度的原因。这会将模型置于一个场景中,在该场景中遇到的情况并非其训练的一部分。在我们的案例中,这可能意味着尝试确定该模型中全新的苹果或橙子的类型。但是,通过训练,该模型应具有足够的能力来推断信息并确定该水果是苹果还是橙子。
在商业应用中,评估变得非常重要。评估使数据科学家可以检查他们是否设定了要实现的目标。如果结果不令人满意,则需要重新检查先前的步骤,以便找出并找出模型性能不佳的根本原因。如果评估未正确完成,则该模型可能无法出色地实现其所需的商业目的。这可能意味着设计和销售模型的公司可能会失去与客户的良好信誉。这也可能会损害公司的声誉,因为在信任公司关于机器学习模型的敏锐度时,未来的客户可能会犹豫不决。因此,评估模型对于避免上述不良影响至关重要。
如果评估成功,则进入超参数调整步骤。此步骤试图改善在评估步骤中获得的积极结果。对于我们的示例,我们将看看是否可以使我们的模型在识别苹果和橙子方面更加出色。我们可以采用不同的方法来改进模型。其中之一是重新训练步骤,并使用训练数据集的多次扫描来训练模型。这可能会导致更高的准确性,因为训练的持续时间越长,暴露越多,并改善了模型的质量。解决该问题的另一种方法是优化提供给模型的初始值。随机初始值通常会因反复试验逐渐完善而产生较差的结果。然而,如果我们可以提出更好的初始值,或者使用分布而不是值来启动模型,那么我们的结果可能会更好。我们还可以使用其他参数来完善模型,但是该过程比逻辑过程更直观,因此没有确定的方法。
自然地,出现一个问题,当模型实现其目标时,为什么我们首先需要进行超参数调整?这可以通过查看基于机器学习的服务提供商的竞争性质来回答。客户寻求机器学习模型来解决各自的问题时,可以从多个选项中进行选择。但是,它们更有可能被产生最准确结果的方法所吸引。这就是为什么要确保机器学习模型的商业成功,超参数调整是必不可少的步骤。
机器学习过程的最后一步是预测。在此阶段,我们认为模型已准备就绪,可以用于实际应用。我们的水果模型现在应该能够回答给定的水果是苹果还是橙子的问题。该模型不受人为干扰,并根据其数据集和训练得出自己的结论。该模型所面临的挑战仍然是在不同的相关场景下其性能是否能胜过或至少与人类判断相匹配。
预测步骤是最终用户在各自行业中使用机器学习模型时看到的内容。这一步凸显了为什么许多人认为机器学习是各个行业的未来。复杂但执行良好的机器学习模型可以改善其各自所有者的决策过程。做出决定时,人类只能处理一定数量的数据和相关因素。另一方面,机器学习模型可以处理和链接大量数据。这些链接使模型可以获得独特的见解,如果采用通常的手动方法,则可能无法发现这些见解。结果,宝贵的人力资源从处理信息然后做出决定的负担中解放出来。
借助机器学习,我们可以确定如何区分苹果和橘子,尽管听起来可能并不令人印象深刻,但是对于大多数机器学习模型而言,我们采取的步骤都是相同的。随着机器学习的发展和AI的普遍发展,该标准将来可能会改变,但是下次需要进行ML项目时,请记住这些标准:
收集数据
准备该数据
选择模型
训练
评估
超参数调整
预言
— — 完 — —
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












