作者|机器之心编辑部
来源|机器之心
在机器学习领域里有一句俗话:「Attention is all you need」,通过注意力机制,谷歌提出的 Transformer 模型引领了 NLP 领域的大幅度进化,进而影响了 CV 领域,甚至连论文标题本身也变成了一个梗,被其后的研究者们不断重新演绎。技术潮流总有变化的时候——到了 2021 年,风向似乎变成了多层感知机(MLP)。近日,谷歌大脑 Quoc Le 等人的一项研究对注意力层的必要性提出了质疑,并提出了一种具有空间门控单元的无注意力网络架构 gMLP,在图像分类和掩码语言建模任务上均实现了媲美 Transformer 的性能表现。
最近一段时间,多层感知机 MLP 成为 CV 领域的重点研究对象。谷歌原 ViT 团队提出了一种不使用卷积或自注意力的 MLP-Mixer 架构,并且在设计上非常简单,在 ImageNet 数据集上也实现了媲美 CNN 和 ViT 的性能。接着,清华大学图形学实验室 Jittor 团队提出了一种新的注意机制「External Attention」,只用两个级联的线性层和归一化层就可以取代现有流行的学习架构中的「Self-attention」。同一时期,清华大学软件学院丁贵广团队提出的结合重参数化技术的 MLP 也取得了非常不错的效果。Facebook 也于近日提出了一种用于图像分类的纯 MLP 架构,该架构受 ViT 的启发,但更加简单:不采用任何形式的注意力机制,仅仅包含线性层与 GELU 非线性激活函数。MLP→CNN→Transformer→MLP 似乎已经成为一种大势所趋。谷歌大脑首席科学家、AutoML 鼻祖 Quoc Le 团队也将研究目光转向了 MLP。在最新的一项研究中,该团队提出了一种仅基于空间门控 MLP 的无注意力网络架构 gMLP,并展示了该架构在一些重要的语言和视觉应用中可以媲美 Transformer。
研究者将 gMLP 用于图像分类任务,并在 ImageNet 数据集上取得了非常不错的结果。在类似的训练设置下,gMLP 实现了与 DeiT(一种改进了正则化的 ViT 模型)相当的性能。不仅如此,在参数减少 66% 的情况下,gMLP 的准确率比 MLP-Mixer 高出 3%。这一系列的实验结果对 ViT 模型中自注意力层的必要性提出了质疑。他们还将 gMLP 应用于 BERT 的掩码语言建模(MLM)任务,发现 gMLP 在预训练阶段最小化困惑度的效果与 Transformer 一样好。该研究的实验表明,困惑度仅与模型的容量有关,对注意力的存在并不敏感。随着容量的增加,研究者观察到,gMLP 的预训练和微调表现的提升与 Transformer 一样快。gMLP 的有效性,视觉任务上自注意力和 NLP 中注意力机制的 case-dependent 不再具有优势,所有这些都令研究者对多个领域中注意力的必要性提出了质疑。总的来说,该研究的实验结果表明,自注意力并不是扩展 ML 模型的必要因素。随着数据和算力的增加,gMLP 等具有简单空间交互机制的模型具备媲美 Transformer 的强大性能,并且可以移除自注意力或大幅减弱它的作用。
https://arxiv.org/pdf/2105.08050.pdf具有空间门控单元(Spatial Gating Unit, SGU)的 gMLP 架构示意图如下所示,该模型由堆叠的 L 块(具有相同的结构和大小)组成。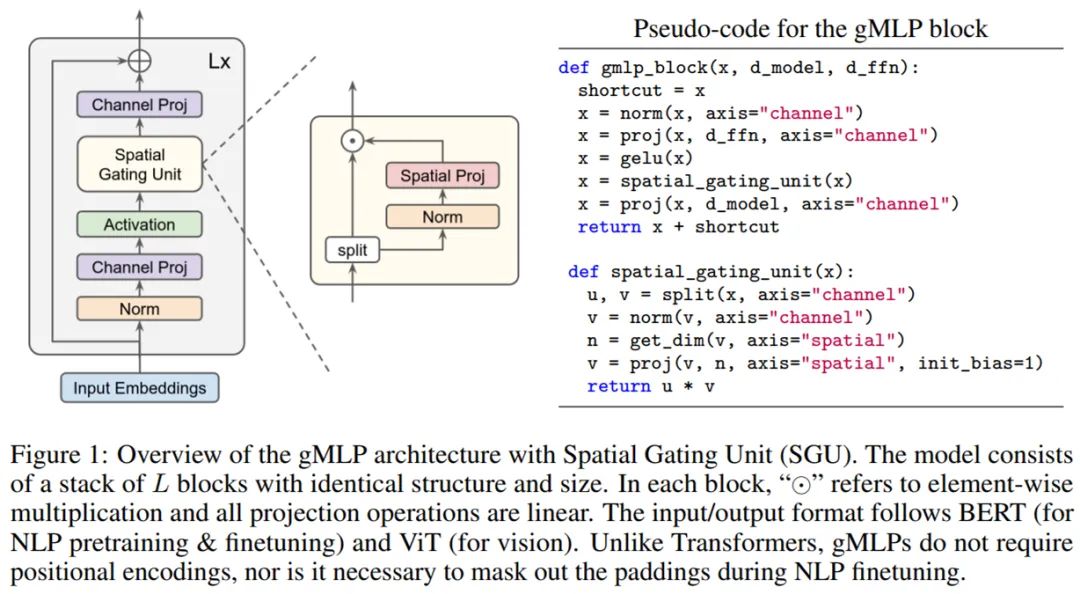

上图公式中的关键组件是 s(·),这是一个用于捕获空间交互的层。所以,研究者需要设计一个能够捕获 token 间复杂空间交互的强大 s(·)。L 块的整体布局受到了反转瓶颈(inverted bottleneck)的启发,将 s(·) 定义为一个空间深度卷积(spatial depthwise convolution)。值得注意的是,不同于 Transformer,gMLP 模型无需位置嵌入,因为这类信息将在 s(·) 中被捕获。并且,gMLP 模型使用与 BERT 和 ViT 完全相同的输入和输出格式。为了实现跨 token 的交互,s(·) 层必须要包含空间维度上的收缩变换。最简单的方法是线性投影:
在该论文中,研究者将空间交互单元定义为其输入和空间转换输入的乘积:
研究者在没有额外数据的 ImageNet 数据集上将 gMLP 应用于图像分类任务,以衡量它在计算机视觉领域的性能。他们将三个 gMLP 变体模型(gMLP-Ti、gMLP-S 和 gMLP-B)与其他基于原始 Transformer 的模型进行了对比,包括 ViT、DeiT 以及其他几个有代表性的卷积网络。下表 1 给出了上述三个 gMLP 变体的参数、FLOPS 和生存概率(Survival Probability):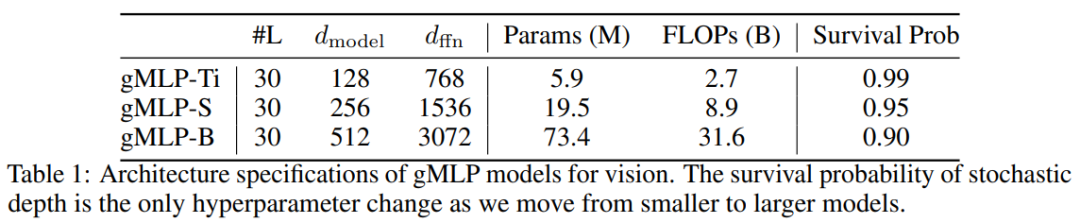
下表 2 为不同模型的对比结果。可以看到,gMLP 的 Top-1 准确率与 DeiT 模型相当。这一结果表明,无注意力的模型在图像分类任务上具有与 Transformer 一样的数据高效性。此外,gMLP 可以媲美原始 Transformer,性能仅落后现有性能最佳的 ConvNet 模型和混合注意力模型。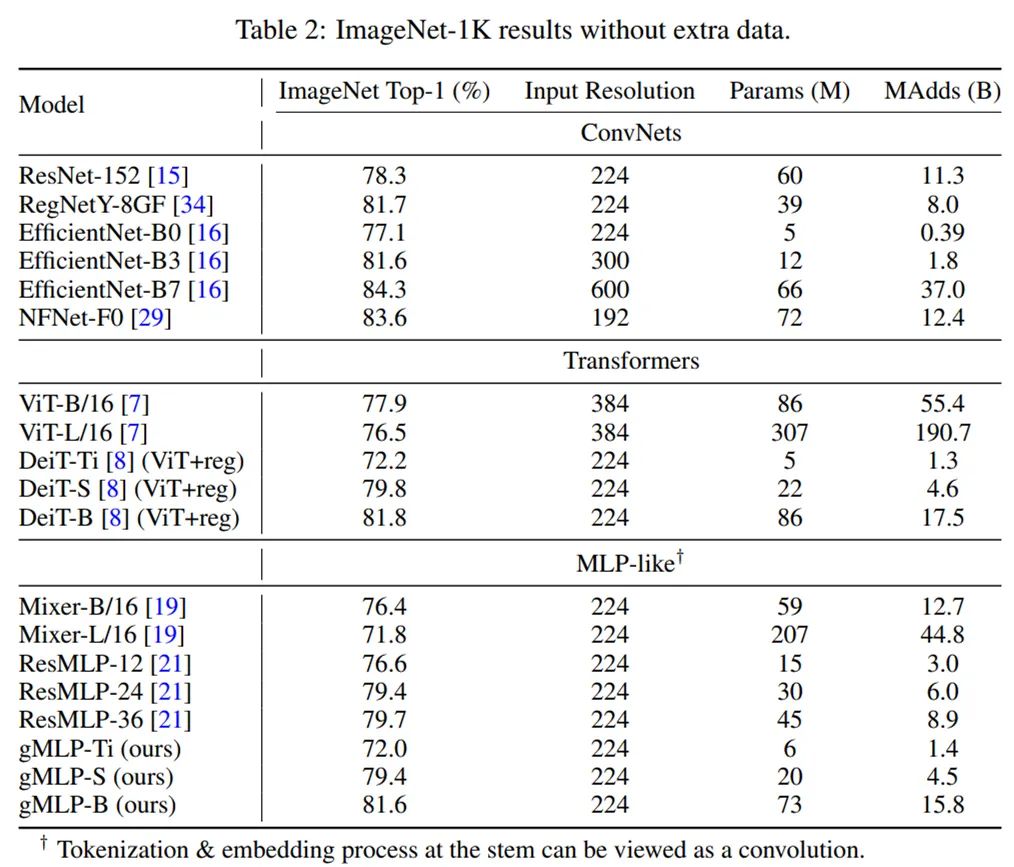
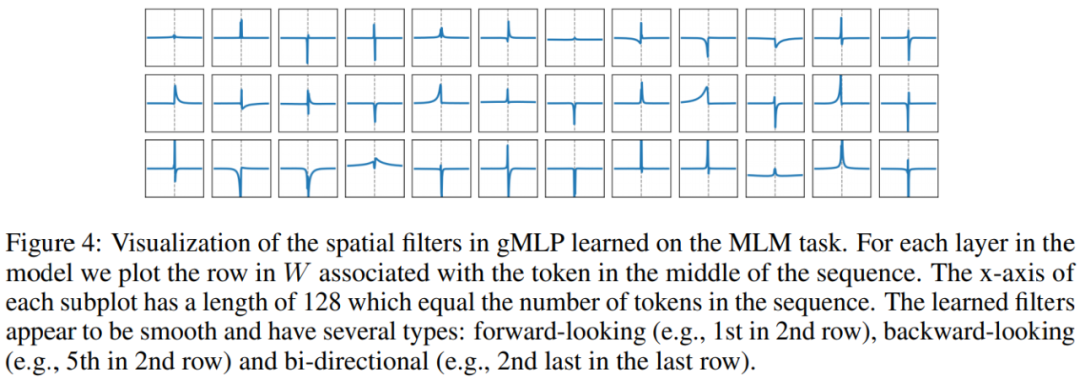
MLP-like 模型中的 Tokenization 和嵌入过程可视作一种卷积。研究者对不同模型在掩码语言建模任务(MLM)上的性能进行了实验研究。消融实验:gMLP 中门控(gating)对 BERT 预训练的重要性具有 Transformer 架构和可学得绝对位置嵌入的 BERT;
具有 Transformer 架构和 T5-style 可学得相对位置偏差的 BERT;
同上,但在 softmax 内部移除了所有与内容有关的项,并仅保留相对位置偏差。
在下表 3 中,他们将这些基准 BERT 模型与类似大小、不同版本的 gMLP 进行了对比。需要注意,表格最后一行 Multiplicative, Split 即上文方法部分描述的空间门控单元(SGU)。可以看到,SGU 的困惑度低于其他变体,具有 SGU 的 gMLP 得到了与 BERT 相当的困惑度。
在下表 4 中,研究者探究了随着模型容量的增长,Transformer 与 gMLP 模型的扩展性能。结果表明,在模型容量相当时,足够深度的 gMLP 在困惑度上的表现能够赶上甚至优于 Transformer(困惑度越低,模型效果越好)。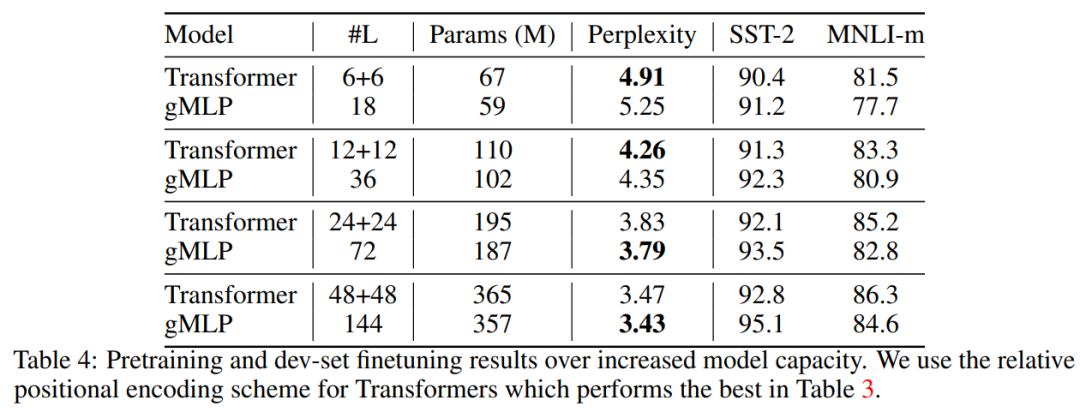
gMLP 和 Transformer 这两类不同架构模型的困惑度 - 参数关系大体符合幂次定律(如下图 5 左)。此外,从图 5 中还可以看到,尽管在预训练和微调之间存在特定于架构的差异,但 gMLP 和 Transformer 在微调任务上均表现出了相当的扩展性。这表明,下游任务上模型的可扩展性与自注意力的存在与否无关。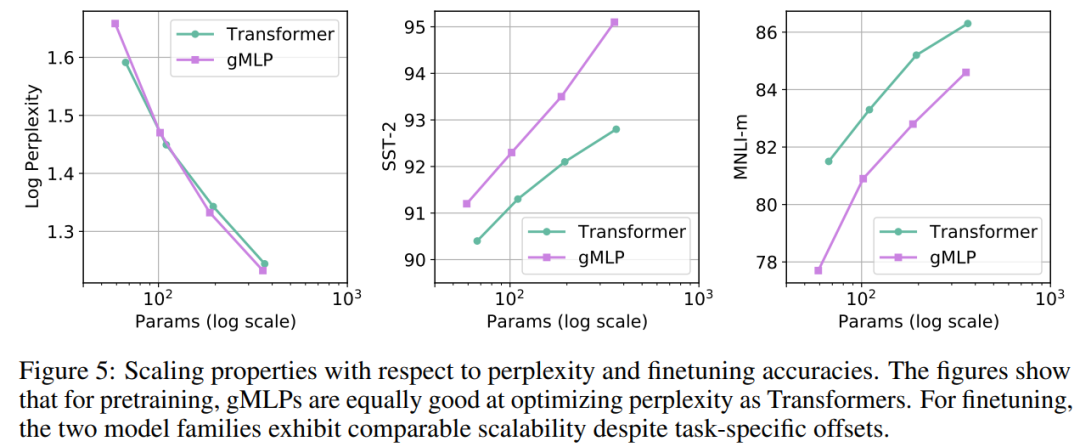
消融实验:tiny 注意力在 BERT 微调中的作用为了脱离注意力的影响,研究者尝试了一个混合模型,其中将一个 tiny 自注意力块与 gMLP 的门控组件相连。他们将这个混合模型称为 aMLP(a 表示注意力)。下图 6(左)为具有 tiny 自注意力块的混合模型,图 6(右)为 tiny 注意力模块的伪代码
如下表 7 所示,研究者通过预训练困惑度和微调度量指标之间的校正曲线探究了 Transformer、gMLP 和 aMLP 的可迁移性。可以看到,就 SST-2 准确率而言,gMLP 的迁移效果优于具有注意力机制的 Transformer 模型,但在 MNLI 语料库上的表现较差,但在加了 tiny 注意力(即 aMLP)之后就缩小了差距。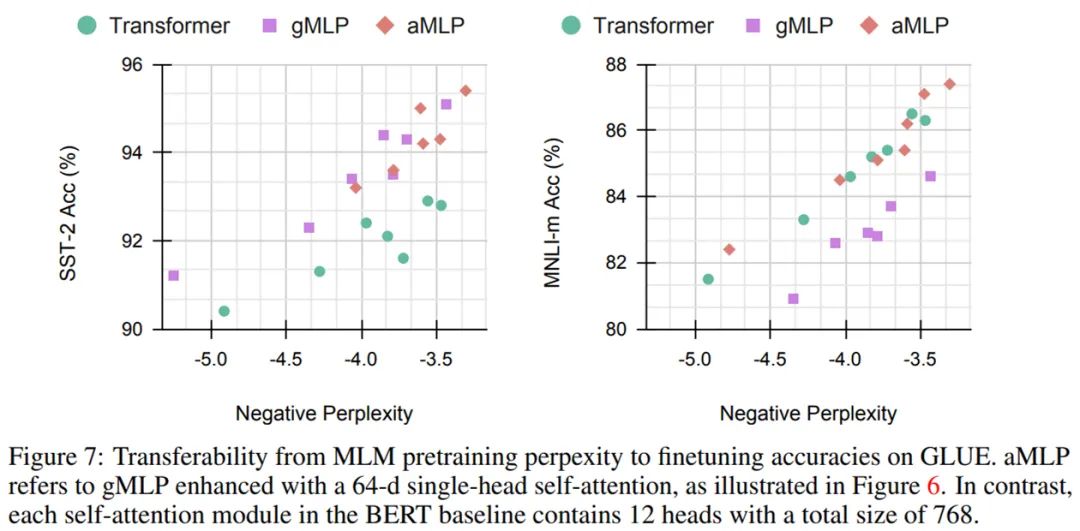
研究者展示了完整 BERT 设置下预训练和微调的结果。他们使用了完整的英语 C4 数据集,并采用了批大小为 256、最大长度为 512 和 100 万步训练的常用掩码语言建模设置。下表 5 为 BERT、gMLP 和 aMLP 模型的规格: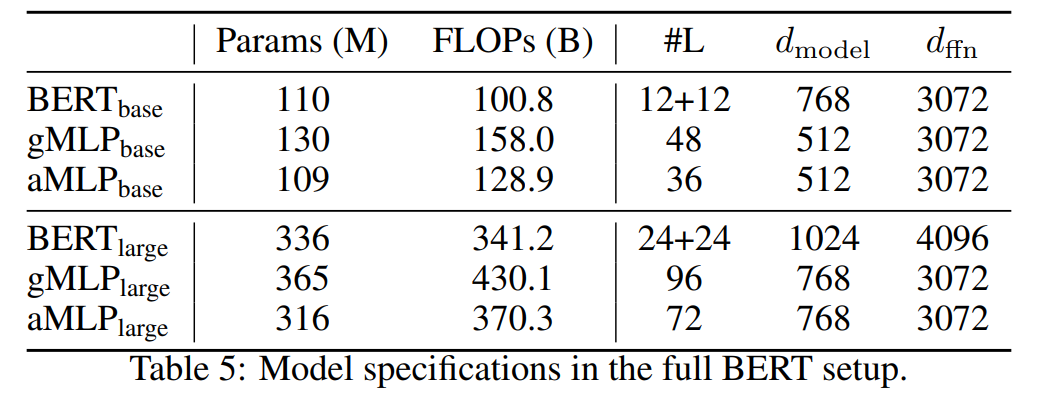
如下表 6 所示,主要结果与前文结论保持一致,gMLP 在困惑度指标上可以媲美 BERT,模型规模越大结果更明显。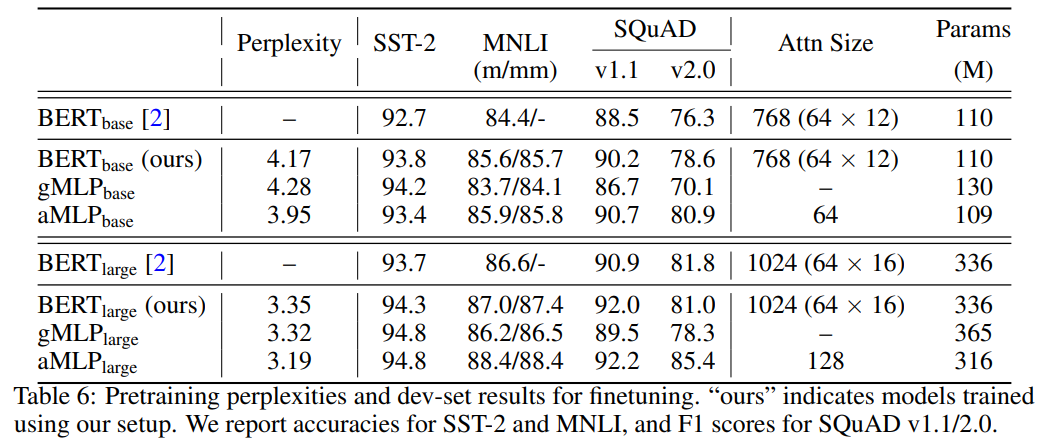
不过,对于这项研究中提出的基于空间门控单元的 gMLP 架构,有网友质疑:「gMLP 的整体架构难道不是更类似于 transformer 而不是原始 MLP 吗?」
也有知乎网友质疑到:「空间门控单元不就是注意力吗?」另一网友则表示:「不算是注意力可能是因为没有 softmax。」
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。









