摄像头传统视觉技术在算法上相对容易实现,因此已被现有大部分车厂用于辅助驾驶功能。但是随着自动驾驶技术的发展,基于深度学习的算法开始兴起,本期小编就来说说深度视觉算法相关技术方面的资料,让我们一起来学习一下吧。

深度学习(DL,Deep Learning)是一类模式分析方法的统称,属于机器学习(ML,MachineLearning)领域中一个新的研究方向。深度学习通过学习样本数据的内在规律和表示层次,能够让机器像人一样具有分析、学习能力,可识别文字、图像和声音等数据,从而实现人工智能(AI,Artificial Intelligence)。
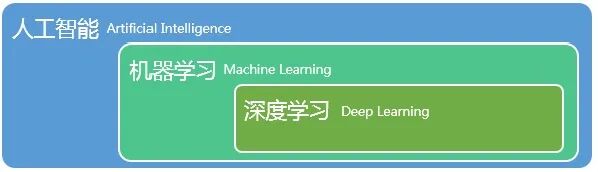
图为:(人工智能、机器学习、深度学习)关系图
很多小伙伴们可能了解汽车想要实现自动驾驶,感知、决策与控制这三大系统是缺一不可的。其中,感知被我们放在了首位,因为车辆首先需要实时了解自车与现实世界三维变化的关系,即精准了解自车与周围人、车、障碍物及道路要素等位置关系和变化。深度学习算法有效提升了摄像头、激光雷达等传感器的“智能”水平,这很大程度上也决定了自动驾驶汽车在复杂路况上的可靠度,因此深度学习的应用便成为了关键所在。另外汽车的感知传感器虽然有多种,但是摄像头是唯一一个通过图像可以感知现实世界的传感器,通过深度学习可以快速提升图像的识别能力,让我们的行驶更加安全。

有看过小编上期写的关于摄像头传统视觉算法的小伙伴们就要问了,既然传统摄像头视觉算法已经可以使用,为什么还要研究深度学习算法呢?
因为传统视觉算法有着自身的一些瓶颈,无论单目摄像头还是多目摄像头,传统视觉算法都是基于人为特征提取得到样本特征库去识别计算。当自动驾驶车辆行驶过程中如发现特征库没有该样本或特征库样本不准确,都会导致传统视觉算法无法识别,另外传统视觉算法还有在复杂场景下分割不佳等情况。因此,基于人为特征提取的传统视觉算法具有性能瓶颈,无法完全满足自动驾驶的目标检测。
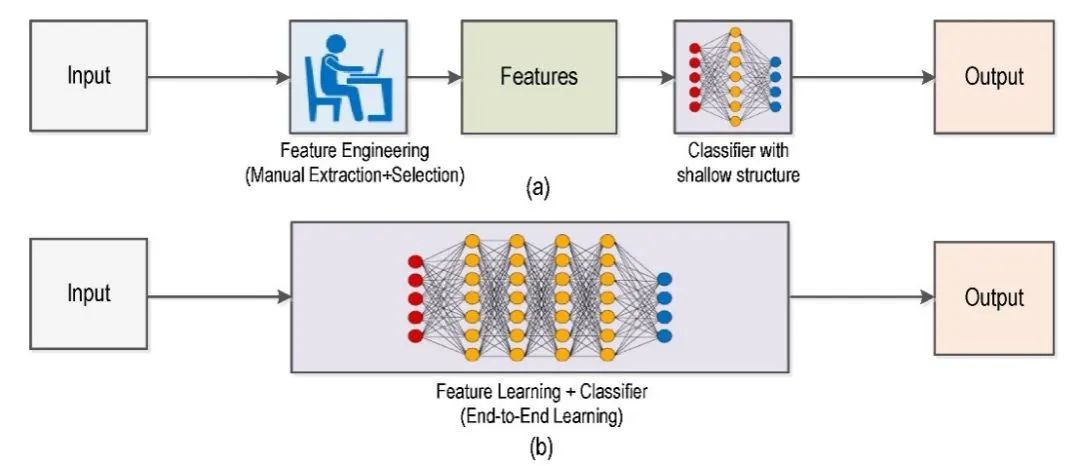
图片来源:论文《DeepLearning vs. Traditional Computer Vision》
而摄像头深度学习视觉算法的特征提取优势是基于神经网络算法,它模拟人的神经网络,可将自动驾驶上摄像头输入的图像(甚至激光雷达的点云)等信息进行语义分割,有效解决了传统视觉算法对复杂的实际场景分割或样本特征库不佳的情况,让图像分类、语义分割、目标检测和同步定位与地图构建(SLAM)等任务上获得更高的准确度。
接下来为了便于大家理解,小编先讲讲深度学习的神经网络是什么?它是如何帮助摄像头完成图像识别等视觉计算的。它比传统摄像头的视觉算法又好在哪里?
深度学习大家看字面就很容易发现它是由“深度”+“学习”来完成的。“深度”就是模仿大脑的神经元之间传递处理信息的模式,其模型结构包括输入层(inputlayer),隐藏层(Hiddenlayer)和输出层(outputlayer),其中输入层和输出层一般只有1层,而隐藏层(或中间层)它往往有5层、6层,甚至更多层,多层隐层(中间层)节点被称为深度学习里的“深度”;“学习”就是进行“特征学习”(featurelearning)或“表示学习”(representationlearning),也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,利用大数据来学习和调优,建立起适量的神经元计算节点和多层运算层次结构,尽可能的逼近现实的关联关系,从而使特征分类或预测更容易。
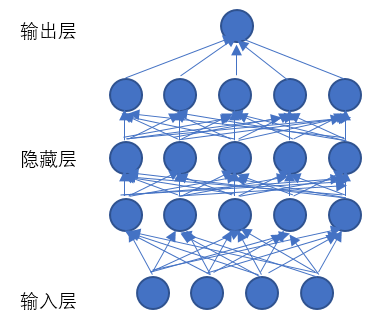
图为:神经网络结构示意图
上面的内容太抽象了,简单来讲神经网络有三层:
输入:输入层每个神经元对应一个变量特征,输入层的神经元相当于装有数字的容器
输出:输出层,回归问题为一个神经元,分类问题为多个神经元
参数:网络中所有的参数,即中间层(或隐藏层)神经元的权重和偏置,每一个神经元代表该层神经网络学习到的特征
这里大家只需要记住神经网络不管规模的大小,都是由一个一个单神经元网络堆叠起来的。
不好理解也没有关系,下面小编举个例子来说明一下吧。
假设我们要买房子,那么买房子我们所能承受的最终成交价格就是输出层;
输入层可能会有很多原始特征(即购房因素,如房屋面积,房间个数,附近学校个数,学校教育质量,公共交通,停车位);
中间层(或隐藏层)的神经元就是我们可以学习到的特征,如家庭人数,教育质量,出行
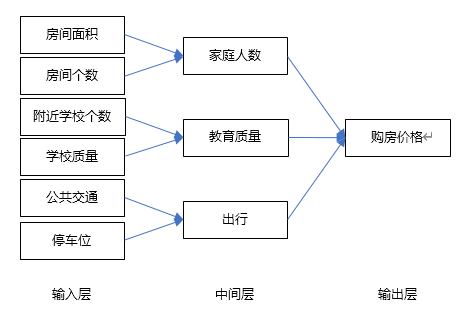
我们搜集的输入特征数据越多,就能得到一个更为精细的神经网络。而且随着输入层的原始特征神经元个数的增多,中间层就能从原始特征中学到足够多的、更为细致的不同含义组合特征,比如房屋面积和房间数量能表示容纳家庭人数,学校数量和学校质量表示教育质量。通过每个神经元对应的特征分类、统计和计算,最终得到我们想要输出层“房价”。
那么对于摄像头的深度学习来说,输入层为摄像头获取的图像,图像对于摄像头深度学习算法来说可以看成是一堆数据流,那么这些数据流还可以分成更多原始特征,如图像各像素点的稀疏和密集、语义和几何信息,还包括颜色、明暗、灰度等;中间层将这些输入层的原始特征信息分类计算后,可识别出图像中包含的物体有哪些(如车道线、障碍物、人、车、红绿灯等),最终输出与自动驾驶车有关的物体的实时距离、大小、形状、红绿灯颜色等要素,帮助自动驾驶车辆完成实时感知周围环境识别、测距等功能。

图为:四维图新-摄像头视觉识别样例
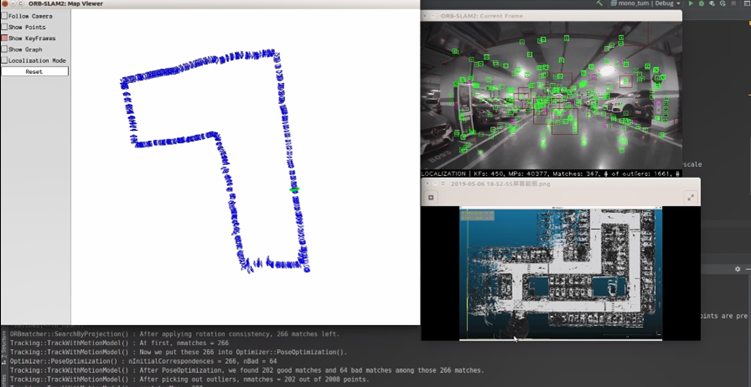
图为:四维图新-地下车库建图和实时重定位系统
以上我们可以看出,基于神经网络的摄像头视觉深度学习算法比基于人为特征提取的传统摄像头视觉算法要好用的多。因此目前主流的摄像头视觉算法,都会使用深度学习去解决自动驾驶车对于图像分类、图像分割,对象检测、多目标跟踪、语义分割、可行驶区域、目标检测和同步定位与地图构建(SLAM)、场景分析等任务的准确率、识别率及图像处理速度等,深度学习视觉算法也让自动驾驶车快速量产落地成为可能。

自动驾驶摄像头传感器所使用的深度学习视觉算法常用的有以下三种:
(1)基于卷积运算的神经网络系统,即卷积神经网络(CNN,ConvolutionalNeural Network)。在图像识别中应用广泛。
(2)基于多层神经元的自编码神经网络,包括自编码(Autoencoder)以及近年来受到广泛关注的稀疏编码(SparseCoding)。
(3)以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN,DeepBelief Networks)。

图为:深度学习一般流程
虽然讲了这么多,究竟基于神经网络的深度学习算法是如何获得输入输出的,其实上面的案例和算法分类也只是帮助我们去简单理解深度学习的神经网络,事实上深度学习是一个“黑箱”。“黑箱”意味着深度学习的中间过程不可知,深度学习产生的结果不可控。实际上程序员们编程后的神经网络到底是如何学习,程序员们也不知道,只知道最终输出结果是利用“万能近似定理”(Universal approximation theorem)尽可能准确的拟合出输入数据和输出结果间的关系。所以,很多时候深度学习能很好的完成学习识别等任务,可是我们并不知道它学习到了什么,也不知道它为什么做出了特定的选择。知其然而不知其所以然,这可以看作是深度学习的常态,也是深度学习工作中的一大挑战。尽管如此,深度学习还是很好用滴!

当然,深度学习算法不仅仅可以用于自动驾驶摄像头方面的视觉感知,还可以用于语音识别、交通、医疗、生物信息等领域。
这里顺带说一句,作为四维图新而言,摄像头不仅是四维图新自动驾驶解决方案里的重要传感器,也是四维图新高精度地图采集的主要工具。而且在高精度地图采集和制图标注过程中,不仅为四维图新自动驾驶深度学习提供了海量的标注数据,还建立了四维图新自动驾驶各类场景仿真库,让四维图新基于深度学习的自动驾驶算法获得的结果更为准确、高效。

四维图新通过高精度地图采集车上搭载的高清摄像头、激光雷达等传感器,将采集到的数据加以处理,并通过高度的自动化平台进行绘制,从而为自动驾驶车感知、定位、规划、决策等模块提供重要支持。
目前四维图新高精度地图已经覆盖国内32万+公里高速公路以及10000+公里城市道路。
在自动驾驶仿真方面,依托大规模数据资源,形成参数化的场景模板,并具备静态场景生成与动态场景制作的场景库构建能力,为自动驾驶提供完备的仿真云平台能力和商用分析平台能力。
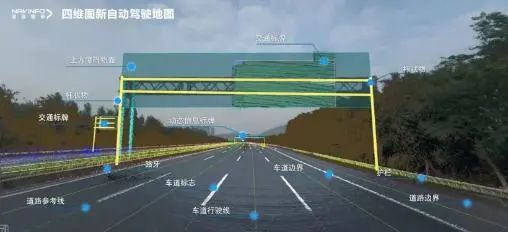
图为:四维图新-高速道路HD Map
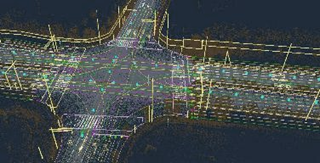
图为:四维图新-城市道路HD Map
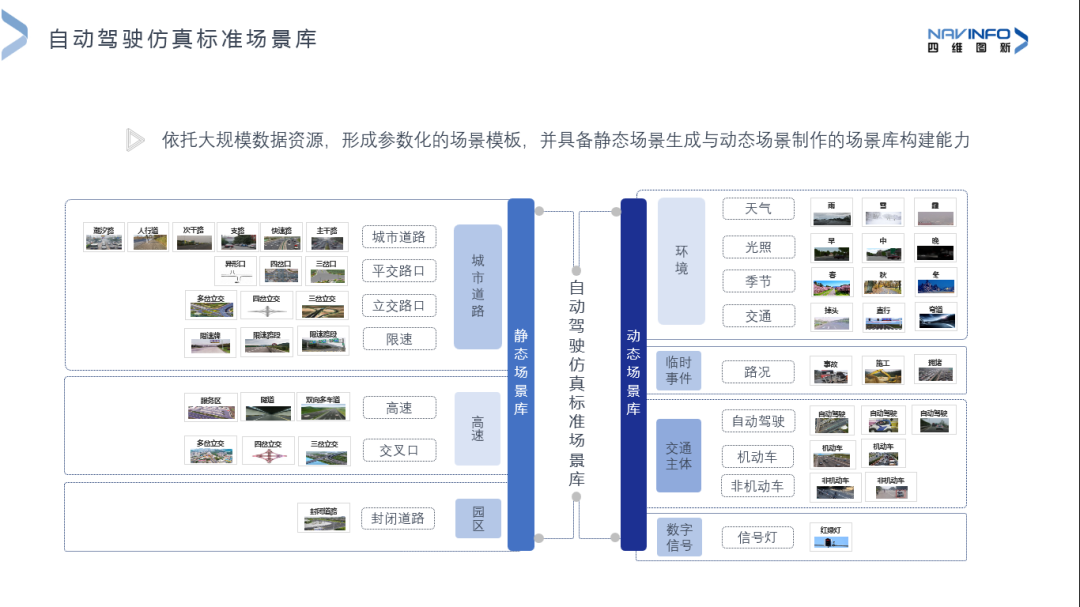
图为:四维图新-自动驾驶仿真标准场景库
如果你对本文感兴趣,请后台发送“知识星球”获取二维码,务必按照“姓名+学校/公司+研究方向”备注加入免费知识星球,免费下载pdf文档,和更多热爱分享的小伙伴一起交流吧!
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入免费星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享及合作方式:微信“920177957”(需要按要求备注) 联系邮箱:dianyunpcl@163.com,欢迎企业来联系公众号展开合作。










