
作者 | 琰琰
8月18日,VLDB 2021公布了今年的论文获奖情况,SFU王健楠教授及博士生团队(王笑盈,曲昌博,吴畏远)获得年度最佳EA&B论文奖。

VLDB (Very Large Data Base ),与 SIGMOD、ICDE 被公认为数据管理与数据库领域的三大国际顶尖学术会议。8月18日,VLDB 2021采用线上线下结合的方式在丹麦哥本哈根正式开幕。VLDB的研究论文分为三个类别,王健楠团队获得了实验、分析与基准(Experiment, Analysis and Benchmark ,EA&B)类别的最佳论文。
王健楠是SFU计算机系的副教授。他于2013 年在清华大学获得博士学位,2013 年 -2015 年间在加州大学伯克利分校AMPLab进行博士后阶段的研究工作。他领导开发的数据准备工具dataprep.ai 目前已经有近 20 万的下载量。
所获奖项包括加拿大计算机协会授予的杰出青年奖 (2020),IEEE授予的数据工程新星奖(2018),ACM SIGMOD 最佳演示奖(2016),CCF最佳博士论文奖(2013)以及Google PhD Fellowship (2011)。他为VLDB 2021副主编,将在VLDB 2023大会担任共同主席。
其本次获奖论文题目为“Are We Ready for Learned Cardinality Estimation"(《通过机器学习的基数估计技术成熟了吗?》),与腾讯周庆庆合著完成。

VLDB组委会认为,这篇研究工作概述了不同的基于学习的方法在数据库产品中应用的可能性及优缺点,几乎覆盖了实际使用环境中可能出现的情况。此外,该工作提出了可用于改善现有相关研究的方法,并进一步指出了未来需要的研究方向,为ML for DB研究领域的发展做出了重要贡献。
研究概要
近几年,机器学习以及深度学习方面技术的进步以及在其它领域内被成功应用的先例,让 ML for DB 这个课题变得越来越火,今年VLDB会议的Keynote,Workshop,Tutorial以及Session都在讨论这个话题。
王健楠告诉AI科技评论,基于学习的方法(Learned Methods)是数据库领域的热门研究方向,但是现有研究过于关注模型的准确度,而忽略了其在部署到实际数据库系统时可能会面临的问题。这篇论文希望扭转当前的研究重心,让大家关注“如何如何降低模型成本?如何提高模型更可信性?”等重要问题。
按照目前ML for DB课题的发展情况来看,5-10年之后要么是研究人员发现模型并不能被真正的使用在生产环境中,渐渐的失去对该课题的研究兴趣;要么是主流的数据库系统开始大规模采用机器学习模型,并大幅提升了系统性能。

要想将第二种情况变为现实,王健楠团队认为我们现在需要回答一个核心问题,即基于机器学习的方法是否已经可以使用在数据库产品中?如果不行,需要从哪些方面进行提升?
在本篇论文中,研究团队从基数估计模块入手,探究了基于机器学习的基数估计方法是否可用于数据库产品这个问题。基数估计 (Cardinality Estimation)是数据库优化器(optimizer)中非常重要的一个模块,该模块会向优化器提供查询(query)可能返回的行数,从而引导查询计划(query plan)的选择,并直接影响甚至决定查询的速度。
由于现有基数估计方法很难做到精确估计,有时甚至会引起较大误差,从而减缓查询速度,因此基数估计一直被称为数据库优化器的“阿喀琉斯之踵”(意为“致命要害”)。
目前采用机器学习或深度学习来预测基数的研究方法不在少数,并且这些方法在准确度上也展现了超越传统数据库中基数估计方法的极大潜能。
研究方法
在论文中,作者选择了5个先进且不同的基于学习的模型,通过实验评估了其在数据库产品应用的可能性、可能引发的问题,并进一步为数据库中除基数估计之外的其它模块应用机器学习提供参考。实验主要分成三个部分:
1、基于学习的方法是否适合静态环境?
静态环境是指数据库中的数据不进行更新的状态。作者首先评估了静态环境下,基于学习的基数估计方法与传统方法在准确度和效率(包括训练时间和推断时间)两个维度上的实验结果。
实验选取了3个广泛应用的数据库产品和6个常用以及最新的传统基数估计方法作为基准,并且选择了4个常用的且具有不同属性的数据集。通过研究现有工作中的SQL查询生成方法,作者提出了一个更能涵盖所有可能的查询生成框架,并通过它来生成实验所需要的训练和测试数据。
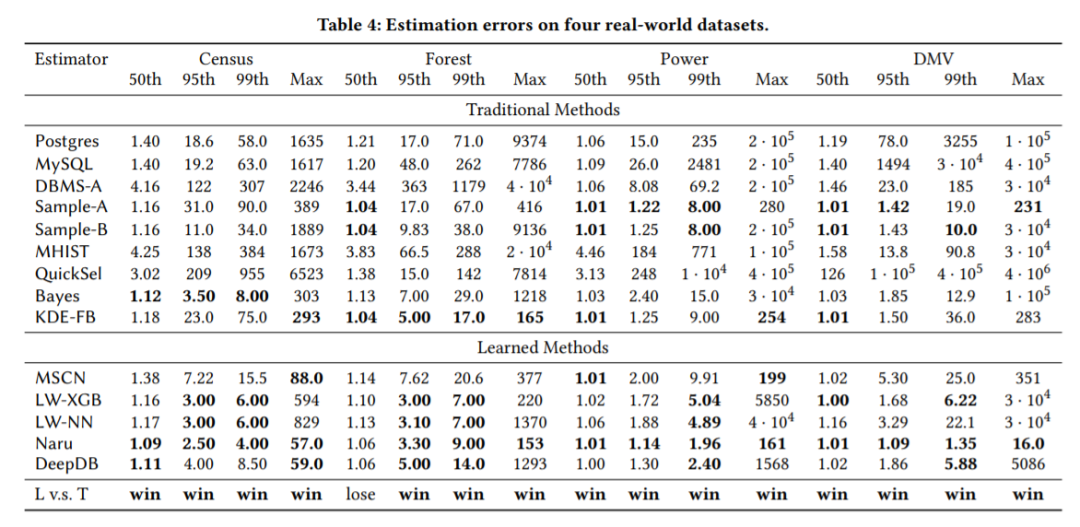 q误差比较结果
q误差比较结果
实验表明,学习的方法在几乎所有的数据库系统中都比传统方法的准确度更高,最好的学习的方法可以在最大q-误差指标上超过传统方法14x,在Census、Forest、Power和DMV数据集上,三个数据库系统上分别达到28x、51x、938x和1758x。
在所有学习的方法中,Naru最稳健、准确度最高,其最大误差均保持在200以内。
在训练时间和推理时间方面,这些高精度学习方法与DBMS产品进行了比较。如下图,三个DBMS都可以在1或2毫秒内完成整个过程,相较于拟合整个数据分布来估算基数的学习方法,通过回归模型的方法能够达到与DBMS相似或更好的查询效率。
DeepDB中的SPN模型在三个较大的数据集上需要大约25ms,在Census数据集中平均需要5ms。Naru的推理过程包括一个渐进式抽样机制,需要将模型运行数千次才能得到准确的结果。它的总时间对运行的设备很敏感,在GPU上需要5到15毫秒,CPU的速度可以慢20倍。
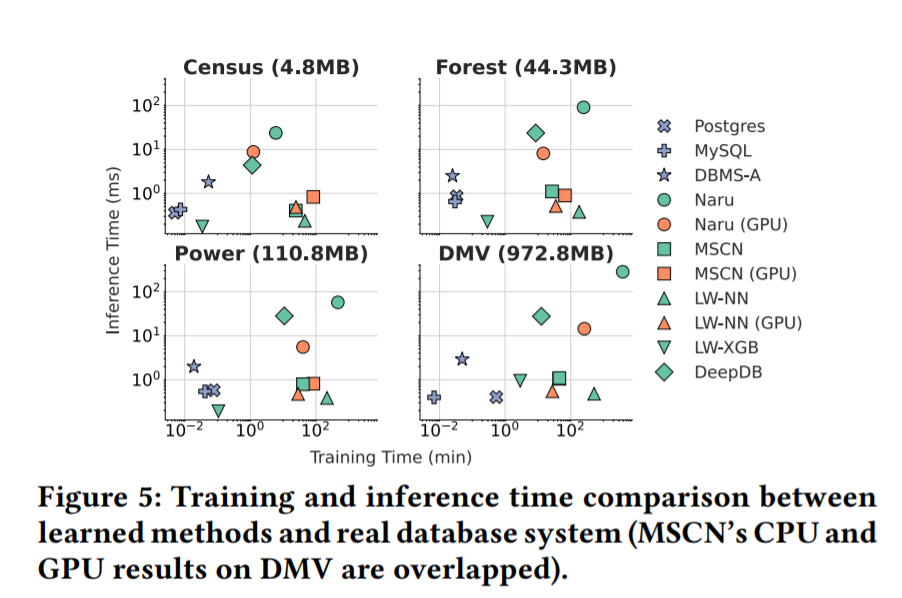
超参数调整是学习方法的另一个成本。如果没有超参数调整,学习的模型可能会表现得非常糟糕。实验发现,对于同一种方法,具有不同超参数的模型之间的最大q误差与最小q误差之比可以达到10的5次方。
一般情况下,我们需要训练多个模型才能找到最佳超参数。如上图,Naru在带有GPU的DMV上训练单个模型用了4个多小时。如果训练了五个模型,Naru可能需要20多个小时(几乎一天)进行超参数调整。
主要结论:基于机器学习的方法在准确率上相比于传统方法有比较大的提升。然而相比于传统方法,除了 [Selectivity estimation for range predicates using lightweight models] 中的LW-XGB以外,机器学习方法需要更多的时间去训练模型,同时在模型运行的时候也会更慢。
2、学习的方法是否是适合动态环境?
“数据更新”在现实生产环境的数据库中时常会发生,这使得基数估计器常处于一个“动态”变化之中。
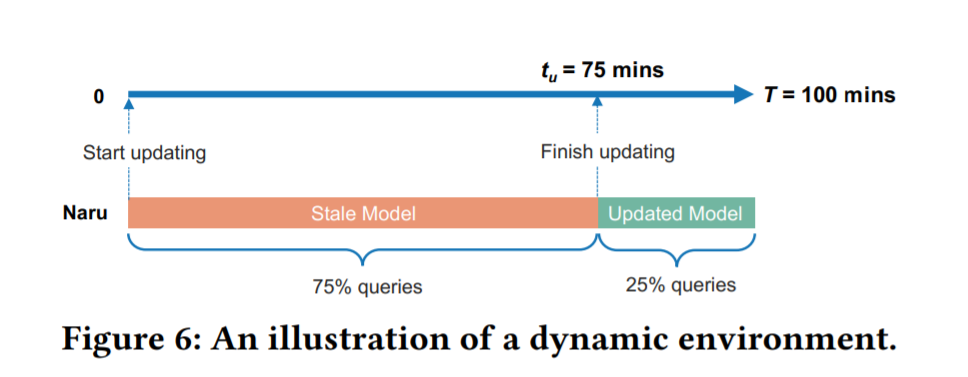
为了更加公平的比较基于学习的方法和现有的数据库产品,需要在模型中引入一个动态的框架。作者在本文提出了一个在动态环境中符合数据和模型更新速度的评估基数估计模块的方法,并且设计了一系列实验探讨了基于学习类的方法在真实环境中应该能够如何调整。
以下为DBMS与不同数据集动态环境下的5种学习方法。
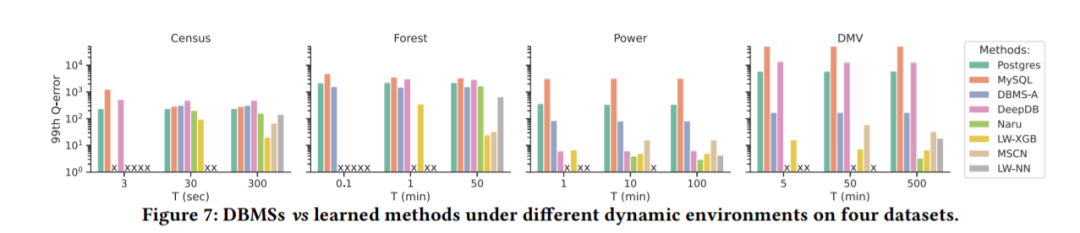
T表示数据集的更新频率:高、中、低
可以发现,与学习的方法相比,DBMS具有更稳定的性能。其原因是DBMS的更新时间非常短,几乎所有查询都是在更新的统计数据上运行的,而很多学习的方法无法跟上快速的数据更新,即使可以其性能也次于DBMS。
例如,当DMV T=50 min时,DBMS-A的性能比DeepDB高出约100倍,因为更新的DeepDB模型无法很好地捕捉相关性变化。
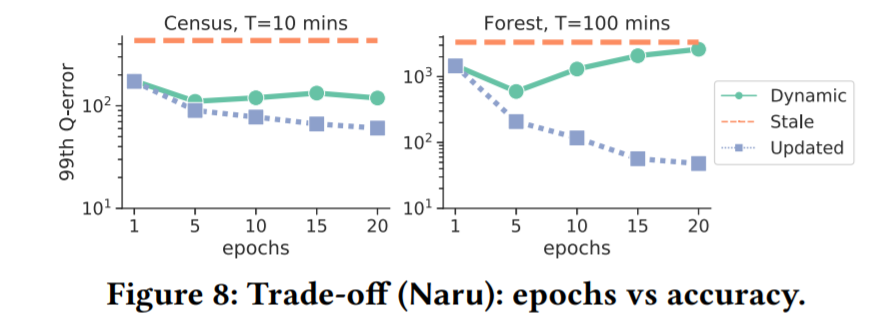
作者进一步探讨了学习的方法的更新次数和准确性之间的相关性。实验表明,当 Census T=10min,Forest T=100min时,“Dynamic”(代表Naru在10K查询中的性能)是先下降后逐渐回升的,这表明训练时间增加,模型更新缓慢,使未更新的模型执行了更多的查询。虽然多次迭代改进了更新模型的性能,但损害了整体性能。
使用GPU是否能够改进Naru和LW-NN。实验表明,当Forest T =100min,DMV T=500min时,在GPU的帮助下,LW-NN在Forest和DMV上分别提高了约10倍和2倍。其原因是:
(1)使用GPU,LW-NN的训练时间提高了20倍;(2) 高效训练的LW-NN(500个epoch)可以获得更好的准确性。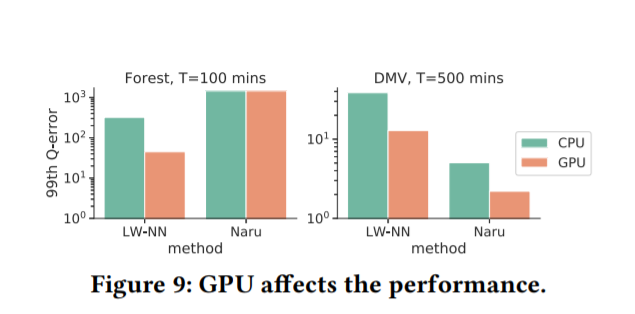
Naru在DMV上改进了2倍,在Forest中没有改进。这是因为更新时间越短,更新模型的查询就越多,1个步态不足以让Naru获得更好的更新模型。
主要结论:机器学习方法需要更久的时间去更新模型,因此往往会跟不上数据更新的速度。与此同时,不同机器学习方法的估计误差在不同的数据集上有所差异,并没有一个显著的最优方法。
3、可能出现错误的几种情况
机器学习和深度学习模型的可解释性差一直被学术界所诟病。可解释性差,意味着研究人员很难评估模型什么表现佳,什么时候表现不佳,从而导致用户难以信任和使用它们。
在本篇论文中,作者重点分析了不同的基于学习的基数估计方法出现较大误差的几种情况,从中发现了模型一些不符合逻辑的行为,并提出了一套提升模型可信性的逻辑规则。
如下图,相关性、分配和域名大小会在不同程度上影响q-误差的分布。
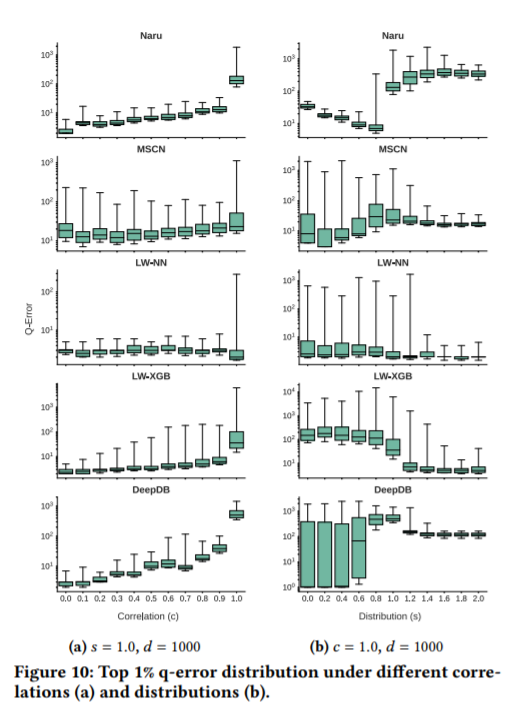
相关性:当改变相关参数时,所有方法都倾向于在数据集上产生更大的q-误差。如图(a)显示了指数分布s =1.0和域大小 d=1000时,不同相关度上前1% q误差的趋势分布情况。很明显,所有图中的箱线图都有随 c 增加而上升的趋势。
分配:
当改变第一列分布和基础相关性设置时,每个学习的方法都发生了不同的变化。当s从0.0变为2.0,同时修正相关性c=1.0和域大小d=1000时,顶部1%的q-误差分布趋势如图10b所示。
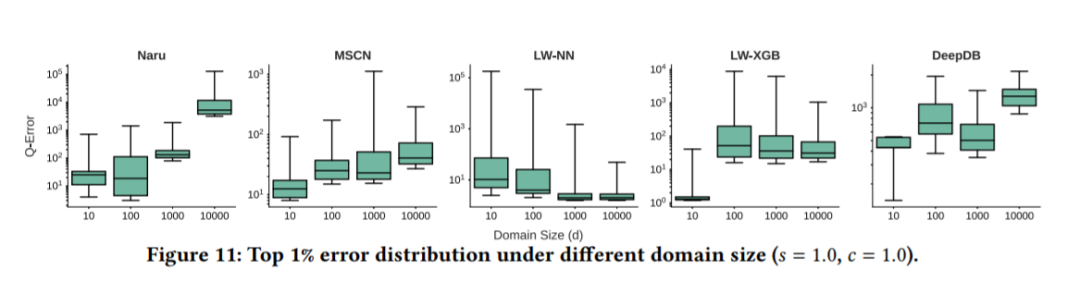
域名大小:不同的域大小(s=1.0和c=1.0)在数据集上生成的最大的1%q误差分布,如上图,Naru可能会在每个域大小上使用不同的模型体系结构,以满足相同的1%大小预算。
在实验研究中,作者发现部分模型出现了一些不合逻辑的行为。例如,当查询谓词的范围从[320, 800] 缩减到 [340, 740] 时,实际基数减少了,但LW-XGB估计的基数增加了60.8%。这种不合理的逻辑规则可能会给DBMS开发人员和用户带来麻烦。
受到深度学习解释领域的工作的启发,作者提出了五个基本规则,这些规则简单直观,可作为一般基数估计器的评估标准:
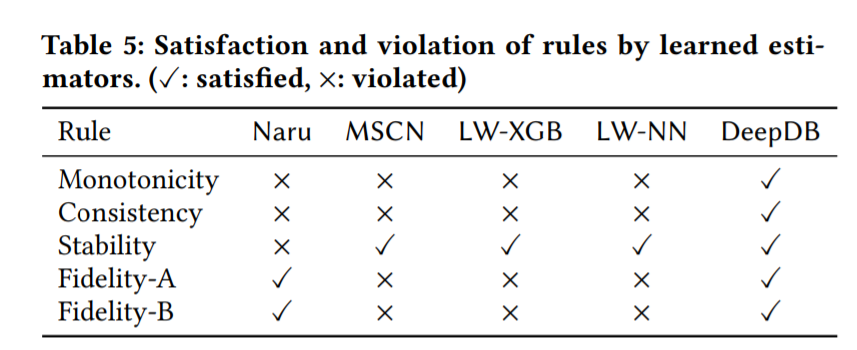
(1) 单调性:使用更大(或更小)的谓词,估计结果不应增加(或减少);
(2) 一致性:一个查询的预测值应等于其分段查询预测值之和;
(3) 稳定性:对于同一查询,来自同一模型的预测结果都应该是相同的;
(4) Fidelity-A:查询整个域的结果应为1;
(5) Fidelity-B:对于具有无效谓词的查询,结果应为0。
主要结论:我们发现所有机器学习方法会在数据有较高的相关性时产生较大的误差。与此同时,黑箱模型导致了无法解释误差的来源。
研究结论
虽然目前基于学习方法的基数估计方法还不能够投入使用,但是以上实验验证了其在准确度方面的潜力以及对数据库优化器可能带来的巨大的影响力。为了能够真正的将其部署到真实的数据库产品中,作者在认为未来需要重点解决两个问题:
1.提升模型训练和查询速度
通过实验可以看到,当前大部分的机器学习模型与数据库产品相比,无论从训练还是查询时间上都有较大的差距,同时针对于模型本身的参数调优的步骤也会花费数据库管理员一定的时间和精力。并且由于更新速度过慢,很多准确度很高的模型无法处理高速变化的数据,因此提升模型的训练以及查询速度是部署该类方法到数据库产品中的重要前提。
2. 提升模型解释性
现有的基于学习模型的方法大多基于复杂的黑盒模型,很难预测它们何时会出问题,如果出现问题也很难进行调试。我们在实验中展示了传统方法出现的一些不符合逻辑的行为,这些都会成为把它们投入到真实使用中的障碍。因此,提升模型解释性在将来会是一个非常重要的课题,我们认为一方面可以从研究更为透明的模型入手,另一方面也可以投入更多的精力在模型解释和调试上。
论文链接:http://www.vldb.org/pvldb/vol14/p1640-wang.pdf
代码链接:https://github.com/sfu-db/AreCELearnedYet
官网链接:https://vldb.org/2021/?conference-awards
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看
”。








