欲掌握模型评估与选择相关算法原理,魔术师推荐大家学习本文的内容,并且阅读周志华教授所著的《机器学习》第二章。

1. 人类学习
在一次自然测验前,王老师给同学们讲了 10 道不同风格的训练题。舒岱梓同学死记硬背的学,基本上是死记每道题的细节和解题步骤;肖春丹同学心不在焉的学,老师讲的时候他一直在分心;甄薛申同学举一反三的学,主要学习老师讲的解题思路和方法。讲完题后老师开始发卷子测验,里面有 10 道测验题。舒岱梓同学把训练题学的太过以至于测验题稍微变动一点就做不好了,典型的应试教育派;肖春丹同学学习能力低下,训练题都学不好,测验题一样也做不好,典型的不学无术派;甄薛申同学学到了题里的普遍规律,发现所有题都是万变不离其宗,测试题也做的很好,典型的素质教育派。
舒岱梓同学这种现象叫做“过学习” (overstudy),它的极端结果就是只能在做过的题上拿高分;肖春丹同学这种现象叫做“欠学习” (understudy),它的极端后果就是做什么题都拿不到高分。这两者都不好,我们要向甄薛申同学学习。
读者看了看其中的一道题和他们给的答案,就以下明白了为什么“过学习” 和“欠学习”为什么不好了。
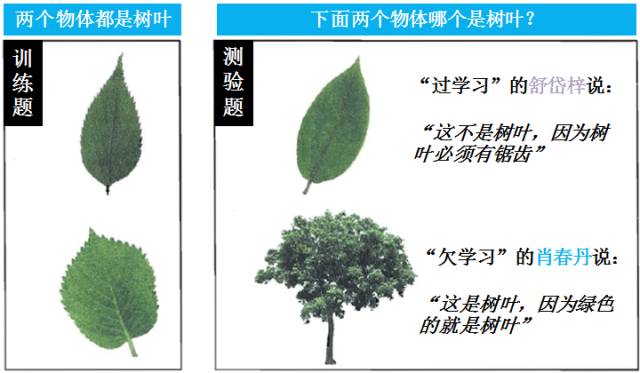
“过学习”的舒岱梓学的太细,把训练样本自身的一些特点 (树叶的锯齿) 当作了潜在样本 (没有锯齿的树叶) 都会具有的特性。“欠学习”的肖春丹学的太粗,连训练样本的一般性质 (树叶至少不会有树干吧) 都没学好。人类学习这样,机器学习亦如此。对人类来说,你训练题全做对不算什么,牛的是每次测验题都能拿高分;对机器来说,你训练数据能拟合 (fit) 好不算什么,牛的是每次测试数据拟合的误差小。
注:舒岱梓,肖春丹
和甄薛申分别的谐音是书呆子,小蠢蛋和真学神。
2. 机器学习
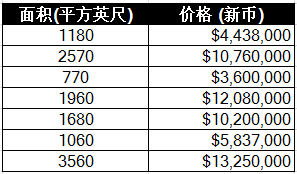
我在一家房地产中介上班,一天老板说一个富豪客户想买一套在滨海湾的公寓,需要我们给个报价,你根据周边公寓的不同面积的价格建个模型吧。我心想这还不简单,赶紧收集数据如下:
首先我用了一次多项式做了线性拟合,马上把结果展示给老板看:
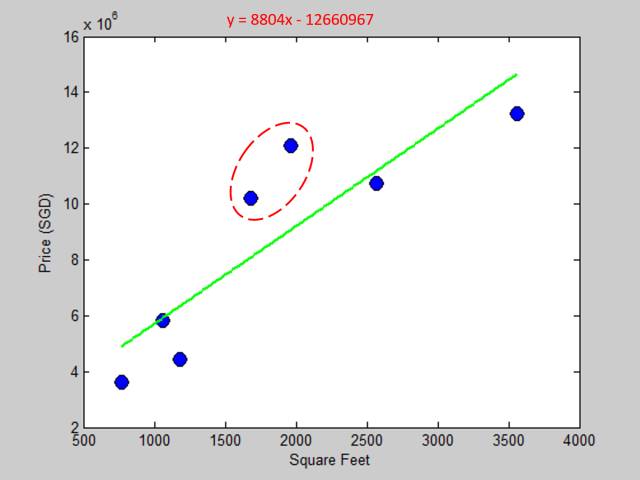
注:蓝色实心点是真实数据,绿色线是拟合后的模型
老板:这拟合的是什么鬼?红框里面那两套房子离你预测模型差太远了吧,你这整体的误差也太大了吧。
我:。。。
的确误差有点大,怎么改善模型呢?突然我灵机一动,可以用高次多项式啊,7个数据我用个六次多项式可以完美拟合所有点啊,机智如我!马上我用六次多项式做了拟合,屁颠屁颠着给老板展示,心想我做到了零误差期待你的肯定:
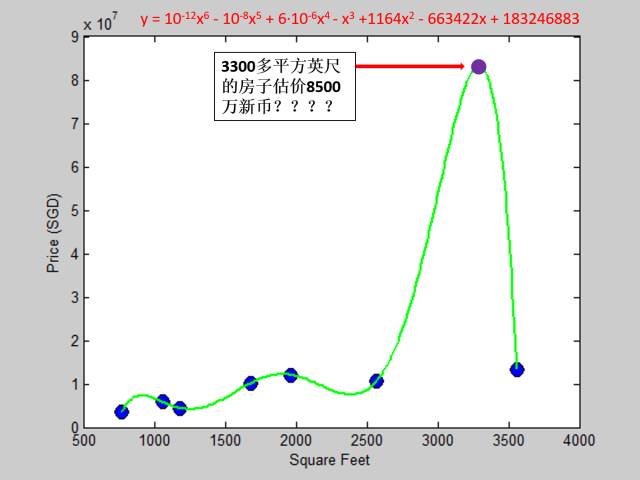
注:紫色实心点是新数据
老板:这个客户想买的面积大概3300平方英尺,你的模型告诉我客户需要付8500万新币?而市场3500平方英尺大概才1300多万哦!什么烂模型!
我:。。。
误差大也不行,零误差也不行?你还要我怎样,要怎样 (薛之谦的音乐背景)?到底哪里出了问题?想了几天,我大概摸出以下一些规则:
太简单的模型拟合现有数据的质量不太好,误差比较大。即便给了新数据,也没有人会用这个模型来预测。
太复杂的模型拟合现有数据的质量会很好甚至完美 (零误差),但适应新数据的能力不好也没什么卵用。
折中方案是找一个中间模型,即使你拟合现有数据的质量低于复杂模型,但它只要能更好的适应新数据,我们就应该选用它。
经过一轮调试,我使用二次多项式来拟合数据,结果如下图:
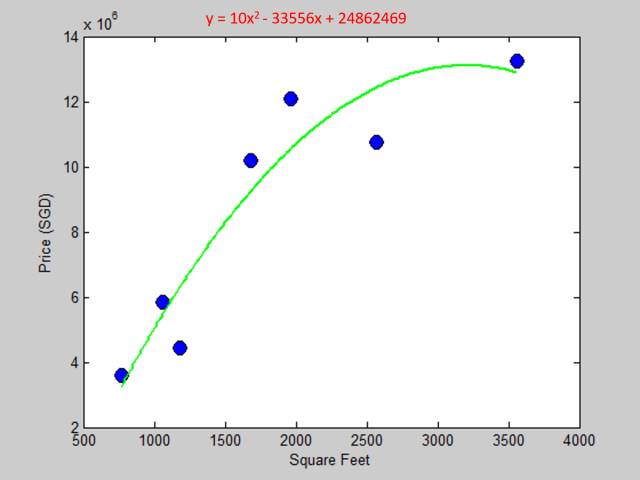
老板:哎哟这个模型不错哟,现有数据拟合的很好,而且貌似对新数据的预测也比较合理。(客户想买的3300平方英尺大概1250万左右)
我:Yeah?
通过上面三个例子,一次多项式“欠拟合” (underfitting) 数据 (基本上没有学习到数据的非线性特征),六次多项式“过拟合” (overfitting) 数据 (学数据学的太过了导致于来个新数据 3300 平方英尺给出那么离谱的价格),而二次多项式拟合的结果看起来比它们都好。这个“好”可以量化吗?说它“好”是因为它能适应新数据,但是在没见到新数据之前怎么来判断模型的好坏呢 (更别提如何量化它了)?
这些问题在第 4 节都会得到解答,但是在此之前,我们一定要了解第 3 节里的几个重要概念。
3. 重要概念
3.1 总体 (population) 和样本 (sample)
在统计中,把研究对象的全体称为总体,而把组成总体的各个元素称为个体,把从总体中抽取的若干个体称为样本。举个调查中国男性平均身高的例子,全国的男性就是总体,每个男性是个体。有时候普查所有男性金钱花费和时间成本太高,通常我们会抽取若干男性作为样本。我们计算样本里的男性平均身高作为总体里的所有男性平均身高的推理 (inference)。

弄清楚总体和样本的概念之后,我们来看看误差和残差。
3.2. 误差 (error) 和残差 (residual)
误差和残差是两个极易混淆的概念,误差是观察值和总体平均值的偏差,而残差是观察值和样本平均值的偏差。还是用调查中国男性平均身高的例子:
因此可看出残差是不可观察量的误差的可观察估计。(residual is the observable estimator of unobservable error)。当我们做统计调查时都是用的样本 (通常不可能用总体的,除非总体里面的元素不多),样本均值可以作为总体均值的良好估计量,然后我们有:
作者费这么多功夫描述误差和残差的区别,是因为我觉得所有机器学习的术语里对训练误差 (training error),测试误差 (test error) 和验证误差 (validation error) 定义的都不太严谨 (如果按传统的统计学定义的话)。原因是误差都是基于总体而且不可观察也不可量化的,但是训练集,测试集和验证集都是样本而且可观察也可量化,难道不应该叫做训练残差 (training residual),测试残差 (test residual) 和验证残差 (validation residual) 吗?有一个术语,真实误差 (true error),作者觉得这个定义就很严谨。因为真实误差衡量的是模型对新数据适用的能力,所以真实误差是不可观察的,不能称其为真实残差。
注:这个问题也困扰了我很久,如果是我才疏学浅,望大牛们来斧正。也许这是机器学习术语界的一种惯例吧。在后文作者也就跟着惯例用这些术语。为了不给大家添堵,我们就认为“对于一个模型,误差就是该模型预测输出和样本真实输出之间的差异 ”吧。在我们的预测房价的例子里
误差 = 预测价格 - 真实价格
3.3 多项式函数
在本贴作者都拿多项式模型举例,在解释后面的训练误差 (真实误差) 跟模型复杂度的关系时更加直观一点。说白了就是用不同阶的多项式来拟合房价,像第 2 节那个例子一样,用一次多项式结果不理想就试试六次多项式,结果还不理想再试试二次多项式,一直到结果理想为止。模型函数如下:
hw(x) = w0 + w1x + w2x2
+ … + wpxp
其中
hw(x)是预测函数
x 是房屋面积
w 是模型参数
p 是多项式的阶
3.4 模型复杂度 (model complexity)
原本以为这个定义会很简单,google 发现没有一个解释是非常通俗易懂的,要不定义的不清不楚,要不用了一大堆严谨的数学符号。为了帮助理解本帖内容,我们就把注意力集中在“多项式函数”上,多项式阶越高,该模型复杂度越高。例如:
以此类推。
3.5 损失函数 (loss function)
损失函数是一种衡量预测损失和错误 (损失和错误预测相关) 程度的函数。定义为
L(hw(x), y) = (y- hw(x))2
其中
hw(x)是预测函数 (用多项式函数来表示)
y 是真实的房屋价格
为什么可以把“预测不准”看做是一种损失?以预测房屋价格为例,如果你是卖家,估价太低赚的就少了,估价太高很可能会失去买家;如果你是买家,估价太低很可能会失去卖家,估价太高花的就多了。在各种情况 (买家或卖家) 下,估不准房价,估高 (overpredict) 或估低 (underpredict),可能都会造成损失。损失函数里面的“平方”就考虑了因估高或估低而使买家或卖家蒙受损失的情况。
3.6 训练集和训练误差 (training set, training error)
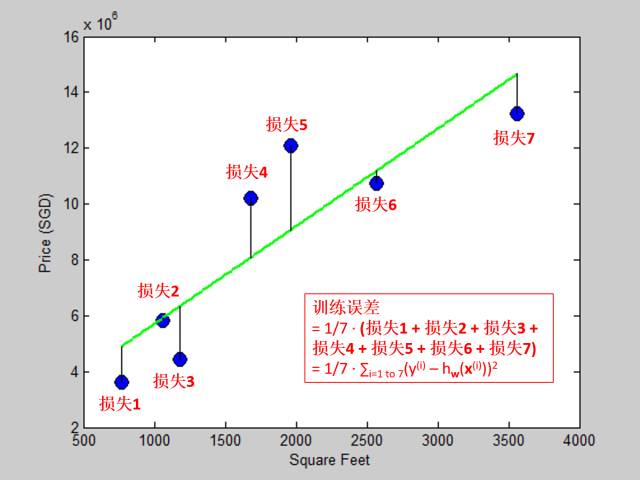
训练集是每一个训练样本组成的集合,也是上文那 7 个 [面积, 房价] 的数据。
训练误差又叫经验误差 (empirical error),定义为模型在训练集上的误差,通常可表示为训练集上的损失均值
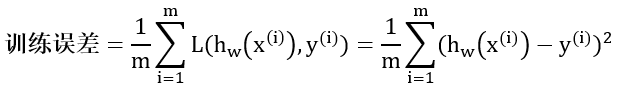
假设我们用线性模型拟合训练集,训练误差展示于下图:
下面两图我们计算了用零次,一次,二次和六次多项式拟合后的训练误差,发现模型复杂度越高,训练误差越小 (六次多项式已经可以生成零训练误差了)。
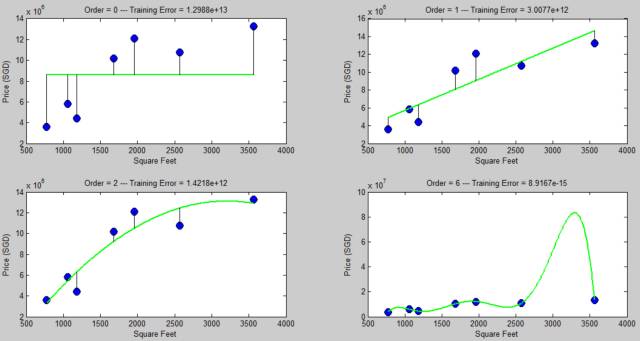
训练误差跟模型复杂度的关系如下:
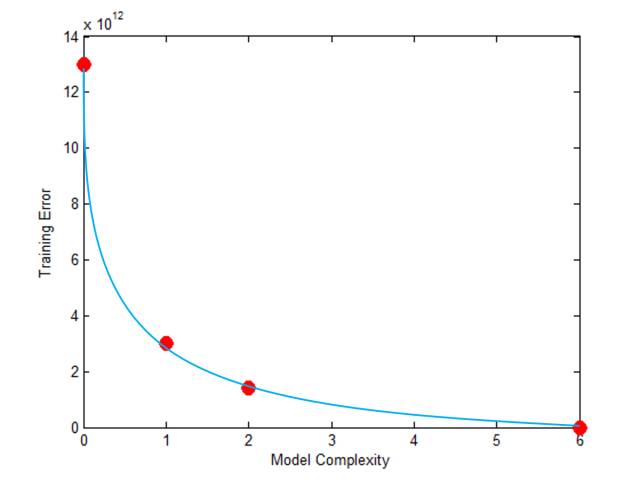
问题:训练误差是模型预测能力的好的度量吗?换句话问,是不是训练误差越小模型预测就越准?
回答:不是!除非训练数据包含了所有数据!反例可见下图
这个六次多项式完美的拟合训练数据,训练误差为 0,你看着它的疯狂形状,扪心自问你会对它的预测能力有信心吗?紫色那个点对应的那个价格会不会太疯狂?
3.7. 真实误差 (true error)
真实误差又叫泛化误差 (generalization error),它的定义是一个模型学完训练数据之后,用在新数据上的误差。真实误差主要衡量模型的“归纳能力” (induction ability),模型是否能从训练数据中归纳出规则而适应新数据的能力。
新数据是没有见过的数据。真实误差实际上是测量已训练好的模型在所有数据 (所有现有的数据和未来的数据) 上的误差。在这数据全集上,对任何一个给定面积的房子,它的价格总会有一个概率分布。
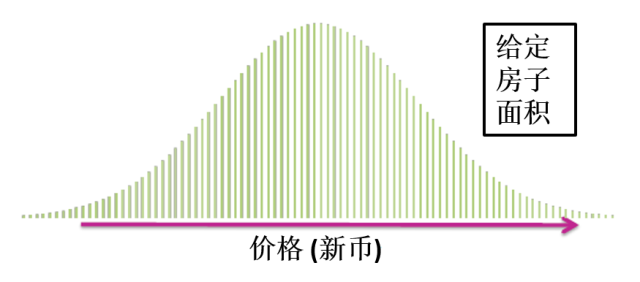
假设某房子面积为 2500 平方英尺,它的价格在 800~1500 万之间 (假设价格只有800万,1000万和1500万这三个,真实情况不可能这样,只是为了便于下文分析),而且分布概率通常会如上图所示,极低价800万和极高价1500万的个数会很小,分别是1栋和2栋,而中间价1000万的个数会很大,是7栋。对于这套房子,用模型拟合的价格是1050万,它的真实误差为

实际中,面积为 2500 平方英尺会有无数个,因为未来会一直有新数据进来。在给定 xt 时,真实误差的严谨数学表达式为
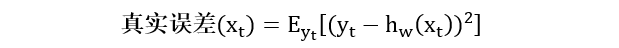
其中
xt = 房屋面积 (给定的量)
yt = 真实的房屋价格 (随机变量)
hw(xt) = 模型预测的房屋价格
公式里面的期望符号相当于上例中累加符号。
对于所有
xt,真实误差的数学表达式为
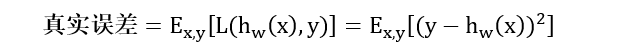
接下来我们分析一下真实误差和模型复杂度之间的关系,首先是一次多项式:
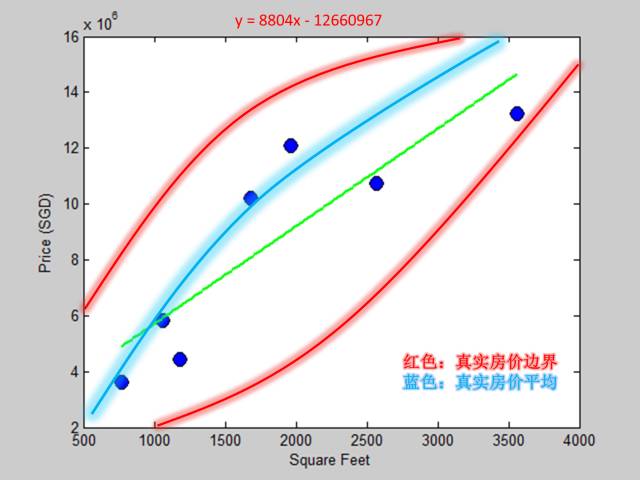
由上文分析可知,在整个数据集里 (已知的未知的) 每一个面积的房子对应的价格都有一个概率分布,而上图两条红色曲线就是真实房价的上下边界,而那条蓝色曲线就是真实房价的均值。绿色直线是拟合出来的一次多项式模型,我们发现它和蓝色曲线相差比较远,因此一次多项式模型对应的真实误差比较大。
接着二次多项式:
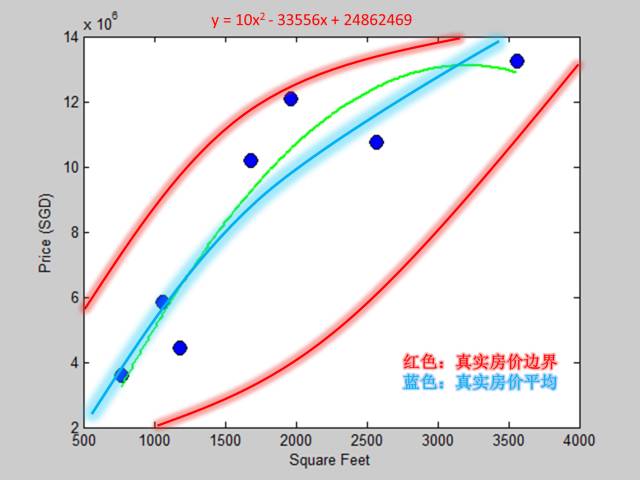
绿色曲线是拟合出来的二次多项式模型,我们发现它和蓝色曲线相差很近,因此二次多项式模型对应的真实误差很小。
最后六次多项式:
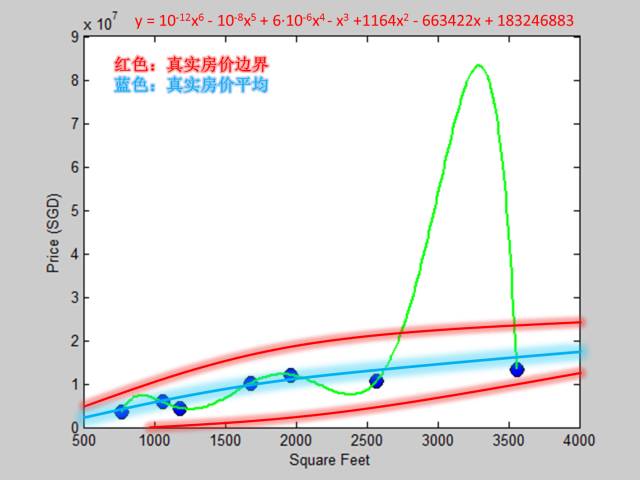
绿色曲线是拟合出来的六次多项式模型,我们发现它和蓝色曲线相差非常非常远,因此六次多项式模型对应的真实误差非常大。
真实误差跟模型复杂度的关系如下:
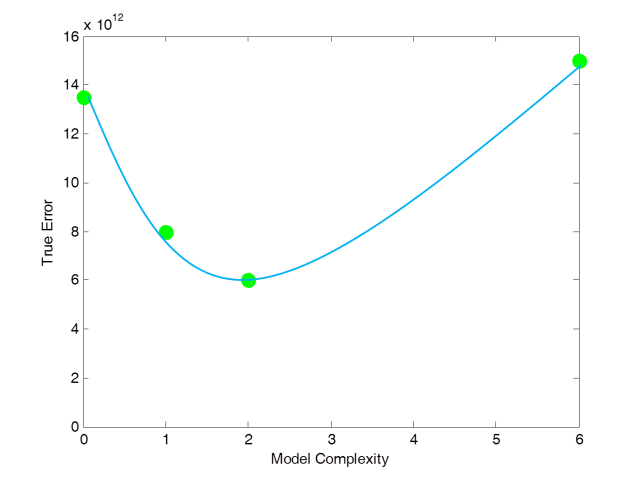
和训练误差不同,真实误差不是随着模型复杂度变高而变小的,它是先变小再变大的。当训练模型时,我们希望找一个模型使得它的真实误差最小。
最严重的问题是上面所有关于真实误差的图都是假想的 (我们最多只能推断出它的形状是这样的,但得不到具体的数值),因为真实误差是基于所有数据的,没有人可以计算出基于未来数据的误差,因此真实误差只能意会,不能计算!不能计算那费这么大篇幅介绍它有何用?测试误差终于派上用场了。
3.8 测试集和测试误差 (test set, test error)
测试集是选出用来测试的样本组成的集合。最重要的是测试集里面不包含任何训练集里面的数据。当你选好训练集之后,测试集是在模拟那些你从来都没见过但未来可能会见到的数据集。
测试误差是定义为模型在测试集上的误差,它是真实误差的一种近似 (还记得上文说过真实误差看以来很美但是不能计算,因此我们需要找一个可以计算的而又能够近似真实误差的量)。计算公式如下:
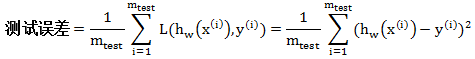
其中 w 是从训练集 (不是测试集) 里面拟合出来的模型参数,而 (x(i), y(i)) 是测试集(不是训练集) 里面的样本。 假设我们用线性模型拟合训练集,测试误差展示于下图:
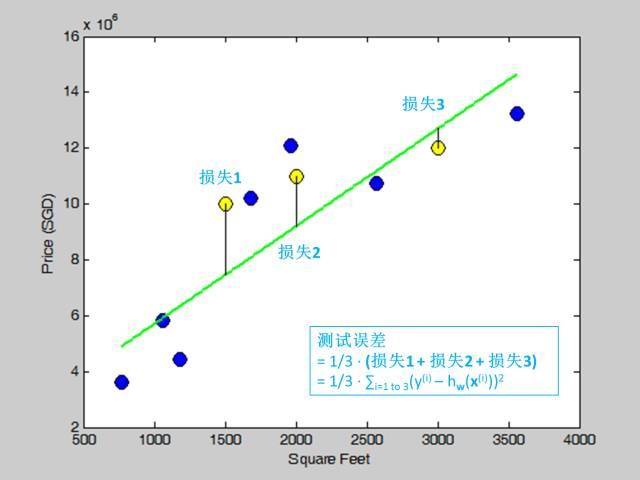
3.9 偏差,方差和噪声 (bias, variance and noise)
让我们再深一步剖析真实误差。以房价为例,给定一个模型 (比如线性模型),该模型在给定一个面积下来预测房价,是一定会有误差的,那么误差的来源有哪几个呢?
这个模型只用了一套 [面积, 房价] 训练集来拟合模型参数,而市场中有无数套同样大小的 [面积, 房价] 训练集。用每套训练集来拟合模型都会得出一套不同的模型参数。我们可以假想市场上有一个真实模型 (想的到捉不着) 来描述面积与房价关系的。
这些成交房价不一定只是和面积相关,还可能和当时买家或卖家的心情,风水,甚至成交当天的天气有关。这些因素造成的误差都可以看成是噪声。
简单模型和复杂模型
为了便于解释,我们选常函数为简单模型,高次多项式函数为复杂模型。下图是展示了两套数据拟合出的两个简单模型 (绿色水平线),而黄色曲线是真实模型。
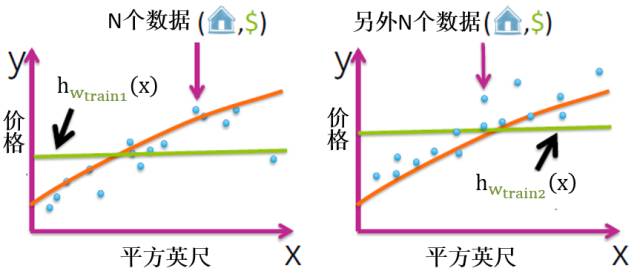
同样,下图是展示了两套数据拟合出的两个复杂模型 (绿色疯狂曲线),而黄色曲线是真实模型。
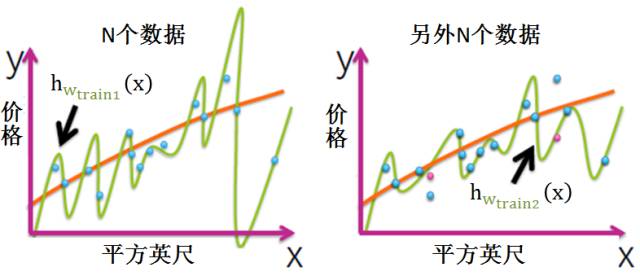
从上图可看出,用不同训练集的数据可以拟合出不同的简单模型或复杂模型,简单模型平淡,复杂模型疯狂。接下来我们来看看这两种情况下的偏差和方差的性质。
偏差
简单模型 (模型复杂度低)
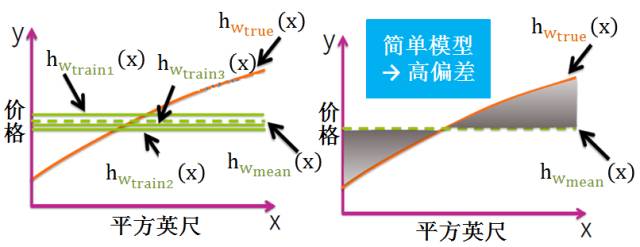
将所有简单模型求平均得到下图的绿色虚线,发现它和黄色曲线相差甚远。给定无数套训练集而期望拟合出来的模型就是平均模型。偏差就是真实模型和平均模型的差异。该模型太简单,就是一组水平直线,平均之后和真实模型的曲线差别较大,因此简单模型通常高偏差 (见灰色阴影部分)。
复杂模型 (模型复杂度高)
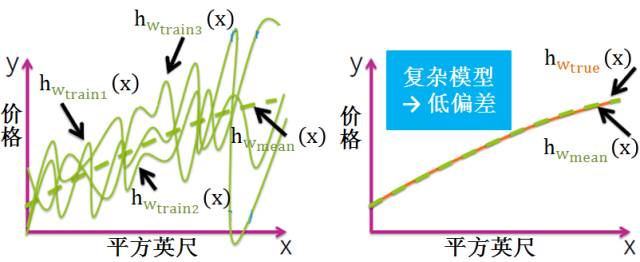
将所有复杂模型求平均得到下图的绿色虚线,发现它和黄色曲线相差甚近。该模型太复杂,是一组起伏很大波浪线,平均之后最大值和最小值都会相互抵消,和真实模型的曲线差别较小,因此复杂模型通常低偏差 (见黄色曲线和绿色虚线几乎重合)。
方差
简单模型 (模型复杂度低)
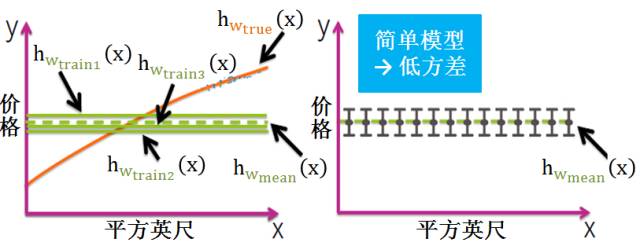
简单模型的对应的函数如出一辙,都是水平直线,而且平均模型的函数也是一条水平直线,因此简单模型的方差很小,并且对数据的变动不敏感。
复杂模型 (模型复杂度高)
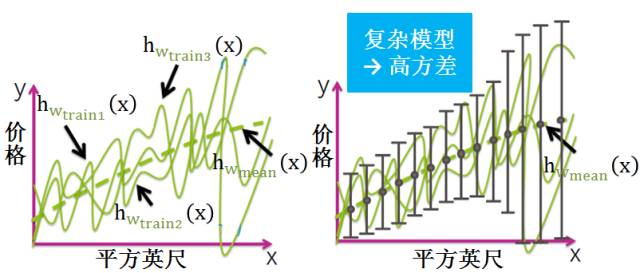
复杂模型的对应的函数千奇百怪,毫无任何规则,但平均模型的函数也是一条平滑的曲线,因此复杂模型的方差很大,并且对数据的变动很敏感。
噪声
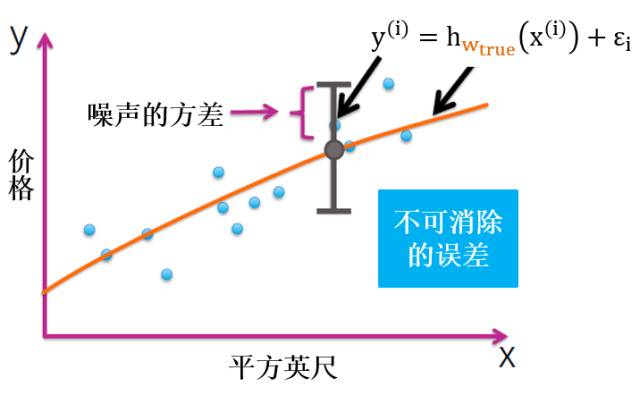
噪声表达了在当前任务上任何学习算法所能达到的期望真实误差的下界,即学习问题本身的难度。
偏差和方差权衡 (bias-variance tradeoff)
由上两小节可知:
简单模型的偏差大方差
小,复杂模型的偏差小方差大。
偏差和模型复杂度成反比,方差和模型复杂度成正比。
简单模型“欠拟合”,复杂模型“过拟合”。
“欠拟合”的模型的偏差大方差小,“过拟合”的模型的偏差小方差大
一张图胜过千句话:
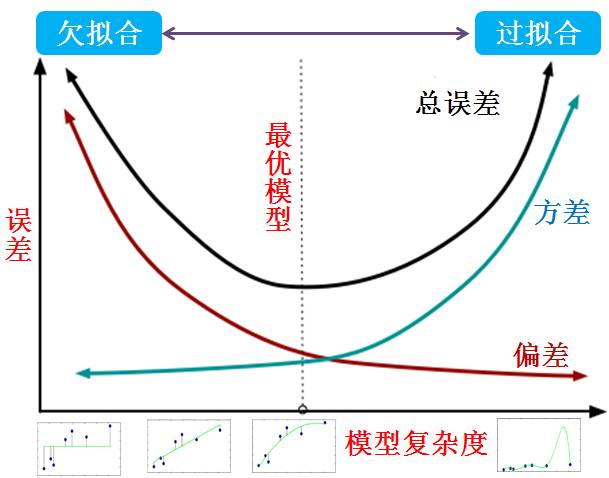
一般来说,偏差和方差是有冲突的,这称为偏差-方差权衡。给定学习任务:
如上图所示,最优模型出现在总误差最小的那点。
深度研究真实误差 (Deep study of true error)
温馨小贴士:本节是给喜爱数学的读者准备的,不爱数学的同学可以跳过。
回忆真实误差的定义,对于所有 xt (面积) ,其数学表达式为
然而现在还有一个新问题,就是你每次选的训练集也是随机选取的,今天选前1000个,明天选后1000个,后天选中间1000个,每次拟合出来的模型也不尽相同,因此我们真的要量化的东西是:用不同训练集来计算真实误差 (拟合出来不同的房价预测函数 h,和真实房价 y 一起计算出损失函数 L),然后将所有真实误差求平均值,称为预期误差 (expected prediction error)。预期误差的严谨数学公式如下:
E训练集[Ex,y[(y – h训练参数(x))2]
接下来我们从数学上来推出真实误差是噪声的平方,偏差的平方和方差的总和。(点击看大图)

推导解释:
第 1 步 ~~ 关注特定的 xt;用 D 来表示训练集
第 2 步 ~~ (a-b) = (a-c) + (c-b)
第 3 步 ~~ 令 h1 = hw_true, h2 = hw_train
第 4 步 ~~ (a+b)2= a2 + 2ab + b2
第 5 步 ~~ y
t - h1 和 D 无关,h1 - h2 和 yt 无关
第 6 步 ~~ 根据噪声的定义 σ = yt - h1
第 7 步 ~~ 假设噪声的均值是 0
第 8 步 ~~ 化简
第 9 步 ~~ (a-b) = (a-c) + (c-b);hm = ED[h2]
第 10 步 ~~ (a+b)2= a2 + 2ab + b2
-
第 11 步 ~~ 根据偏差的定义 h1 - hm 和方差的定义 E(hm - h2)2
第 12 步 ~~ 偏差和噪声相互独立,所以 ED[XY] = ED[X]ED[Y]
第 13 步 ~~ 根据定义 hm = ED[h2]
小结
综上所述,真实误差有三个来源,偏差,方差和噪声。由于真实误差是衡量模型泛化性能的,因此泛化性能是由学习算法的能力,数据的充分性以及学习任务的本身难度所共同决定的。给定学习任务 (因为其本身难度是无法降低的,就像噪声是无法消除的一样),为了获得好的泛化性能 (降低真实误差),有两条路可走:增强拟合数据能力 (降低偏差) 和增强数据的抗扰能力 (降低方差)。
4. 模型精度评估和选择
如果你有耐心看到这,现在思路应该很明晰了。我们用训练集来训练模型,通常模型复杂度越高训练误差越小。但是看一个模型好不好是要看它的泛化能力,也就是适应新数据的能力,而真实误差是衡量模型泛化能力的。可惜的是,真实误差就像一个仙子一样,只能说说想想,却永远抓不到算不出,因此我们用测量误差来代替真实误差来选择合适的模型复杂度,但有时能成功,有时会失败,且听以下分析。
4.1 训练集和测试集划分 (training/test sets split)
如果数据足够多的话,通常按 80% 和 20% 来划分训练集和测试集。
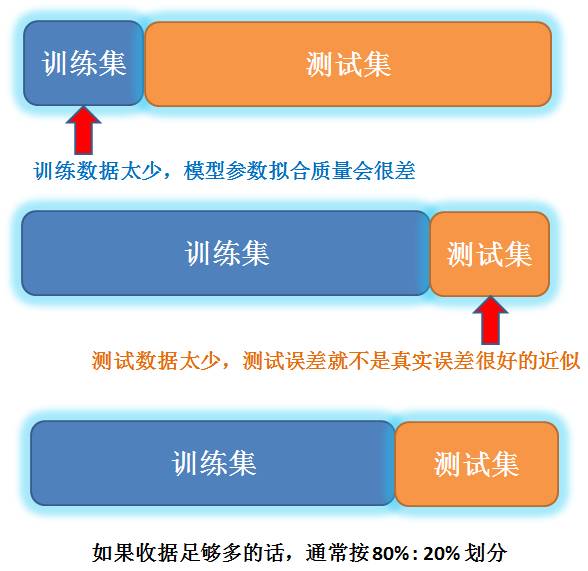
4.2 假想执行方案 (hypothetical implementation)
模型选择流程如下:
按 80% 和 20% 划分训练集和测试集。
对于每一个模型 (例如,不同阶的多项式模型),用训练集的数据拟合出模型参数。
用此参数和测试集算出测试误差。选一个测试误差最小的模型。
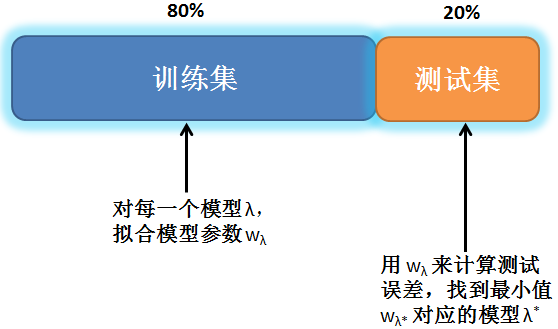
此做法的缺陷是,如果测试集的数据不能代表数据全集,那么最小测试误差的模型可能表现还没有其他模型好。
4.3 实际执行方案 (practical implementation)
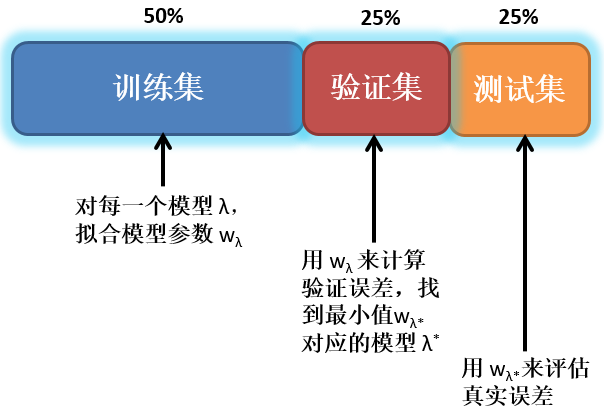
解决方案就是除训练集之外创建两个“集”,一个用来选择模型或调解参数,叫做“验证集”,一个用来估计选好的模型在实际使用时的泛化能力,叫做“测试集”。如果数据足够多的话,通常按 50%, 25% 和 25% 来划分训练集,验证集和测试集。

模型选择流程如下:
按 50%, 25% 和 25% 划分训练集,验证集和测试集。
对于每一个模型 (例如,不同阶的多项式模型),用训练集的数据拟合出模型参数。
用此参数和验证集算出验证误差。选一个验证误差最小的模型。
用对应的模型参数和测试集算出测试误差作为真实误差的评估。
4.4 k 折交叉验证法 (k-fold cross vallidation)
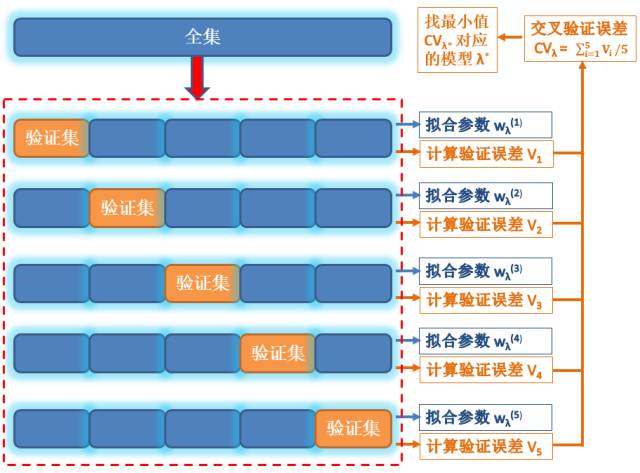
上次划分 50%, 25% 和 25% 为训练集,验证集和测试集的先决条件是数据足够多。如果数据不够多的话,验证集里的数据也不足以反映真实数据的特征。这个时候通常会使用 k 折交叉验证法。以 k 等于 5 为例:
将整个数据集大概平均分成 5 份。
对于每一个模型(例如,不同阶的多项式模型),从第一份到最后一份,将选中一份数据集当作验证集,剩余的四份一起当作训练集。
用训练集的数据拟合出模型参数。
用此参数和验证集算出验证误差。
重复以上过程,每次选取不同验证集并求出 5 个验证误差的均值作为交叉验证误差
选一个交叉验证误差最小的模型。
假定数据集中包含m个样本,若令k=m,即每个样本都归为一个单独的划分子集,则得到了交叉验证法的一个特例:留一法 (LOO, leave-one-out)。显然此评估会非常准确,且不受随机样本划分方式的影响,因为每个数据集的属性就是每个样本的属性,且只有一种划分方式。但是当数据集比较大时,其计算开销太大。在实践中 k 通常选 5 或 10,分别叫做 5折交叉验证法和 10折交叉验证法。
5. 模型综合评估和选择
上节模型评估只是从精准角度出发,在实践中这是远远不够的,通常选择一个模型需要考虑以下五点:
精度 (accuracy)
可解释 (interpretability)
高效 (efficiency)
可扩展 (scalability)
简单 (simplicity)
一个好的方法是从简单模型开始,然后根据需要才增加模型复杂性。 一般来说,简单应该是首选,除非复杂模型可以大幅度提高精度。
模型精度的主要测量来自于估计给定模型的测试误差。因此,模型选择的精度提高目标是减少估计的测试误差。需要注意的是,通常在提高模型性能时,模型精度可以提高,但是提高的幅度递减 (diminishing return)。鉴于此,选择模型并不总是要它最精准。有时还必须考虑其他重要因素,包括可解释,高效,可扩展和简单。
通常,给定的一个应用程序,你可能需要折中一下模型精度和模型可解释性。人工神经网络 (ANN, aritificial neural network),支持向量机 (SVM, suppport vector machine) 和一些集合方法 (ensemble methods) 可以用于创建非常精确的预测模型,但是对非专业人士就是个黑盒子。
当预测性能是首要目标时并且不需要解释模型如何工作和进行预测,可以优选黑盒算法。然而,在某些情况下,模型可解释性是首选,有时甚至是法律强制的。比如在金融业,假设机器学习算法用于接受或拒绝个人的信用卡应用程序。如果申请人被拒绝并决定提出投诉或采取法律行动,金融机构将需要解释该决定是如何做出的。虽然这对于 ANN 或 SVM 系统几乎是不可能的,但对于基于决策树 (decision tree) 的算法来说是相对直接的。
在训练,测试,处理和预测速度方面,一些算法和模型类型需要更多的时间,并且需要比其他算法和存储器更大的计算能力和内存。在一些应用中,速度和可扩展性是关键因素,特别是在任何广泛使用的接近实时的应用 (电子商务站点) 中,给了一个新数据,模型就需要快速更新,并且在大数据上预测或分类。
最后,如前所述,模型简单应该总是优选的,除非提高精度对你有显著的增益。简单模型通常更高效,更容易扩展也更容易解释。
6. 总结
如何评估模型精度?
千万不要看训练误差,要看真实误差。但由于真实误差不可计算,通常用测试误差或者验证误差来代表它。
如何划分数据集?
如果数据够多,将数据集按 50%, 25% 和 25% 来划分训练集,验证集和测试集。如果数据不够多,将采用5折或10折交叉验证法。
如何选择模型?
简单为大,除非提高精度对你有显著的增益。

扫码可加入QQ群,获取更多的运筹优化算法及人工智能算法学习资料
↓↓↓
感谢您,
支持学生们的原创热情!
郑重承诺
打赏是对工作的认可
所有打赏所得
都将作为酬劳支付给辛勤工作的学生
指导老师不取一文
-The End-
审稿人 / 付喆(大二)
指导老师 / 秦时明岳
如对文中内容有疑问,欢迎交流。PS:部分资料来自网络。
付喆(华中科技大学管理学院本科二年级、fuzhefuzhefuzhe@163.com)









