编者按:全球碳排放问题亟待解决已是非常明确的科学共识,为了实现净零排放这一全球性目标,微软在2020年就提出了将在2030年实现碳负排放。近日,微软亚洲研究院与清华大学的研究员们共同合作,在环境与地球科学领域国际知名期刊 Geoscientific Model Development 上发表了题为 “Exploring Deep Learning for Air Pollutant Emission Estimation” 的论文。文章详细阐述了如何使用 AI 来帮助环境学家更精确地估算 NOx、SO2、VOC、一次 PM2.5 等污染物的排放量,并且把相对的估计误差降低了20%,极大提高了估算精度。该方法同样可以应用于二氧化碳、甲烷等温室气体的排放估算中,为中国实现“碳达峰、碳中和”也提供了有价值的参考。随着经济发展和人口数量的飞速增长,人类活动排放的有害气体严重损坏着公共健康与生态系统。排放清单的准确核算是有效模拟空气污染控制政策的重要前提,但由于污染源繁多如居民生活、汽车尾气、车间工厂等,并且其排放量不断变化,因此基于传统“自下而上”的排放源调查效率十分低下。而且传统方法严重依赖于宏观统计数据,缺乏时效性及精度保障。这种不准确的排放清单也成为了当前影响空气质量预测与模拟精度的主要限制因素。
事实上,排放清单和空气污染之间存在着一个对偶结构。考虑到空气污染物的浓度可以通过地面观测、卫星遥感等手段获取,研究员们猜想,如果排放清单与污染物浓度之间有一个足够准确的关系,那么就使用污染物浓度作为约束,来获得更准确的排放清单。基于此,微软亚洲研究院与清华大学的研究员们共同合作,在环境与地球科学领域国际知名期刊 Geoscientific Model Development 上发表了题为 “Exploring Deep Learning for Air Pollutant Emission Estimation” 的论文。研究员们在论文中提出了一种基于对偶学习的新方法,利用 AI 任务的原始对偶结构来获取信息反馈和正则化信号,从而增强学习和推理过程。该方法的关键难点在于如何快速准确的量化从排放到浓度的高度非线性响应关系。
Exploring Deep Learning for Air Pollutant Emission Estimation
论文链接:
https://gmd.copernicus.org/articles/14/4641/2021/gmd-14-4641-2021.html
模型代码:
https://doi.org/10.5281/zenodo.4607127
为此,研究员们设计了基于神经网络的化学传输模型 NN-CTM,来准确表征从排放转化到环境浓度中所经历的一系列大气物理化学过程。与传统的化学传输模型 CTM 相比,它是高效且可微分的,所以可基于浓度观测值和模拟值之间的误差梯度来更新排放清单。
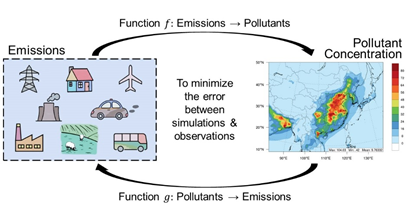
图1:基于对偶学习的排放清单估算框架图
首先,研究员们构建了以神经网络为基础的化学传输模型 NN-CTM,以模拟大气污染物的生成过程。同时结合光照、地理、气象等信息,该模型可模拟出最终空气中的污染物浓度。考虑到 CTM 中复杂的物理化学反应、时空的对流扩散、地理特征等影响,研究员们选用了一个相对复杂的复合神经网络。如图2所示,在该网络中,研究员们用 CNN 实现了对地理位置的编码,用 LSTM 循环神经网络实现了对时序变化信息的编码,用 U-Net 实现了对空间信息的建模。
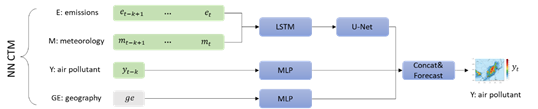
图2:NN-CTM 模型结构
实验结果表明,训练好的 NN-CTM 模型可以很准确地复现大气污染物的数值模拟结果,且误差仅有3%左右,同时模拟速度可达到原数值模型的1000倍。
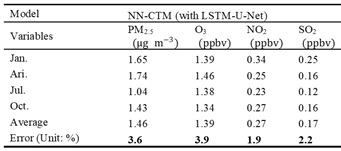
表1:NN-CTM 模型误差
研究员们基于训练好的 NN-CTM 来准确反映排放清单与污染物浓度之间的关系,进而在模型中输入地表和卫星观测的污染物浓度数据,通过误差反向传播的方法来估算新的排放清单。
图3:排放清单反向估算
在本研究中,不同季节对排放清单的调整存在着很大的区别。表2列出了四个月内机器学习方法估算的排放清单(N-Emis)较原始清单(P-Emis)的变化率。新的 N-Emis 结果表明:NOx 在1、10月份增加约3.5~4.0%,而7月份减少超过10%;NH3 的排放量在1月份增加,而在其他三个月减少,其中10月份的降幅最大;SO2 的排放量在所有月内都减少约10%;VOC 的排放量也发生降低,且幅度比 SO2 更大,约20%,这可能与 CTM 对 O3 的高估有关;一次 PM2.5 的排放量在所有月都增加不到5%。
 表2:估算的排放清单相比原始的排放清单区别
表2:估算的排放清单相比原始的排放清单区别
为了进一步分析不同区域的排放变化,研究员们首先选取了5个典型区域:人口密集的京津冀地区(BTH)、长江三角洲地区 (YRD)、珠江三角洲地区(PRD)、四川盆地地区(SCH) ,以及因缺少观测数据而约束条件不足的中国西北部地区(NWC)。并计算了各典型区域内5种排放物4个月的平均排放量在调整前后的变化,如图4所示。
图4:不同区域主要污染物排放量的变化
随后,研究员们将使用调整后的排放清单(N-Emis)的污染物浓度模拟值与612个观测站的数据进行对比,发现NO2、SO2、O3 和 PM2.5 浓度的平均绝对误差(MAE)分别从7.39降低至5.91(20.03%)、3.64降低至3.22(11.54%)、14.33降低至11.56(19.33%)ppbv 和从18.94降低至16.67 (11.99%) μg m-3。结果证明了 N-Emis 的可靠性及本研究应用机器学习方法的实用性。(注:括号内数值为降低率。)
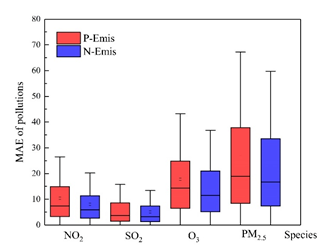
图5:污染物误差对比
本篇论文提出的方法也可以扩展到如 CH4、CO2 等温室气体的排放清单估算问题及其他基础性研究问题上。除此之外,该方法还可以应用到基于实时污染物观测数据所构建的实时排放清单监测系统中。
可以看到,本文的研究成果对环境问题的改善,以及温室气体排放的控制有着十分重要的参考价值。在未来,微软亚洲研究院的研究员们会继续高度关注人类可持续发展中的诸多重要问题,探索 AI 技术在电池材料开发、吸碳材料开发、碳捕捉过程、碳封存过程等各个方面的应用,持续以前沿技术推动可持续发展。
作者:黄麟(微软亚洲研究院),刘松(清华大学),张佳(微软亚洲研究院),邢佳(清华大学)













