
本文主要基于近三年发表的顶会论文(ACL、EMNLP、SIGIR、SIGKDD等),对深度学习在四个数学相关领域的研究工作进行梳理和介绍。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!作者 | 龚政
机构 | 中国人民大学硕士二年级
研究方向 | 自然语言处理
近年来,随着大规模语言模型和其他深度学习技术的迅速发展,人工智能在自然语言的纯文本理解上已经达到了较高的水平。然而自然语言中还存在一类特殊的文本,数学文本,例如日常表达中的数字、数量词以及数学题目中的公式和各种符号。理解这些数学文本通常需要模型具备更强的逻辑能力和推理能力。
目前深度学习中数学相关的研究工作分布在多个领域,本文主要基于近三年发表的顶会论文(ACL、EMNLP、SIGIR、SIGKDD等),对以下四个数学相关领域的研究工作进行梳理和介绍。
Numbers Representation : 数字以及数字相关的量词在自然语言文本中占取了很大的一部分,更好的理解数字可以有效的提升语言模型对数学相关文本的语义理解。由于不可能将每个数字都纳入到语言模型的词表当中,在以往很多研究中,数字要么在文本处理时被直接丢弃或者替换成特殊的符号,要么被切分为和原始语义相去甚远的多个子词。如何对数字进行更好的表示以及如何提升现有语言模型对数值相关问题的理解能力是本部分工作的关注重点。
Math Word Problem Solving : Math Word Problem (MWP) 是一类简单的数学应用题目。给定一段有关真实场景的描述和问题,模型需要根据这段文本生成一个表达式,然后计算出相应的答案,下图是一个具体例子。
(图片来自于论文《MWPToolkit: An Open-source Framework for Deep Learning-based Math Word Problem Solvers》)这些题目通常来源于小学低年级的数学应用题,不会包含复杂的公式符号,因此模型更关注于如何捕获问题文本和其中出现的数字之间的语义关联。目前MWP的主流解决方法是使用Seq2Seq或者Seq2Tree等生成模型架构,输入问题序列到encoder,然后在decoder端生成对应的表达式的序列或者树结构,最后根据表达式计算出最终答案。
Math Formula Embedding : 前两部分工作更加关注于建模单纯的数字和自然文本之间的关联。而作为数学文本中重要的一部分,数学公式中通常包含大量的数字、变量和操作符,这些符号通过一定的数学规则组合到一起,使数学公式蕴含一定的结构信息。这一部分工作主要关注对数学公式的建模,得到的公式表示通常被用于一些检索任务中,例如输入公式查找相关的数学题目等。
Educational Questions Representation : 数学问题建模的一大应用场景就是教育。这一部分的工作主要关注如何通过大量的数学题语料学习到一个通用的表示模型,模型编码数学问题后得到的表示可以用于许多教育相关的下游任务中,例如题目难度评级、知识点预测以及相似题推荐等。这一部分工作可能更加关注于具有一定复杂性的高年级数学题目文本,这些数学文本通常包含较多公式、图片以及一些相关属性,例如知识点等。如何对这些异构的信息进行统一建模是本部分工作的主要难点之一。
上述四类工作的研究重点和需要解决的问题都互不相同,但彼此之间存在着一定的关联,例如如何很好的建模数字或者数学公式,对理解和解决数学问题都是相当重要的。下面分别对这四个领域的一些近期研究工作进行介绍。
本文试图探究预训练语言模型是否从大规模的训练语料中获取到了足够的数量相关的知识并能很好的加以利用。
具体来说,给定一个探测模板,“XX很重”,模型需要具备一定的数量知识,才能判断出“重”这个词在不同上下文中代表的具体数量级。例如“小明很重”中的”重“可能代表100KG,而”大象很重“中的“重”则可能代表10000KG。
本文针对这一任务场景构建了一个量级分类数据集,并对Word2Vec、ELMO、BERT三种模型进行了评测。实验结果显示,相较于Word2Vec,另外两种上下文相关的语言模型表现要更好。
此外本文按照Bert的训练方式重新训练了一个NumBert模型,相比起原来的Bert,本文将预训练预料中的数字表达全部替换成了科学表示法,例如314.1被替换为3.141 [EXP] 2。这种表示方法显示的增强的数字的量级表达能力,实验表明,基于这种语料训练的NumBert能够更好的捕获量词在不同场景下的所代表的具体数量级。
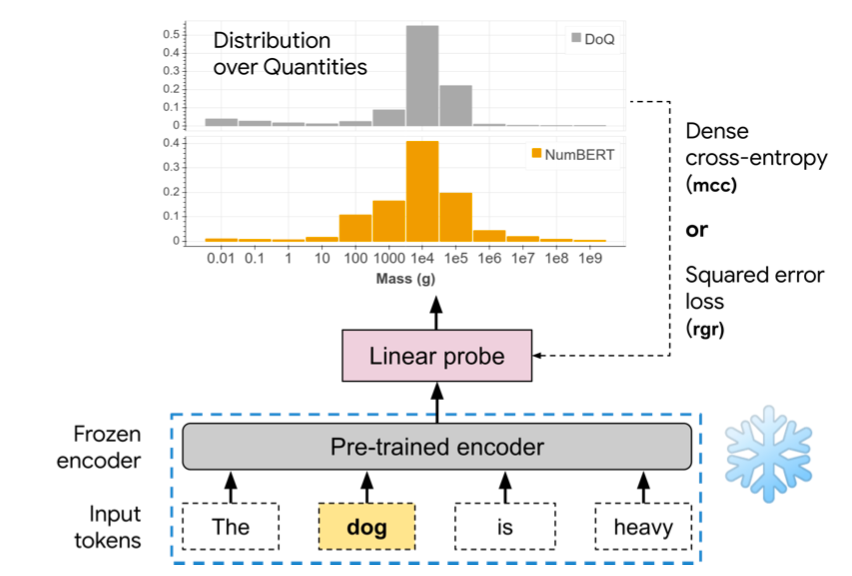
本文试图探究不同的数字表示方法对语言模型的读写能力(literacy)的影响。给定一句话,“[MASK] 的速度是100 km/h“,根据“100 km/h” 可以推断出 [MASK] 为汽车的概率要远大于人或者自行车。这需要模型很好的理解100这个数字在这句话中代表的含义。
本文总共测试了如图所示的六种数字表示方法。实验发现不同的数字表示会在一定程度上影响模型的预测结果,其中Exponent表示法取得了最佳结果。这表明采取合适的数字表示方法能够让语言模型更好的理解文本。
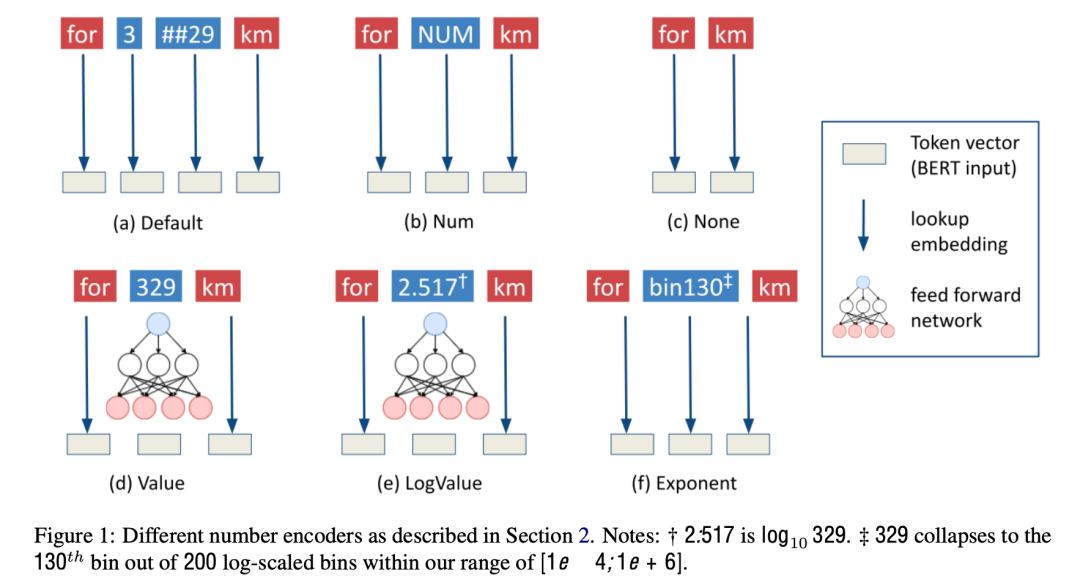
本文提出了一种通用的方法,通过自动生成大量的数据并进行预训练,来向语言模型直接注入数值推理的能力。其首先通过模板生成两类数据:
(1) Numerical Data,全部由数值计算构成的问答文本,例如Q:max(100, 200),A:200;
(2) Textual Data,包含上下文的问答文本,这些文本包含一段上下文以及几个数值相关的问题和答案。
基于这些自动生成的问答样本,本文构造了一个简单的基于BERT的生成模型进行继续预训练。为了防止模型丢失原本的语言知识,本文在继续预训练阶段加入了原始的MLM损失。实验证明,该方法可以有效提升模型在数值推理任务上的表现,成功向模型注入了数值计算的能力。
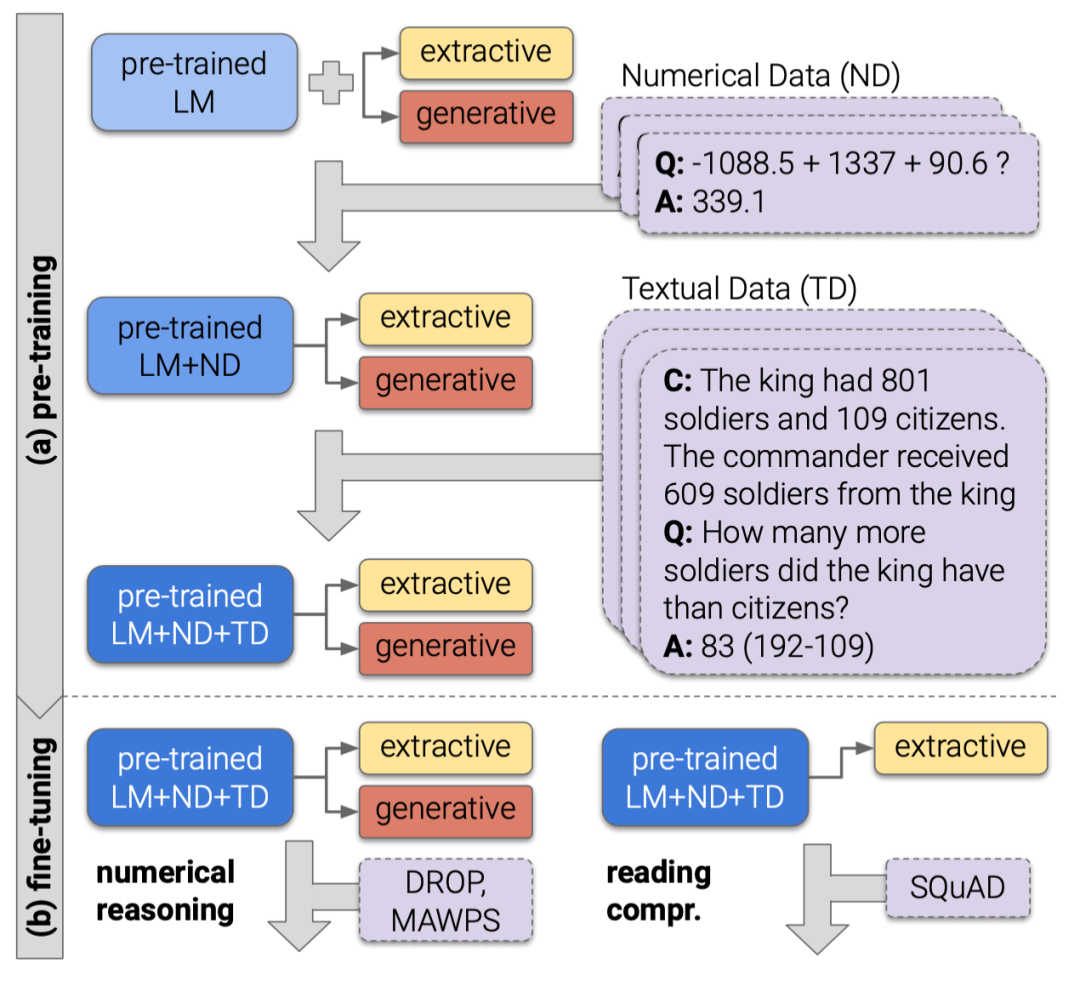
Math Word Problem Solving考虑到单一的encoder-decoder结构难以完全抓住问题文本中包含的语义信息,本文设计一种 Multi-Encoders and Multi-Decoders 的模型架构,以实现从多个层次编码和解码问题序列中的信息。
具体来讲,本文除了将一段问题描述表示为一段文本序列,还通过句法分析工具将其转换为一棵依存句法树。相比起原始的序列,依存句法树可以提供更多关于问题的结构化信息,用于增强问题文本的最终表示。
本文采取GRU和GCN作为sequence-based encoder和graph-based encoder,分别对序列和句法树进行编码。得到的编码结果被同时输入到tree-based decoder 和 sequence-based decoder中,两个解码器会分别生成表达式的后缀形式和前缀形式,最后模型根据两个decoder生成表达式的概率大小来选择最终的答案。
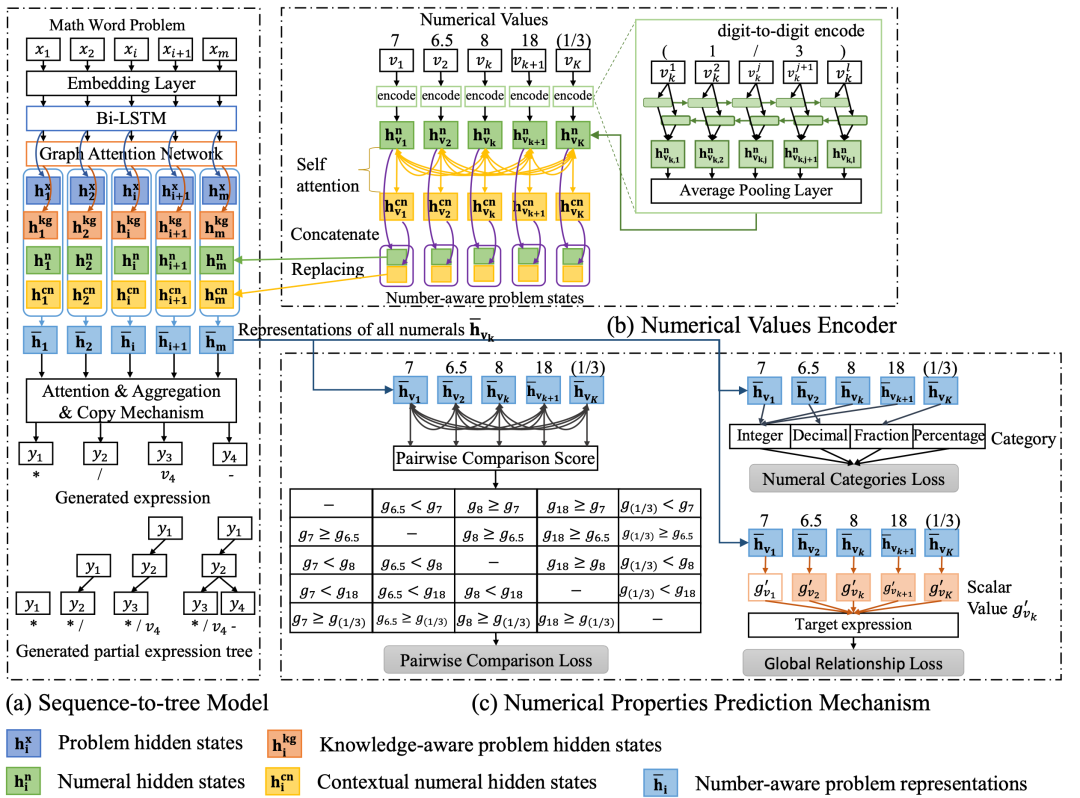
前文提到过,由于MWP中可能出现的数字是无穷的,很难将所有可能出现的数字都纳入到模型的词表当中,因此之前的研究工作通常将问题中出现的数字全部替换成统一的变量符号。
本文考虑到当同样的变量符号代表不同的数值时,最终的答案表达式可能也有所不同,下图提供了一个具体的例子。

为了解决这一问题,本文在原有的Seq2Tree架构上加入了一个Numerical Values Encoder用于对数字进行编码,得到编码结果和原有encoder得到的编码结果进行concat,以增强问题的编码表示。其在解码段设计了一种Numerical Properties Prediction Mechanism,通过将问题中的数字进行两两对比来决定哪些数字应该出现在最终的表达式当中。
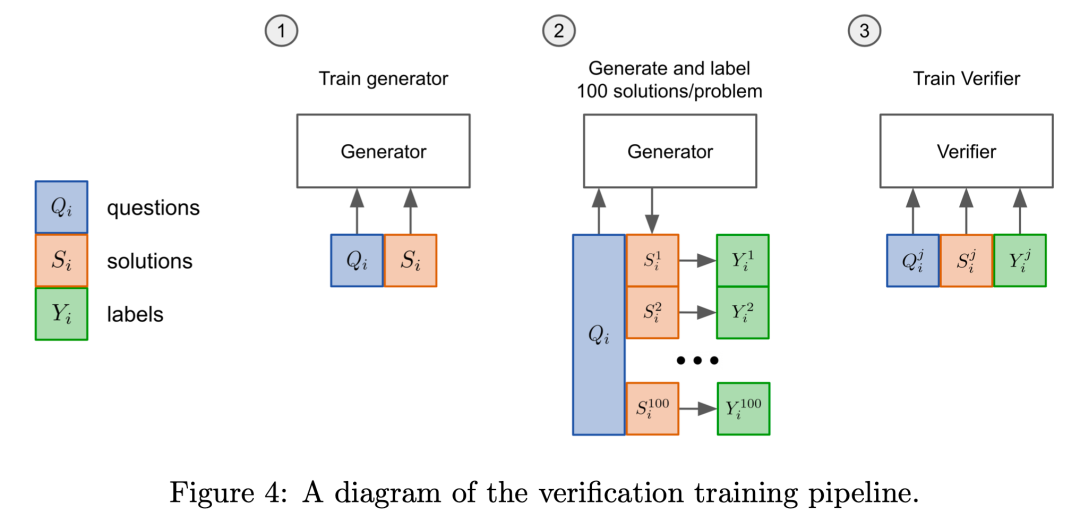
当前尝试解决MWP的研究工作大多基于一种微调的范式,即给定一个问题和最终答案的表达式,微调根据交叉熵损失训练一个生成器,在测试阶段生成器通过自回归采样,生成单个低温表达式并检查最终答案是否正确来判断性能。本文在此基础上引入一个验证器,使用验证的方式对模型进行训练。
具体来说,验证的训练方式包含两个部分:(1) 首先通过上述微调过程对生成器进行训练;(2)训练得到的生成器用于对问题生成多个高温表达式,这些表达式根据最终得到的结果是否和正确答案相匹配来进行标注,然后用这些表达式和标签去训练验证器。最终得到的验证器用于在测试时对生成器生成的表达式进行打分,分数最高的表达式被用于计算最终答案。
实验表明,相比起之前使用单一的生成器进行微调并根据采样概率来选择表达式的方式,引入额外的验证器来选择表达式具有更高的效率。
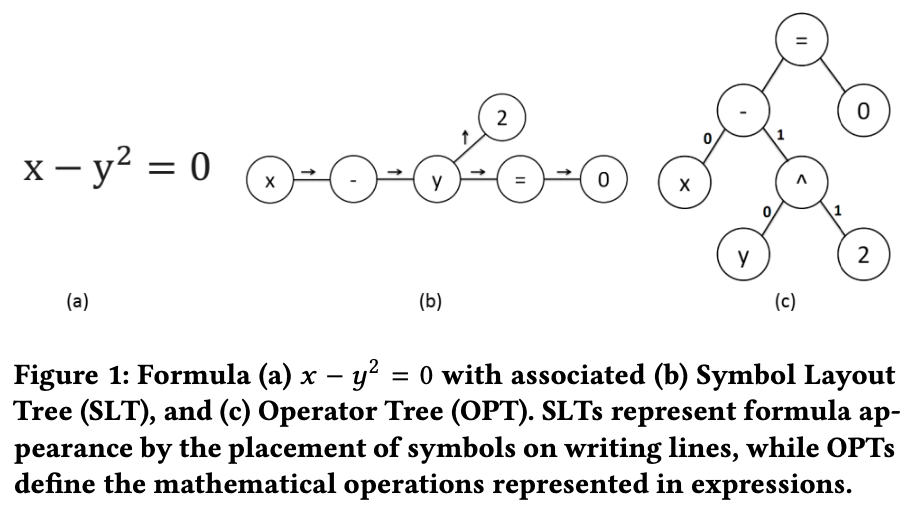
考虑到数学公式中通常包含丰富的结构化信息,本文利用数学公式的两种层次化表示来对数学公式进行嵌入。其首先将数学公式转换为两种树结构:
(1)Symbol Layout Tree(SLT),表示数学公式各个符号的空间位置;
(2)Operator Tree(OPT),定义了数学公式中各个操作符的计算顺序。然后将树的结点和边表示成多个元组,最后使用fastText对这些元组进行编码。
通过结合SLT和OPT两种树结构的编码结果,最后获取的公式嵌入同时捕获到了公式的空间结构信息和语义结构信息,在公式检索任务上取得了有效提升。
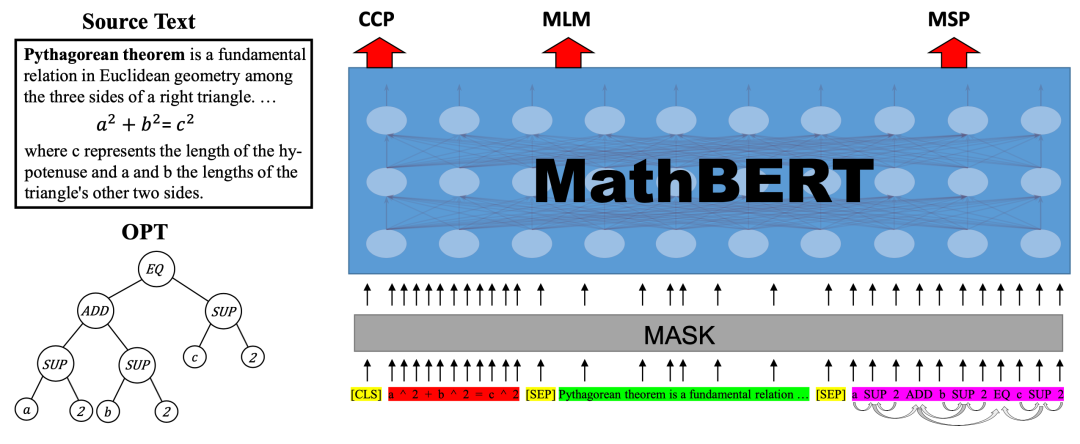
本文将预训练语言模型引入数学公式编码任务中。其基于BERT,提出一种在数学语料上继续预训练的方法。
本文同时考虑到公式内蕴含的结构化信息和公式的上下文中可能包含一些公式相关的说明文本,将公式、公式的上下文以及公式的Operator Tree(OPT)同时输入到语言模型中进行预训练。模型在预训练同时学习三个预训练任务:
(1)Masked Language Modeling;
(2)Context Correspondence Prediction,预测输入的上下文和输入的公式是否相关联;
(3)Masked Substructure Prediction,选取OPT中一定比例的结点,对这些结点的父结点和子结点进行预测。为了让模型更好的捕获OPT中的结构信息,本文对输入的OPT部分的attention矩阵进行修改,让每个结点只能注意到和其相连的结点。
Educational Questions Representation在教育场景下,数学问题通常包含除了文本以外的许多信息,例如图片以及问题相关的知识点。
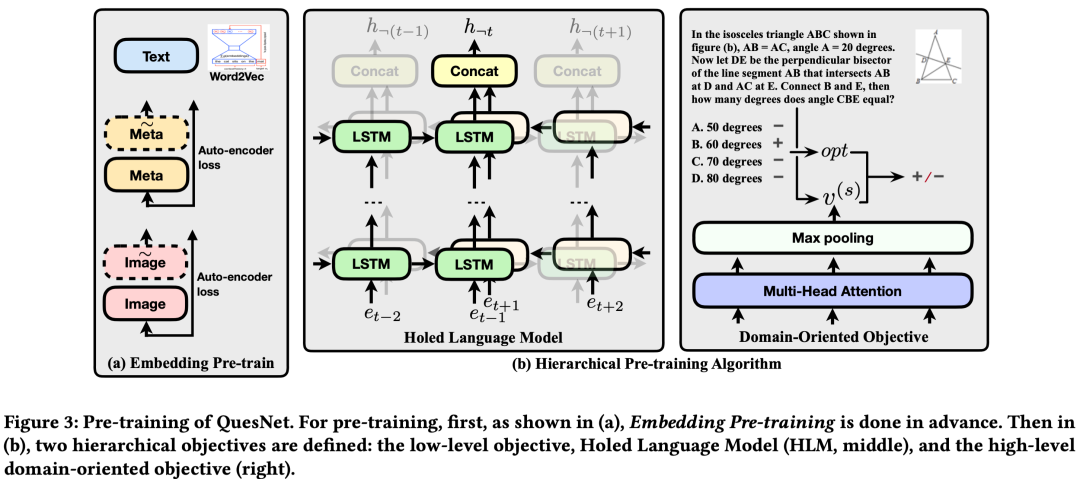
本文提出一种通用的模型架构,用于对文本序列、图片、知识点等基本单元进行统一建模。其首先通过Embedding层将三部分信息映射到同一个向量空间,然后用双向的LSTM对embedding后的向量序列进行编码,得到每个基本单元的token表示,最后用self-attention和max-pooling对这些token表示进行聚合,得到最终整个数学问题的表示。
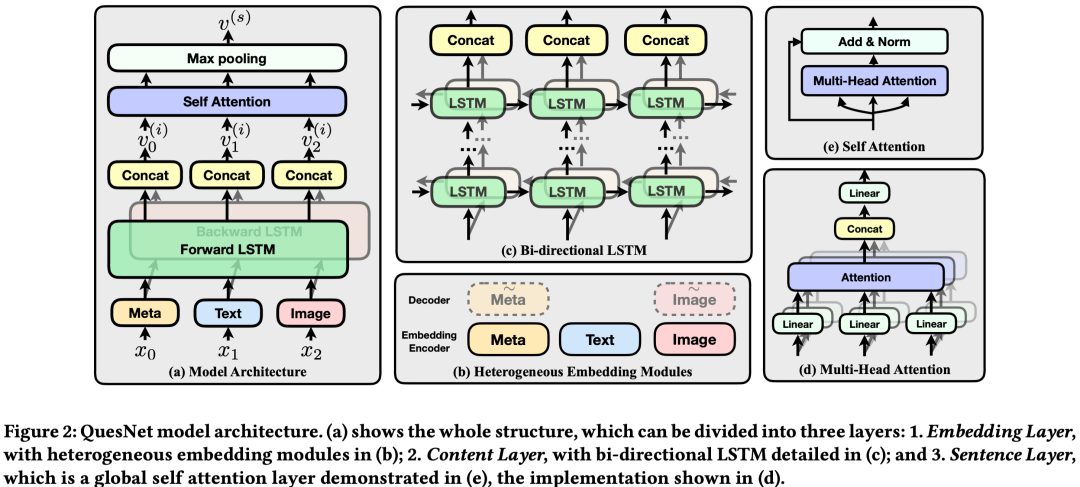
本文进一步提出两个预训练任务,分别从token level和sentence level对上述模型进行预训练。
其中token level的预训练任务holed language model (HLM) 根据每个token两边的LSTM输出的hidden states对当前token的信息进行还原。sentence level的预训练任务利用了问题相关的答案信息,输入一个问题和答案对,判断两者是否匹配。
此外,本文还对embedding layer进行了预训练,其中文本embedding层采用word2vec的方式训练,图像和知识点的embedding层采用auto-encoder的方式进行训练。
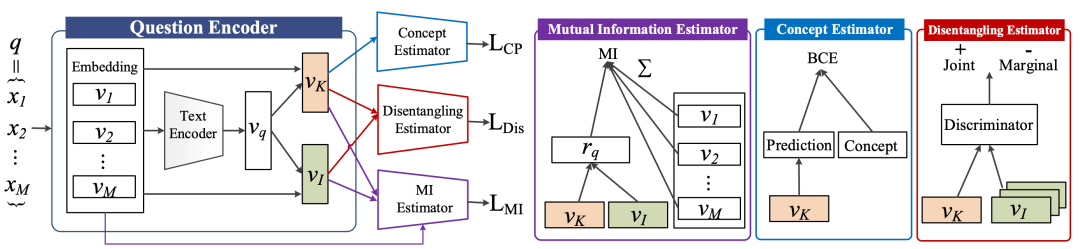
本文提出一种无监督的模型和自监督训练方式为每个数学问题同时训练两种表示:
(1)concept representation,显式的存储知识点相关的信息;
(2)individual representation,只保留文本相关信息的表示。其出发点在于数学文本中的某些词汇可能和知识点更为相关,而某些词汇更倾向于描述题目本身的场景。
为了解决这一问题,
本文将编码后的数学文本表示用不同参数的attention模块进一步分离为concept和individual两种表示,并设计三个自监督任务:
(1)Mutual Information Estimator,让分离后的两种表示和原本的编码表示互信息最大化;
(2)Concept Estimator,利用得到的concept表示预测题目相应的知识点;
(3)Disentangling Estimator,采用对抗训练的方式拉远concept和individual两种表示的距离。模型在无标注的数据上同时优化这三个任务,以实现进一步分离和增强concept和individual两种表示。
总结与展望
本文分别从四个数学相关的领域介绍了一些近期研究进展。从以上研究工作中可以看出,如何对更好的对数字、公式以及数学问题进行建模,是当前各研究工作的重点。
目前各个研究工作已经能够在一定程度上理解和表示数学文本并解决一些简单的数学应用题。但近期还有一部分工作表明,对于复杂的数学问题解答,例如高中、大学的数学题目,现有的模型依然束手无策。
当前预训练语言模型的发展表明,通过在大量无标注的文本上预训练,语言模型已经可以学习到和人类相当的常识知识,用于解决一些传统的NLP任务。效仿这一点,如果能设计出合适的结构和任务,让语言模型像人类一样大量的刷题和补充相关知识点,或许模型有一天在数学问题上也能够具备和人类一样的推理和解答能力。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。







