点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作为一种常见的多元统计分析方法,主成分分析法(Principal Component Analysis,PCA)也是一种经典的无监督学习算法。PCA通过正交变换将一组由线性相关变量表示的数据转换为少数几个由线性无关变量表示的数据,这几个线性无关的变量就是主成分。PCA通过将高维数据维度减少到少数几个维度,本质上属于一种数据降维方法,也可以用来探索数据的内在结构。
import numpy as np
class PCA(): def calculate_covariance_matrix(self, X): m = X.shape[0] X = X - np.mean(X, axis=0) return 1 / m * np.matmul(X.T, X)
def pca(self, X, n_components): covariance_matrix = self.calculate_covariance_matrix(X) eigenvalues, eigenvectors = np.linalg.eig(covariance_matrix) idx = eigenvalues.argsort()[::-1] eigenvectors = eigenvectors[:, idx] eigenvectors = eigenvectors[:, :n_components] return np.matmul(X, eigenvectors)
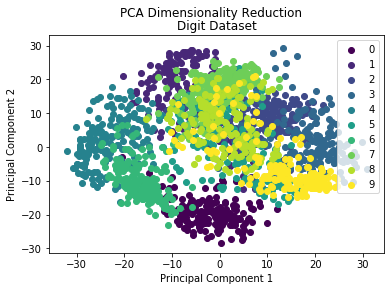
由上述代码可以看到,基于numpy我们仅需要数行核心代码即可实现一个PCA降维算法。下面以sklearn digits数据集为例看一下降维效果:
from sklearn import datasetsimport matplotlib.pyplot as pltimport matplotlib.cm as cmximport matplotlib.colors as colors
data = datasets.load_digits()X = data.datay = data.target
X_trans = PCA().pca(X, 2)x1 = X_trans[:, 0]x2 = X_trans[:, 1]
cmap = plt.get_cmap('viridis')colors = [cmap(i) for i in np.linspace(0, 1, len(np.unique(y)))]
class_distr = []for i, l in enumerate(np.unique(y)): _x1 = x1[y == l] _x2 = x2[y == l] _y = y[y == l] class_distr.append(plt.scatter(_x1, _x2, color=colors[i]))
plt.legend(class_distr, y, loc=1)
plt.suptitle("PCA Dimensionality Reduction")plt.title("Digit Dataset")plt.xlabel('Principal Component 1')plt.ylabel('Principal Component 2')plt.show();
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲
,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~









