用Python进行数据可视化你会用什么库来做呢?
今天就来和大家分享Python数据可视化库中的一员猛将——Altair!
它非常简单、友好,并基于强大的Vega-Lite JSON规范构建,我们只需要简短的代码即可生成美观、有效的可视化效果。
Altair是统计可视化Python 库,目前在GitHub上已经收获超过3000 Star。
借助Altair,我们可以将更多的精力和时间放在理解数据本身及数据意义上,从复杂的数据可视化过程中解脱出来。
简单来说,Altair是一种可视化语法,也是一种创建、保存和分享交互式可视化设计的声明式语言,可以使用JSON 格式描述可视化的外观和交互过程,产生基于网络的图像。
我们来看看利用Altair做出的可视化效果!
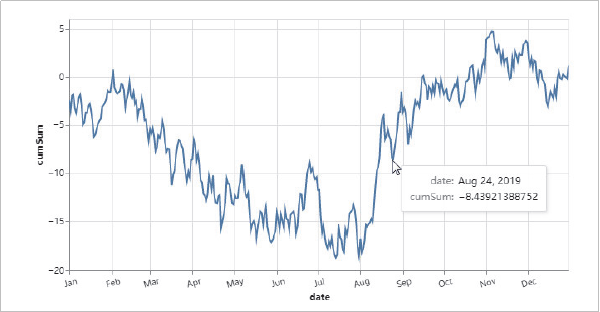
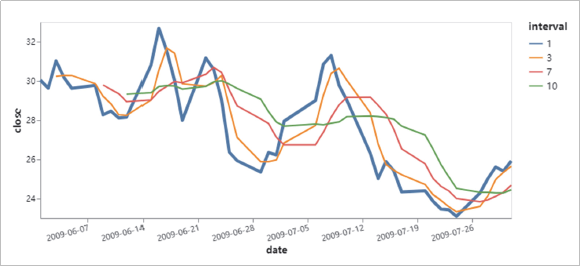
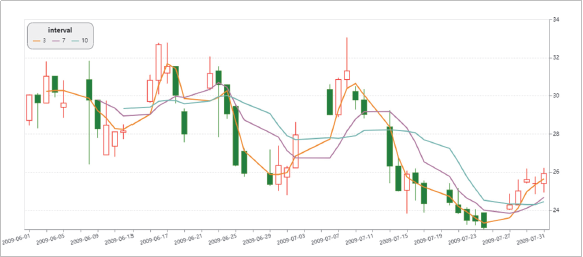
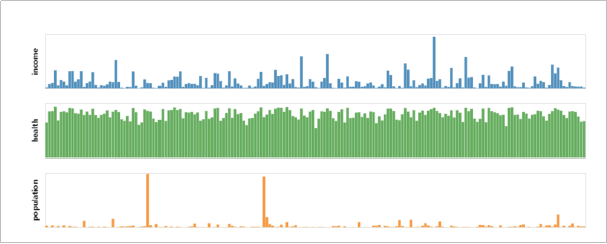
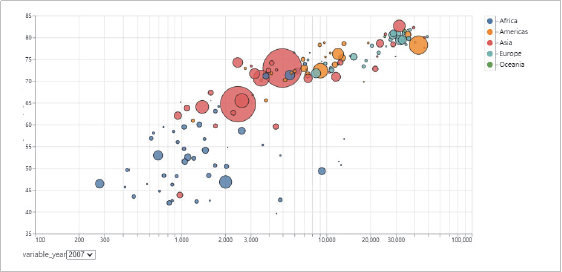
Altair可以通过分类汇总(aggregation)、数据变换(datatransformation)、数据交互、图形复合等方式全面地认识数据、理解数据和分析数据。这些过程都可以帮助我们增加对数据本身和数据意义的理解维度,培养直观的数据分析思维。
总的来看,Altair 的特点有以下几个方面。
- 基于Vega-Lite 的JSON 语法规则生成Altair 的Python 代码。
- 在启动的Jupyter Notebook、JupyterLab 和nteract 中展示统计可视化过程。
- 可以将可视化作品导出为PNG/SVG 格式的图片、独立运行的HTML 格式的网页,或者在线上Vega-Lite 编辑器中查看运行效果。
在Altair中,使用的数据集要以“整洁的格式”加载。Pandas 中的 DataFrame 是 Altair 使用的主要数据结构之一。Altair对Pandas的DataFrame有很好地加载效果,加载方法简单高效。例如,使用Pandas读取Excel数据集,使用Altair加载Pandas返回值的实现代码,如下所示:
import altair as alt
import pandas as pd
data = pd.read_excel( "Index_Chart_Altair.xlsx", sheet_name="Sales", parse_dates=["Year"] )
alt.Chart( data )
Altair 很强调变量类型的区分和组合。变量的取值是数据,且有差异,有数值、字符串、日期等表现形式。变量是数据的存储容器,数据是变量的存储单元内容。
另一方面,从统计抽样角度来看,变量是总体,数据是样本,需要使用样本研究和分析总体。可以通过将不同的变量类型相互组合从而生成统计图形,以便更直观地认识数据。
按照不同变量类型的组合方式划分,变量类型的组合方式可以分为如下几种。
其中,时间型变量是一种特殊类型的数量型变量,可以将时间型变量设定为名义型变量(N)或次序型变量(O),实现时间型变量的离散化,从而形成与数量型变量的组合。
这里以名义型变量+数量型变量中的一条来讲解。
如果将数量型变量映射到x 轴,将名义型变量映射到y 轴,依然将柱体作为数据的编码样式(标记样式),就可以绘制条形图。条形图可以更好地使用长度变化比较商品销售利润的差距,如下图所示。
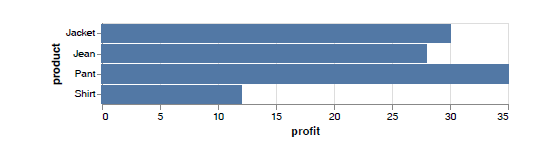
对照柱形图的实现代码,条形图的实现代码变化的部分如下所示。
chart = alt.Chart(df).mark_bar().encode(x="profit:Q",y="product:N")
是不是很简单呢?
下面就演示一下分区展示不同年份的每月平均降雨量!
我们可以使用面积图描述西雅图从2012 年到2015 年的每个月的平均降雨量统计情况。接下来,进一步拆分平均降雨量,以年份为分区标准,使用阶梯图将具体年份的每月平均降雨量分区展示,如下图所示。
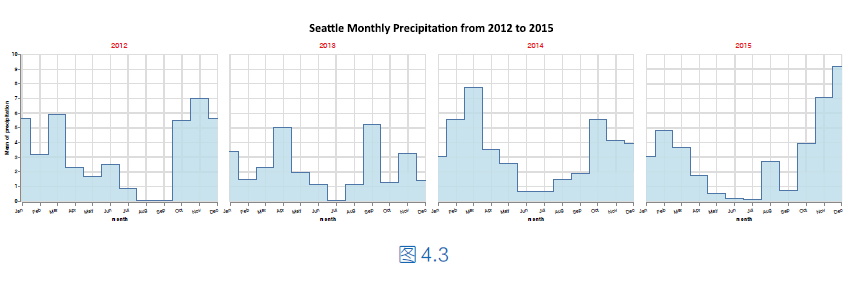
核心的实现代码如下所示。
…
chart = alt.Chart(df).mark_area(
color="lightblue",
interpolate="step",
line=True,
opacity=0.8
).encode(
alt.X("month(date):T",
axis=alt.Axis(format="%b",
formatType="time",
labelAngle=-15,
labelBaseline="top",
labelPadding=5,
title="month")),
y="mean(precipitation):Q",
facet=alt.Facet("year(date):Q",
columns=4,
header=alt.Header(
labelColor="red",
labelFontSize=15,
title="Seattle Monthly Precipitation from 2012 to 2015",
titleFont="Calibri",
titleFontSize=25,
titlePadding=15)
)
0)
…
在类alt.X()中,使用month 提取时间型变量date 的月份,映射在位置通道x轴上,使用汇总函数mean()计算平均降雨量,使用折线作为编码数据的标记样式。
在实例方法encode()中,使用子区通道facet 设置分区,使用year 提取时间型变量date 的年份,作为拆分从2012 年到2015 年每个月的平均降雨量的分区标准,从而将每年的不同月份的平均降雨量分别显示在对应的子区上。使用关键字参数columns设置子区的列数,使用关键字参数header 设置子区序号和子区标题的相关文本内容。
具体而言,使用Header 架构包装器设置文本内容,也就是使用类alt.Header()的关键字参数完成文本内容的设置任务,关键字参数的含义如下所示。
- titlePadding:子区标题与序号标签的留白距离。
如有文章对你有帮助,
“在看”和转发是对我最大的支持!

关注Python极客专栏











