
凡是搞计量经济的,都关注这个号了
稿件:econometrics666@126.com
所有计量经济圈方法论丛的code程序
, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.

2021年三位诺奖得主在获得诺奖后首次见面
前面引荐过两诺奖得主谈计量经济学发展进化, 机器学习的影响, 如何合作推动新想法!而最近又看到“Michael C Knaus, Double machine learning based program evaluation under unconfoundedness, The Econometrics Journal, 2022;, utac015”在计量社群传阅得比较多。从中了解到,双重机器学习方法相对于传统的倾向匹配、双重差分、断点回归等因果推断方法,有非常多的优点,包括但不限于适用于高维数据(传统的计量方法在解释变量很多的情况下不便使用),且不需要预设协变量的函数形式。今天,我们通过社群里分享的相关文章和资料对双重机器学习进行简要介绍,包括如何使用软件对该方法进行实现。
而在Knaus(2022)之前,Chernozhukov et al. (2018) 已经将双重机器学习方法应用在了平均处理效应(Average Treatment Effects)、局部处理效应(Local Average Treatment Effects)和部分线性IV模型(Partially Linear IV Models)等中。他们通过三个案例,包括失业保险对失业持续时间的影响、401(k)养老金参与资格对于净金融资产的影响、制度对经济增长的长期影响,拓展了双重机器学习在政策评估中的应用场景。
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, James Robins, Double/debiased machine learning for treatment and structural parameters, The Econometrics Journal, Volume 21, Issue 1, 1 February 2018, Pages C1–C68,
注:下面的①和②的参考资料都在文后的reference里
①
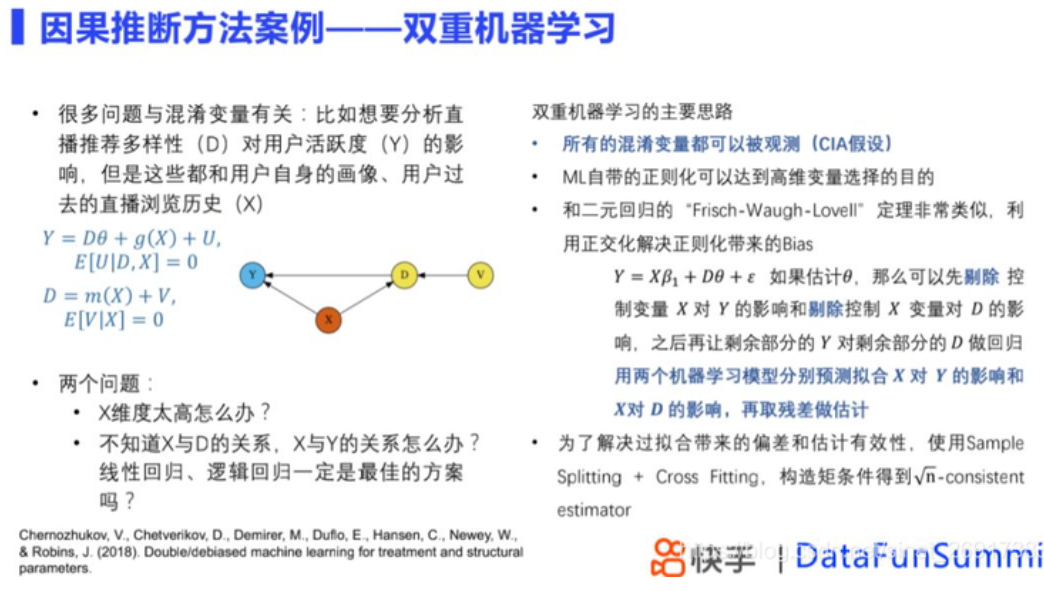
因果推断会遇到混淆变量的问题,比如想要去分析直播推荐多样性对用户活跃度的影响,但是这些都和用户历史相关。传统计量经济学方法可以解决这个问题,但是依赖很多强假设,强假设下,得到的估计不一定合理,双重机器学习为这个问题提供了解决的思路。
双重机器学习假设所有混淆变量都可以被观测,其正则化过程能够达到高维变量选择的目的,与Frisch-Waugh-Lovell定理相似,模型通过正交化解决正则化带来的偏差。除了上面所描述的,还有一些问题待解决,比如在ML模型下存在偏差和估计有效性的问题,这个时候可以通过Sample Splitting 和 Cross Fitting的方式来解决,具体做法是我们把数据分成一个训练集和估计集,在训练集上我们分别使用机器学习来拟合影响,在估计集上我们根据拟合得到的函数来做残差的估计,通过这种方法,可以对偏差进行修正。在偏差修正的基础上,我们可以对整个估计方法去构造一个moment condition,得到置信区间的推断,从而得到一个有良好统计的估计。
②
从非实验数据中考察变量之间的因果关系是社会科 学研究的主要目标之一。然而,相关计量方法,如倾向匹 配、双重差分、断点回归等,都有依赖严格的前提条件,从 而对实证应用造成了诸多限制。在非常宽松的假设条件 下,Chernozhukov等(2018)提出了双重机器学习(Double machine learning)方法来估计处理效应。与传统模型相 比,双重机器学习方法适用于高维数据,且不需要预设协变量的函数形式。因此,基于双重机器学习的因果效应估计能弥补传统方法的缺点,在处理经济变量之间的非线性关系上具有极大优势。


③
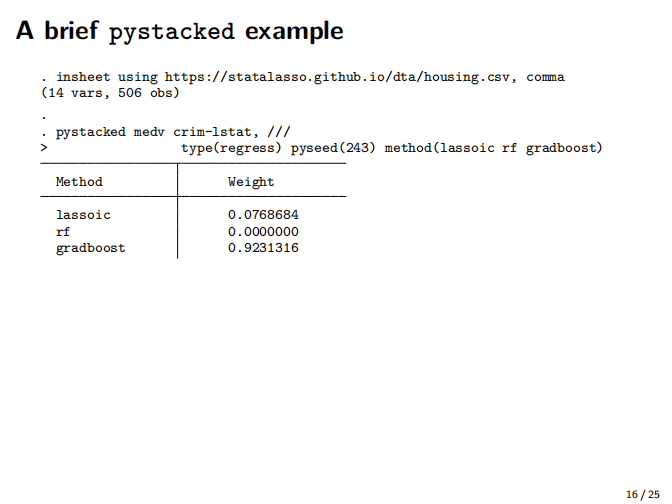
在2021年德国Stata会议上关于双重机器学习的最新进展以及Stata实现程序,ddml和pystacked。

























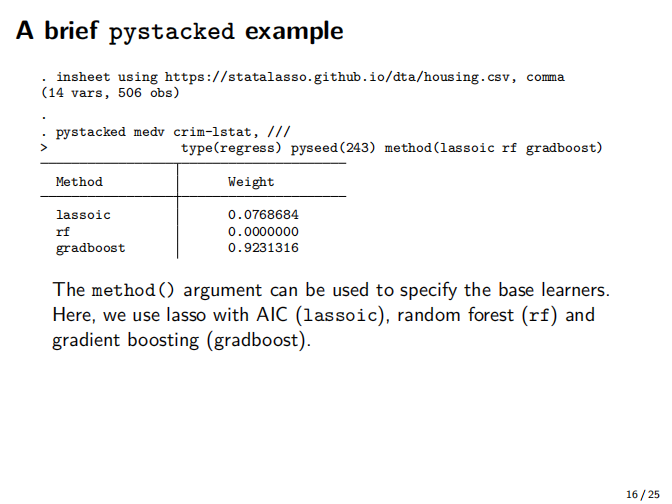










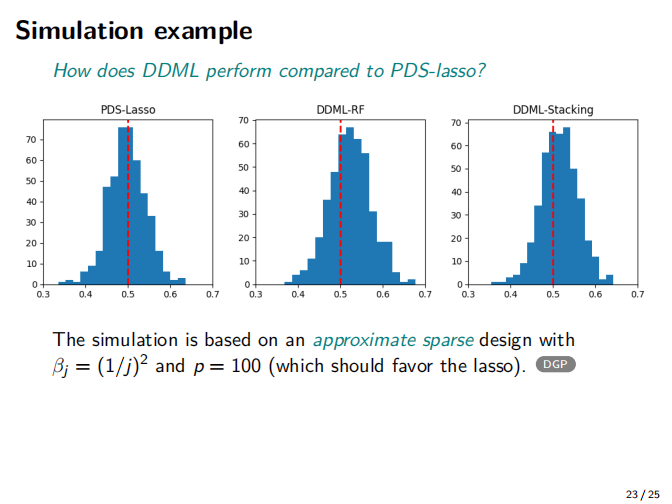











④
James MacKinnon教授也分享了一份关于双重机器学习的Slides供大家学习。
















Reference:
①DataFunSummit
②杨利雄,赵君昌,李庆男.双重机器学习处理效应估计的蒙特卡洛模拟[J].统计与决策,2022,38(06):26-31.
关于机器学习,参看1.
机器学习之KNN分类算法介绍: Stata和R同步实现(附数据和代码),2.机器学习对经济学研究的影响研究进展综述,3.回顾与展望经济学研究中的机器学习,4.最新: 运用机器学习和合成控制法研究武汉封城对空气污染和健康的影响! 5.Top, 机器学习是一种应用的计量经济学方法, 不懂将来面临淘汰危险!6.Top前沿: 农业和应用经济学中的机器学习, 其与计量经济学的比较, 不读不懂你就out了!7.前沿: 机器学习在金融和能源经济领域的应用分类总结,8.机器学习方法出现在AER, JPE, QJE等顶刊上了!9.机器学习第一书, 数据挖掘, 推理和预测,10.
从线性回归到机器学习, 一张图帮你文献综述,11.11种与机器学习相关的多元变量分析方法汇总,12.机器学习和大数据计量经济学, 你必须阅读一下这篇,13.机器学习与Econometrics的书籍推荐, 值得拥有的经典,14.机器学习在微观计量的应用最新趋势: 大数据和因果推断,15.R语言函数最全总结, 机器学习从这里出发,16.机器学习在微观计量的应用最新趋势: 回归模型,17.机器学习对计量经济学的影响, AEA年会独家报道,18.回归、分类与聚类:三大方向剖解机器学习算法的优缺点(附Python和R实现),19.关于机器学习的领悟与反思,20.
机器学习,可异于数理统计,21.前沿: 比特币, 多少罪恶假汝之手? 机器学习测算加密货币资助的非法活动金额! 22.利用机器学习进行实证资产定价, 金融投资的前沿科学技术! 23.全面比较和概述运用机器学习模型进行时间序列预测的方法优劣!24.用合成控制法, 机器学习和面板数据模型开展政策评估的论文!25.更精确的因果效应识别: 基于机器学习的视角,26.一本最新因果推断书籍, 包括了机器学习因果推断方法, 学习主流和前沿方法,27.如何用机器学习在中国股市赚钱呢? 顶刊文章告诉你方法!28.机器学习和经济学, 技术革命正在改变经济社会和学术研究,29.世界计量经济学院士新作“大数据和机器学习对计量建模与统计推断的挑战与机遇”,30.
机器学习已经与政策评估方法, 例如事件研究法结合起来识别政策因果效应了!31.重磅! 汉森教授又修订了风靡世界的“计量经济学”教材, 为博士生们增加了DID, RDD, 机器学习等全新内容!32.几张有趣的图片, 各种类型的经济学, 机器学习, 科学论文像什么样子?33.机器学习已经用于微观数据调查和构建指标了, 比较前沿!34.两诺奖得主谈计量经济学发展进化, 机器学习的影响, 如何合作推动新想法!
下这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
3.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。












