CnOCR 是 Python 3 下的文字识别(Optical Character Recognition,简称OCR)工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带了20+个训练好的识别模型,适用于不同应用场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。欢迎加入 交流群。CnOCR 追求的目标一直是使用简单,而不是实现各种最新的模型算法。
CnOCR V2.2 前两天终于上线了,内部集成了场景文字检测功能,终于不挑图片了~。而且,文档做了大规模更新,可爱多了~。
官方代码库:https://github.com/breezedeus/cnocr 。
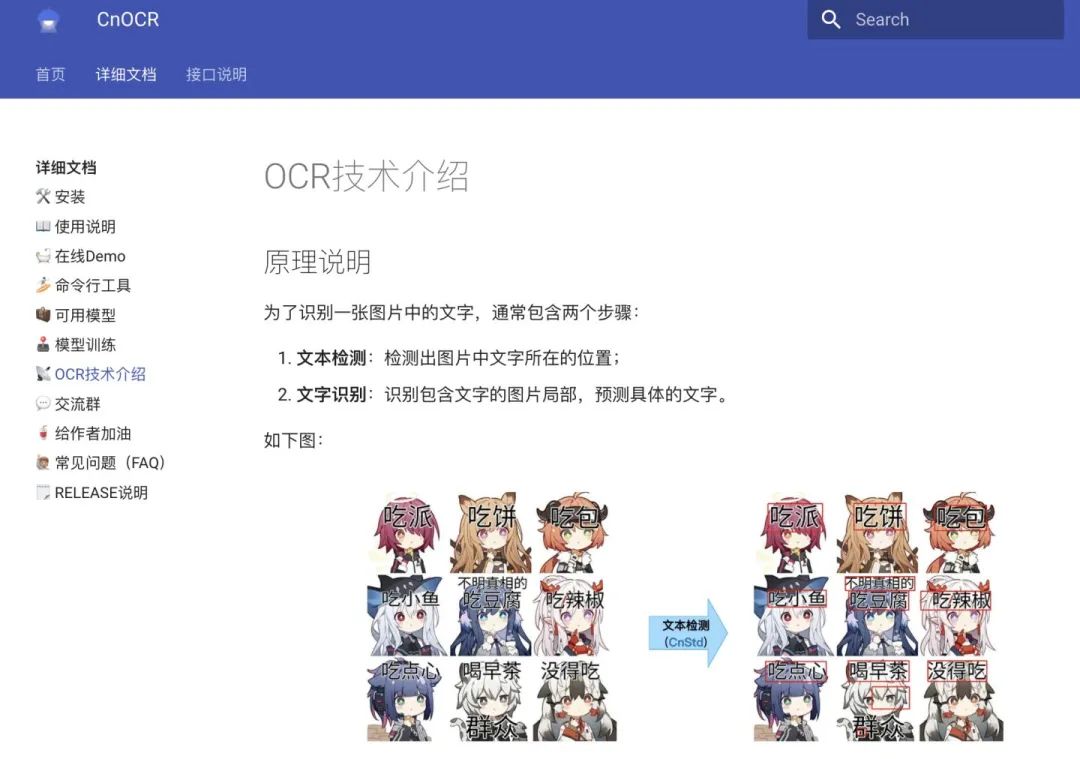
可以使用 在线 Demo (https://cnocr.readthedocs.io/zh/latest/demo/) 查看效果。
之前版本把文本检测 CnSTD 分离出来的初衷是 CnOCR 不用依赖opencv,降低安装成本,结果发现opencv的安装对大部分人来说不是事。分离出来的另一个问题是很多人在第一次用CnOCR时都是在随便的一张图片上看效果,然后觉得效果很差就不用了。真正结合CnSTD试验效果的人很少。从 V2.2 开始,CnOCR 内部调用 CnSTD 进行文本检测,这样整个文本检测+文本识别过程都在 CnOCR 内部完成,对用户完全透明。
CnOCR 新版 V2.2 会比 PaddleOCR (ppocr) 好用,主要体现在四个方面:
CnOCR 安装更简单,不依赖PaddlePaddle;
CnOCR 使用更简单,主要接口依旧就3个,文档尽量简洁明了;
CnOCR 精度不低于 ppocr,因为 CnOCR 中引入了 ppocr 的主要模型(ONNX版本)。而且从我的使用经验看,CnOCR 自己训练的模型在某些场景精度是比 ppocr 模型更高的,比如不常见的汉字排列,简单的文字截图图片;
CnOCR 速度更快。CnOCR 中支持的ppocr模型是 ONNX版本,会比 ppocr 的 paddle版本更快一倍左右(经验值)。而且 CnOCR 自己训练的部分识别模型更精简,速度也会更快。
安装简单
嗯,顺利的话一行命令即可完成安装。
> pip install cnocr
更多说明可见 安装文档。
注:如果电脑中从未安装过 PyTorch,OpenCV python包,初次安装可能会遇到问题,但一般都是常见问题,可以自行百度/Google解决。
各种场景的调用示例
常见的图片识别
所有参数都使用默认值即可。如果发现效果不够好,多调整下各个参数看效果,最终往往能获得比较理想的精度。
from cnocr import CnOcr
img_fp = './docs/examples/huochepiao.jpeg'
ocr = CnOcr() # 所有参数都使用默认值
out = ocr.ocr(img_fp)
print(out)
识别结果:

排版简单的印刷体截图图片识别
针对 排版简单的印刷体文字图片,如截图图片,扫描件图片等,可使用 det_model_name='naive_det',相当于不使用文本检测模型,而使用简单的规则进行分行。
使用 det_model_name='naive_det' 的最大优势是速度快,劣势是对图片比较挑剔。如何判断是否该使用此检测模型呢?最简单的方式就是拿应用图片试试效果,效果好就用,不好就不用。
from cnocr import CnOcr
img_fp = './docs/examples/multi-line_cn1.png'
ocr = CnOcr(det_model_name='naive_det')
out = ocr.ocr(img_fp)
print(out)
识别结果:

竖排文字识别
采用来自 ppocr 的中文识别模型 rec_model_name='ch_PP-OCRv3' 进行识别。
from cnocr import CnOcr
img_fp = './docs/examples/shupai.png'
ocr = CnOcr(rec_model_name='ch_PP-OCRv3')
out = ocr.ocr(img_fp)
print(out)
识别结果:

英文识别
虽然中文检测和识别模型也能识别英文,但专为英文文字训练的检测器和识别器往往精度更高。如果是纯英文的应用场景,建议使用来自 ppocr 的英文检测模型 det_model_name='en_PP-OCRv3_det', 和英文识别模型 rec_model_name='en_PP-OCRv3' 。
from cnocr import CnOcr
img_fp = './docs/examples/en_book1.jpeg'
ocr = CnOcr(det_model_name='en_PP-OCRv3_det', rec_model_name='en_PP-OCRv3')
out = ocr.ocr(img_fp)
print(out)
识别结果:

繁体中文识别
采用来自ppocr的繁体识别模型 rec_model_name='chinese_cht_PP-OCRv3' 进行识别。
from cnocr import CnOcr
img_fp = './docs/examples/fanti.jpg'
ocr = CnOcr(rec_model_name='chinese_cht_PP-OCRv3') # 识别模型使用繁体识别模型
out = ocr.ocr(img_fp)
print(out)
使用此模型时请注意以下问题:
识别精度一般,不是很好;
除了繁体字,对标点、英文、数字的识别都不好;
此模型不支持竖排文字的识别。
识别结果:

单行文字的图片识别
如果明确知道待识别的图片是单行文字图片(如下图),可以使用类函数 CnOcr.ocr_for_single_line() 进行识别。这样就省掉了文字检测的时间,速度会快一倍以上。

调用代码如下:
from cnocr import CnOcr
img_fp = './docs/examples/helloworld.jpg'
ocr = CnOcr()
out = ocr.ocr_for_single_line(img_fp)
print(out)
更多应用示例


更多文档
请见:https://cnocr.readthedocs.io 。
知识星球私享群
作者也维护 知识星球CnOCR/CnSTD私享群 (
https://wx.zsxq.com/dweb2/index/group/28858522821151) ,欢迎加入。知识星球私享群会陆续发布一些CnOCR/CnSTD相关的私有资料,包括更详细的训练教程,未公开的模型,使用过程中遇到的难题解答等。本群也会发布OCR/STD相关的最新研究资料。此外,私享群中作者每月提供两次免费特有数据的训练服务。






