点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

数据清理是一个非常耗时的任务,在应用机器学习模型之前,你需要获得待处理的数据,然后你会意识到这些数据是一团乱麻。
根据IBM数据分析的观点 —— 数据科学家花费80%的时间来寻找、清理和组织数据上,只用20%的时间来分析数据。
在这篇文章中,我们将使用Python的panda库来完成许多不同的数据清理任务,具体来说,我们将关注最大的数据清理任务——丢失值。
阅读这篇文章后,你将更够更快的清理数据 。我们都想少花点时间清理数据,多花点时间研究数据分析模型。
1. 缺失值的来源
在深入研究代码之前,了解缺失值的来源非常重要。以下是数据丢失的一些典型原因:
用户忘记填写表格某一项的内容
数据传输时,丢失了数据
编程错误
用户基于隐私的原因,没有填写表格
正如你所看到的的,这些来源中的一些知识简单的随机错误,其他时候,可能是更深层次的原因。
从统计的角度理解这些不同类型的缺失数据是非常重要的,丢失数据的类型将影响你如何填充丢失值。
2. 获取数据基本信息
在开始清理数据集之前,最好先大致了解一下数据。之后,你可以制定一个计划来清理数据。
获取数据的几个基本问题;
为了说明这几个问题,以一个房地产数据集的例子开始(文末附下载方式):
首先快速查看数据集:
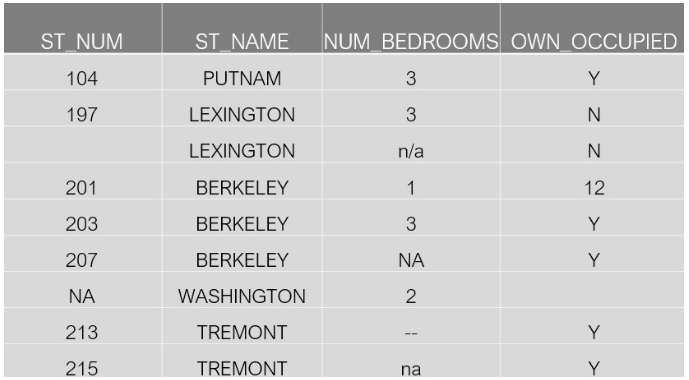
这是一个比您通常使用的数据集小的多的数据集,尽管它是一个小数据集,但它突出了您将遇到的许多真实项目的情况。
快速了解数据的一个好方法是查看前几行数据,Pandas可以快速实现:
# Importing libraries
import pandas as
pd
import numpy as np
# Read csv file into a pandas dataframe
df = pd.read_csv("property data.csv")
# Take a look at the first few rows
print df.head()
Out:
ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS
0 104.0 PUTNAM Y 3.0
1 197.0 LEXINGTON N 3.0
2 NaN LEXINGTON N 3.0
3 201.0 BERKELEY NaN 1.0
4 203.0 BERKELEY Y 3.0
导入Numpy库的原因是可能在处理缺失值时,需要用到该库的函数。
导入库后,我们将CSV文件读取到Pandas的dataframe结构中,您可以将dataframe看成电子表格。df.head()方法是打印前5行数据
现在回答我提出的第一个基本问题:
数据有哪些特征:
ST_NUM:街道号码
ST_NAME:街道名称
OWN_OCCUPIED:是否有人入住
NUM_BEDROOMS:房间数量
我们还可以回答,期望的类型是什么:
回答后面两个问题,需要深入了解Pandas,通过例子介绍如何检测缺失值。
3. 标准缺失值
标准缺失值是Pandas可以检测到的缺失值,回到我们的原始数据集,让我们看看“Street Number"列:
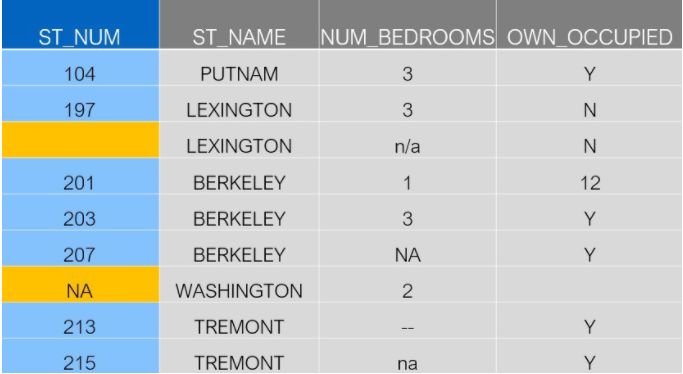
"Street Number"列的第3行是空值,第7行是“NA”,显然这两个值是缺失的,让我们看看Pandas是如何处理这两类的缺失值:
# Looking at the ST_NUM column
print df['ST_NUM']
print df['ST_NUM'].isnull()
Out:
0 104.0
1 197.0
2 NaN
3 201.0
4 203.0
5 207.0
6 NaN
7 213.0
8 215.0
Out:
0 False
1 False
2 True
3 False
4 False
5 False
6 True
7 False
8 False
Pandas在空白处添上了"NA",使用isnull()方法,我们可以确认"空值"和"NA"都被识别为缺失的值,因为它们的结果为True。
虽然是一个简单的例子,但强调了重要的一点——Pandas将空白单元格和"NA"型识别为缺失值。下一节,我们将介绍一些Pandas不认识的类型。
3. 非标准缺失值
数据文件中有可能出现不同格式的缺失值,如原始数据中的"NUM_BEDROOMS"列:
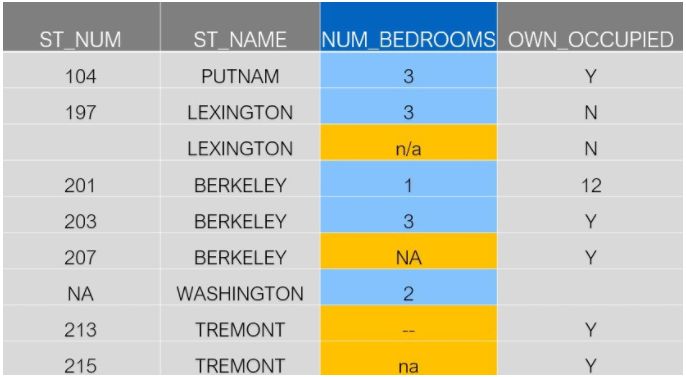
在这一列中,有四个缺失的值:
从上一节中,我们知道Pandas会将"NA"识别为缺失值,但是若出现上面几个类型的缺失值,我们来看看Pandas是否能识别:
# Looking at the NUM_BEDROOMS column
print df['NUM_BEDROOMS']
print df['NUM_BEDROOMS'].isnull()
Out:
0 3
1 3
2 n/a
3 1
4 3
5 NaN
6 2
7 --
8 na
Out:
0 False
1 False
2 False
3 False
4 False
5 True
6 False
7 False
8 False
和以前一样,Pandas能够识别"NA"为缺失值,不幸的是,其他类型没有被识别,如"n/a","--","na"。
如果有多个用户手动输入数据,那么这是一个常见的问题,也许我习惯用"n/a",但你习惯用"na"。
检测这些不同格式的一个简单方法是将它们放在一个列表中,然后导入数据时,设置缺失值为该列表,Pandas会立即识别这些缺失值,如下代码:
# Making a list of missing value types
missing_values = ["n/a", "na", "--"]
df = pd.read_csv("property data.csv", na_values = missing_values)
现在让我们再看一看这列"NUM_BEDROOMS",看看会发生什么:
# Looking at the NUM_BEDROOMS column
print df['NUM_BEDROOMS']
print df['NUM_BEDROOMS'].isnull()
Out:
0 3.0
1 3.0
2 NaN
3 1.0
4 3.0
5 NaN
6 2.0
7 NaN
8 NaN
Out:
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 True
8 True
这一次,所有不同格式都被识别为丢失值。
你也许不知道所有缺失值的类型,我们在处理数据并查看其他类型的缺失值时,可以将它们添加到列表中。
4. 预料不到的缺失值
我们已经介绍了标准缺失值和非标准缺失值,如果我们有一个预料不到的缺失值类型呢?
例如,如果我们的特性是一个字符串,但是某个单元格是数字类型,那么从技术来说这也是一个缺失值。
我们看一看原始数据的"OWN_OCCUPIED"列:
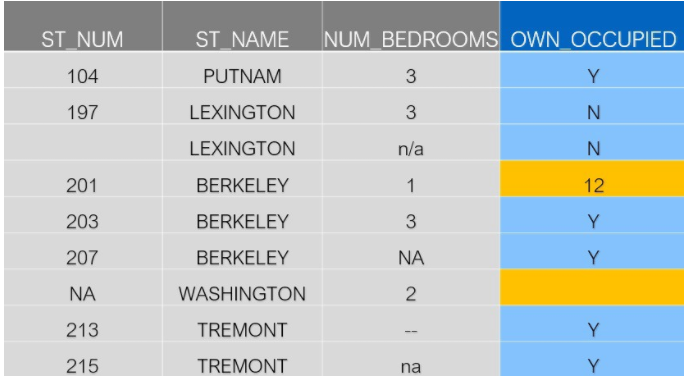
从前面的实例中,我们知道Pandas将检测第7行的空单元为缺失值,还是用之前的代码确认下:
# Looking at the OWN_OCCUPIED column
print df['OWN_OCCUPIED']
print df['OWN_OCCUPIED'].isnull()
# Looking at the ST_NUM column
Out:
0 Y
1 N
2 N
3 12
4 Y
5 Y
6 NaN
7 Y
8 Y
Out:
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 False
8 False
第4行是数字12,"OWN_OCCUPIED"列的值很明显是字符串(Y或N),因此这个数字类型应该是一个缺失值。
这个实例稍微复杂一些,因此我们需要考虑一种方法检测这些类型的缺失值,下面介绍一种小编要用的方法:
1. 循环"OWN_OCCUPIED"列的所有元素
2. 输入转化为整数
3. 若输入能够转化为整数,则该输入为缺失值
4. 若输入不能够转化为整数,则输入为字符串
我们用如下的代码实现上面的步骤:
# Detecting numbers
cnt=0
for row in df['OWN_OCCUPIED']:
try:
int(row)
df.loc[cnt, 'OWN_OCCUPIED']=np.nan
except ValueError:
pass
cnt+=1
6. 缺失值汇总
我们已经研究了检测缺失值的不同方法,我们计算每列的缺失值总数:
# Total missing values for each feature
print df.isnull().
sum()
Out:
ST_NUM 2
ST_NAME 0
OWN_OCCUPIED 2
NUM_BEDROOMS 4
检测所有列中的元素是否含有缺失值:
# Any missing values?
print df.isnull().values.any() # 检测是否有缺失值
Out:
True # True表示有缺失值
计算所有缺失值的总数:
# Total number of missing values
print df.isnull().sum().sum()
Out:
8 # 共有8个缺失值
7. 缺失值替换
用单一值替换缺失值:
# Replace missing values with a number
df['ST_NUM'].fillna(125, inplace=True) # 125替换缺失值
或者可以用赋值的方式:
# Location based replacement
df.loc[2,'ST_NUM'] = 125
用该列的中值替换缺失值:
# Replace using median
median = df['NUM_BEDROOMS'].median()
df['NUM_BEDROOMS'].fillna(median, inplace=True)
8. 小结
本文介绍了一些检测,汇总和替换缺失值的方法,有了这些方法,您将花费更少的时间进行数据清理,更多的时间用于构建数据分析模型。
原文:https://towardsdatascience.com/data-cleaning-with-python-and-pandas-detecting-missing-values-3e9c6ebcf78b
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个
实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












