「 点击上方"GameLook"↑↑↑,订阅微信 」
8月14日至8月17日,由腾讯游戏学堂举办的2022腾讯游戏开发者大会(Tencent Game Developers Conference,以下简称TGDC)将正式举行。
大会以Inspire Six Senses为主题,汇聚国内外顶尖游戏从业者以及学界专家学者,以激发游戏的创意力、想象力、洞察力、科技力、影响力和凝聚力,共同拓宽游戏产业的边界与可能性。
8月14日技术专场论坛上,腾讯互娱研发效能部游戏AI技术总监殷俊进行了题为“通往未来之路——基于机器学习技术实现游戏AI工业化的思考”的分享。

以下为演讲实录:
殷俊:大家好,我是来自腾讯互娱CROS游戏AI的殷俊。很高兴能够在TGDC跟大家分享一下,过去几年我们在游戏AI上的工作。

我今天演讲的题目是通往未来之路,主要讲的是我们基于机器学习技术实现游戏工业化落地过程中遇到的一些问题和思考。第一部分主要介绍一下整个背景和动机。第二部分,主要是介绍我们的解决方案,GameAIR平台。第三部分,讲一下我们未来的方向和工作。

先看第一部分,为什么我们需要有游戏AI。从去年开始,关于元宇宙、虚实混合、Web3.0等等话题在业界和社会上都非常火。这都是现在我们对未来的一些可能的想象。因为在移动互联网的时代,我们发现过往的科幻影视作品中能看到的一些关于未来可能性,已经部分以不同形式出现在我们身边。

在所有的可能性里面,有一个问题我们没有办法去回避,也就是人工智能,以及人工智能与人的关系。在我们现在的环境里面,人工智能的相关研究以及人工智能与人之间的互动关系,最重要、最现实的一个落地场景就是游戏AI。

每当我们说起游戏AI的时候,大家的第一个反应它是游戏里面的NPC,这就是通过游戏AI技术去实现的。我们以2018年Rockstar的《荒野大镖客2》为例去说明,这是一个美国西部主题的开放世界的游戏。大家都知道这个游戏做得非常好,里面的NPC做得特别地逼真。
它在整个世界里塞进去了将近1000个NPC,每一个NPC都非常生动和逼真,玩家你跟NPC打招呼,他也会跟你打招呼。如果你威胁他,如果这是一个胆子很大的NPC,他也会很激烈地回应你。如果是一个很胆小的NPC,会被你吓得逃跑,跟现实世界很像。在游戏里做这么一个可信的AI系统,代价有多大呢?
大家都知道Rockstar是世界上非常出名的一个AAA游戏的开发公司,它的《荒野大镖客2》开发团队投入了将近1600人,开发了七年,整个研发成本在2亿美元左右。其中在NPC AI部分,整个故事的主线,它们的剧本团队写了将近1000页的剧本,每一个NPC都有独立的剧本,平均的长度80页,整个的制作量非常可怕。这意味着对于广大的游戏研发团队来说,要去做这样的AI可能要付出非常高昂的代价。我们看一下原因是什么?
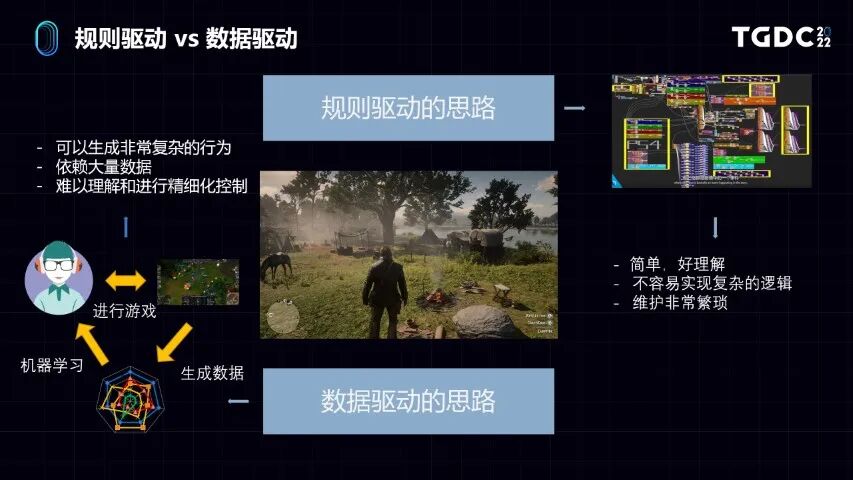
包括《荒野大镖客2》在内,有些业内成熟的游戏AI研发方式,无论是基于状态机和行为树,我们都可以认为它是某一种规则驱动的思路。
什么是规则驱动的思路?就像刚刚举的例子,你要用规则去描述这个AI的行为,就要写清楚每一步AI需要怎么做,当玩家对你打招呼,你也应该打招呼。当玩家威胁你,比如拔枪指着你,如果你设定的胆子很大,应该反过来威胁他。如果胆子设定很小,应该逃跑。看右上角的图,如果把AI的行为做得非常逼真,所需要付出的代价就是在游戏里面设计一套非常复杂的系统。
虽然规则驱动的方法很好理解,因为是用人能够理解的方式去开发的,但是一旦系统复杂度高了,它的二次开发和后续维护的代价就会非常大。这也是为什么这些团队会投入非常大的精力去开发这样的AI系统背后的主要原因。
除了规则驱动的思路外,近些年来,尤其是在AI研究的学术领域,还有一种思路是基于数据驱动。它不是基于写规则的方式告诉AI做什么,而是提供很多数据,从数据里面学习出规律,通常是通过机器学习模型来进行表达。更进一步,是以深度学习神经网络为代表的机器学习模型,去驱动AI做对应的行为。它的特点是行为可以非常做到复杂,能力的上限会非常高。但是它的问题在于首先依赖于大量的数据。无论数据是从用户身上获得的,还是AI本身跟游戏互动产生的数据。
同时我们也知道,尤其像深度学习网络的模型包含几百万,甚至上千万的参数,是一个黑盒模型,我们很难理解这个模型的内里的运行机制。所以对于游戏研发人员很难去理解和精细化去控制这个AI,这是这个方法会产生的问题。

大家都知道近几年的AI浪潮是随着2016年DeepMind的Alphago开始的,所以近些年的AI研发的浪潮,也是被游戏AI的相关研究所驱动。
我们能看到从IBM的深蓝,到Alphago,再到Alphastar等相关的游戏AI工作,整个学术界的进展非常快。但是这些方法的原理是以游戏作为AI研究的一个测试床或者测试环境。主要目的在于游戏上面去探索AI的研究方法和一些可能性。这导致了这些研究工作并没有以解决实际游戏研发生产过程中的问题出发。举个例子,我们能看到很多相关的研究,都是一些特定对抗性玩法的游戏,因为这种类型的游戏可以比较好的说明AI技术的进步带来的效果。

但其实我们在不同品类的游戏里面,游戏的研发方对AI的要求是不一样的。比如我们能看到像射击、即时战略类的游戏,它的玩法主要是对抗,是以PVP为主的玩法。如果这里面需要用AI,重点在于AI的强度够不够。因为游戏本身的策略性是比较复杂的。第二,AI的行为能不能像人,就是玩家不会觉得非常突兀。这些需求对于现在的学术界的方法就比较适用。
比如前面说到的《荒野大镖客》或者别的RPG类型的游戏,主要玩法是PVE,主要打法是打BOSS或者解密或通关卡,这里面重点在于如何控制NPC的行为,做一些内容的生成和玩法的探索。这对于现在学术界研究的方法来说,相对来讲没有那么直接。

我们需要什么样的游戏AI和研究方法呢?其实所有的游戏制作者都想像《西部世界》一样,有没有非常智能化和方便的工具,来创建非常真实,给玩家带来沉浸式体验的游戏世界。同时它又不至于失控,像电视剧里面AI做出一些玩家不想看到的事情。
基于规则驱动的方法,AI能做的事情总是有限的。我们的想法是基于机器学习技术,虽然这些技术并不是那么成熟,但是基于这些技术可能可以达到一个更高的高度。基于机器学习技术去做游戏AI的研发工作,要解决的核心问题,就包括如何降低机器学习技术本身的门槛,以及真实的用这些技术来提高研发效率,这是我们需要去考虑和解决的一些问题。

第二部分,我们介绍一下我们的想法和解决方案,也就是GameAIR平台。
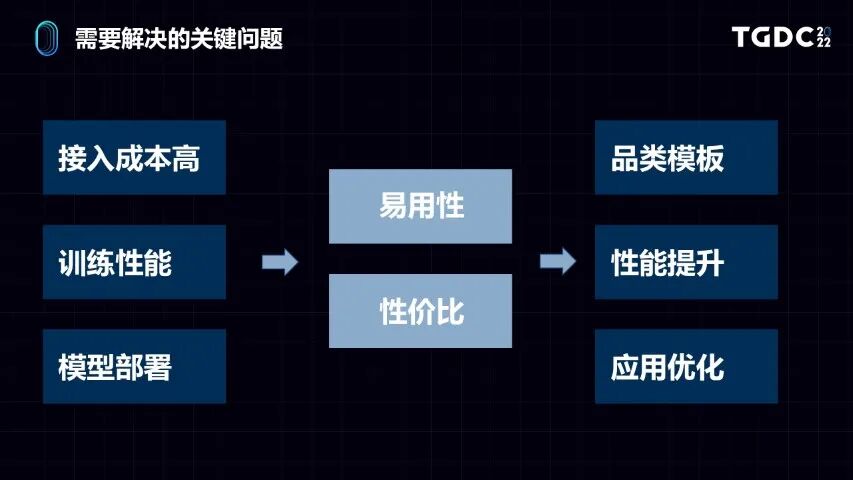
就像前面所提到的一样,如果要利用机器学习技术做游戏AI,有几个关键的难点。第一点是接入成本很高,包括用户对机器学习技术不熟悉,代码开发量很大。
第二,机器学习很贵,训练要有很多机器。而且部署模型时也很麻烦,譬如把一个复杂的模型放到手机上跑会有很多困难。
怎么更好地解决这些问题,我们抽象出两个核心点,第一是易用性,易用性是能降低游戏研发人员使用这些工具的门槛。第二是性价比,就是大家比较担心的,在模型训练和推理上用到很多机器,我能不能把训练的效率跟推理的效率提升,把性价比提高。
因此我们提出了几点优化方案,比如使用品类模板、提升框架性能,以及做机器学习在应用上的优化,下面分项详细看一下。

首先介绍一下我们的平台,名字叫GameAIR。它是一个基于机器学习进行游戏AI研发,给游戏做AI工业化开发的平台。
首先在应用点上,我们支持两种大的类型应用。一种叫BOT,就是游戏里的机器人,一般是一些功能型的AI。另外和玩法和内容制作相关,是NPC的AI。平台本身在应用层上主要提供AI的制作和部署,以及AI行为的数据分析功能。整个平台基于大规模分布式机器学习技术,容器化平台,以及大数据分析,来提供一个非常大规模分布式的高效AI生产的方式,这是总的介绍。
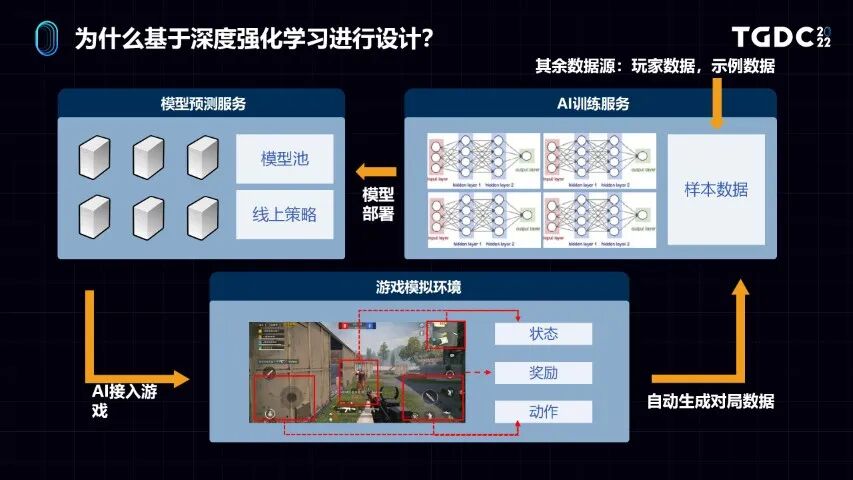
我们整个平台的设计,主要围绕一种叫深度强化学习的方法,这是机器学习其中一种范式。它也是近几年比较火的阿尔法狗背后的技术。我们为什么要基于这个范式进行设计呢?因为我们认为这个架构,特别适用于游戏AI。
为什么呢?简单介绍一下。强化学习的原理是让AI接入到游戏的环境,通过一个SDK的方式让它感知游戏环境,并且进行智能体的行为控制。在这个过程中AI会产生很多数据,我们通过一些评分告诉它什么行为是好的,什么行为是不好的,它就学习到一些策略来玩这个游戏。整个过程跟人学玩游戏很像,从青铜一步步到了王者。整个强化学习的实现,对结构进行一些抽象,可以分成三个大的板块。
(一)游戏模拟环境。这个模块指的是需要有一个环境,把游戏在很多机器上面运行起来。模型训练要跟环境去交互,通过一个SDK放在模拟环境里面,让AI能够跟这个游戏环境去进行通信,去模拟玩游戏的过程。
(二)要有一个AI的训练服务。在这个里面进行非常复杂的深度学习模型的训练,进行一些参数的同步。
(三)模型训练好以后,因为要接入游戏,所以有要模型推理,要有一个模型预测服务。把训练好的模型,部署到预测服务上,预测服务连到游戏模拟环境里面进行推理,它就可以在游戏里面跟人一样玩游戏。
这个结构对于游戏AI非常通用,即便把整个AI制作的机器学习方法进行一些切换,我们兼容一些别的机器学习的范式,比如监督学习,依然依赖这三个模块。区别只是在于监督学习是从已有的人类数据去学的,训练的数据源不从游戏环境来,而是从别的数据源获取。
AI训练完之后,依然还是要预测,有一个部署过程。同时还是要在模拟游戏环境运行起来,让监督游戏模型能够接入到游戏模拟游戏里面去进行交互。所以这是一个更通用的架构,可以更好地兼容不同范式的机器学习的模型,这是基础的设计理念。
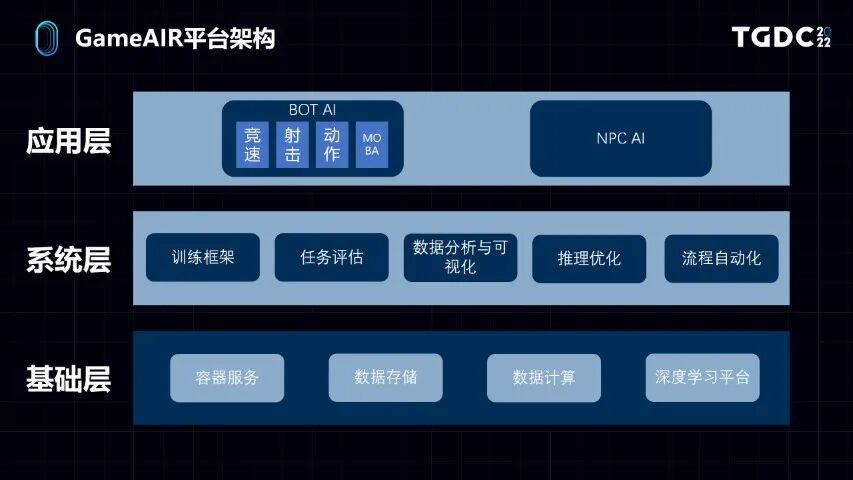
具体到GameAIR平台的架构,可以分为三层。
最下面是基础层,就是容器服务、大数据存储和计算、深度学习框架,我们大量使用公司内外比较成熟的技术和服务。自己开发的主要是系统层和应用层。
在系统层,针对游戏AI训练的整个流程,我们抽象出了很多系统的功能模块。比如说训练框架,任务评估,数据分析和可视化,推理优化,以及在系统上让这些模块都能串起来的流程自动化能力。
在应用层对应前面做的两大类应用,分别是BOT机器人和NPC。BOT的话,由于我们已经接入比较多的业务了,因为不同游戏有不同的玩法,我们针对同一类的玩法进行抽象。比如我们囊括了赛车、射击、动作、MOBA等品类。整个平台提供了不同层级和颗粒度的接入方式。
举个例子,如果接入的用户自己有机器学习的经验,希望能够搭建一个自有的AI生产管线,也就是定制化,它就可以在系统层去接入。如果用户对机器学习和生产AI的技术没有那么了解,就可以在应用层接入。比如我们提供了一个射击游戏的模板,你做了一个射击游戏,就可以很大程度上复用在应用层已经做好的AI代码,然后进一步去降低开发和使用的成本,这是整个架构的介绍。
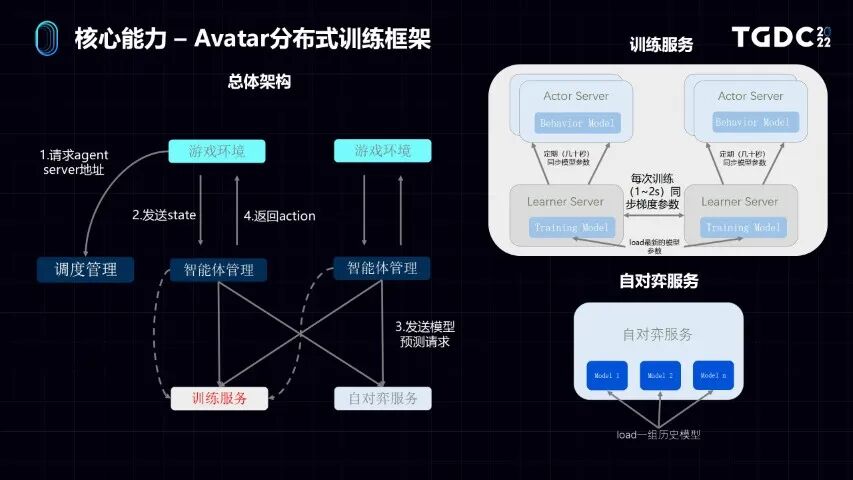
接下来我会分部分介绍一下在整个系统里面,做到了哪些事情,使得我们可以做到易用性和性价比这两点。
首先所有的机器学习平台,最重要的当然都是训练框架。我们先介绍一下Avatar的分布式训练框架。大家在左边可以看到,它也是一个三层结构,最上层是游戏的模拟环境,中间就是调度,因为是分布式的机器学习系统,是一个任务的调度管理。包括我们做游戏接入AI智能体的状态管理的模块。
最下面就是训练模块,里面有两个部分,先说训练服务。训练用的是Actor-Learner的架构。所谓的Learner就是学习器,它就是机器学习训练模型的过程,Actor就是预测服务。实际上整个AI模型的训练跟预测这两个部分分开了。Learner的学习过程是分布式的,有很多个Learner,有很多学习器相互之间做参数的交互,我们看到每一次几秒钟就会交换很多数据。
训练好了一个版本的模型,就会把这个模型从Learner上发到Actor上。Actor拿到这个新版本的模型,就拿这个模型去玩游戏,去获得更多的数据,这就叫Actor-Learner架构。
我们还有自对弈的服务,自对弈就是在游戏AI的训练场景下,很多时候需要有不同版本的AI模型相互地去对战。它有一个能够批量加载历史模型,进行对战的功能。
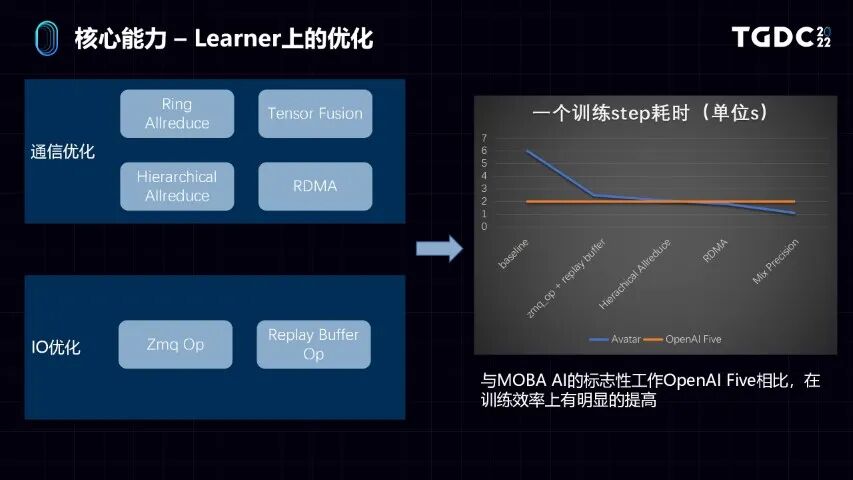
在具体的Actor和Learner架构,因为我们做的是大规模的分布式的训练系统。为什么需要做大规模分布式系统呢?因为有非常多的游戏,比如即时战略,像《星际争霸》这样的游戏,游戏复杂度很高,从复杂度上比围棋高很多倍。要通过数据驱动的方式,做出高水平的AI,要解决的第一个问题,就是要有非常多的训练数据。这些非常多的训练数据又要达到性价比,训练效率就要非常高。
我们在Learner和Actor上针对大规模的分布式机器学习训练做了非常多的优化。比如在Learner,在学习器上,我们主要是针对大的机器学习模型,训练的时候两个容易出现的瓶颈点。第一点是通信,第二是IO。
通信优化,首先分布式有很多个Learner,Learner是要通信的。它跟以往的传统基于中心式的parameter server架构不一样。我们的Learner架构是一个基于Horovod实现的ring Allreduce的结构。同时我们又叠加了一些别的优化的点,比如Tensor Fusion、Hierarchical Allreduce、包括RDMA的功能,去优化了Learner间通信的延迟。
另外由于机器学习用的很多模型比较大,一些模型可能有几千万,甚至有的模型有上亿的参数。这些模型参数在同步的时候,就会遇到一些IO的问题。因为我们这边用的基础深度学习的框架是tensorflow,tensorflow本身自带的一些数据IO的读写操作,其实性能是有一些问题的,我们主要是通过自研算子来优化。
比如我们实现了一个Zmq Op跟Replay Buffer Op,它就比较好地解决了在tensorflow框架和业务代码之间数据拷贝,以及一些python全局锁带来的性能消耗。解决通信和IO优化,就使得我们可以做到针对非常复杂的游戏AI的训练环境,可以通过加机器规模,把训练规模做得很大,性能有接近线性的提升。
看右边的对比。和MOBA类AI一个标志性的工作,OpenAI的OpenAI Five,和它们的公开数据作对比,它一个训练step耗时2秒钟,我们最开始比它慢很多,就是baseline。通过叠加了这些在通信IO上的优化,我们逐步优化,最后能做到接近1秒,就是比它快1倍,这是我们在Learner上做的一些优化。
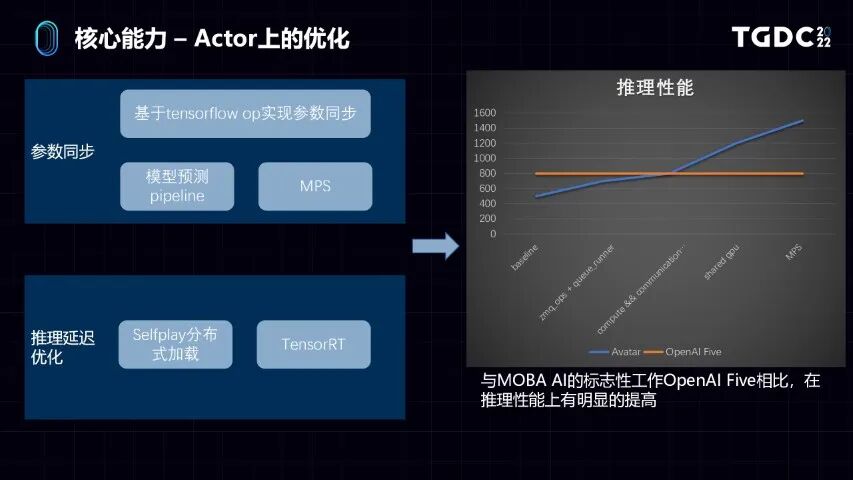
第二点,主要是在Actor做的优化。前面说了Actor的主要问题,如何快速把模型从Learner上同步过来。所以第一点是参数同步的问题,我们基于tensorflow的send和recv这两个算子去实现了参数同步的功能。同时也针对性地去优化了模型预测的pipeline。
另外主要是在推理延迟上的优化,一块是我们在自对弈的服务上,做了分布式的加载。第二个和tensorflow本身自带的tf serving对比,我们也应用了英伟达的Tensor RT的推理框架,它能够比较明显地提升深度学习模型的推理性能。在右边我们同样去跟OpenAIFive做对比,可以看到单个pod最大的并发是800。我们通过逐步地优化,最后也能做到接近1倍的性能提升。
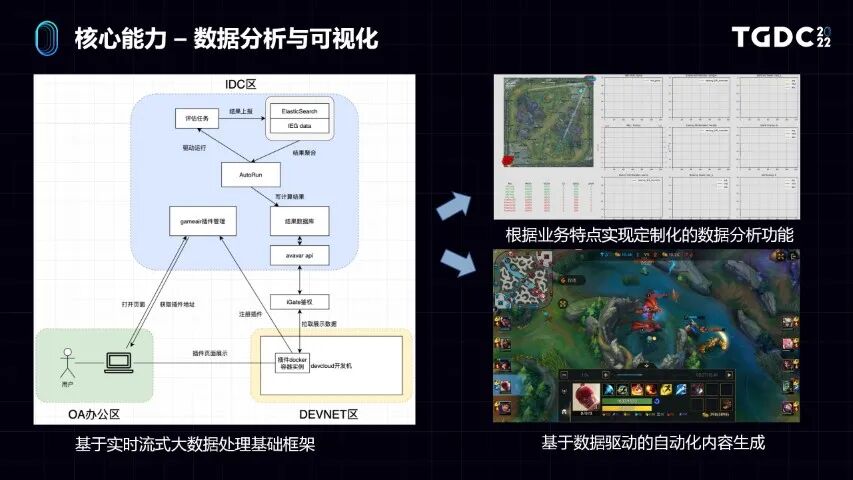
前面的Actor和Learner是在训练框架上做优化,我们做了模型的训练以后,另外就是需要评估模型效果,需要做很多数据的分析。这其实是做工业应用和做研究的主要区别。
因为做工业应用,游戏AI的策划和开发需要去理解AI的行为模式,从而对应调整它在游戏里面的表现,所以数据分析非常重要。我们基于实时的流式大数据基础框架,实现了完整的数据分析和可视化系统。用户可以用这套东西定制化这种数据分析的指标,不同的游戏,玩法不一样。我们可以根据这些玩法去定制这个指标,因为它是实时流式的处理框架,随着AI的训练可以实时观察到AI在游戏里面做了些什么事情。
比如大家可以看到,右上角就是某个游戏的AI。随着游戏在进行。它定制了非常多的指标。因为这是个MOBA游戏,大家知道MOBA游戏策略性很强,相关数据分析很丰富。里面包含的个别英雄的操作数据、团队经济等数据,甚至包括了AI的决策数据,这些都可以看到。
比较有意思的是,基于这个数据分析的工具产生的副产品。比如MOBA游戏训练并发规模很大,生成了几千万局的AI之间的对战数据。从数据分析上加了一些指标,比如打大龙团,某一方只有一个英雄参加,结果最后这个人拿到了龙,就是1V5抢大龙。在大家实际玩游戏时,这种场景很少出现,一般可以作为一个精彩镜头进行回放。我们在AI训练通过事后的数据分析和数据挖掘,发现了类似这样的很多有趣的内容。等于在AI训练过程中,实现了基于数据驱动的自动化内容生成,可以批量的生成这样的精彩视频。
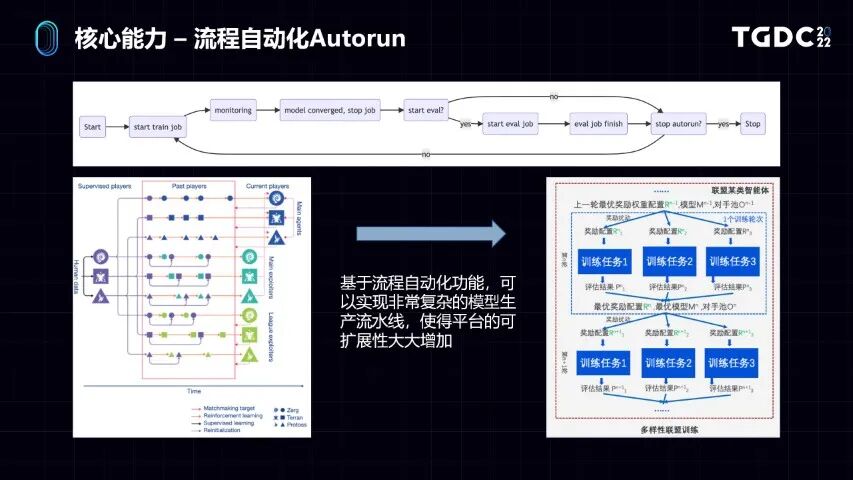
既然我们有了训练系统,也有了评估和分析系统。大家肯定要想的是,我究竟怎么样可以搭建一个我想要的游戏AI的生成流水线。就像上面的图看到的一样,可能由一个流水线开始,先有训练任务,我按照一定的规则,去评估一些指标进行分析,根据分析出来的结果再对AI行为进行调整,就这样进行循环。
这种机器学习的数据驱动方式,跟以往基于规则有很大不同的地方,就是它有能力可以做到全自动地AI生成。因为以往基于规则地驱动的生产方式,中间需要有人的参与。
但是基于机器学习的方法,设定好了AI模型的生产参数,设计好需要观测的指标,可以提供一套叫做Autorun的流程自动化系统。这个系统是通过一些API自动化控制系统各个子模块。实现你想要的工作流,就可以做出非常复杂的全自动模型生产流水线。
比如在左边,我们看到是Deepmind在《星际争霸》里面提出的Alpha league,这个主要设计目的是为了实现多样性,就是不仅AI能力很强,而且打法风格也不一样,是基于进化算法和博弈论的方法实现的。这种训练流程可以允许不同风格的AI进行对战。根据对战效果,再调整AI生产的参数。
基于Autorun功能,你也可以实现联赛或天梯这种很复杂的生产流程,比如左边我们可以生成三种不同风格的AI,让这三种AI对打,目标是探索不同风格和打法的AI。所以对于生产来说,我不仅可以同时得到你满意的强度,还可以生产出你之后想要的打法。这个流程自动化的功能,是实现定制化的工业流水线的基础。
有了训练框架,有了数据分析,也有了自动化的方法去串流程,最后也得到了AI。另外一个难点就是部署。为什么部署是大问题呢?第一点,大家都知道深度学习模型大家比较在意的是,实际上线用时会不会用很多机器,会不会很贵?第二,现在有很多游戏业务,需要去做本地化的部署,尤其是移动游戏,把模型放到手机上。除了推理效率以外,对模型大小也有要求。
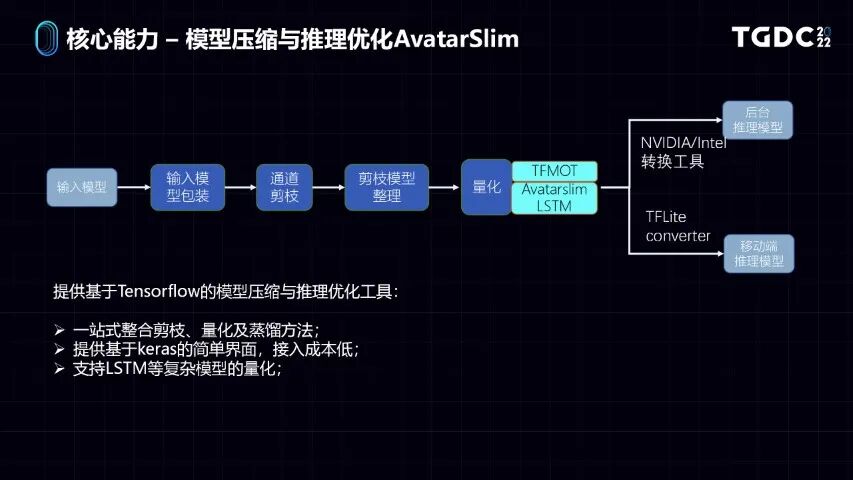
这些问题在机器学习的领域里,有一个模型压缩和推理优化的方向。但是这个方向成熟工具比较零散,而且传统来说这类方法在机器视觉上用得比较多。而游戏AI是一个复杂的序列决策的过程,它对模型要求和推理优化的精度损失很敏感,因为误差会叠加。
我们实现了一套跟我们的框架整合得比较好的AvatarSlim的模型压缩和推理优化服务,这套服务它整合了现在学术界用得比较好的剪枝和量化,以及模型蒸馏方法。我们也提供了一个基于Keras的简单界面,用户用起来很方便。写训练代码时,只要通过几个简单的函数调用,就可以实现你想要的模型压缩和推理优化的流程。
而且我们也做了一些比较多的自研工作,去支持在LSTM上复杂结构的模型的量化。
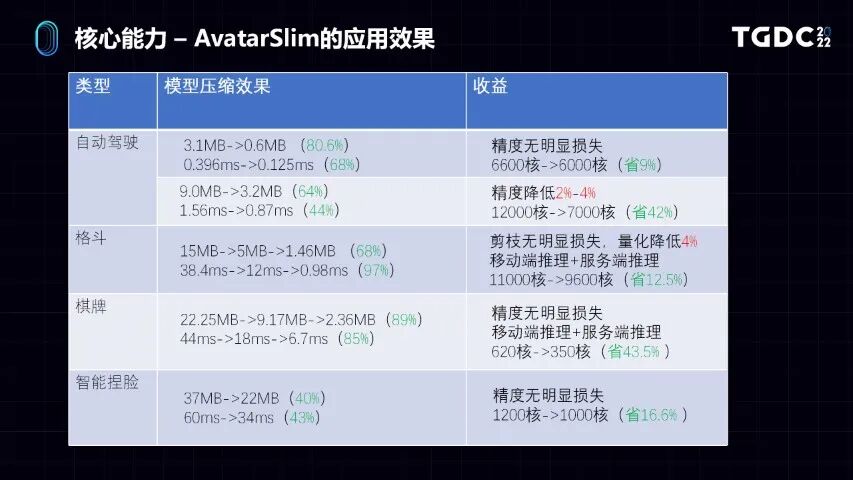
大家可以看到在AvataSlim具体在一些业务上的应用效果,从两个方面来看,一个是模型大小的压缩,另外是模型推理性能上的改变。几乎在精度损失很少,或者根本没有精度损失,精度损失一般在5%以内。在这个代价下,我们可以实现把模型的大小缩减70%到80%。我们在模型推理上面的收益,也能够有个比较明显的提升,大家可以看到在CPU核数和GPU上能起到比较明显的效果。

以上介绍的就是我们平台的核心功能,包括整个训练的模块、数据分析的功能、自动化的模块,以及模型部署推理优化上的能力。整个平台在腾讯内部,以及有十几款业务都接入了,有五个大的品类,包括竞速、MOBA、棋牌、动作格斗、射击,其中8款已经上线提供服务了。我们给它们提供的功能,因为它们主要的用处是一些温暖局功能。主要是能够提升用户的活跃度跟留存,我们都会3%到5%不等的提升,这就是它在内部应用的一些效果。

第三部分,讲一下我们现在做的事情,以及后面的方向。
前面讲了很多,大家觉得这个方法还是挺难的,下面有这么复杂的机器学习框架,上面的应用层我还要做很多开发。这个游戏研发的项目组,尤其对强化学习这种复杂的方法,了解得相对比较有限,担心是不是上手很难。
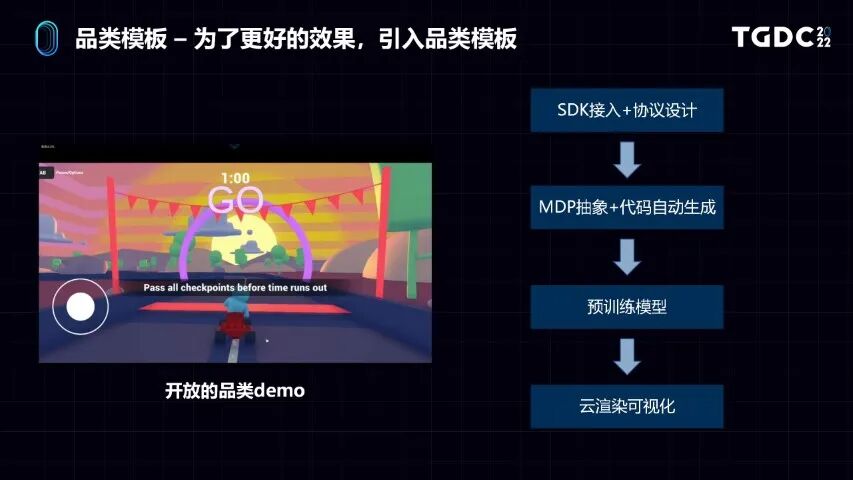
我们也仔细考虑过这个问题,所以我们为了更好地让大家快速地做接入,我们做了一个品类模板。看一下左边的示例,这是一个很简单的示例,它没有任何版权和IP问题,这是我们完全可以开放的。这是一个赛车类游戏,它很简单,它有一般赛车游戏有的因素,有赛道,有障碍物,有计时,有排名等等功能。
这个品类模板在平台上会提供对应的流程,从SDK接入到赛车游戏的协议设计,包括机器学习的代码的自动生成。甚至我们提供预训练好的模型,也就是拿过来游戏已经有模型可以跑了。包括可以把客户端放在云上,做云渲染的可视化。
如果你有一个游戏,拿到这样的品类模板,从SDK接入开始,就可以用一个模板导入,比较快地帮助你开发出一个你想要的AI。虽然同一个品类下不同的游戏,多少有细微的区别。但通过这种方式,可以让你比较快地得到一个还不错的结果,这就是品类模板。
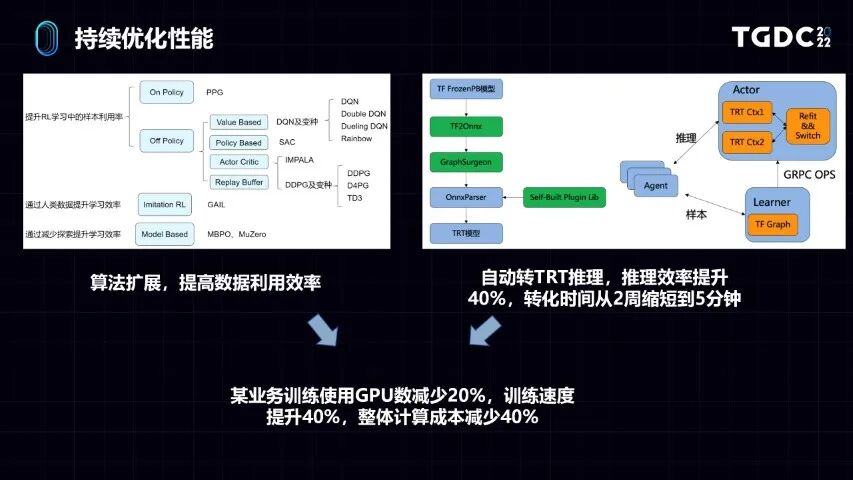
另外我们会持续地去优化性能,大家能看到两个部分。一方面是算法扩展,因为我们是个分布式机器学习的平台,所以理论上可以实现各种各样的机器学习算法。这些算法可以去做一些持续的扩展。我们扩展的逻辑,大家能看到,包括现在主流的一些强化学习的算法以及包括现在前沿的一些offline RL方法,我们都会去做。但是我们拓展的逻辑,是从提高数据利用效率的角度出发,去拓展这些算法。
另外我们也会从框架在推理方面的性能去做,比如前面说到跟英伟达用做合作,用TRT做推理,但是原来用的时候TRT有问题,它做推理的时候需要做格式转换。英伟达跟谷歌提供的工具不是很完善,这个转换需要人手去做。我们今年做的工作,跟英伟达进行了一些深入合作,自研了很多OP,自动把训练好的模型转TRT的推理。之前转一个模型人手转需要转5周,现在5分钟就可以转成,整个流程非常自动化。推理效率跟之前相比,可以直接提升40%。
基于我们持续优化,比如今年已经支持的业务,跟去年比,在某个业务上训练使用的GPU数能减少20%,训练速度提升40%,整体的计算成本减少40%。整个框架性能是我们持续做的事情。

关于未来的展望,首先就是品类模板,前面看了一个赛车的游戏。今年下半年我们会提供赛车和射击的模板,明年我们还会提供一个动作格斗,就是像格斗或ARPG的模板。
同时还会进一步降低业务的接入成本,提升鲁棒性。比如我们会做一些数据的自动化校验,之前人手去校验状态数据是一个繁琐的事情。包括我们甚至会根据游戏品类,去自动把神经网络的结构给生成出来,通过一些更多自动化功能去降低大家的接入成本。在系统的鲁棒性上,因为我们这是一个比较大规模的分布式系统,分布式的系统的鲁棒性是一个比较麻烦的问题。我们后面也会做一些系统节点的故障自愈,包括做不同层级的资源调度的功能,去提升我们的鲁棒性。
现在除了腾讯内部的资源业务外,我们也有一些外部的腾讯合作的公司,已经开始用这些平台接入了一些AI。我们希望在不远的将来,可以逐步对外开放,给更多的游戏研发团队接入进行使用。

其实从前面的介绍看来,大家都知道这种机器学习的方法,它本身有很多的优点,其实也存在很多的问题。我们的想法是,虽然我们认为现在基于机器学习去做游戏AI并不是目前最成熟、成本最低的方案,但它的确有一个非常光明的未来。
我们认为可能通往未来真实的元宇宙或虚实融合的未来道路有很多条,我们并不一定会选择当前成本最低或最容易的道路。做基于机器学习做游戏AI的过程是非常痛苦,也充满非常多的困难。我们相信在整个过程中,我们积累下来的一些经验会让整个方法得到更好地提升。我们希望通过自己的一些工作,和合作伙伴一起逐步去实现一个比较理想的未来,并终将改变游戏和人工智能本身。
这就是我今天主要分享的内容,谢谢各位。
····· End ·····
GameLook每日游戏产业报道
全球视野 / 深度有料
爆料 / 交流 / 合作:请加主编微信 igamelook
广告投放 : 请加 QQ:1772295880
长按下方图片,"识别二维码" 订阅微信公众号

····· 更多内容请访问 www.gamelook.com.cn ·····
Copyright © GameLook
® 2009-2022
觉得好看,请点这里 ↓↓↓








