从结果看,两个SQL居然真的没有走主键meeting_id索引,而是都走了phone_id这个普通的二级索引,其中第一个查询SQL走的索引全扫描,扫描记录数rows为397399,和表的记录数一致,显然走了全索引扫描,虽然比全表扫描好一些,但效率仍然低下;另外一个update的SQL走了正常的索引扫描,rows只有2,性能高效。为什么两个SQL没有走meeting_id这个主键索引呢?看trace打印的部分内容:
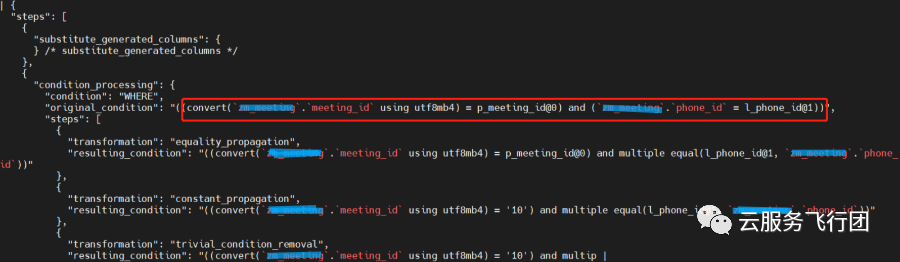
trace显示两个SQL在优化器分析时,将meeting_id做了隐式转换,转换函数为convert('meeting_id' using utf8mb4),也就是将meeting_id做了字符集的转换,熟悉索引机制的同学都清楚,这种情况下优化器是不会走meeting_id索引的。这也可以解释了客户第一次创建索引的时候为啥有性能提升,但效果并不明显,原因就是只有update语句真正用到了索引带来的性能提升,而且是phone_id索引带来的提升,不是性能更高的主键meeting_id。
现在聚焦到最关键的问题,meeting_id为啥要做字符集的隐式转换?查看了一下实例相关字符集的设置:
表和列的字符集都为utf8;
表所在库的字符集为utf8mb4;
server字符集((character_set_server))为utf8
character_set_client/character_set_connection/character_set_results为utf8mb4
果然,server、database、table的字符集不完全一致,猜想一下实际流程应该是这样的:存储过程中传入的字符参数字符集为utf8mb4,和表中字符集为utf8的字段meeting_id比较时,meeting_id做了字符集的隐式转换,转换为utf8mb4后再和输入参数比较,从而导致meeting_id上的索引无法使用。
根据这个猜测,建议用户将表的字符集更改为utf8mb4,这样应该可以避免字符集的转换。由于这个功能还未上线,用户直接对 表做了字符集的修改:
alter table zm_meeting convert to character set utf8mb4;
修改后让用户再次测试,预期效果终于出现,并发500测试在秒级完成,trace查看执行计划,都走了meeting_id的主键索引,隐式转换也随之消失,性能问题得到了彻底解决。
存储过程的入参为啥使用了utf8mb4?这是本次案例的核心,查阅mysql文档,存储过程介绍里面有一段描述:

简单说,就是存储过程的字符型参数,如果没有显式指定字符集,默认将会使用所在数据库的字符集,而本案例中表所在的数据库字符集为utf8mb4,所以参数默认使用了utf8mb4,导致了匹配过程的隐式转换。存储过程外直接写SQL为什么没有这种情况发生,我猜测比较的字符串应该会自动匹配‘=’左边表字段的字符集。
既然这样,理论上直接修改参数的字符集应该也可以达到同样结果,简单测试下,将存储过程参数加上表上的字符集属性:
CREATE PROCEDURE `zm_sp_next_phone_id`(IN `p_meeting_id` VARCHAR(36) character set utf8)
测试结果如我们预期,不会产生隐式转换,执行计划正确。
问题虽然解决了,原因也找到了,但反思一下整个过程,如果用户的server、库、表字符集能够保持一致,将完全可以避免这个故障。与字符集相关的类似故障也可以大概率避免,所以客户侧还是要有一定的设计规范;产品侧如果有一定的检查规则可以帮客户发现类似的隐患,对提升客户体验也是一种很有价值的服务。








