在机器学习和量子计算的交叉领域,量子机器学习具有加速数据分析的潜力,特别是对于量子数据,在量子材料、生物化学和高能物理等领域都有应用。尽管如此,关于量子机器学习模型的可训练性仍然存在挑战。
在这里,美国洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory,LANL)的研究人员回顾了量子机器学习的当前方法和应用。研究人员强调量子和经典机器学习之间的差异,重点是量子神经网络和量子深度学习。最后,他们讨论了利用量子机器学习获得量子优势的机会。
该论述以「Challenges and opportunities in quantum machine learning」为题,于 2022 年 9 月 15 日发布在《Nature Computational Science》。

世界是量子力学的认识使研究人员能够将成熟但经典的理论嵌入到量子希尔伯特空间的框架中。作为通信技术基础的香农信息论已推广到量子香农理论(或量子信息论),开辟了量子效应使信息传输更高效的可能性。生物学领域已扩展到量子生物学,以更深入地了解光合作用、气味和酶催化等生物过程。图灵的通用计算理论已经扩展到通用量子计算,可能导致物理系统的模拟速度呈指数级增长。
本世纪最成功的技术之一是机器学习 (ML),它旨在对大型数据集进行分类、聚类和识别模式。学习理论与 ML 技术同时发展,以理解和改进其成功。支持向量机、神经网络和生成对抗网络等概念对科学和技术产生了深远的影响。机器学习现在已经深入社会,以至于对机器学习的任何根本改进都会带来巨大的经济效益。
与其他经典理论类似,ML 和学习理论实际上可以嵌入到量子力学形式主义中。从形式上讲,这种嵌入导致了称为量子机器学习 (QML) 的领域,该领域旨在了解物理定律所允许的数据分析的最终限制。实际上,量子计算机的出现,希望在数据分析中实现所谓的量子优势(例如下定义),这使得 QML 如此令人兴奋。量子计算利用纠缠、叠加和干扰来执行某些任务,与经典计算相比具有显著的加速,有时甚至是指数级的更快。事实上,虽然对于人为的问题已经观察到了这种加速,但即使在理论层面上,实现数据科学的速度仍然不确定,但这是 QML 的主要目标之一。

在实践中,QML 是一个广义术语,涵盖了图 1 中所示的所有任务。例如,ML 可应用于量子应用,例如发现量子算法或优化量子实验,或者量子神经网络(QNN)可用于处理经典或量子信息。甚至经典任务在受到量子启发时也可以被视为 QML。
研究人员注意到,这个观点的重点将放在 QNN、量子深度学习和量子内核上,尽管 QML 的领域相当广泛并且超出了这些主题。

图 2:QML 的关键应用。(来源:论文)
在激光发明之后,它被称为寻找问题的解决方案。在某种程度上,QML 的情况类似。QML 应用程序的完整列表尚不完全清楚。尽管如此,可以推测图 2 中显示的所有区域都将受到 QML 的影响。例如,QML 可能会使化学、材料科学、传感和计量、经典数据分析、量子纠错和量子算法设计受益。其中一些应用程序产生的数据本质上是量子力学的,因此将 QML(而不是经典的 ML)应用于它们是很自然的。
虽然经典机器学习和量子机器学习之间存在相似之处,但也存在一些差异。由于 QML 使用量子计算机,来自这些计算机的噪声可能是一个主要问题。这包括硬件噪声,例如退相干以及由量子态测量产生的统计噪声(即散粒噪声)。
这两种噪声源都会使 QML 训练过程复杂化。此外,由于量子变换的线性,经典 ML 中自然的非线性操作(例如,神经激活函数)需要更仔细地设计 QML 模型。
对于 QML 领域,近期的目标是展示量子优势,即在数据科学应用中优于经典方法。实现这一目标需要对哪些应用程序将从 QML 中受益最多保持开放的态度(例如,它可能是一个本质上是量子力学的应用程序)。还需要了解 QML 方法如何扩展到大型问题,包括分析可训练性(梯度缩放)和预测误差。高质量量子硬件的可用性也至关重要。
最后,研究人员注意到 QML 提供了一种思考已建立领域的新方法,例如量子信息论、量子纠错和量子基础。从数据科学的角度看待此类应用程序可能会带来新的突破。
框架
数据
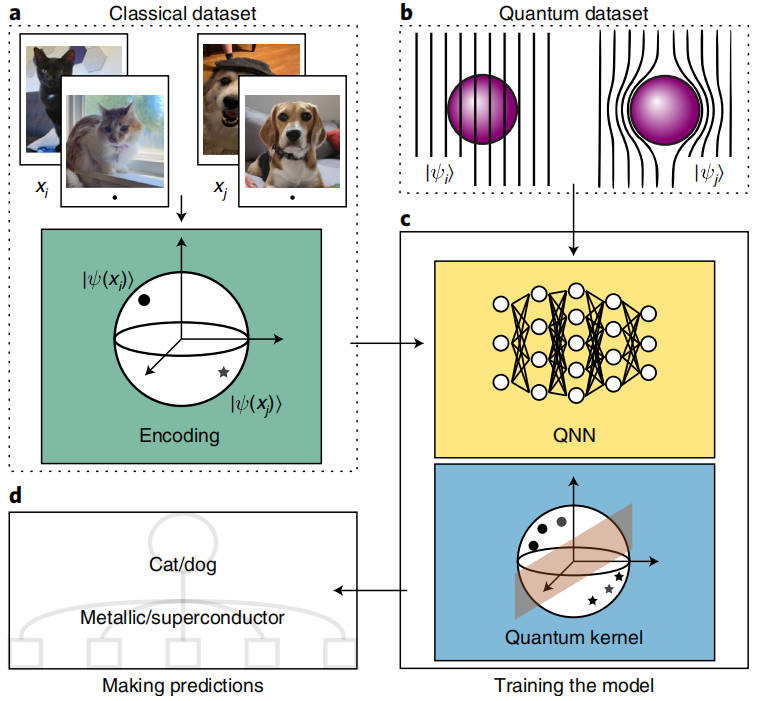
图 3:使用 QML 进行分类。(来源:论文)
如图 3 所示,QML 可用于从经典数据或量子数据中学习,研究人员对比了这两种类型的数据。经典数据最终以比特编码,每个比特都可以处于 0 或 1 状态。这包括图像、文本、图表、医疗记录、股票价格、分子特性、生物实验的结果和高能物理实验的碰撞痕迹。
量子数据以量子比特编码,称为量子比特或更高维的类似物。一个量子比特可以由状态 |0>、|1> 或这两者的任何归一化复线性叠加来表示。在这里,状态包含从一些物理过程中获得的信息,例如量子传感、量子计量、量子网络、量子控制,甚至是量子模拟-数字转换。此外,量子数据还可以解决在量子计算机上获得的问题:例如,准备各种哈密顿量的基态。
原则上,所有经典数据都可以在量子比特系统中有效编码:长度为 n 的经典比特串可以很容易地编码到 n 个量子比特上。然而,反过来就不行了,因为不能在位系统中有效地编码量子数据。也就是说,一般 n 量子比特系统的状态需要指定 (2n-1) 个复数。因此,量子位系统(以及更普遍的量子希尔伯特空间)构成了最终的数据表示媒介,因为它们不仅可以编码经典信息,还可以编码从物理过程中获得的量子信息。
这里有一个重要且比较合理的猜想,量子数据的可用性将在不久的将来大幅增加。人们将使用可用的量子计算机这一事实在逻辑上将导致更多的量子问题得到解决并进行量子模拟。这些计算将产生量子数据集,因此预期量子数据的快速增长是合理的。不过,在短期内,这些量子数据将以对准备数据集的量子电路的有效描述的形式存储在经典设备上。
最后,随着科学家对量子技术控制水平的提高,量子信息从物理世界到数字量子计算平台的相干转换可能会实现。这将在量子力学上模拟来自物理世界的经典数据的主要信息获取机制,即模数转换。
此外,大家可以期待实用的量子纠错和量子存储器的最终出现,将使研究人员能够将量子数据存储在量子计算机本身上。
模型
从数据中分析和学习需要一个参数化模型,并且已经为 QML 应用程序提出了许多不同的模型。神经网络和张量网络等经典模型(如图 1 所示)通常可用于分析来自量子实验的数据。然而,由于它们的新颖性,综述中重点讨论了使用量子算法的量子模型,其中将学习方法直接应用于量子级别。
与经典 ML 类似,存在几种不同的 QML 范式:监督学习(基于任务)、无监督学习(基于数据)和强化学习(基于奖励)。虽然这些领域中的每一个本身都令人兴奋和蓬勃发展,但监督学习最近因其实现量子优势、抗噪声能力和良好的泛化特性的潜力而受到了相当大的关注,这使其成为近期应用的有力候选者。

图 4:QNN 架构示例。(来源:论文)
QML 中的挑战
由于不可预见的技术挑战,启发式领域可能会面临停滞期(或「寒冬」)。的确,在经典 ML 中,引入单个感知器和多层感知器(即神经网络)之间存在差距,尝试训练多层与引入反向传播方法之间也存在差距。
自然地,研究人员希望避免 QML 出现这些停滞或冬天。显而易见的策略是尝试尽快确定所有挑战,并将研究工作集中在解决这些问题上。幸运的是,QML 研究人员采用了这种策略。

图 5:QML 的挑战。(来源:论文)
图 5 展示了 QML 模型的一些不同元素,以及与之相关的挑战。综述中,研究人员从嵌入方案和量子数据集、量子景观、QNN 架构设计、量子噪声的影响等方面,介绍了各种 QML 挑战,以及如何避免和克服这些挑战。
机遇与展望
量子优势的潜力
QML 的第一个量子优势可能来自于从量子数据中提取隐藏参数。这可以用于量子传感或量子状态分类/回归。经典参数提取可能产生优势的另一个应用领域是量子机器感知,即量子传感、计量学等。另外,除了嵌入在量子数据中的经典参数提取之外,发现量子纠错码可能也有优势。在无法对分布进行经典采样的情况下,当可以使用包含 QNN 的模型生成基态、平衡态或量子动力学时,可以实现生成建模的量子优势;与经典 ML 方法相比,产生更准确的预测或更广泛的泛化。
量子优势会是什么样子?
当数据来自量子力学过程时,例如来自化学、材料科学、生物学和物理学的实验,则更有可能在 ML 中看到指数量子优势。量子优势可能在于样本复杂度或时间复杂度。样本复杂度的指数优势总是意味着时间复杂度的指数优势,但反之亦然。
最近的研究表明,当科学家可以使用量子传感器、量子存储器和量子计算机来检索、存储和处理实验中的量子信息时,样本复杂性具有指数量子优势。
时间复杂度优势的情况更加微妙。在许多情况下,量子过程的经典模拟是难以处理的,因此预计时间复杂度的指数优势将普遍存在。但是,应该对 ML 任务中数据的可用性保持谨慎,这使得经典的 ML 算法在计算上更加强大。甚至在最坏的情况下,预测几何局部间隙哈密顿量的基态特性没有指数量子优势。此外,量子力学过程中有效经典理论的出现可以使经典机器提供准确的预测。
当数据是纯粹的经典来源时,例如在向客户推荐产品、执行投资组合优化和处理人类语言和日常图像的应用程序中,没有已知的指数优势。但是,期望多项式优势仍然是合理的。此外,对于纯经典问题,可以严格证明二次优势。
从长远来看,当科学家拥有容错量子计算机时,可能会产生潜在的影响,尽管当前已知的容错量子计算方案的量子纠错开销显着抑制了加速。
过渡到容错时代及以后
虽然 QML 已被提议作为使用 NISQ 设备在短期内实现量子优势的候选者,但仍然可以就其在未来的可用性提出问题。在这里,研究人员设想了 NISQ 后两个不同的年代时代。
首先,可以称之为「部分纠错」,量子计算机将有足够的物理量子比特(几百个)和足够小的错误率,以允许少量完全纠错的逻辑量子比特。由于一个逻辑量子位由多个物理量子位组成,因此在这个时代,科学家将可以自由权衡并将设备中的量子位拆分为纠错量子位的子集以及非纠错量子位的子集。下一个时代,即「容错」时代,将在量子硬件拥有大量纠错的量子比特时出现。
事实上,人们可以很容易地想象 QML 在这两个后 NISQ 时代都是有用的。首先,在部分纠错时代,QML 模型将能够执行高保真电路,从而提高性能。这将通过减轻噪声引起的贫瘠高原自然而然地增强模型的可训练性,并减少 QML 模型中噪声引起的分类错误。最重要的是,QML 可能会在容错时代看到其最广泛和最关键的用途。在这里,诸如用于量子模拟的量子算法将能够准确地准备量子数据,并将其忠实地存储在量子存储器中。因此,QML 将成为从量子数据中学习、推断和预测的自然模型,因为这里的量子计算机将直接从数据本身中学习。
从长远来看,研究人员预计将有可能通过从自然模拟形式转换为量子数字形式(例如,通过量子模拟-数字相互转换)直接从自然界捕获量子数据。然后,这些数据将能够在量子网络中穿梭,使用 QML 模型进行分布式或集中处理,使用容错量子计算和纠错量子通信。在这一点上,QML 将达到与今天的 ML 相似的阶段,边缘传感器捕获数据,将数据中继到中央云,并在聚合数据上训练 ML 模型。
随着广泛的经典机器学习的现代出现出现在数据丰富的这一点上,人们可以预期,在容错时代对量子数据的无处不在的访问同样可以推动 QML 得到更广泛的使用。
论文链接:https://www.nature.com/articles/s43588-022-00311-3
人工智能 × [ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。










