点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

自从第14篇文章结束,所有的单模型基本就讲完了。而后我们进入了集成学习的系列,整整花了5篇文章的篇幅来介绍集成学习中最具代表性的Boosting框架。从AdaBoost到GBDT系列,对XGBoost、LightGBM和CatBoost作了较为详细的了解。本文作为集成学习的最后一篇文章,来介绍与Boosting框架有所不同的Bagging框架。
Bagging与随机森林
Bagging是并行式集成学习方法最典型的代表框架。其核心概念在于自助采样(Bootstrap Sampling),给定包含m个样本的数据集,有放回的随机抽取一个样本放入采样集中,经过m次采样,可得到一个和原始数据集一样大小的采样集。我们可以采样得到T个包含m个样本的采样集,然后基于每个采样集训练出一个基学习器,最后将这些基学习器进行组合。这便是Bagging的主要思想。Bagging与Boosting图示如下:
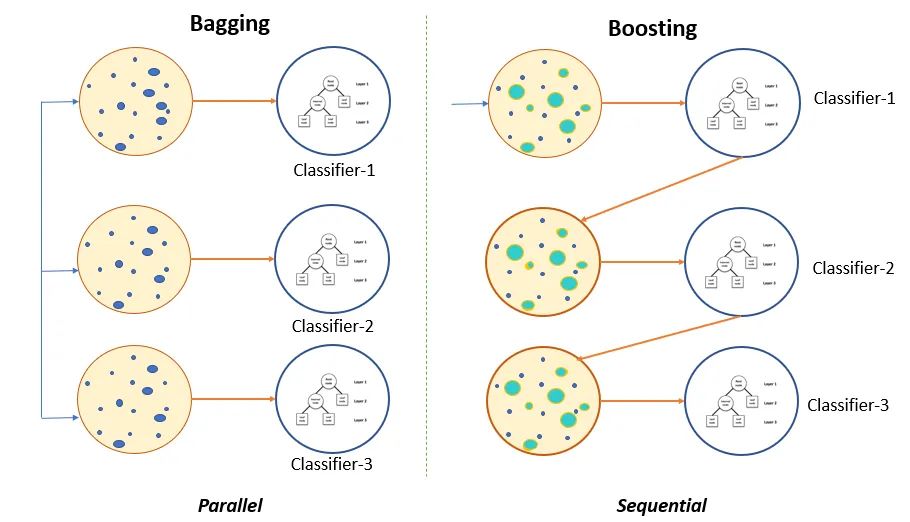
可以清楚的看到,Bagging是并行的框架,而Boosting则是序列框架(但也可以实现并行)。
有了之前多篇关于决策树的基础以及前述关于Bagging基本思想的阐述,随机森林(Random Forest)就没有太多难以理解的地方了。所谓随机森林,就是有很多棵决策树构建起来的森林,因为构建过程中的随机性,故而称之为随机森林。随机森林算法是Bagging框架的一个典型代表。
关于构建决策树的过程,可以参考前述第4~5篇,这里不做重复阐述。因为基础的推导工作都是前述章节都已完成,这里我们可以直接阐述随机森林的算法过程,简单来说就是两个随机性。具体如下:
假设有M个样本,有放回的随机选择M个样本(每次随机选择一个放回后继续选)。
假设样本有N个特征,在决策时的每个节点需要分裂时,随机地从这N个特征中选取n个特征,满足n<
基于抽样的M个样本n个特征按照节点分裂的方式构建决策树。
按照1~3步构建大量决策树组成随机森林,然后将每棵树的结果进行综合(分类使用投票法,回归可使用均值法)。
所以,当我们熟悉了Bagging的基本思想和决策树构建的过程后,随机森林就很好理解了。
随机森林算法实现
本文我们使用numpy来手动实现一个随机森林算法。随机森林算法本身是实现思路我们是非常清晰的,但其原始构建需要大量搭建决策树的工作,比如定义树节点、构建基本决策树、在基本决策树基础上构建分类树和回归树等。这些笔者在前述章节均已实现过,这里不再重复。
在此基础上,随机森林算法的构建主要包括随机选取样本、随机选取特征、构造森林并拟合其中的每棵树、基于每棵树的预测结果给出随机森林的预测结果。
导入相关模块并生成模拟数据集。
import numpy as npfrom ClassificationTree import *from sklearn.datasets import make_classificationfrom
sklearn.model_selection import train_test_splitn_estimators = 10max_features = 15X, y = make_classification(n_samples=1000, n_features=20, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1)rng = np.random.RandomState(2)X += 2 * rng.uniform(size=X.shape)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
定义第一个随机性,行抽样选取样本:
def bootstrap_sampling(X, y): X_y = np.concatenate([X, y.reshape(-1,1)], axis=1) np.random.shuffle(X_y) n_samples = X.shape[0] sampling_subsets = []
for _ in range(n_estimators): idx1 = np.random.choice(n_samples, n_samples, replace=True) bootstrap_Xy = X_y[idx1, :] bootstrap_X = bootstrap_Xy[:, :-1] bootstrap_y = bootstrap_Xy[:, -1] sampling_subsets.append([bootstrap_X, bootstrap_y]) return sampling_subsets
然后基于分类树构建随机森林:
trees = []for _ in range(n_estimators): tree = ClassificationTree(min_samples_split=2, min_impurity=0, max_depth=3) trees.append(tree)
定义训练函数,对随机森林中每棵树进行拟合。
def fit(X, y): n_features = X.shape[1] sub_sets = bootstrap_sampling(X, y) for i in range(n_estimators): sub_X, sub_y = sub_sets[i] idx2 = np.random.choice(n_features, max_features, replace=True) sub_X = sub_X[:, idx2] trees[i].fit(sub_X, sub_y) trees[i].feature_indices = idx2 print('The {}th tree is trained done...'.format(i+1))
我们将上述过程进行封装,分别定义自助抽样方法、随机森林训练方法和预测方法。完整代码如下:
class RandomForest(): def __init__(self, n_estimators=100, min_samples_split=2, min_gain=0, max_depth=float("inf"), max_features=None): self.n_estimators = n_estimators
self.min_samples_split = min_samples_split self.min_gain = min_gain self.max_depth = max_depth self.max_features = max_features
self.trees = [] for _ in range(self.n_estimators): tree = ClassificationTree(min_samples_split=self.min_samples_split, min_impurity=self.min_gain, max_depth=self.max_depth) self.trees.append(tree) def bootstrap_sampling(self, X, y): X_y = np.concatenate([X, y.reshape(-1,1)], axis=1) np.random.shuffle(X_y) n_samples = X.shape[0] sampling_subsets = []
for _ in range(self.n_estimators): idx1 = np.random.choice(n_samples, n_samples, replace=True) bootstrap_Xy = X_y[idx1, :] bootstrap_X = bootstrap_Xy[:, :-1] bootstrap_y = bootstrap_Xy[:, -1] sampling_subsets.append([bootstrap_X, bootstrap_y]) return sampling_subsets def fit(self, X, y): sub_sets = self.bootstrap_sampling(X, y) n_features = X.shape[1] if self.max_features == None: self.max_features = int(np.sqrt(n_features)) for i in range(self.n_estimators): sub_X, sub_y = sub_sets[i] idx2 = np.random.choice(n_features, self.max_features, replace=True) sub_X = sub_X[:, idx2] self.trees[i].fit(sub_X, sub_y) self.trees[i].feature_indices = idx2 print('The {}th tree is trained done...'.format(i+1)) def predict(self, X): y_preds = [] for i in range(self.n_estimators): idx = self.trees[i].feature_indices sub_X = X[:, idx] y_pred = self.trees[i].predict(sub_X) y_preds.append(y_pred) y_preds = np.array(y_preds).T res = [] for j in y_preds: res.append(np.bincount(j.astype('int')).argmax()) return res
基于上述随机森林算法封装来对模拟数据集进行训练并验证:
rf = RandomForest(n_estimators=10, max_features=15)rf.fit(X_train, y_train)y_pred = rf.predict(X_test)print(accuracy_score(y_test, y_pred))
sklearn也为我们提供了随机森林算法的api,我们也尝试一下与numpy手写的进行效果对比:
from sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(max_depth=3, random_state=0)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print(accuracy_score(y_test, y_pred))
可以看到sklearn的预测结果要略高于我们手写的结果。当然我们的训练结果还可以经过调参进一步提高。随机森林调参可参考sklearn官方文档,这里略过。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:
Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~













