如果自己想分析自己家的用电数据,那么如何获取用电量数据呢?网上国网app就可以做到。
入口一:打开网上国网App,点击【住宅】频道下的【电量电费】。
入口二:打开网上国网App,点击【更多】—【查询】—【电费电量】
查询方法:进入界面后,如果您绑定了多个户号,可选择切换需要查询的户号。
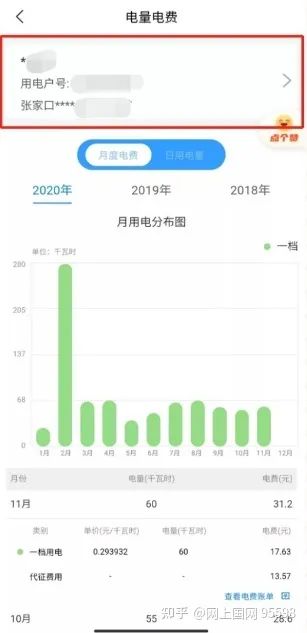
界面内默认展示月度电费使用情况,这里您可以查到近一年每月的电量电费信息。
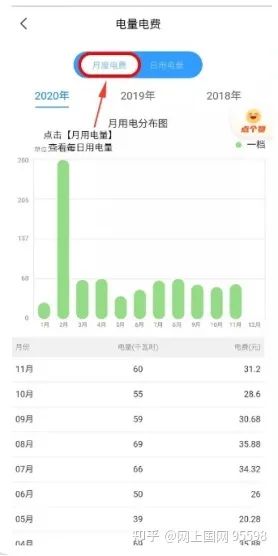
点击【日用电量】,您可以查询近7天或近30天的电费电量情况,由此分析家中耗电量大的电器和用电问题。
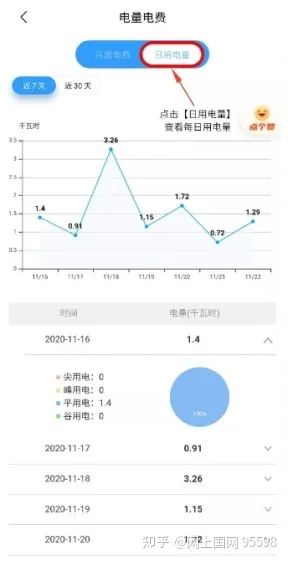
对于安装了智能电表的用户,每15分钟即可完成一次采集,每日可完成96点采集。每日96点高频数据主要用于供电质量相关指标分析,24小时每日用电量已能支撑普通用户分析自己的家庭用电情况。
数据介绍:
这里我们拿到的公开模拟数据是某家庭2017年的用电情况,数据点采集以30分钟间隔进行。样例数据如下。
import pandas as pdimport numpy as np
df = pd.read_csv('2017 House Energy Use.csv')print(df)
输出为: Time of day\tElectricity Used (kwH)\tDate0 0:00\t\t1/1/20171 0:30\t50.8\t1/1/20172 1:00\t54.1\t1/1/20173 1:30\t54\t1/1/20174 10:00\t50.3\t1/1/2017... ...17515 7:30\t43.6\t12/31/201717516 8:00\t43.5\t12/31/201717517 8:30\t43.5\t12/31/201717518 9:00\t44.6\t12/31/201717519 9:30\t44.5\t12/31/2017
[17520 rows x 1 columns]
可以看到三列数据以\t分割开,读入时需要进行处理。
df = pd.read_csv('2017 House Energy Use.csv',sep='\t')print(df)
输出为: Time of day Electricity Used (kwH) Date0 0:00 NaN 1/1/20171 0:30 50.8 1/1/20172 1:00 54.1 1/1/20173 1:30 54.0 1/1/20174 10:00 50.3 1/1/2017... ... ... ...17515 7:30 43.6 12/31/201717516 8:00 43.5 12/31/201717517 8:30 43.5 12/31/201717518 9:00 44.6 12/31/201717519 9:30 44.5 12/31/2017
用python进行家庭用电分析:
可以看到第一行就来个下马威,NaN值,即空值。那么我们浅看一下到底有多少空值,顺便描述一下整个数据,日常四连shape、dtypes、info()、describe():
print(df.shape)print(df.dtypes)print(df.info())print(df.describe())
输出为:(17520, 3)Time of day objectElectricity Used (kwH) float64Date objectdtype: object 'pandas.core.frame.DataFrame'>RangeIndex: 17520 entries, 0 to 17519Data columns (total 3 columns):--- ------ -------------- ----- 0 Time of day 17520 non-null object 1 Electricity Used (kwH) 17512 non-null float64 2 Date 17520 non-null object dtypes: float64(1), object(2)memory usage: 410.8+ KBNone Electricity Used (kwH)count 17512.000000mean 57.834736std 13.722834min 36.90000025% 45.50000050% 55.20000075% 68.100000max 107.800000
可以看出时间是date和time是分开的,且是object类型,需要合并转换为datatime类型才能游刃有余地操作。
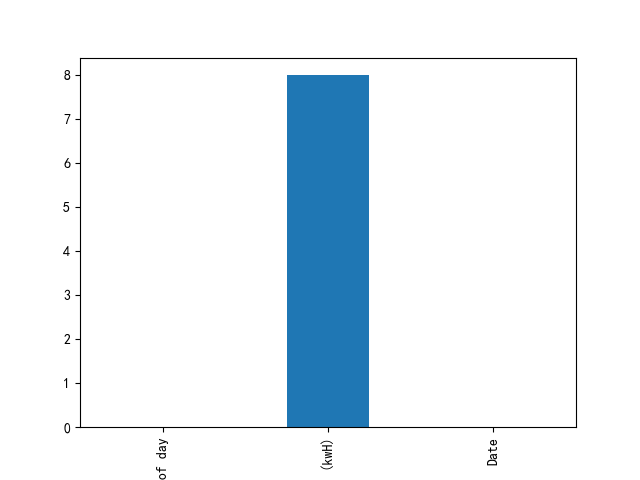
电量数据有8条缺失。
电量数据最大107.8kwH,最小36.9kWH,均值为57.8kWH,方差为13不算太大,说明电量相对较为稳定,波动不大。
下面验证一下缺失数据量和缺失率:
输出为:Time of day 0Electricity Used (kwH) 8Date 0
import matplotlib.pyplot as pltdf.isnull().sum().plot(kind='bar')plt.show()
df.isnull().mean().plot(kind='bar')plt.show()
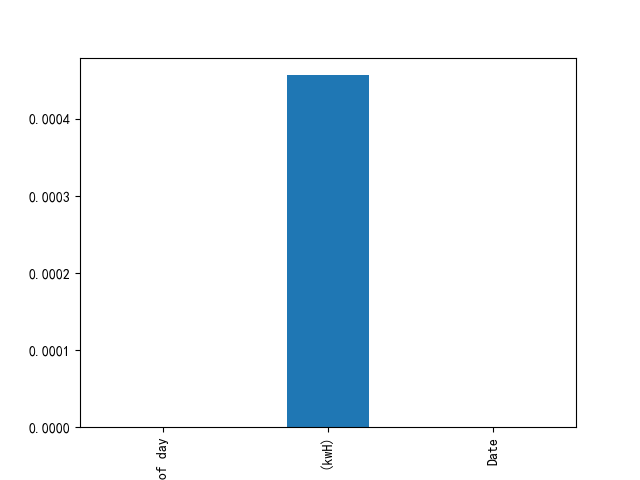
下面就要对缺失的电量数据进行填充,方法是全年该时间点(同一时刻,精确到分钟)用电量的算术平均值。
先把处理时间数据,把date、time合并并转换成datetime类型方便处理:
df['datetime']=df['Date']+" "+df['Time of day']print(df['datetime'])
输出为:0 1/1/2017 0:00
1 1/1/2017 0:302 1/1/2017 1:003 1/1/2017 1:304 1/1/2017 10:00 ... 17515 12/31/2017 7:3017516 12/31/2017 8:0017517 12/31/2017 8:3017518 12/31/2017 9:0017519 12/31/2017 9:30Name: datetime, Length: 17520, dtype: object
'%m/%d%Y %H:%M'是完全复刻df['datetime']里面的格式,如:12/31/2017 9:30。
利用time.mktime和time.strptime方法把字符串变成datetime:
import timedf['datetime']=df['datetime'].apply(lambda x:time.mktime(time.strptime(x,'%m/%d/%Y %H:%M')))print(type(df['datetime'][0]))print(df['datetime'][0])
输出:<class 'numpy.float64'>1483200000.0
此时df['datetime']里面数据的类型是用秒数表示时间的浮点数,不够直观,我们直接把时间重新表示为datatime类型。
df['datetime']=df['Date']+" "+df['Time of day']
df['datetime']=pd.to_datetime(df['datetime'],format='%m/%d/%Y %H:%M')print(df['datetime'][0])
此时我们要求全年每一时刻的平均值,那么就需要按照每一个时刻对全年数据进行分组,再求组内的平均值,就得到了一天每个时刻全年该时刻的平均值。
print(df.groupby(['Time of day']).describe())
Electricity Used (kwH) ... count mean std ... 50% 75% maxTime of day ... 0:00 364.0 47.454121 7.019431 ... 44.55 51.150 73.20:30 365.0 46.967671 6.827787 ... 44.30 50.400 70.110:00 365.0 68.301370 15.356182 ... 70.40 77.700 107.510:30 365.0 67.997808 15.060789 ... 69.30 77.300 104.211:00 365.0 67.943288 14.785737 ... 70.10 76.800 104.711:30 365.0 68.079452 14.571361 ... 70.40 76.300 106.812:00 365.0 67.864110 14.588877 ... 70.00 76.900 104.912:30 365.0
67.502740 14.611705 ... 69.30 75.900 104.313:00 365.0 67.131781 14.499516 ... 69.10 76.200 106.213:30 365.0 67.284110 14.572755 ... 69.50 76.200 107.814:00 365.0 66.709863 14.243894 ... 69.20 75.800 104.414:30 365.0 66.311781 14.060790 ... 69.00 75.100 104.515:00 363.0 66.084022 13.848656 ... 68.10 75.000 103.815:30 365.0 65.120274 13.608636 ... 66.90 73.300 107.516:00 365.0 64.453973 13.546506 ... 65.70 73.200 103.116:30 365.0 63.750411 13.370528 ... 64.40 71.900 104.817:00 365.0 62.424932 13.012038 ... 62.90 70.600 106.617:30 365.0 61.115616 12.183235 ... 61.30 68.200 101.718:00 364.0 60.079945 11.273788 ... 59.70 67.025 99.718:30 365.0 59.483014 10.412943 ... 58.90 65.800 92.019:00 365.0 58.545479 10.019808 ... 57.50 64.800 91.719:30 365.0 57.493425 9.650848 ... 56.50 63.400 91.81:00 364.0 46.531868 6.640835 ... 43.80 49.625 69.91:30 365.0 46.483562 6.562485 ... 43.90 49.400 71.920:00 365.0 55.786849 9.342838 ... 54.20 61.600 86.020:30 365.0 54.607671 8.986158 ... 52.80 60.100 84.321:00 365.0 53.138630 8.281985 ... 51.80 57.800 84.521:30 365.0 52.134795 7.995419 ... 50.80 56.900
79.522:00 365.0 51.203836 7.821627 ... 49.30 56.300 79.322:30 365.0 50.177808 7.476709 ... 48.10 54.400 77.623:00 364.0 49.315934 7.159734 ... 47.60 52.850 77.223:30 365.0 48.269315 7.128309 ... 45.80 51.700 74.42:00 365.0 46.357808 6.547877 ... 43.80 49.200 70.62:30 365.0 46.783562 6.491813 ... 44.30 50.200 71.93:00 365.0 47.001370 6.223244 ... 44.60 50.400 69.63:30 365.0 47.171233 6.246834 ... 44.60 51.100 69.04:00 365.0 47.283014 6.205363 ... 44.90 50.400 69.54:30 365.0 47.747397 6.137171 ... 45.70 50.800 69.75:00 365.0 48.838630 5.931770 ... 47.10 51.600 70.55:30 365.0 50.587671 6.091034 ... 49.80 53.900 70.76:00 365.0 52.771233 6.774834 ... 52.90 56.300 71.96:30 365.0 56.054521 8.167263 ... 57.40 61.400 77.17:00 365.0 58.490959 9.646790 ... 60.40 64.600 84.97:30 365.0 62.524384 11.520545 ... 65.30 70.100 90.88:00 364.0 64.531593 12.711482 ... 67.55 73.100 94.48:30 365.0 67.289589 14.453562 ... 70.00 76.700 98.69:00 365.0 68.198904 15.035851 ... 71.40 77.200 100.89:30 364.0 68.702747 15.349771 ... 71.65 77.625 104.4
print(df.groupby(['Time of day']).describe()['Electricity Used (kwH)']['mean'])
输出为:Time of day0:00 47.4541210:30 46.96767110:00 68.30137010:30 67.99780811:00 67.94328811:30 68.07945212:00 67.86411012:30 67.50274013:00 67.13178113:30 67.28411014:00 66.70986314:30 66.31178115:00 66.08402215:30 65.12027416:00 64.45397316:30 63.75041117:00 62.42493217:30 61.11561618:00 60.07994518:30 59.48301419:00 58.54547919:30 57.4934251:00 46.5318681:30 46.48356220:00 55.78684920:30 54.60767121:00 53.13863021:30 52.13479522:00 51.20383622:30 50.17780823:00 49.31593423:30 48.2693152:00 46.3578082:30 46.7835623:00 47.0013703:30 47.1712334:00 47.2830144:30 47.7473975:00 48.8386305:30 50.5876716:00 52.7712336:30 56.0545217:00 58.4909597:30 62.5243848:00 64.5315938:30 67.2895899:00 68.1989049:30 68.702747
此时就可以手动查找每个时间点的平均值了,可手动填入缺失数据,那么如何用python自动处理呢?groupby分组后,每个组内计算平均值,再看组内有无缺失值,有立即用平均值填入,最后把每个分组内的数据堆叠在一起。
new_data=[]for name,group in df.groupby(['Time of day']): # print(name) #前面的时间:Time of day,此处就是某一个时间点
# print(group) #用Time of day分出来的组,该时间点内的所有值和集合 #计算组内的均值 mean_value=group['Electricity Used (kwH)'].mean() mean_value=round(mean_value,1) #填充缺失值 group['Electricity Used (kwH)'].fillna(mean_value,inplace=True) new_data.append(group)
#将处理好缺失值的各分组进行垂直拼接再按时间顺序进行排列
final_data = pd.concat(new_data)
final_data.sort_values(by=['datetime'],inplace=True)
final_data.drop(columns=['datetime'],inplace=True)
print(final_data)
输出为: Time of day Electricity Used (kwH) Date0 0:00 47.5 1/1/20171 0:30 50.8 1/1/20172 1:00 54.1 1/1/20173 1:30 54.0 1/1/201724 2:00 55.6 1/1/2017... ... ... ...17501 21:30 48.8 12/31/201717502 22:00 50.7 12/31/201717503 22:30 51.9 12/31/201717504 23:00 50.9 12/31/201717505 23:30 50.5 12/31/2017
1/1/2017格式不好看我们把他变为2017/1/1
def f(x): x=str(x) x=x.split('/') y=x[2]+'/'+x[0]+'/'+x[1] return y
final_data['Date']=final_data['Date'].apply(lambda x:f(x))
print(final_data['Date'][0])
把结果存起来备用:
final_data.to_csv('final_data.csv',index=False)
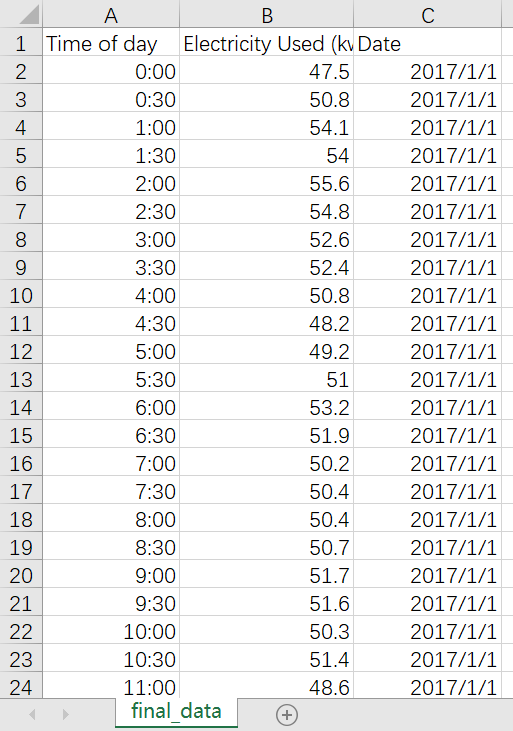
现在想看一下每个月的用电量统计,也就是如下图:
需要用到groupby对月份进行分组并统计每个月的总用电量,用统计出来的用电量进行数据可视化。
import numpy as npimport pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.family'] = 'SimHei' plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv('final_data.csv')
数据里面根本就没有月份列,所以要先把月份列造出来:
df['month']=df['Date'].apply(lambda x:x.split('/')[1])
先把数据生成DataFrame保存成文件,再把画图需要的x、y轴数据分别求出来:
import numpy as npimport pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.family'] = 'SimHei' plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv('final_data.csv')
df['month']=df['Date'].apply(lambda x:x.split('/')[1])
new_data=[]for name,group in df.groupby(['month']): sum_value = group['Electricity Used (kwH)'].sum() sum_value = round(sum_value,1) new_data.append([sum_value,name])
result = pd.DataFrame(new_data,columns=['Electricity Used (kwH)','month'])result['Date']=result['month'].map(str)+'/2017'
result_final=result.drop(columns=['month'])result_final.to_csv('result_final.csv')
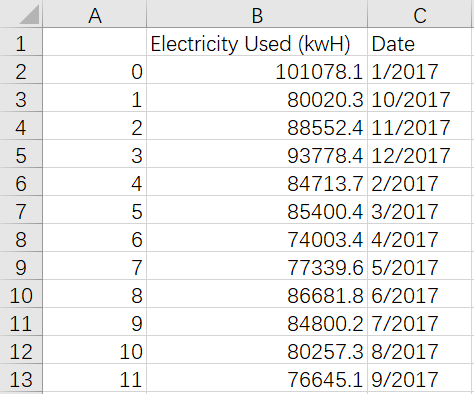
result['month'] = result['month'].astype(int)result.sort_values(by=['month'],ascending=True,inplace=True)
x_axis = result['month'].valuesy_axis = result['Electricity Used (kwH)'].values
fig=plt.figure()plt.bar(x_axis,y_axis)plt.title("月用电量")plt.ylabel("kWh")plt.xlabel("月份")plt.show()
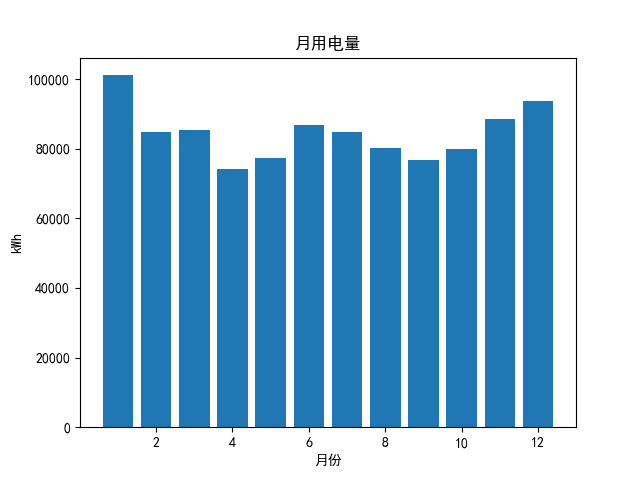
可以看出6-8月夏天和11-2月冬天开空调的时候用电量比较大,且冬天用电量比夏天大。
假如我10月份被疫情关在家里,我想分析只分析10月份的数据,我需要用pandas的条件选择语句把10月份的数据选出来。
import numpy as npimport pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.family'] = 'SimHei' plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv('final_data.csv')
df['month']=df['Date'].apply(lambda x:int(x.split('/')[1]))
df_ten = df[df['month'] == 10]
print(df_ten)
输出为: Time of day Electricity Used (kwH) Date month13104 0:00 41.6 2017/10/1 1013105 0:30 42.7 2017/10/1 1013106 1:00 41.9 2017/10/1 1013107 1:30 41.5 2017/10/1 1013108 2:00 41.0 2017/10/1 10... ... ... ... ...14587 21:30 57.9 2017/10/31 10
14588 22:00 57.0 2017/10/31 1014589 22:30 57.8 2017/10/31 1014590 23:00 56.8 2017/10/31 1014591 23:30 56.4 2017/10/31 10
用Date和time生成datetime用于排序:
df_ten['datetime']=df_ten['Date']+" "+df_ten['Time of day']
df_ten['datetime']=pd.to_datetime(df_ten['datetime'],format='%Y/%m/%d %H:%M')
df_ten.sort_values(by=['datetime'],inplace=True)
df_ten.drop(columns=['month','datetime'],inplace=True)
df_ten.to_csv('df_ten.csv')
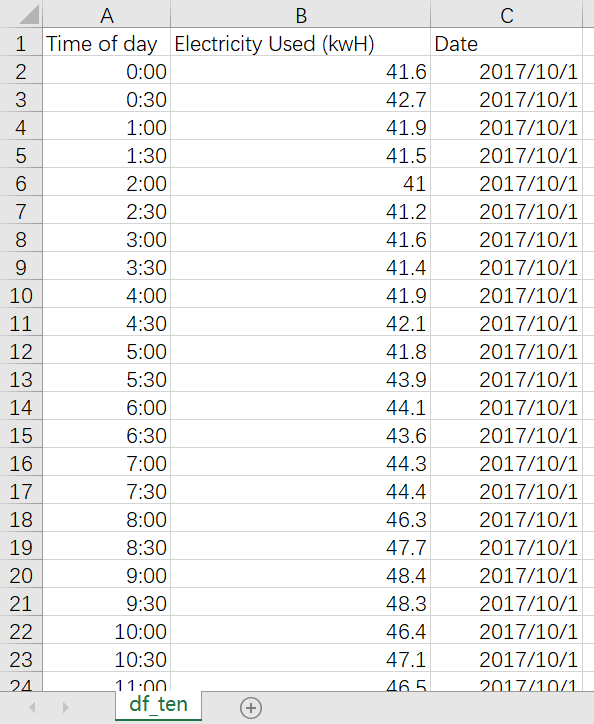
对11:00-14:00,17:00-20:00点这两个用电高峰期的用电曲线进行数据可视化,对这两个时间段中的数据选取用isin方法。
df = pd.read_csv('df_ten.csv')
#采用此函数来把要画图的y值求出来,也就是def get_value(param_datas,para_point): #选取包含指定时间点的数据 select_data = param_datas[param_datas['Time of day'].isin(para_point)] #新建两个要返回的值 date=[] value=[] #按每天来分组求和 for name,group in select_data.groupby("Date"): sum_value = group['Electricity Used (kwH)'].sum() sum_value = round(sum_value,1) date.append(name) value.append(sum_value) return date,value
time_point1 = ['11:00','11:30','12:00','12:30','13:00','13:30']time_point2 = ['17:00','17:30','18:00','18:30','19:00','19:30']
#对两组时间点数据分别处理date_1,datas_1 = get_value(df,time_point1)date_2,datas_2 = get_value(df,time_point2)
#图形绘制及输出
#生成1-31的天数的x值x = [i for i in range(1,32)]
plt.plot(x,datas_1,label='11-14')
for x,y in zip(x,datas_1): plt.text(x,y,y)
x = [i for i in range(1,32)]
plt.plot(x,datas_2,label='17-20')
for x,y in zip(x,datas_2): plt.text(x,y,y)
plt.title("十月用电两个时段对比")plt.legend()plt.savefig('10月.png')plt.show()
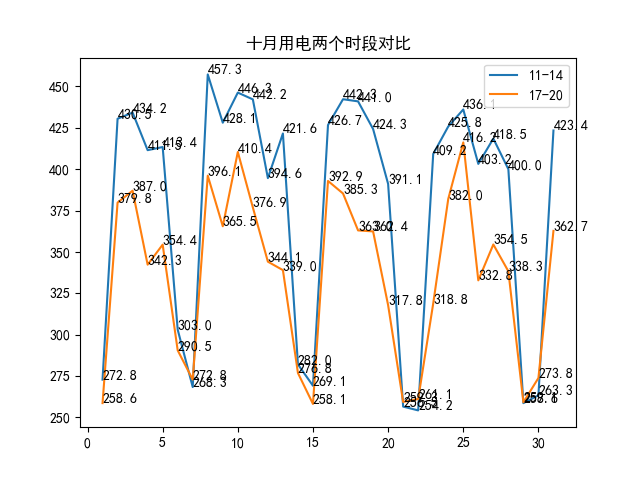
可以看出中午的用电量比下午的用电量大。
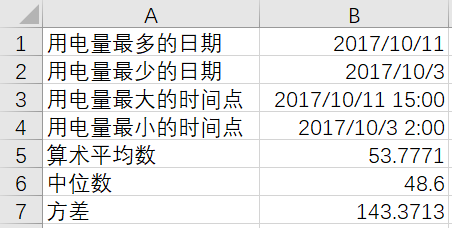
最后详细统计10月份用电最多最少的日期及时间节点,平均数、中位数、方差等信息:
df = pd.read_csv('df_ten.csv')
min_value = df['Electricity Used (kwH)'].min()min_select = df[df['Electricity Used (kwH)']==min_value]print(min_select)
输出为: Time of day Electricity Used (kwH) Date100 2:00 39.3 2017/10/3
max_value = df['Electricity Used (kwH)'].max()max_select = df[df['Electricity Used (kwH)']==max_value]
mean_value = df['Electricity Used (kwH)'].mean()median_value = df['Electricity Used (kwH)'].median()var_value = df['Electricity Used (kwH)'].var()
result = pd.DataFrame()
result['a'] = ['用电量最多的日期','用电量最少的日期','用电量最大的时间点','用电量最小的时间点','算术平均数','中位数','方差']result['b'] = [max_select['Date'].values[0], min_select['Date'].values[0], max_select['Date'].values[0]+' '+max_select['Time of day'].values[0], min_select['Date'].values[0]+' '+min_select['Time of day'].values[0], round(mean_value,4), round(median_value,4), round(var_value,4)]
result.to_csv('result.csv',index=False,header=None)
- 机器学习交流qq群955171419,加入微信群请
扫码









